尽管无架构数据库(如 Azure Cosmos DB),但可以轻松存储和查询非结构化和半结构化数据,但请考虑数据模型以优化性能、可伸缩性和成本。
如何存储数据? 应用程序如何检索和查询数据? 应用程序是读取密集型还是写入密集型?
阅读本文后,可以回答以下问题:
- 什么是数据建模,我为什么应该关注?
- Azure Cosmos DB 中的数据建模与关系数据库有何不同?
- 如何在非关系数据库中表达数据关系?
- 我应何时嵌入数据和何时链接数据?
JSON 格式的数字
Azure Cosmos DB 将文档保存在 JSON 中,因此请务必在将数字存储在 JSON 中之前确定是否将数字转换为字符串。 如果数字可能会超过IEEE 754 binary64定义的双精度浮点数的边界,请将所有数字转换为String。
JSON 规范解释了为何使用此边界之外的数字是一种不良做法,因为互作性问题。 这些问题尤其与分区键列相关,因为它不可变,并且需要数据迁移才能在以后进行更改。
嵌入数据
在 Azure Cosmos DB 中为数据建模时,请将实体视为自包含项表示为 JSON 文档。
为了进行比较,让我们先了解一下关系数据库中的数据建模方式。 下面的示例演示了如何在关系型数据库中存储一个人的信息。
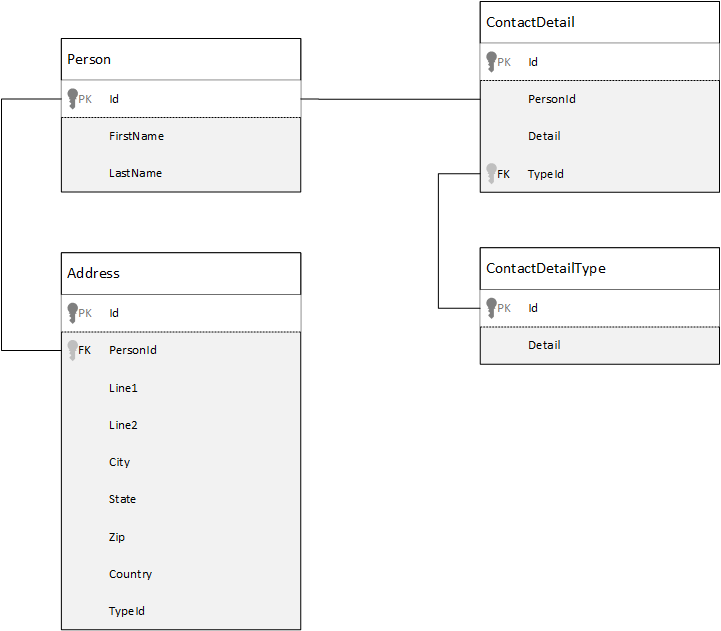
使用关系数据库时,策略是将所有数据规范化。 规范化数据通常涉及到将一个实体(例如某人)的信息分解为多个离散的组成部分。 在示例中,一个人可以有多个联系人详细信息记录,以及多个地址记录。 可以通过提取常见字段(如类型)来进一步细分联系人详细信息。 相同的方法适用于地址。 每个记录都可以归类为 家庭 或 企业。
规范化数据时的指导前提是避免在每个记录中 存储冗余数据 ,而是引用数据。 在本示例中,若要读取某个人的所有联系人详细信息和地址信息,在运行时需要使用 JOINS 有效地重新撰写(或反规范化)数据。
SELECT p.FirstName, p.LastName, a.City, cd.Detail
FROM Person p
JOIN ContactDetail cd ON cd.PersonId = p.Id
JOIN ContactDetailType cdt ON cdt.Id = cd.TypeId
JOIN Address a ON a.PersonId = p.Id
更新单个人员的联系人详细信息和地址需要跨多个独立的表格执行写入操作。
现在让我们看看如何在 Azure Cosmos DB 中将同一数据建模为自包含实体。
{
"id": "1",
"firstName": "Thomas",
"lastName": "Andersen",
"addresses": [
{
"line1": "100 Some Street",
"line2": "Unit 1",
"city": "Seattle",
"state": "WA",
"zip": 98012
}
],
"contactDetails": [
{"email": "thomas@andersen.com"},
{"phone": "+1 555 555-5555", "extension": 5555}
]
}
使用此方法,我们已将与此人相关的所有信息(例如其联系人详细信息和地址)嵌入到单个 JSON 文档中,来非规范化人员记录。 此外,由于我们没有被固定的架构所限制,因此我们可以灵活地进行操作,比如拥有完全不同格式的联系方式。
从数据库检索完整的人员记录现在只需对单个容器中的单个项进行一次读取操作。 更新人员记录的联系人详细信息和地址也是针对单个项的“单个写入操作”。
数据反规范化可能会减少您的应用程序完成常见操作所需的查询数和更新。
何时嵌入
通常在下列情况下使用嵌入式数据模型:
- 实体之间存在“包含”关系。
- 实体之间存在“一对多”关系。
- 数据 不常更改。
- 数据 不会在没有绑定的情况下增长。
- 数据经常被一起查询。
注释
通常非规范化数据模型具有更好的读取性能。
何时不嵌入
尽管在 Azure Cosmos DB 中,经验法则是将所有内容非规范化并将所有数据嵌入到单个项中,但这种方法可能会导致需要避免的情况。
以下面的 JSON 代码段为例。
{
"id": "1",
"name": "What's new in the coolest Cloud",
"summary": "A blog post by someone real famous",
"comments": [
