微服务
本教程使用 Azure Cosmos DB for PostgreSQL 作为多个微服务的存储后端,演示了此类群集的示例设置和基本操作。 了解如何:
- 创建群集
- 为微服务创建角色
- 使用 psql 实用工具创建角色和分布式架构
- 为示例服务创建表
- 配置 服务
- 运行服务
- 浏览数据库
适用对象:![]() Azure Cosmos DB for PostgreSQL(由 PostgreSQL 的 Citus 数据库扩展提供支持)
Azure Cosmos DB for PostgreSQL(由 PostgreSQL 的 Citus 数据库扩展提供支持)
先决条件
如果没有 Azure 订阅,请在开始前创建一个试用版订阅帐户。
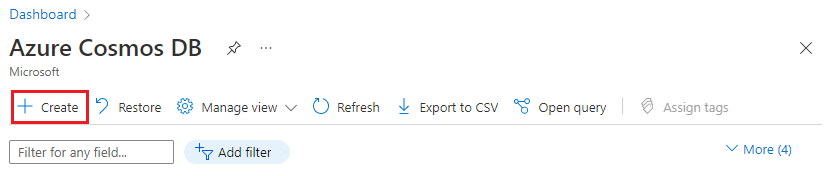
创建群集
登录到 Azure 门户,并按照以下步骤创建 Azure Cosmos DB for PostgreSQL 群集:
转到 Azure 门户中的创建 Azure Cosmos DB for PostgreSQL 群集。
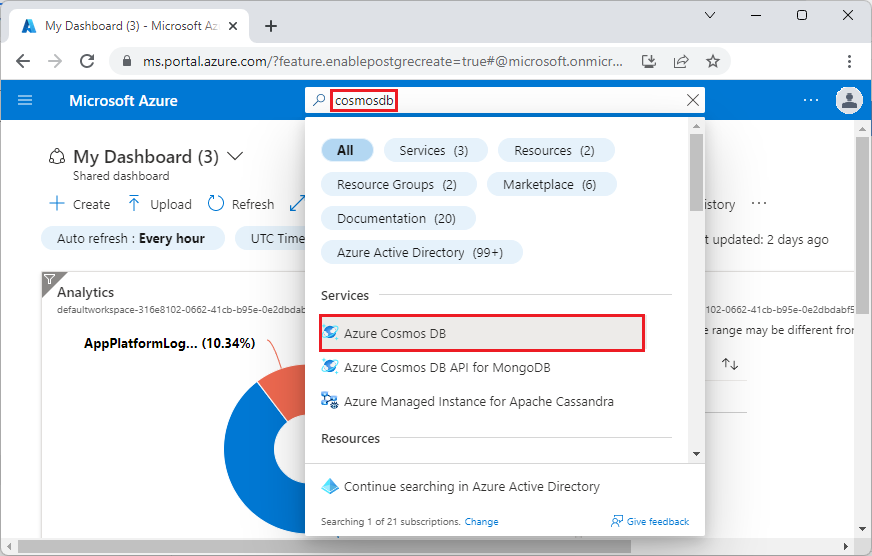
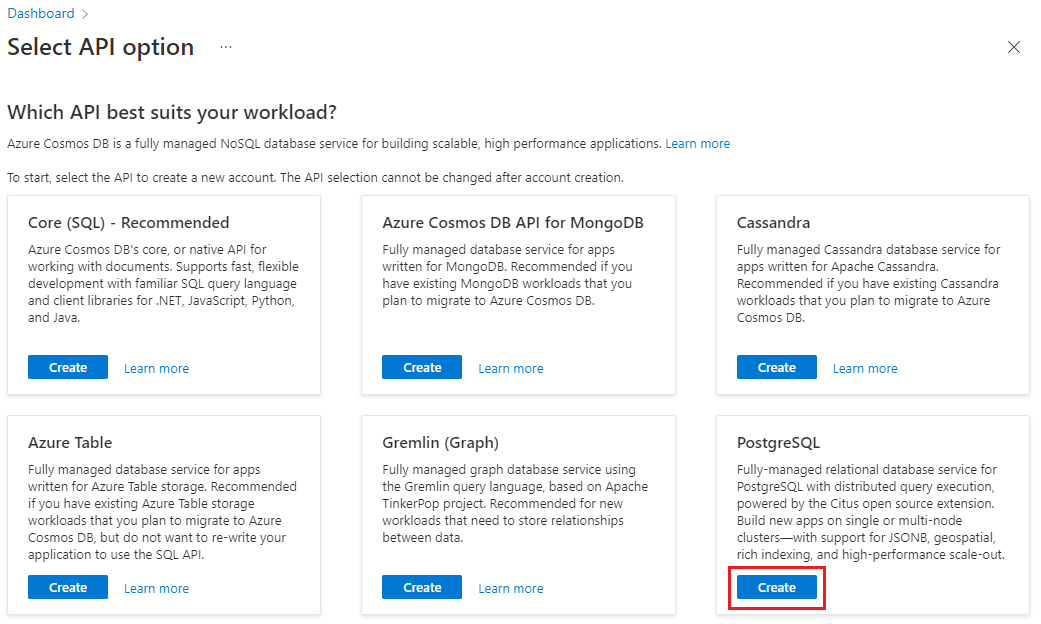
在“创建适用于 PostgreSQL 的 Azure Cosmos DB 群集”窗体上:
在“基本信息”选项卡上填写相关信息。
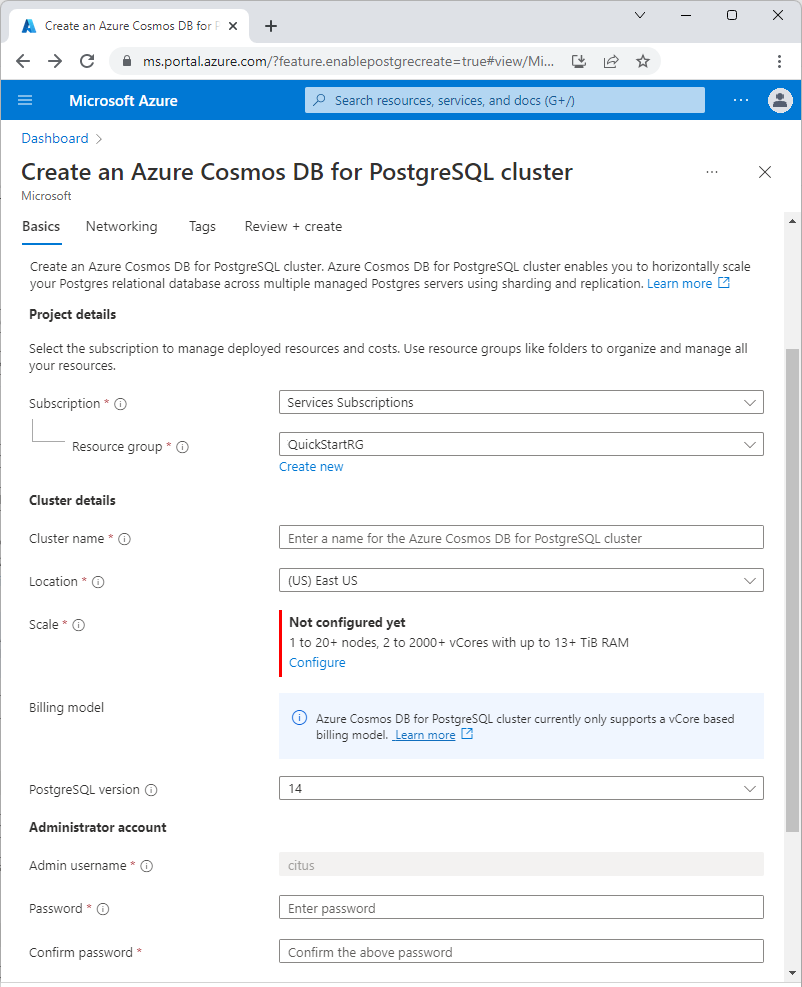
大多数选项都是一目了然的,但请记住:
- 群集名称决定应用程序用来进行连接的 DNS 名称(采用
<node-qualifier>-<clustername>.<uniqueID>.postgres.database.chinacloudapi.cn格式)。 - 可以选择主要 PostgreSQL 版本,例如 15。 Azure Cosmos DB for PostgreSQL 始终支持所选主要 Postgres 版本的最新 Citus 版本。
- 管理员用户名必须是值
citus。 - 可以将数据库名称保留为默认值“citus”,也可以定义唯一的数据库名称。 预配群集后无法重命名数据库。
- 群集名称决定应用程序用来进行连接的 DNS 名称(采用
在屏幕底部选择“下一步: 网络”。
在“网络”屏幕中,选择“允许从 Azure 内的 Azure 服务和资源公开访问此群集”。
