重要
此功能目前以预览版提供,不提供服务级别协议。 目前,不建议在生产环境中使用预览功能。 此预览版的某些功能不受支持或可能具有功能约束。 有关详细信息,请参阅 Azure 预览版的补充使用条款。
在本指南中,您将为 Microsoft Fabric 工作区启用 Azure Cosmos DB 群集分析。
本指南将向您介绍如何为 Azure Data Lake Storage 帐户启用 Azure Cosmos DB 群组分析功能。
先决条件
现有的 Azure Cosmos DB 机队
如果没有现有 机队,请创建新的机队。
舰队分析仅支持配置了舰队的 Azure Cosmos DB for NoSQL 帐户。
现有 Microsoft Fabric 工作区
工作区必须使用 OneLake 作为默认存储位置。
工作区必须由许可或试用 Fabric 容量提供支持。
注释
建议为 Fleet Analytics 创建专用 Fabric 工作区,因为与该功能关联的服务主体需要参与者访问整个工作区。
与 Azure Data Lake Storage 兼容的现有 Azure 存储帐户(Gen2)
- 必须在创建帐户时启用 分层命名空间 功能。
启用机群分析
首先,配置车队分析所需的资源。
登录到 Azure 门户(https://portal.azure.cn)。
导航到现有的 Azure Cosmos DB 舰队。
在机群的页面上,在资源菜单的“监控”部分选择“机群分析”。
然后选择 “添加目标”。
在 车队分析 对话框中,选择 发送到 Fabric 工作区。 然后,选择现有的 Fabric 工作区,选择现有的 OneLake 湖屋,然后保存目标。
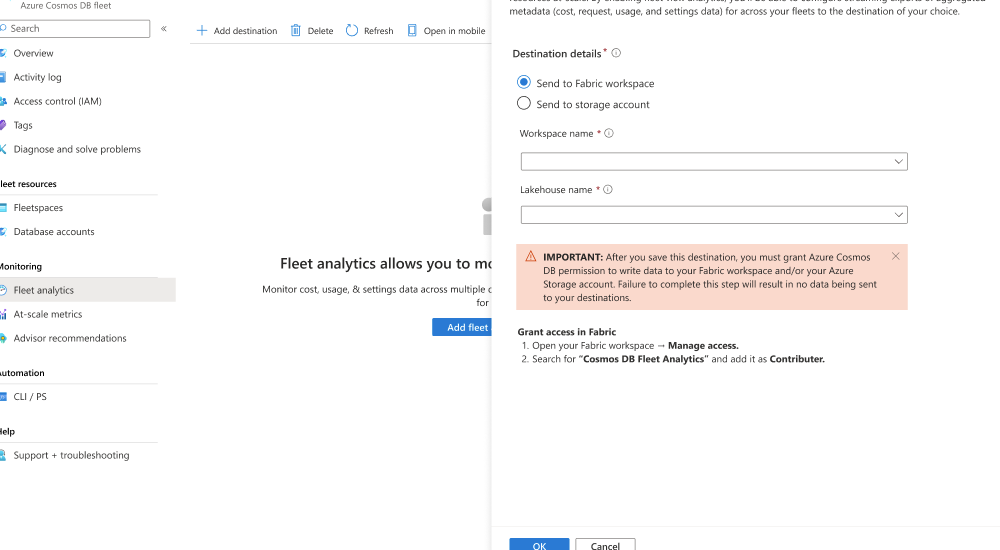
在 Microsoft Fabric 门户中导航到 Fabric 工作区。
在工作区的“管理”部分中,通过搜索共享的“Cosmos DB 舰队分析”服务主体,将用于舰队分析的主体添加为“参与者”角色。

重要
未能完成此步骤会导致数据未写入目标 Fabric 工作区。
保存所做更改。
登录到 Azure 门户(https://portal.azure.cn)。
导航到现有的 Azure Cosmos DB 舰队。
在机群的页面上,在资源菜单的“监控”部分选择“机群分析”。
然后选择 “添加目标”。
在 “舰队分析 ”对话框中,选择“ 发送到存储帐户”。 然后,选择现有的 Azure 存储帐户,选择现有容器,然后 保存 目标。
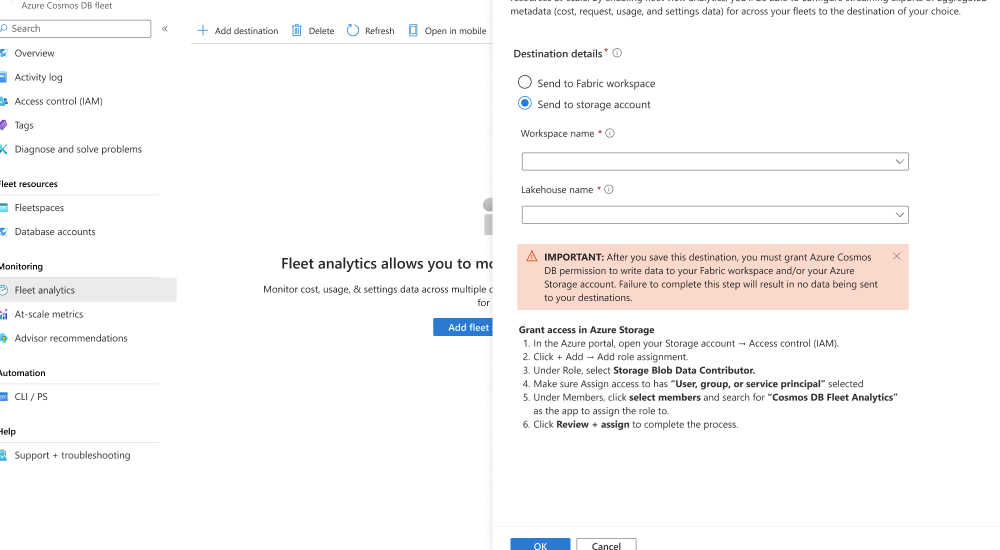
导航到 Azure 存储帐户。 然后,导航到 “访问控制”(IAM) 页。
选择 “添加角色分配 ”菜单选项。
在 “添加角色分配 ”页上,选择 “存储 Blob 参与者 ”角色,以授予向现有帐户贡献 Blob 的权限。