{"id": 1, "author": "anon", "comment": "something useful, I'm sure"},
{"id": 2, "author": "bob", "comment": "wisdom from the interwebs"},
…
{"id": 100001, "author": "jane", "comment": "and on we go ..."},
…
{"id": 1000000001, "author": "angry", "comment": "blah angry blah angry"},
…
{"id": ∞ + 1, "author": "bored", "comment": "oh man, will this ever end?"},
]
}
如果我们以典型的博客或内容管理系统(CMS)为模型,那么这个示例可能展示了一个带有嵌入评论的帖子实体。 此示例中的问题是评论数组没有限制,这意味着任何单个发布的评论数都没有(实际)限制。 此设计可能会导致问题,因为项目的大小可以无限大,因此请避免此问题。
随着项大小的增加,大规模传输、读取和更新数据变得更加具有挑战性。
在此情况下,最好是考虑以下数据模型。
Post item:
{
"id": "1",
"name": "What's new in the coolest Cloud",
"summary": "A blog post by someone real famous",
"recentComments": [
{"id": 1, "author": "anon", "comment": "something useful, I'm sure"},
{"id": 2, "author": "bob", "comment": "wisdom from the interwebs"},
{"id": 3, "author": "jane", "comment": "....."}
]
}
Comment items:
[
{"id": 4, "postId": "1", "author": "anon", "comment": "more goodness"},
{"id": 5, "postId": "1", "author": "bob", "comment": "tails from the field"},
...
{"id": 99, "postId": "1", "author": "angry", "comment": "blah angry blah angry"},
{"id": 100, "postId": "2", "author": "anon", "comment": "yet more"},
...
{"id": 199, "postId": "2", "author": "bored", "comment": "will this ever end?"}
]
此模型为每个评论准备了一个条目,并在其中包含一个属性,该属性持有帖子标识符。 此模型允许帖子包含任意数量的评论并高效增长。 如果用户想要查看的内容不止是最近的评论,则需通过传递 postId(应为评论容器的分区键)查询此容器。
另一种嵌入数据不是好主意的情况是,当嵌入的数据在多个项目中频繁使用并且频繁变化时。
以下面的 JSON 代码段为例。
{
"id": "1",
"firstName": "Thomas",
"lastName": "Andersen",
"holdings": [
{
"numberHeld": 100,
"stock": { "symbol": "zbzb", "open": 1, "high": 2, "low": 0.5 }
},
{
"numberHeld": 50,
"stock": { "symbol": "xcxc", "open": 89, "high": 93.24, "low": 88.87 }
}
]
}
此示例可以表示人员的股票组合。 我们选择将股票信息嵌入每个项目组合文档中。 在一个相关数据经常变动的环境中,嵌入这些经常变化的数据就意味着你必须持续更新每个项目组合。 使用股票交易应用程序的示例,每次交易股票时,都会更新每个投资组合项目。
股票 zbzb 可以在一天内交易数百次,成千上万的用户可以在他们的投资组合中交易 zbzb 。 使用类似示例的数据模型,系统每天必须多次更新数千个项目组合文档,这无法很好地扩展。
参考数据
在许多情况下,嵌入数据非常有效,但在某些情况下,数据非规范化会导致问题多于其价值。 那么,你能做什么?