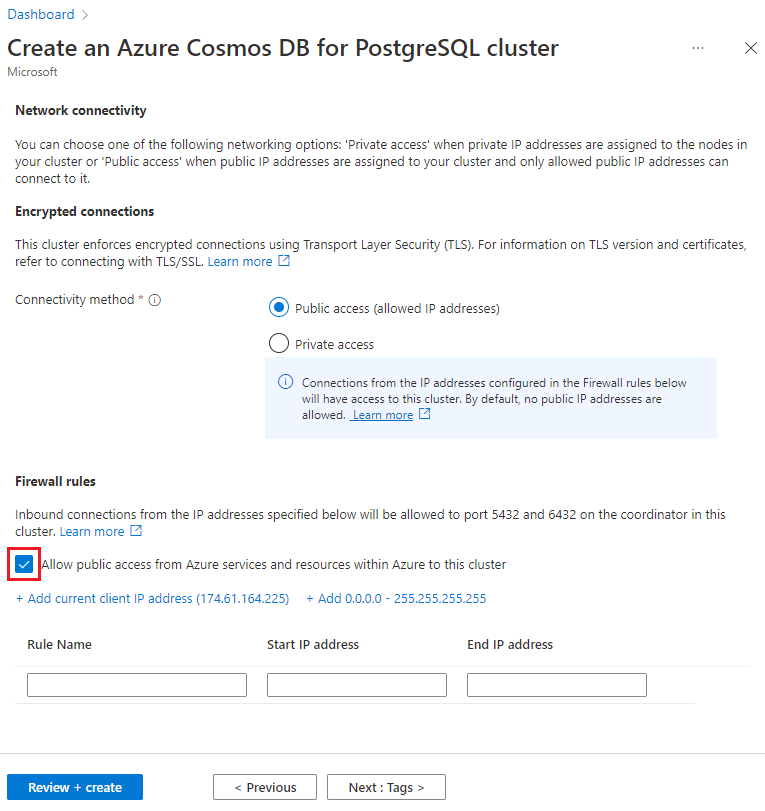
选择“查看 + 创建”,在验证通过时,选择“创建”以创建群集。
预配需要数分钟。 页面会重定向,以监视部署。 当状态从“部署进行中”更改为“部署已完成”时,请选择“转到资源”。
为微服务创建角色
分布式架构可在 Azure Cosmos DB for PostgreSQL 群集中重新定位。 系统可以在可用节点中将其重新平衡为整个单元,从而可以有效地共享资源,而无需手动分配。
根据设计,微服务拥有存储层,我们不对它们创建和存储的表和数据的类型做出任何假设。 我们为每个服务提供一个架构,并假定它们使用不同的 ROLE 连接到数据库。 当用户连接时,其角色名称将放在 search_path 的开头,因此,如果角色与架构名称匹配,则不需要任何应用程序更改来设置正确的 search_path。
在本示例中,我们使用三个服务:
- user
- time
- ping
按照描述如何创建用户角色的步骤操作,并为每个服务创建以下角色:
userservicetimeservicepingservice
使用 psql 实用工具创建分布式架构
使用 psql 连接到适用于 PostgreSQL 的 Azure Cosmos DB 后,可以完成一些基本任务。
可通过两种方式在 Azure Cosmos DB for PostgreSQL 中分发架构:
通过调用 citus_schema_distribute(schema_name) 函数手动操作:
CREATE SCHEMA AUTHORIZATION userservice;
CREATE SCHEMA AUTHORIZATION timeservice;
CREATE SCHEMA AUTHORIZATION pingservice;
SELECT citus_schema_distribute('userservice');
SELECT citus_schema_distribute('timeservice');
SELECT citus_schema_distribute('pingservice');
此方法还允许将现有常规架构转换为分布式架构。
注意
只能分发不包含分布式表和引用表的架构。
替代方法是启用 citus.enable_schema_based_sharding 配置变量:
SET citus.enable_schema_based_sharding TO ON;
