适用于:![]() Azure SQL 数据库
Azure SQL 数据库![]() Azure SQL 托管实例
Azure SQL 托管实例
注意
截至 2020 年 9 月,此连接器未进行主动维护。 本文仅用于存档目的。
通过使用 Spark 连接器,Azure SQL 数据库、Azure SQL 托管实例和 SQL Server 中的数据库可以充当 Spark 作业的输入数据源或输出数据接收器。 由此,可在大数据分析中利用实时事务数据,并保留临时查询或报告的结果。 与内置 JDBC 连接器相比,此连接器能够将数据批量插入数据库。 它的性能可以比逐行插入快 10 倍到 20 倍。 Spark 连接器支持使用 Microsoft Entra ID(以前称为 Azure Active Directory)进行身份验证以连接到 Azure SQL 数据库和 Azure SQL 托管实例,从而允许你使用 Microsoft Entra 帐户从 Azure Databricks 连接数据库。 它提供与内置 JDBC 连接器类似的接口。 可以轻松迁移现有的 Spark 作业以使用此新连接器。
注意
Microsoft Entra ID 以前称为 Azure Active Directory (Azure AD)。
下载并构建 Spark 连接器
我们不主动维护以前从此页链接到的旧连接器的 GitHub 存储库, 但强烈建议你评估并使用新连接器。
官方支持的版本
| 组件 | 版本 |
|---|---|
| Apache Spark | 2.0.2 或更高版本 |
| Scala(编程语言) | 2.10 或更高版本 |
| 用于 SQL Server 的 Microsoft JDBC 驱动程序 | 6.2 或更高版本 |
| Microsoft SQL Server | SQL Server 2008 或更高版本 |
| Azure SQL 数据库 | 支持 |
| Azure SQL 托管实例 | 支持 |
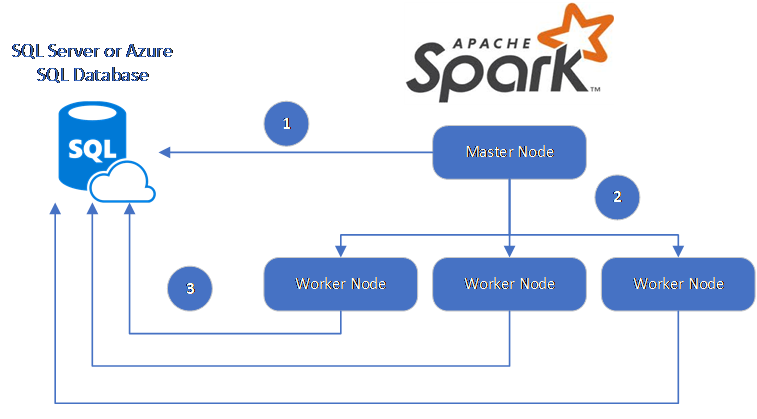
Spark 连接器利用 Microsoft JDBC Driver for SQL Server 在 Spark 工作器节点和数据库之间移动数据:
数据流如下所示:
- Spark 主节点连接到 SQL 数据库或 SQL Server 中的数据库,并从特定的表中或使用特定的 SQL 查询加载数据。
- Spark 主节点将数据分发到辅助角色节点以进行转换。
- 工作器节点连接到与 SQL 数据库或 SQL Server 连接的数据库并将数据写入数据库。 用户可选择使用逐行插入或批量插入。
下图演示了此数据流。
生成 Spark 连接器
目前,连接器项目使用 maven。 若要构建不带依赖项的连接器,可以运行:
- mvn 清理包
- 从 releases 文件夹中下载最新版本的 JAR
- 包括 SQL 数据库 Spark JAR
使用 Spark 连接器连接和读取数据
可以从 Spark 作业连接到 SQL 数据库和 SQL Server 中的数据库以读取或写入数据。 也可在 SQL 数据库或 SQL Server 的数据库中运行 DML 或 DDL 查询。
从 Azure SQL 和 SQL Server 读取数据
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.connect._
val config = Config(Map(
"url" -> "mysqlserver.database.chinacloudapi.cn",
"databaseName" -> "MyDatabase",
"dbTable" -> "dbo.Clients",
"user" -> "username",
"password" -> "*********",
"connectTimeout" -> "5", //seconds
"queryTimeout" -> "5" //seconds
))
val collection = sqlContext.read.sqlDB(config)
collection.show()
使用指定的 SQL 查询从 Azure SQL 和 SQL Server 读取数据
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.connect._
val config = Config(Map(
"url" -> "mysqlserver.database.chinacloudapi.cn",
"databaseName" -> "MyDatabase",
"queryCustom" -> "SELECT TOP 100 * FROM dbo.Clients WHERE PostalCode = 98074" //Sql query
"user" -> "username",
"password" -> "*********",
))
//Read all data in table dbo.Clients
val collection = sqlContext.read.sqlDB(config)
collection.show()
将数据写入 Azure SQL 和 SQL Server
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.connect._
// Acquire a DataFrame collection (val collection)
val config = Config(Map(
"url" -> "mysqlserver.database.chinacloudapi.cn",
"databaseName" -> "MyDatabase",
"dbTable" -> "dbo.Clients",
"user" -> "username",
"password" -> "*********"
))
import org.apache.spark.sql.SaveMode
collection.write.mode(SaveMode.Append).sqlDB(config)