可以在文档数据库中的实体之间创建关系,而不仅仅是在关系数据库中创建关系。 在文档数据库中,一个项目可以包含与其他文档中的数据相关的信息。 Azure Cosmos DB 不是针对复杂关系而设计的,例如关系数据库中的关系,但项之间的简单链接是可能的,并且可能很有帮助。
在 JSON 中,我们使用前面提供的股票组合示例,但这次我们引用了投资组合中的股票项,而不是嵌入它。 这样,当库存品全天频繁更改时,唯一需要更新的项目是单个库存文档。
Person document:
{
"id": "1",
"firstName": "Thomas",
"lastName": "Andersen",
"holdings": [
{ "numberHeld": 100, "stockId": 1},
{ "numberHeld": 50, "stockId": 2}
]
}
Stock documents:
{
"id": "1",
"symbol": "zbzb",
"open": 1,
"high": 2,
"low": 0.5,
"vol": 11970000,
"mkt-cap": 42000000,
"pe": 5.89
},
{
"id": "2",
"symbol": "xcxc",
"open": 89,
"high": 93.24,
"low": 88.87,
"vol": 2970200,
"mkt-cap": 1005000,
"pe": 75.82
}
此方法的一个缺点是,应用程序必须发出多个数据库请求来获取有关人员投资组合中每个股票的信息。 此设计使写入数据更快,因为更新经常发生。 但是,它使读取或查询数据的速度变慢,这对于此系统来说不太重要。
注释
规范化的数据模型可能需要更多的往返访问服务器。
外键呢?
由于缺乏约束概念(例如外键),数据库不会验证文档中的任何文档间关系;这些链接实际上是“弱链接”。如果要确保引用的数据项实际存在,则需要在您的应用程序中执行此步骤,或者在 Azure Cosmos DB 上使用服务器端触发器或存储过程。
何时引用
通常在下列情况下使用规范化的数据模型:
- 表示“一对多”关系。
- 表示“多对多”关系。
- 相关数据频繁更改。
- 引用的数据可能没有限制。
注释
通常规范化能够提供更好的写入性能。
将关系数据存储在何处?
关系的发展有助于确定在哪个项目中存储引用。
让我们看看对出版商和书籍进行建模的 JSON。
Publisher document:
{
"id": "mspress",
"name": "Microsoft Press",
"books": [ 1, 2, 3, ..., 100, ..., 1000]
}
Book documents:
{"id": "1", "name": "Azure Cosmos DB 101" }
{"id": "2", "name": "Azure Cosmos DB for RDBMS Users" }
{"id": "3", "name": "Taking over China one JSON doc at a time" }
...
{"id": "100", "name": "Learn about Azure Cosmos DB" }
...
{"id": "1000", "name": "Deep Dive into Azure Cosmos DB" }
如果每publisher的书籍数量较小,并且增长有限,则将书籍引用存储在publisher项中可能很有用。 但是,如果每个publisher的书籍数量不受限制,则此数据模型将导致可变、不断增长的数组,如示例中publisher文档中所示。
切换结构会导致模型表示相同的数据,但避免了大型可变集合。
Publisher document:
{
"id": "mspress",
"name": "Microsoft Press"
}
Book documents:
{"id": "1","name": "Azure Cosmos DB 101", "pub-id": "mspress"}
{"id": "2","name": "Azure Cosmos DB for RDBMS Users", "pub-id": "mspress"}
{"id": "3","name": "Taking over China one JSON doc at a time", "pub-id": "mspress"}
...
{"id": "100","name": "Learn about Azure Cosmos DB", "pub-id": "mspress"}
...