CREATE SCHEMA AUTHORIZATION userservice;
CREATE SCHEMA AUTHORIZATION timeservice;
CREATE SCHEMA AUTHORIZATION pingservice;
可以针对当前会话更改变量,也可以在协调器节点参数中永久更改。 将参数设置为 ON 时,默认情况下会分发所有创建的架构。
可以通过运行以下命令列出当前的分布式架构:
select * from citus_schemas;
schema_name | colocation_id | schema_size | schema_owner
-------------+---------------+-------------+--------------
userservice | 5 | 0 bytes | userservice
timeservice | 6 | 0 bytes | timeservice
pingservice | 7 | 0 bytes | pingservice
(3 rows)
为示例服务创建表
现在,需要连接到每个微服务的 Azure Cosmos DB for PostgreSQL。 可以使用 \c 命令交换现有 psql 实例中的用户。
\c citus userservice
CREATE TABLE users (
id SERIAL PRIMARY KEY,
name VARCHAR(255) NOT NULL,
email VARCHAR(255) NOT NULL
);
\c citus timeservice
CREATE TABLE query_details (
id SERIAL PRIMARY KEY,
ip_address INET NOT NULL,
query_time TIMESTAMP NOT NULL
);
\c citus pingservice
CREATE TABLE ping_results (
id SERIAL PRIMARY KEY,
host VARCHAR(255) NOT NULL,
result TEXT NOT NULL
);
配置 服务
在本教程中,我们使用一组简单的服务。 可以通过克隆此公共存储库来获取它们:
git clone https://github.com/citusdata/citus-example-microservices.git
$ tree
.