现在,请使用 “+ 选择成员 ”选项。 在对话框中,搜索并选择共享 Cosmos DB Fleet Analytics 服务主体。

重要
未能完成此步骤会导致数据未写入目标 Azure 存储帐户。
查看 + 分配角色分配。
查询和可视化数据
在星型架构设计中,检索详细信息通常需要按照标准最佳做法将事实数据表与其相关维度表联接。 本部分介绍使用 Microsoft Fabric 查询和可视化数据的步骤。
打开你的 Fabric 工作区。
导航到现有的 OneLake 资源。
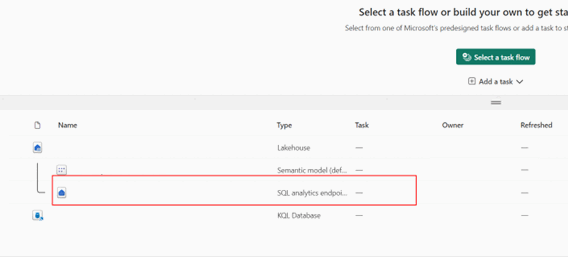
在 SQL 终结点资源管理器中,选择任何表并运行
SELECT TOP 100查询以快速观察数据。 可以在上下文菜单中找到此查询。
小窍门
或者,运行以下查询以查看帐户级详细信息:
SELECT TOP (100) [Timestamp], [ResourceId], [FleetId], [DefaultConsistencyLevel], [IsSynapseLinkEnabled], [IsFreeTierEnabled], [IsBurstEnabled], [BackupMode], [BackupStrategy], [BackupRedundancy], [BackupIntervalInMinutes], [BackupRetentionIntervalInHours], [TotalRUPerSecLimit], [APISettings], [AccountKeySettings], [LastDateAnyAccountKeyRotated] FROM [FactAccountHourly]观察查询的结果。 请注意,你仅引用了
ResourceId字段。 仅使用此查询的结果,无法确定单个行的确切数据库或容器。运行此示例查询,将
DimResource和FactRequestHourly表联接起来,以按事务查找最活跃的前100个帐户。SELECT TOP 100 DR.[SubscriptionId], DR.[AccountName], DR.[ResourceGroup], SUM(FRH.[TotalRequestCount]) AS sum_total_requests FROM [FactRequestHourly] FRH JOIN [DimResource] DR ON FRH.[ResourceId] = DR.[ResourceId] WHERE FRH.[Timestamp] >= DATEADD(DAY, -7, GETDATE()) -- Filter for the last 7 days AND ResourceName IN ('Document', 'StoredProcedure') -- Filter for Dataplane Operations GROUP BY DR.[AccountName], DR.[SubscriptionId], DR.[ResourceGroup] ORDER BY sum_total_requests DESC; -- Order by total requests in descending order运行此查询, 按存储查找前 100 个最大帐户。