{"id": "1000","name": "Deep Dive into Azure Cosmos DB", "pub-id": "mspress"}
在此示例中,Publisher文档不再包含无限制的集合。 相反,每本书籍都包含对其出版商的引用。
我该如何建模多对多关系?
在关系数据库中,多对多关系通常使用联接表建模。 这些关系只是将其他表中的记录联接在一起。
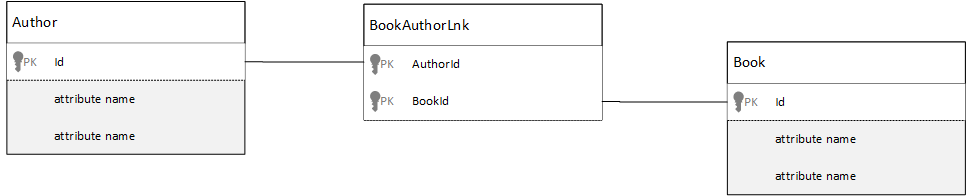
可能想要使用文档复制相同内容,并生成类似以下示例的数据模型。
Author documents:
{"id": "a1", "name": "Thomas Andersen" }
{"id": "a2", "name": "William Wakefield" }
Book documents:
{"id": "b1", "name": "Azure Cosmos DB 101" }
{"id": "b2", "name": "Azure Cosmos DB for RDBMS Users" }
{"id": "b3", "name": "Taking over China one JSON doc at a time" }
{"id": "b4", "name": "Learn about Azure Cosmos DB" }
{"id": "b5", "name": "Deep Dive into Azure Cosmos DB" }
Joining documents:
{"authorId": "a1", "bookId": "b1" }
{"authorId": "a2", "bookId": "b1" }
{"authorId": "a1", "bookId": "b2" }
{"authorId": "a1", "bookId": "b3" }
此方法有效,但加载作者及其书籍或书籍及其作者,始终至少需要两个额外的数据库查询。 对联接项进行一个查询,然后用另一个查询来获取实际要联接的项。
如果此联接只是将两个数据片段粘合在一起,那么为什么不将它完全删除? 请考虑以下示例。
Author documents:
{"id": "a1", "name": "Thomas Andersen", "books": ["b1", "b2", "b3"]}
{"id": "a2", "name": "William Wakefield", "books": ["b1", "b4"]}
Book documents:
{"id": "b1", "name": "Azure Cosmos DB 101", "authors": ["a1", "a2"]}
{"id": "b2", "name": "Azure Cosmos DB for RDBMS Users", "authors": ["a1"]}
{"id": "b3", "name": "Learn about Azure Cosmos DB", "authors": ["a1"]}
{"id": "b4", "name": "Deep Dive into Azure Cosmos DB", "authors": ["a2"]}
使用此模型,你可以通过查看作者的文档轻松查看作者撰写的书籍。 还可以通过检查书籍文档来查看哪些作者撰写了一本书。 无需使用单独的联接表或进行额外的查询。 通过此模型,应用程序可以更快、更简单地获取所需的数据。
从关系数据库迁移
如果要从 PostgreSQL 或其他关系数据库迁移,请计划重塑数据模型和查询。 在关系系统中,查询通常会跨表重新构造具有 JOIN 的业务实体。 在Azure Cosmos DB中,围绕应用程序读取和写入该数据的方式设计每个项。
了解 JOIN 语义
在Azure Cosmos DB中,JOIN 在单个项中工作,通常位于根项和嵌套数组之间。 它不会跨容器或跨不同的顶级项合并这些项。
- 跨表的关系型 JOIN 操作通常要求你根据访问模式重新建模数据,采用嵌入、引用或面向读取优化的投影等方法。
- 对一起读取的包含数据使用嵌入。
- 当相关实体较大、无边界或独立更新时,请使用引用。
有关 JOIN 语法详细信息,请参阅 Azure Cosmos DB 查询语言中的 JOIN。
应用常见的重组模式
转换规范化表时,请使用以下模式:
- 一对少量父子关系: 将子行嵌入父项中。
-
可无限增长的一对多: 将子项保留为独立项并存储引用,例如
