Azure Cosmos DB for PostgreSQL 中的表共置
适用对象:![]() Azure Cosmos DB for PostgreSQL(由 PostgreSQL 的 Citus 数据库扩展提供支持)
Azure Cosmos DB for PostgreSQL(由 PostgreSQL 的 Citus 数据库扩展提供支持)
共置是指将相关信息一起存储在相同节点上。 当提供了所有必要数据时,查询可以快速运行,而且不会产生任何网络流量。 将相关数据共置在不同节点上可使查询在每个节点上高效地并行运行。
哈希分布式表的数据共置
在 Azure Cosmos DB for PostgreSQL 中,如果分布列中值的哈希处于某个分片的哈希范围内,则行将存储在该分片中。 具有相同哈希范围的分片始终放置在同一节点上。 分布列值相等的行始终位于跨表的同一节点上。 哈希分布式表概念也称为基于行的分片。 在基于架构的分片中,分布式架构中的表始终是并置的。
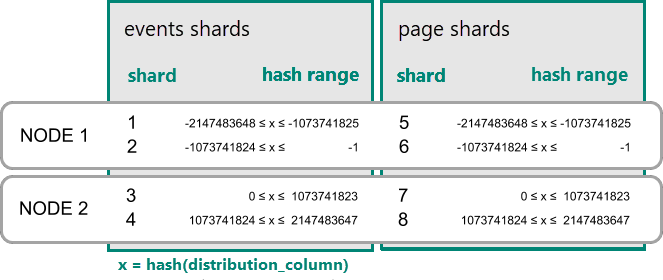
实用的共置示例
假设下表可能是某个多租户 Web Analytics SaaS 的一部分:
CREATE TABLE event (
tenant_id int,
event_id bigint,
page_id int,
payload jsonb,
primary key (tenant_id, event_id)
);
CREATE TABLE page (
tenant_id int,
page_id int,
path text,
primary key (tenant_id, page_id)
);
现在,我们需要应答面向客户的仪表板可能发出的查询。 一个示例查询是“返回租户 6 中以‘/blog’开头的所有页在过去一周的访问次数。”
如果我们的数据在单个 PostgreSQL 服务器中,则我们可以使用 SQL 提供的丰富的关系操作集轻松表达我们的查询:
SELECT page_id, count(event_id)
FROM
page
LEFT JOIN (
SELECT * FROM event
WHERE (payload->>'time')::timestamptz >= now() - interval '1 week'
) recent
USING (tenant_id, page_id)
WHERE tenant_id = 6 AND path LIKE '/blog%'
GROUP BY page_id;
只要此查询的工作集能够装入内存,则单服务器表就是一个适当的解决方案。 让我们考虑使用 Azure Cosmos DB for PostgreSQL 缩放数据模型的可能性。
按 ID 分布表
随着租户数量以及为每个租户存储的数据不断增长,单服务器查询将开始减慢速度。 工作集不再可以装入内存,而 CPU 成了瓶颈。
在这种情况下,我们可以使用 Azure Cosmos DB for PostgreSQL 将数据分片到许多节点。 决定分片时,需要做出的第一项、也是最重要的选择是分布列。 让我们从最原始的选择着手:对事件表使用 event_id,对 page 表使用 page_id:
-- naively use event_id and page_id as distribution columns
SELECT create_distributed_table('event', 'event_id');
SELECT create_distributed_table('page', 'page_id');
将数据分散到不同的辅助角色后,我们无法像在单个 PostgreSQL 节点上那样执行联接操作, 而是需要发出两个查询:
-- (Q1) get the relevant page_ids
SELECT page_id FROM page WHERE path LIKE '/blog%' AND tenant_id = 6;
-- (Q2) get the counts
SELECT page_id, count(*) AS count
FROM event
WHERE page_id IN (/*…page IDs from first query…*/)
AND tenant_id = 6
AND (payload->>'time')::date >= now() - interval '1 week'
GROUP BY page_id ORDER BY count DESC LIMIT 10;
然后,应用程序需要合并两个步骤的结果。
运行查询必须查阅分散在节点之间的分片中的数据。
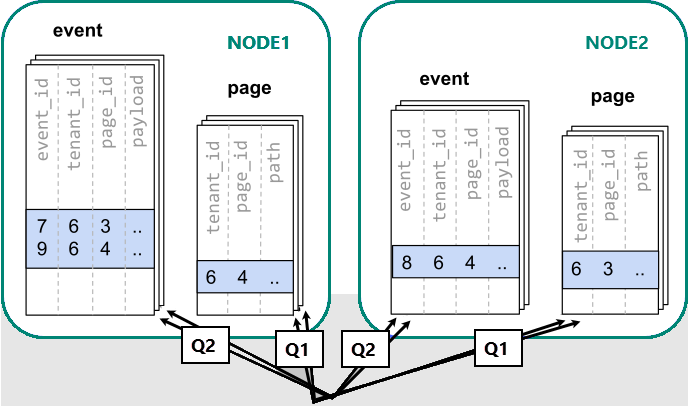
在这种情况下,数据分布会在以下方面造成严重的弊端:
- 查询每个分片并运行多个查询所产生的开销。
- 向客户端返回大量行的查询 1 的开销。
- 查询 2 变得庞大。
- 在多个步骤中编写查询需要在应用程序中进行更改。
数据是分散的,因此可以并行化查询。 仅当查询执行的工作量大大超过查询许多分片所产生的开销时,这种做法才有利。
按租户分布表
在 Azure Cosmos DB for PostgreSQL 中,可以保证具有相同分布列值的行位于同一节点上。 我们可以使用 tenant_id 作为分布列,从头开始创建表。
-- co-locate tables by using a common distribution column
SELECT create_distributed_table('event', 'tenant_id');
SELECT create_distributed_table('page', 'tenant_id', colocate_with => 'event');
现在,Azure Cosmos DB for PostgreSQL 可以应答未经修改的原始单服务器查询(查询 1):
SELECT page_id, count(event_id)
FROM
page
LEFT JOIN (
SELECT * FROM event
WHERE (payload->>'time')::timestamptz >= now() - interval '1 week'
) recent
USING (tenant_id, page_id)
WHERE tenant_id = 6 AND path LIKE '/blog%'
GROUP BY page_id;
由于根据 tenant_id 执行了筛选和联接,Azure Cosmos DB for PostgreSQL 知道可以使用包含该特定租户的数据的共置分片集来应答整个查询。 单个 PostgreSQL 节点可以通过单个步骤应答查询。
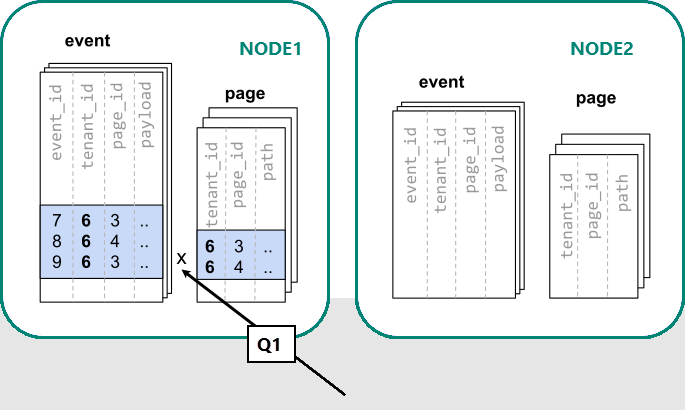
在某些情况下,必须更改查询和表架构,以在唯一约束和联接条件中包含租户 ID。 通常可以直接进行这种更改。
后续步骤
- 参阅多租户教程了解租户数据的共置方式。