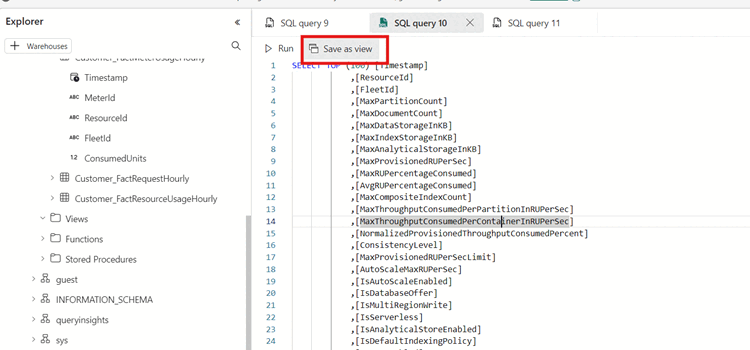
SELECT TOP 100 DR.[SubscriptionId], DR.[AccountName], MAX(FRH.[MaxDataStorageInKB] / (1024.0 * 1024.0)) AS DataUsageInGB, MAX(FRH.[MaxIndexStorageInKB] / (1024.0 * 1024.0)) AS IndexUsageInGB, MAX( FRH.[MaxDataStorageInKB] / (1024.0 * 1024.0) + FRH.[MaxIndexStorageInKB] / (1024.0 * 1024.0) ) AS StorageInGB FROM [FactResourceUsageHourly] FRH JOIN [DimResource] DR ON FRH.[ResourceId] = DR.[ResourceId] WHERE FRH.[Timestamp] >= DATEADD(DAY, -1, GETDATE()) -- Filter for the last 1 day GROUP BY DR.[AccountName], DR.[SubscriptionId] ORDER BY StorageInGB DESC; -- Order by total storage usage现在,通过打开上下文菜单并选择“ 另存为”视图,在数据上创建视图。 为视图指定唯一的名称,然后选择“ 确定”。
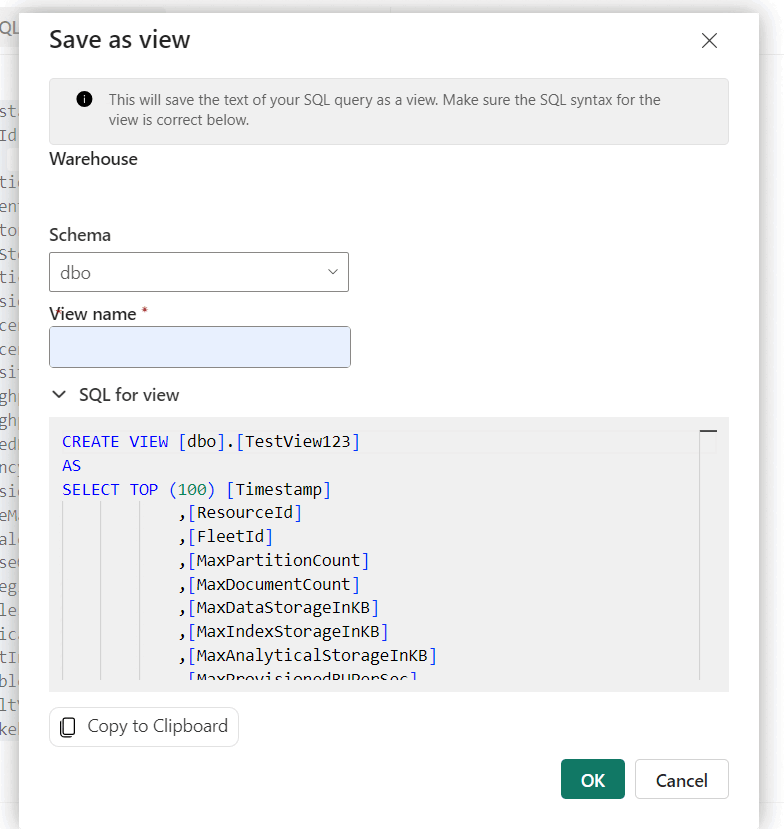
小窍门
或者,直接使用此查询创建视图:
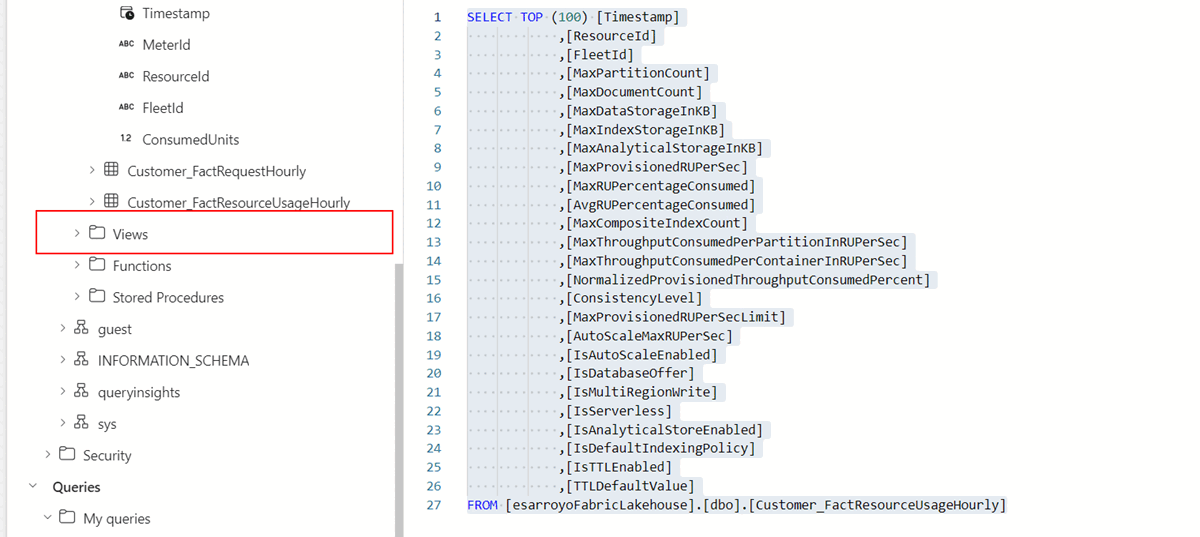
CREATE VIEW [MostActiveCustomers] AS SELECT a.ResourceId AS UsageResourceId, a.Timestamp, a.MeterId, a.FleetId, a.ConsumedUnits, b.ResourceId AS ResourceDetailId FROM FactMeterUsageHourly a INNER JOIN DimResource b ON a.ResourceId = b.ResourceId导航到终结点“视图”文件夹中新建的视图。