在 Azure SQL 和 SQL Server 中运行 DML 或 DDL 查询
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.query._
val query = """
|UPDATE Customers
|SET ContactName = 'Alfred Schmidt', City = 'Frankfurt'
|WHERE CustomerID = 1;
""".stripMargin
val config = Config(Map(
"url" -> "mysqlserver.database.chinacloudapi.cn",
"databaseName" -> "MyDatabase",
"user" -> "username",
"password" -> "*********",
"queryCustom" -> query
))
sqlContext.sqlDBQuery(config)
使用 Microsoft Entra 身份验证从 Spark 连接
可以使用 Microsoft Entra 身份验证连接到 SQL 数据库和 SQL 托管实例。 Microsoft Entra 身份验证可用于集中管理数据库用户的标识,并替代 SQL 身份验证。
使用 ActiveDirectoryPassword 身份验证模式进行连接
设置要求
如果使用 ActiveDirectoryPassword 身份验证模式,请下载 microsoft-authentication-library-for-java 及其依赖项,并将其包含在 Java 生成路径中。
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.connect._
val config = Config(Map(
"url" -> "mysqlserver.database.chinacloudapi.cn",
"databaseName" -> "MyDatabase",
"user" -> "username",
"password" -> "*********",
"authentication" -> "ActiveDirectoryPassword",
"encrypt" -> "true"
))
val collection = sqlContext.read.sqlDB(config)
collection.show()
使用访问令牌进行连接
设置要求
如果使用基于访问令牌的身份验证模式,则需要下载 microsoft-authentication-library-for-java 及其依赖项,并将它们包含在 Java 生成路径中。
请参阅 azure SQL Microsoft Entra 身份验证 ,了解如何获取 Azure SQL 数据库或 Azure SQL 托管实例中数据库的访问令牌。
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.connect._
val config = Config(Map(
"url" -> "mysqlserver.database.chinacloudapi.cn",
"databaseName" -> "MyDatabase",
"accessToken" -> "access_token",
"hostNameInCertificate" -> "*.database.chinacloudapi.cn",
"encrypt" -> "true"
))
val collection = sqlContext.read.sqlDB(config)
collection.show()
通过批量插入操作写入数据
传统的 jdbc 连接器使用逐行插入的方式将数据写入数据库。 可以使用 Spark 连接器,以批量插入的方式将数据写入 Azure SQL 和 SQL Server。 在加载大型数据集或将数据加载到使用列存储索引的表中时,该方式显着提高了写入性能。
import com.microsoft.azure.sqldb.spark.bulkcopy.BulkCopyMetadata
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.connect._
/**
Add column Metadata.
If not specified, metadata is automatically added
from the destination table, which may suffer performance.
*/
var bulkCopyMetadata = new BulkCopyMetadata
bulkCopyMetadata.addColumnMetadata(1, "Title", java.sql.Types.NVARCHAR, 128, 0)
bulkCopyMetadata.addColumnMetadata(2, "FirstName", java.sql.Types.NVARCHAR, 50, 0)
bulkCopyMetadata.addColumnMetadata(3, "LastName", java.sql.Types.NVARCHAR, 50, 0)
val bulkCopyConfig = Config(Map(
"url" -> "mysqlserver.database.chinacloudapi.cn",
"databaseName" -> "MyDatabase",
"user" -> "username",
"password" -> "*********",
"dbTable" -> "dbo.Clients",
"bulkCopyBatchSize" -> "2500",
"bulkCopyTableLock" -> "true",
"bulkCopyTimeout" -> "600"
))
df.bulkCopyToSqlDB(bulkCopyConfig, bulkCopyMetadata)
//df.bulkCopyToSqlDB(bulkCopyConfig) if no metadata is specified.