Azure Cosmos DB 可以存储 TB 级的数据。 可以执行大规模数据迁移,将生产工作负荷移动到 Azure Cosmos DB。 本文介绍将大规模数据迁移到 Azure Cosmos DB 涉及的难题,并介绍有助于应对挑战和将数据迁移到 Azure Cosmos DB 的工具。 在此案例研究中,客户使用了 Azure Cosmos DB API for NoSQL。
在将整个工作负荷迁移到 Azure Cosmos DB 之前,可以先迁移一部分数据,以便在某些方面进行验证,例如分区键的选择、查询性能和数据建模。 验证概念证明后,可将整个工作负荷移到 Azure Cosmos DB。
数据迁移工具
目前,Azure Cosmos DB 迁移策略根据所选的 API 和数据大小而异。 若要迁移较小的数据集(用于验证数据建模、查询性能、分区键选择等)可以使用 Azure 数据工厂的 Azure Cosmos DB 连接器。 如果你熟悉 Spark,则还可以选择使用 Azure Cosmos DB Spark 连接器来迁移数据。
大规模迁移的挑战
用于将数据迁移到 Azure Cosmos DB 的现有工具存在一些限制,进行大规模迁移时,这些限制尤其明显:
受限的横向扩展功能:若要尽快将 TB 量级的数据迁移到 Azure Cosmos DB 并有效利用整个预配吞吐量,迁移客户端应该具备无限横向扩展的能力。
缺少进度跟踪和检查点:迁移大型数据集时,必须跟踪迁移进度并创建检查点。 否则,迁移过程中发生的任何错误将停止迁移,并且必须从头开始该过程。 如果迁移过程已完成 99%,重新开始整个迁移过程将降低效率。
缺少死信队列:在大型数据集中,可能有一部分源数据存在问题。 此外,客户端或网络可能出现暂时性的问题。 其中任一情况都不应导致整个迁移失败。 尽管大多数迁移工具具有可靠的重试功能,可防范间歇性问题,但并非总是足够。 例如,如果源数据文档中大于 2 MB 的文档少于总量的 0.01%,则会导致在 Azure Cosmos DB 中写入失败。 理想情况下,迁移工具可以将这些“失败”的文档保存到另一个死信队列中,迁移完成后再进行处理。
Azure 数据工厂、Azure 数据迁移服务之类的工具正在修复上述许多限制。
包含批量执行程序库的自定义工具
可以通过使用自定义工具来解决上一部分中介绍的挑战,该工具可以轻松地跨多个实例横向扩展,并且可复原暂时性故障。 此外,自定义工具可以在不同的检查点处暂停和恢复迁移。 Azure Cosmos DB 已提供整合了其中某些功能的批量执行程序库。 例如,批量执行程序库已包含处理暂时性错误的功能,并且可以横向扩展单个节点中的线程,以消耗每个节点中的大约 50 万个 RU。 批量执行程序库还可将源数据集分区成可作为检查点形式独立运行的微批。
自定义工具使用批量执行程序库,支持跨多个客户端横向扩展,并可以跟踪引入过程中出现的错误。 若要使用此工具,应将源数据分区成 Azure Data Lake Storage (ADLS) 中的不同文件,以便不同的迁移工作线程可以选取每个文件并将其引入 Azure Cosmos DB。 自定义工具利用单独的集合,该集合存储 ADLS 中每个源文件的迁移进度的相关元数据,并跟踪与这些文件关联的任何错误。
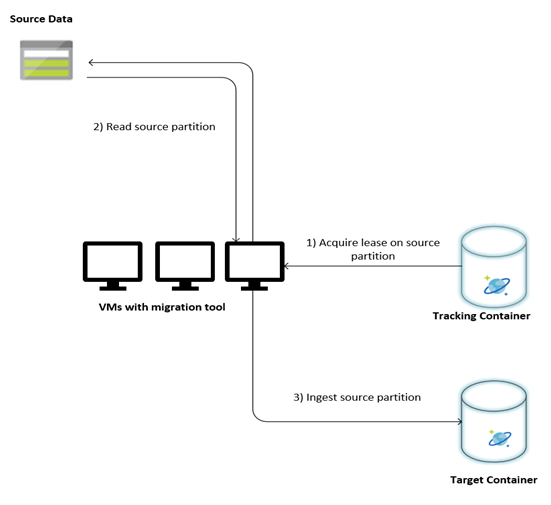
下图描述了使用此自定义工具的迁移过程。 该工具在一组虚拟机上运行,其中每个虚拟机查询 Azure Cosmos DB 中的跟踪集合,以获取某个源数据分区上的租约。 完成此操作后,该工具将读取源数据分区,并使用批量执行程序库将其引入 Azure Cosmos DB。 接下来,跟踪集合将会更新,以记录数据引入的进度和遇到的任何错误。 处理数据分区后,该工具会尝试查询下一个可用的源分区。 它会继续处理下一个源分区,直到迁移了所有数据。 该工具的源代码可从 Azure Cosmos DB 批量引入存储库中获得。
跟踪集合包含以下示例中所示的文档。 你将看到,源数据中的每个分区都有一个这样的文档。 每个文档包含源数据分区的元数据,例如,该数据分区的位置、迁移状态和错误(如果有):
{
"owner": "25812@bulkimporttest07",
"jsonStoreEntityImportResponse": {
"numberOfDocumentsReceived": 446688,
"isError": false,
"totalRequestUnitsConsumed": 3950252.2800000003,
"errorInfo": [],
"totalTimeTakenInSeconds": 188,
"numberOfDocumentsImported": 446688
},
"storeType": "AZURE_BLOB",
"name": "sourceDataPartition",
"location": "sourceDataPartitionLocation",
"id": "sourceDataPartitionId",