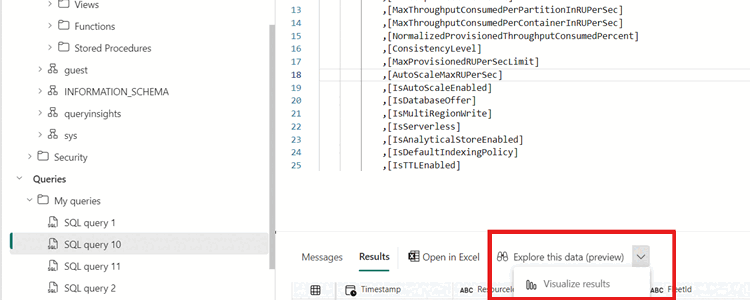
导航到最近创建的视图(或查询),然后选择 “探索此数据(预览)”,然后选择 “可视化结果”。
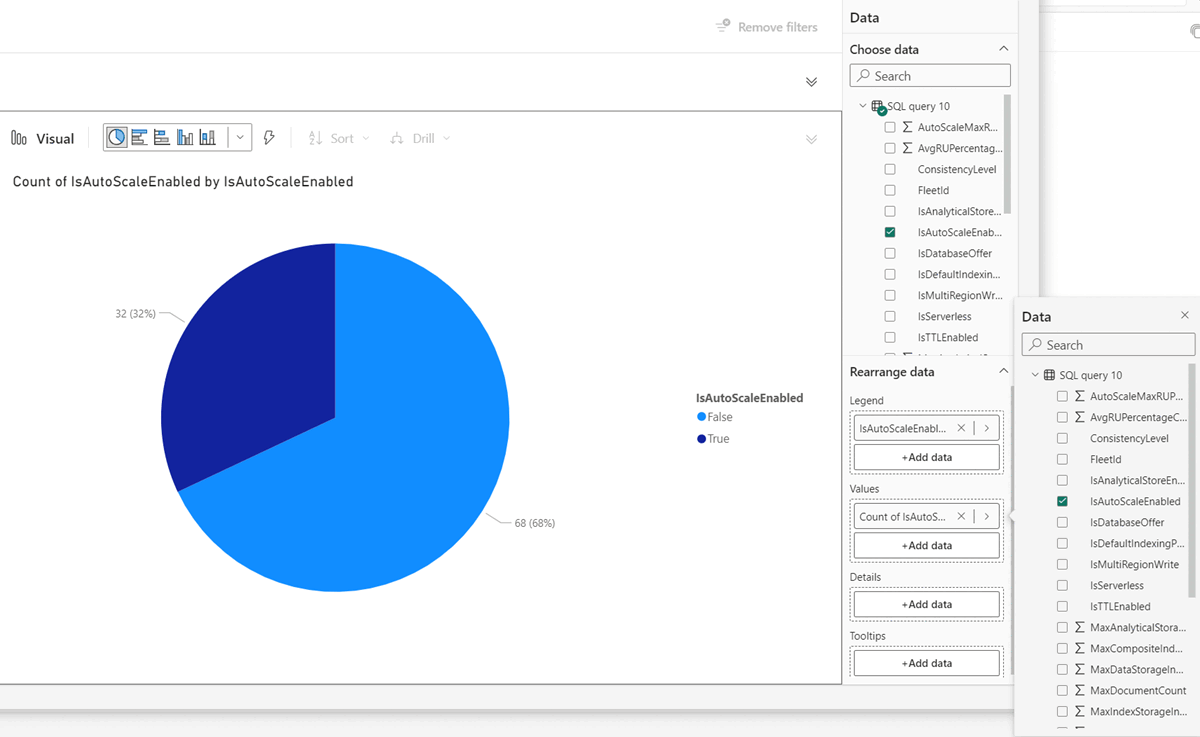
在 Power BI 登陆页上,为方案创建相关视觉对象。 例如,可以显示已启用 自动缩放 功能的 Azure Cosmos DB 工作负荷的百分比。
本部分逐步讲解如何创建和查询从 Azure 存储(ADLS)或 Azure Databricks 中存储的数据加载的表或数据帧。 本部分使用包含 Python 和 SQL 单元格的 Notebook 来连接 Apache Spark。
首先,定义针对 [目标实体] 的 Azure 存储帐户配置
# Define storage configuration container_name = "<azure-storage-container-name>" account_name = "<azure-storage-account-name>" base_url = f"abfss://{container_name}@{account_name}.dfs.core.chinacloudapi.cn" source_path = f"{base_url}/FactResourceUsageHourly"以表的形式创建数据。 通过删除和重新创建 表,从外部源(Azure 存储 - ADLS)重新加载和刷新数据
fleet_data。table_name = "fleet_data" # Drop the table if it exists spark.sql(f"DROP TABLE IF EXISTS {table_name}") # Create the table spark.sql(f""" CREATE TABLE {table_name} USING delta LOCATION '{source_path}' """)查询表
fleet_data并显示结果。# Query and display the table df = spark.sql(f"SELECT * FROM {table_name}") display(df)定义要创建用于处理机群分析数据的额外表的完整列表。
# Table names and folder paths (assumed to match) tables = [ "DimResource", "DimMeter", "FactResourceUsageHourly", "FactAccountHourly", "FactRequestHourly", "FactMeterUsageHourly" ] # Drop and recreate each table for table in tables: spark.sql(f"DROP TABLE IF EXISTS {table}") spark.sql(f""" CREATE TABLE {table} USING delta LOCATION '{base_url}/{table}' """)使用这些表中的任何一个运行查询。 