parentId。 - 经常更新的子实体: 将经常变化的实体单独拆分出来,以避免对多个父项进行扇出式更新。
- 多对多: 将联接表替换为与查询模式匹配的引用数组或重复的读取优化投影。
调整查询
一种常见的关系模式将父表和子表联接起来:
SELECT c.customer_id, c.name, o.order_id, o.total
FROM Customers c
JOIN Orders o ON o.customer_id = c.customer_id
WHERE c.customer_id = 42
在Azure Cosmos DB中,如果在客户项中嵌入订单,请查询该单个项并加入嵌套数组:
SELECT c.id, c.name, o.id AS order_id, o.total
FROM c
JOIN o IN c.orders
WHERE c.id = "42" AND c.tenantId = "adventureworks"
如果订单数量较多或需要独立更新,请将其存储为单独的项,并通过 customerId 查询,而不是执行跨项 JOIN:
SELECT o.id, o.total, o.customerId
FROM o
WHERE o.customerId = "42"
若要使这些查询保持高效,请尽可能在筛选器中包含分区键。 对于单独的订单项,当常见的访问模式是“一个客户的所有订单”时, customerId 通常是一个很好的分区键,但仅在每个客户的订单适合单个逻辑分区的存储和吞吐量限制时选择它。 如果某些客户可以在没有限制的情况下增长或创建不成比例的高流量,请使用分层或综合分区策略,而不是将所有客户的订单放在一个逻辑分区中。
混合数据模型
我们探索嵌入(或非规范化)和引用(或规范化)数据。 每个方法都有好处,并涉及权衡。
它不总是非此即彼。 不要犹豫给事情增添一些变化。
根据应用程序的特定使用模式和工作负载,混合嵌入数据和引用的数据可能有意义。 此方法可以简化应用程序逻辑,减少服务器往返,并保持良好的性能。
请考虑以下 JSON。
Author documents:
{
"id": "a1",
"firstName": "Thomas",
"lastName": "Andersen",
"countOfBooks": 3,
"books": ["b1", "b2", "b3"],
"images": [
{"thumbnail": "https://....png"}
{"profile": "https://....png"}
{"large": "https://....png"}
]
},
{
"id": "a2",
"firstName": "William",
"lastName": "Wakefield",
"countOfBooks": 1,
"books": ["b1"],
"images": [
{"thumbnail": "https://....png"}
]
}
Book documents:
{
"id": "b1",
"name": "Azure Cosmos DB 101",
"authors": [
{"id": "a1", "name": "Thomas Andersen", "thumbnailUrl": "https://....png"},
{"id": "a2", "name": "William Wakefield", "thumbnailUrl": "https://....png"}
]
},
{
"id": "b2",
"name": "Azure Cosmos DB for RDBMS Users",
"authors": [
{"id": "a1", "name": "Thomas Andersen", "thumbnailUrl": "https://....png"},
]
}
在这里,我们(主要是)遵循嵌入模型,将其他实体的数据嵌入到上层文档中,同时引用其他数据。
如果查看书籍文档中的作者数组,会看到一些有趣的字段。 某个 id 字段是用来引用作者文档的字段,这是规范化模型中的标准做法,但是我们还使用了 name 和 thumbnailUrl。 我们可以仅使用 id,并允许应用程序通过“链接”从相应的作者项中检索所需的任何其他信息。然而,由于应用程序会在每本书中显示作者的姓名和缩略图,将一些数据从作者处非规范化可以减少列表中每本书的服务器往返次数。
如果作者的姓名发生更改或更新其照片,则需要更新他们出版的每本书。 但是,对于此应用程序,假设作者很少更改其名称,这种妥协是可接受的设计决策。