"isInProgress": false,
"operation": "unpartitioned-writes",
"createDate": {
"seconds": 1561667225,
"nanos": 146000000
},
"completeDate": {
"seconds": 1561667515,
"nanos": 180000000
},
"isComplete": true
}
数据迁移的先决条件
在开始迁移数据之前,需要注意以下几项先决条件:
估算数据大小:
源数据大小无法确切地映射到 Azure Cosmos DB 中的数据大小。 可以插入源中的几个示例文档,以检查它们在 Azure Cosmos DB 中的数据大小。 然后可以根据示例文档的大小,估算迁移后 Azure Cosmos DB 中的总数据大小。
例如,如果每个文档在迁移到 Azure Cosmos DB 之后大约为 1 KB,并且源数据集中大约有 600 亿个文档,则 Azure Cosmos DB 中的估算大小大致为 60 TB。
预先创建具有足够 RU 的容器:
尽管 Azure Cosmos DB 会自动横向扩展存储,但不建议从最小的容器大小开始。 较小容器的可用吞吐量较低,这意味着,完成迁移所需的时间更长。 相反,创建具有最终数据大小的容器(如上一步估计),并确保迁移工作负荷完全消耗预配的吞吐量非常有用。
在上一步中,由于数据大小估计约为 60 TB,因此需要至少 2.4 M RU 的容器来容纳整个数据集。
估算迁移速度:
假设迁移工作负荷可以消耗整个预配吞吐量,预配吞吐量将会提供迁移速度的估算值。 继续前面的示例,需要五个 RU 才能将 1 KB 文档写入 Azure Cosmos DB API for NoSQL 帐户。 使用 240 万个 RU 每秒可以传输 48 万个文档(每秒 480 MB)。 这意味着 60 TB 的完整迁移需要 125,000 秒或大约 34 小时。
如果你希望迁移在一天内完成,应将预配吞吐量提高到 500 万个 RU。
关闭索引:
由于应尽快完成迁移,因此建议尽量减少为引入的每个文档创建索引所用的时间和 RU。 Azure Cosmos DB 会自动为所有属性编制索引,因此最好将索引降到选定的几个术语,或者完全关闭它以完成迁移过程。 可以通过将 indexingMode 更改为 none 来关闭容器的索引策略,如下所示:
{
"indexingMode": "none"
}
迁移完成后,可以更新索引。
迁移流程
满足先决条件后,可以执行以下步骤来迁移数据:
首先,将源中的数据导入 Azure Blob 存储。 为了加快迁移速度,跨不同的源分区并行化会很有帮助。 在开始迁移之前,应将源数据集分区成大小约为 200 MB 的文件。
批量执行程序库可以纵向扩展,以消耗单个客户端 VM 中的 50 万个 RU。 由于可用吞吐量为 500 万个 RU,因此,应在 Azure Cosmos DB 数据库所在的同一区域中预配 10 个 Ubuntu 16.04 VM (Standard_D32_v3)。 应使用迁移工具及其设置文件准备好这些 VM。
在某个客户端虚拟机上运行排队步骤。 此步骤将创建跟踪集合,该集合会扫描 ADLS 容器,并为每个源数据集的分区文件创建进度跟踪文档。
接下来,在所有客户端 VM 上运行导入步骤。 每个客户端都可以取得源分区的所有权,并将其数据引入 Azure Cosmos DB。 完成后,其状态在跟踪集合中更新后,客户端可以查询跟踪集合中的下一个可用源分区。
此过程将持续到引入了整个源分区集为止。 处理所有源分区之后,应以纠错模式针对同一个跟踪集合重新运行该工具。 此步骤需要标识应因错误而重新处理的源分区。
其中某些错误可能是源数据中错误的文档造成的。 应识别并修复这些错误。 接下来,应针对失败的分区重新运行导入步骤以将其重新引入。
完成迁移后,可以验证 Azure Cosmos DB 中的文档计数是否与源数据库中的文档计数相同。 在此示例中,Azure Cosmos DB 中的总大小为 65 TB。 迁移后,可以选择性地启用索引编制,并且可以将 RU(请求单位)降低到工作负载操作所需的级别。
后续步骤
- 若要进行详细了解,请试用那些在 .NET 和 Java 中使用批量执行程序库的示例应用程序。
- 批量执行工具库已集成到 Azure Cosmos DB Spark 连接器中。若要详细了解,请参阅 Azure Cosmos DB Spark 连接器一文。
- 在“常规咨询”问题类型和“大型(TB+)迁移”问题子类型下打开支持票证,以联系 Azure Cosmos DB 产品团队,以获取更多有关大规模迁移的帮助。
- 尝试为迁移到 Azure Cosmos DB 进行容量规划? 可以使用有关现有数据库群集的信息进行容量规划。
- 如果你只知道现有数据库群集中的 vCore 和服务器数量,请阅读根据 vCore 或 vCPU 数量估算请求单位数
- 若知道当前数据库工作负载的典型请求速率,请阅读使用 Azure Cosmos DB 容量计划工具估算请求单位