例如,此查询交易次数查找前 100 个最活跃帐户。
SELECT DR.SubscriptionId, DR.AccountName, DR.ResourceGroup, SUM(FRH.TotalRequestCount) AS sum_total_requests FROM FactRequestHourly FRH JOIN DimResource DR ON FRH.ResourceId = DR.ResourceId WHERE FRH.Timestamp >= DATE_SUB(CURRENT_DATE(), 7) -- Filter for the last 7 days AND FRH.ResourceName IN ('Document', 'StoredProcedure') -- Filter for Dataplane Operations GROUP BY DR.AccountName, DR.SubscriptionId, DR.ResourceGroup ORDER BY sum_total_requests DESC LIMIT 100; -- Limit to top 100 results运行此查询, 按存储查找前 100 个最大帐户。
SELECT DR.SubscriptionId, DR.AccountName, MAX(FRH.MaxDataStorageInKB / (1024.0 * 1024.0)) AS DataUsageInGB, MAX(FRH.MaxIndexStorageInKB / (1024.0 * 1024.0)) AS IndexUsageInGB, MAX( FRH.MaxDataStorageInKB / (1024.0 * 1024.0) + FRH.MaxIndexStorageInKB / (1024.0 * 1024.0) ) AS StorageInGB FROM FactResourceUsageHourly FRH JOIN DimResource DR ON FRH.ResourceId = DR.ResourceId WHERE FRH.Timestamp >= DATE_SUB(CURRENT_DATE(), 1) -- Filter for the last 1 day GROUP BY DR.AccountName, DR.SubscriptionId ORDER BY StorageInGB DESC LIMIT 100; -- Limit to top 100 results