Azure Cosmos DB 提供各种选项,以便对操作数据启用大规模分析和商业智能报告。
若要获取对 Azure Cosmos DB 数据的有意义的见解,可能需要跨 Cosmos DB 中的多个数据库和集合查询聚合函数(例如总和、计数等),并可能查询其他数据源(如 Azure SQL 数据库或 lakehouse)。 此类查询需要大量的计算能力,这可能会消耗更多请求单位(RU),因此,这些查询可能会影响任务关键型工作负荷性能。
为了将事务工作负荷与复杂分析查询的性能影响隔离开来,并帮助将这些数据与组织中的其他不同数据来源整合,Azure Cosmos DB 和 Microsoft Fabric 通过 Microsoft Fabric 中的 Azure Cosmos DB 镜像和 Cosmos DB 提供零 ETL 和经济高效的分析解决方案来解决这些难题。
重要
新项目不再支持 Synapse Link for Cosmos DB。 请勿使用此功能。
请使用现已正式发布的 Microsoft Fabric 的 Azure Cosmos DB 镜像。 镜像提供相同的零 ETL 优势,并与 Microsoft Fabric 完全集成。
选项 1:将 Azure Cosmos DB 数据镜像到 Microsoft Fabric 中
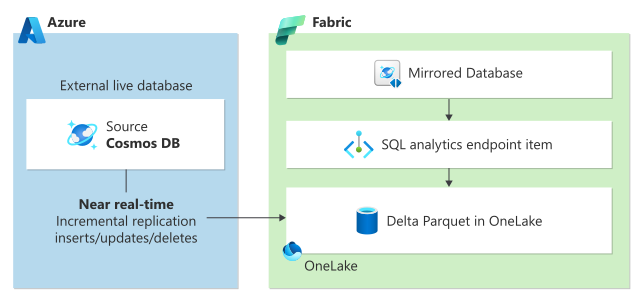
Microsoft Fabric 中的镜像提供了无缝的无 ETL 体验,可将现有的 Azure Cosmos DB 数据与 Microsoft Fabric 中的其余数据集成,实现真正的混合事务/分析处理(HTAP),并在事务和分析系统之间实现完整的工作负荷隔离。 Azure Cosmos DB 数据持续复制到 Fabric OneLake,几乎实时,不会影响事务工作负载的性能,也不会消耗请求单位(RU)。
OneLake 中的数据以开源增量格式存储,并自动提供给 Fabric 上的所有分析引擎。
可以使用内置的 Power BI 功能在 DirectLake 模式下访问 OneLake 中的数据。 借助 Fabric 中的 Copilot 增强功能,您可以利用生成式 AI 的强大功能来获取业务数据的关键见解。 除了 Power BI,还可以使用 T-SQL 运行复杂的聚合查询或使用 Spark 进行数据浏览。 可以无缝访问笔记本中的数据,并使用数据科学生成机器学习模型。
若要开始使用镜像,请访问“镜像入门教程”。
选项 2:Fabric 中的 Azure Cosmos DB
Microsoft Fabric 中的 Cosmos DB 是一个经过 AI 优化的 NoSQL 数据库,具有简化的管理体验。 作为开发人员,可以使用 Fabric 中的 Cosmos DB 构建具有较少摩擦的 AI 应用程序,而无需执行典型的数据库管理任务。 作为分析用户,Cosmos DB 可用作低延迟服务层,使报表更快且能够同时为数千个用户提供服务。
Microsoft Fabric 中的 Cosmos DB 使用与 Azure Cosmos DB for NoSQL 相同的基础结构,但紧密集成到 Fabric 中。 Cosmos DB 提供了一个无架构数据模型,非常适合半结构化数据或不断发展的数据模型;提供无限、自动和即时缩放,延迟低且内置高可用性。