Azure Cosmos DB for PostgreSQL 中的模型实时分析应用
适用对象:![]() Azure Cosmos DB for PostgreSQL(由 PostgreSQL 的 Citus 数据库扩展提供支持)
Azure Cosmos DB for PostgreSQL(由 PostgreSQL 的 Citus 数据库扩展提供支持)
使用分片键并置大型表
若要为实时操作分析应用程序选取分片键,请遵循以下准则:
- 选择大型表上常见的列
- 选择属于数据中的自然维度或属于应用程序的核心部分的列。 以下是一些示例:
- 在金融界,分析安全趋势的应用程序可能会使用
security_id。 - 在要分析网站使用情况指标的用户分析工作负荷中,
user_id将是一个很好的分布列
- 在金融界,分析安全趋势的应用程序可能会使用
通过并置大型表,可以并行将 SQL 查询推送到工作器节点。 向下推送查询可避免通过网络在节点之间混排数据。 可以有效地执行 JOIN、聚合、汇总、筛选器、LIMIT 等操作。
若要可视化并置表上的并行分布式查询,请考虑下图:
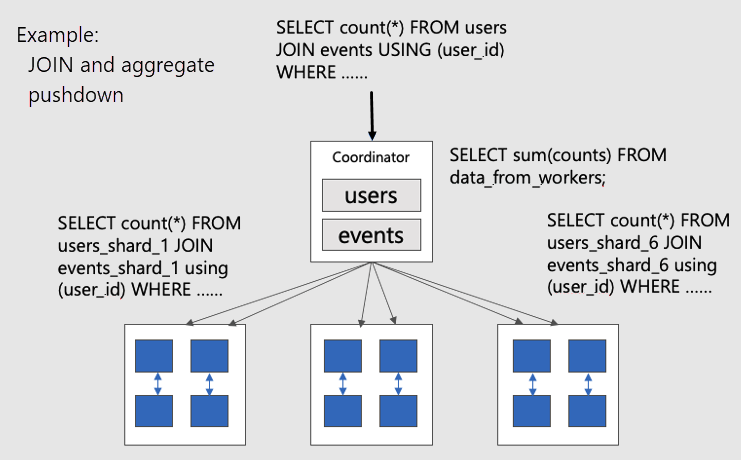
表 users 和 events 表都是依据 user_id 分片的,因此同一用户 ID 的相关行放置在同一工作器节点上。 无需在辅助角色之间拉取信息即可发生 SQL JOIN。
适用于实时应用的最佳数据模型
让我们继续学习分析用户网站访问和指标的应用程序示例。 有两个“事实”表(用户和事件)以及其他较小的“维度”表。
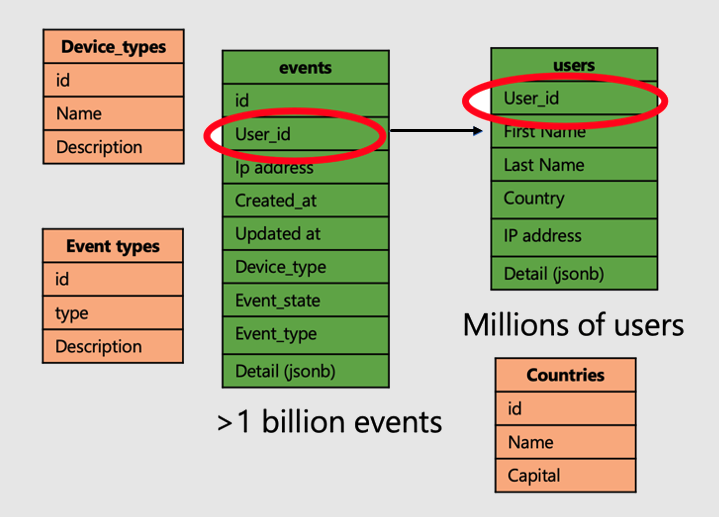
要在 Azure Cosmos DB for PostgreSQL 上应用分布式表的强大功能,请执行以下步骤:
- 在公用列上分布大型事实数据表。 在本例中,用户和事件分布于
user_id上。 - 将小型/维度表(
device_types、countries和 `event_types)标记为引用表。 - 请务必在分布式表的主键、唯一和外键约束中包含分布列。 包括列可能需要使键组合。 需要更新引用表的键。
- 联接大型分布式表时,请务必使用分片键进行联接。
-- Distribute the fact tables
SELECT create_distributed_table('users', 'user_id');
SELECT create_distributed_table('products', 'user_id', colocate_with => 'users');
-- Turn dimension tables into reference tables, with synchronized copies
-- maintained on every worker node
SELECT create_reference_table('countries');
-- similarly for device_types and event_types...
后续步骤
现在,我们已探讨完可缩放应用的数据建模。 下一步是使用所选的编程语言连接和查询数据库。