├── LICENSE
├── README.md
├── ping
│ ├── app.py
│ ├── ping.sql
│ └── requirements.txt
├── time
│ ├── app.py
│ ├── requirements.txt
│ └── time.sql
└── user
├── app.py
├── requirements.txt
└── user.sql
但是,在运行服务之前,请编辑 user/app.py、ping/app.py 和 time/app.py 文件,它们为 Azure Cosmos DB for PostgreSQL 群集提供 连接配置:
# Database configuration
db_config = {
'host': 'c-EXAMPLE.EXAMPLE.postgres.cosmos.azure.cn',
'database': 'citus',
'password': 'SECRET',
'user': 'pingservice',
'port': 5432
}
进行更改后,保存所有修改的文件,然后继续执行运行服务的下一步。
运行服务
更改为每个应用目录,并在各自的 python env 中运行它们。
cd user
pipenv install
pipenv shell
python app.py
对时间和 ping 服务重复命令,之后可以使用 API。
创建一些用户:
curl -X POST -H "Content-Type: application/json" -d '[
{"name": "John Doe", "email": "john@example.com"},
{"name": "Jane Smith", "email": "jane@example.com"},
{"name": "Mike Johnson", "email": "mike@example.com"},
{"name": "Emily Davis", "email": "emily@example.com"},
{"name": "David Wilson", "email": "david@example.com"},
{"name": "Sarah Thompson", "email": "sarah@example.com"},
{"name": "Alex Miller", "email": "alex@example.com"},
{"name": "Olivia Anderson", "email": "olivia@example.com"},
{"name": "Daniel Martin", "email": "daniel@example.com"},
{"name": "Sophia White", "email": "sophia@example.com"}
]' http://localhost:5000/users
列出已创建的用户:
curl http://localhost:5000/users
获取当前时间:
Get current time:
针对 example.com 运行 ping:
curl -X POST -H "Content-Type: application/json" -d '{"host": "example.com"}' http://localhost:5002/ping
浏览数据库
调用某些 API 函数后,数据已存储,你可以检查 citus_schemas 是否反映预期内容:
select * from citus_schemas;
schema_name | colocation_id | schema_size | schema_owner
-------------+---------------+-------------+--------------
userservice | 1 | 112 kB | userservice
timeservice | 2 | 32 kB | timeservice
pingservice | 3 | 32 kB | pingservice
(3 rows)
创建架构时,没有告知 Azure Cosmos DB for PostgreSQL 要在哪台计算机上创建架构。 此过程是自动完成的。 可以使用以下查询查看每个架构所在的位置:
select nodename,nodeport, table_name, pg_size_pretty(sum(shard_size))
from citus_shards
group by nodename,nodeport, table_name;
nodename | nodeport | table_name | pg_size_pretty
-----------+----------+---------------------------+----------------
localhost | 9701 | timeservice.query_details | 32 kB
localhost | 9702 | userservice.users | 112 kB
localhost | 9702 | pingservice.ping_results | 32 kB
为使本页示例输出简明扼要,我们不使用 nodename,如 Azure Cosmos DB for PostgreSQL 中所示,而是将它替换为 localhost。 假设 localhost:9701 为辅助角色 1,localhost:9702 为辅助角色 2。 托管服务上的节点名称更长,并且包含随机元素。
可以看到,时间服务位于节点 localhost:9701 上,而用户和 ping 服务共享第二个辅助角色 localhost:9702 的空间。 示例应用比较简单,此处的数据大小是可忽略的,但假设你对节点之间的存储空间利用率不均衡感到不满。 将两个较小的时间和 ping 服务放在一台机器上,而将大型用户服务单独放在一台机器上,这样会更合理。
可以轻松地按磁盘大小重新平衡群集:
select citus_rebalance_start();
NOTICE: Scheduled 1 moves as job 1
DETAIL: Rebalance scheduled as background job
HINT: To monitor progress, run: SELECT * FROM citus_rebalance_status();
citus_rebalance_start
-----------------------
1
(1 row)
完成后,可以检查新布局的外观:
select nodename,nodeport, table_name, pg_size_pretty(sum(shard_size))
from citus_shards
group by nodename,nodeport, table_name;
nodename | nodeport | table_name | pg_size_pretty
-----------+----------+---------------------------+----------------
localhost | 9701 | timeservice.query_details | 32 kB
localhost | 9701 | pingservice.ping_results | 32 kB
localhost | 9702 | userservice.users | 112 kB
(3 rows)
根据预期,架构已移动,并且我们有一个更均衡的群集。 此操作对于应用程序是透明的。 你甚至不需要重启它们,它们会继续为查询提供服务。
后续步骤
本教程介绍了如何创建分布式架构,并使用它们作为存储运行微服务。 你还了解了如何探索和管理基于架构的分片 Azure Cosmos DB for PostgreSQL。
- 了解群集节点类型