在此示例中,有 预先计算的聚合 值,用于在读取操作期间节省处理负担。 在此示例中,嵌入在作者项中的一些数据是在运行时计算的数据。 每次发布新书时,都会创建一个书籍项 ,countOfBooks 字段会根据特定作者存在的书籍文档数设置为计算值。 在读取频繁的系统中,这种优化效果很好,我们可以通过对写操作进行计算来优化读取操作。
由于 Azure Cosmos DB 支持多文档事务,因此可以生成具有预计算字段的模型。 由于此限制,许多 NoSQL 存储无法跨文档执行事务,因此提倡设计决策,例如“始终嵌入所有内容”。 使用 Azure Cosmos DB,可以在 ACID 事务中用服务器端触发器或存储过程插入书籍并更新作者。 现在,无需将所有内容嵌入一个项,只需确保数据保持一致。
区分不同的项类型
在某些情况下,你可能想要在同一集合中混合不同的项类型;如果希望多个相关文档位于同一 分区中,通常会出现此设计选择。 例如,可将书籍和书籍评论放入同一个集合,并按 bookId 将此集合分区。 在这种情况下,通常需要向文档添加一个字段,用于标识其类型以区分它们。
Book documents:
{
"id": "b1",
"name": "Azure Cosmos DB 101",
"bookId": "b1",
"type": "book"
}
Review documents:
{
"id": "r1",
"content": "This book is awesome",
"bookId": "b1",
"type": "review"
}
{
"id": "r2",
"content": "Best book ever!",
"bookId": "b1",
"type": "review"
}
版本控制与时态数据模式
根据保留要求、查询延迟目标和成本限制,在数据频繁更改并且需要查询较旧状态时,选择版本控制模式。
使用变更馈送的事件溯源
使用仅追加的事件模型,其中每次变更都会写入为一个新的事件项。 使用有关 更改源设计模式 的指导,将当前状态映射到一个或多个物化视图中。
- 存储成本: 随着时间的推移,由于每个突变都保留为事件,因此会更高。
- 查询复杂性:除非维护了读优化投影,否则时间点重建的查询复杂度会更高。
- 写入吞吐量: 高于就地覆盖,因为每次变更都会带来一次额外写入,但写入仍保持简单且可扩展。
快照与增量模式
存储实体的定期完整快照,并存储快照之间的增量差异。 若要读取某个历史版本,请加载最接近的快照,然后依次应用之后的增量,直到目标时间戳。
- 存储成本: 低于将每个版本保留为完整副本,尤其是对于更改较小的大型项目。
- 查询复杂度: 中等到较高,因为读取历史数据可能需要回放多个增量。
- 写入吞吐量: 适中,因为按计划频繁写入小型增量和较大的快照。
基于 TTL 的版本过期
使用 存留时间(TTL) 可在无限期保留当前版本的同时,自动清理较旧版本。 一种常见的方法是将容器 TTL 设置为 -1,并且仅将 ttl 分配给历史版本项。
- 存储成本: 由于过期版本会被自动删除,因此存储成本可预测且有上限。
- 查询复杂性: 低到中等,具体取决于保留时段是否足以满足审核或重播需求。
- 写入吞吐量: 与所选的版本化模型类似,另外还有随版本过期而进行的后台删除操作。
用于历史访问的分析存储
使 分析存储 能够在同步列存储上运行大型历史查询和趋势查询,而不会影响操作容器上的事务查询性能。 分析存储会反映所持久保存的数据,但当项被覆盖时,它不会创建先前版本。 对于按版本或时间点读取,请先存储只追加事件或快照,然后通过分析存储查询该时态数据集。
- 存储成本: 会产生分析存储费用,但可减少历史报表的事务性 RU 消耗。
- 查询复杂性: 对于远程分析而言较低,因为列式扫描和聚合已针对此工作负荷进行优化。
- 写入吞吐量: 由于自动管理分析同步,因此对事务写入的直接影响最小。
在实践中,团队通常会合并这些模式。 例如,可使用事件溯源或快照来实现保留语义,使用 TTL 进行生命周期控制,并使用分析存储来进行经济高效的历史分析。
Takeaways
本文中最大的要点是,无架构方案中的数据建模与以往一样重要。
就像有多种方法可在屏幕上表示一个数据片段一样,数据的建模方法也不会只有一种。 你需要了解应用程序及其生成、使用和处理数据的方式。 通过应用此处介绍的准则,可以创建一个模型,以满足应用程序的即时需求。 应用程序更改时,使用无架构数据库的灵活性轻松调整和改进数据模型。