使用 “版本 ”下拉列表切换服务。 了解有关导航的详细信息。
适用于:✅ Azure Data Explorer
函数 series_mv_if_anomalies_fl() 是一个用户定义的函数 (UDF),它通过应用 scikit-learn 中的隔离林模型来检测序列中的多变量异常。 该函数接受一组序列作为数字动态数组、特征列的名称以及整个系列中预期的异常百分比。 该函数为每个序列生成隔离树的系综,并将快速隔离的点标记为异常。
先决条件
- 必须在群集上启用 Python 插件。 这是函数中使用的内联 Python 所必需的。
语法
T | invoke series_mv_if_anomalies_fl(
, features_colsanomaly_col [,score_col [,anomalies_pct [, [,samples_pct ]]] ])
详细了解语法约定。
参数
| 客户 | 类型 | 必需 | 说明 |
|---|---|---|---|
| features_cols | dynamic |
✔️ | 一个数组,其中包含用于多变量异常情况检测模型的列的名称。 |
| anomaly_col | string |
✔️ | 用于存储检测到的异常的列的名称。 |
| score_col | string |
用于存储异常得分的列的名称。 | |
| anomalies_pct | real |
[0-50] 范围内的实数,指定数据中异常的预期百分比。 默认值:4%。 | |
| num_trees | int |
要为每个时序生成的隔离树数。 默认值:100。 | |
| samples_pct | real |
[0-100] 范围内的实数,指定用于生成每个树的样本百分比。 默认值:100%,即使用完整序列。 |
函数定义
可以通过将函数的代码嵌入为查询定义的函数,或将其创建为数据库中的存储函数来定义函数,如下所示:
使用以下 let 语句定义函数。 不需要任何权限。
// Define function
let series_mv_if_anomalies_fl=(tbl:(*), features_cols:dynamic, anomaly_col:string, score_col:string='', anomalies_pct:real=4.0, num_trees:int=100, samples_pct:real=100.0)
{
let kwargs = bag_pack('features_cols', features_cols, 'anomaly_col', anomaly_col, 'score_col', score_col, 'anomalies_pct', anomalies_pct, 'num_trees', num_trees, 'samples_pct', samples_pct);
let code = ```if 1:
from sklearn.ensemble import IsolationForest
features_cols = kargs['features_cols']
anomaly_col = kargs['anomaly_col']
score_col = kargs['score_col']
anomalies_pct = kargs['anomalies_pct']
num_trees = kargs['num_trees']
samples_pct = kargs['samples_pct']
dff = df[features_cols]
iforest = IsolationForest(contamination=anomalies_pct/100.0, random_state=0, n_estimators=num_trees, max_samples=samples_pct/100.0)
for i in range(len(dff)):
dffi = dff.iloc[[i], :]
dffe = dffi.explode(features_cols)
iforest.fit(dffe)
df.loc[i, anomaly_col] = (iforest.predict(dffe) < 0).astype(int).tolist()
if score_col != '':
df.loc[i, score_col] = iforest.decision_function(dffe).tolist()
result = df
```;
tbl
| evaluate hint.distribution=per_node python(typeof(*), code, kwargs)
};
// Write your query to use the function here.
示例
以下示例使用 invoke 运算符运行函数。
若要使用查询定义的函数,请在嵌入的函数定义后调用它。
// Define function
let series_mv_if_anomalies_fl=(tbl:(*), features_cols:dynamic, anomaly_col:string, score_col:string='', anomalies_pct:real=4.0, num_trees:int=100, samples_pct:real=100.0)
{
let kwargs = bag_pack('features_cols', features_cols, 'anomaly_col', anomaly_col, 'score_col', score_col, 'anomalies_pct', anomalies_pct, 'num_trees', num_trees, 'samples_pct', samples_pct);
let code = ```if 1:
from sklearn.ensemble import IsolationForest
features_cols = kargs['features_cols']
anomaly_col = kargs['anomaly_col']
score_col = kargs['score_col']
anomalies_pct = kargs['anomalies_pct']
num_trees = kargs['num_trees']
samples_pct = kargs['samples_pct']
dff = df[features_cols]
iforest = IsolationForest(contamination=anomalies_pct/100.0, random_state=0, n_estimators=num_trees, max_samples=samples_pct/100.0)
for i in range(len(dff)):
dffi = dff.iloc[[i], :]
dffe = dffi.explode(features_cols)
iforest.fit(dffe)
df.loc[i, anomaly_col] = (iforest.predict(dffe) < 0).astype(int).tolist()
if score_col != '':
df.loc[i, score_col] = iforest.decision_function(dffe).tolist()
result = df
```;
tbl
| evaluate hint.distribution=per_node python(typeof(*), code, kwargs)
};
// Usage
normal_2d_with_anomalies
| extend anomalies=dynamic(null), scores=dynamic(null)
| invoke series_mv_if_anomalies_fl(pack_array('x', 'y'), 'anomalies', 'scores', anomalies_pct=8, num_trees=1000)
| extend anomalies=series_multiply(40, anomalies)
| render timechart
输出
表 normal_2d_with_anomalies 包含一个由 3 个时序组成的集。 每个时序都有二维正态分布,每日异常分别在午夜、上午 8 点和下午 4 点添加。 可以使用示例查询创建此示例数据集。
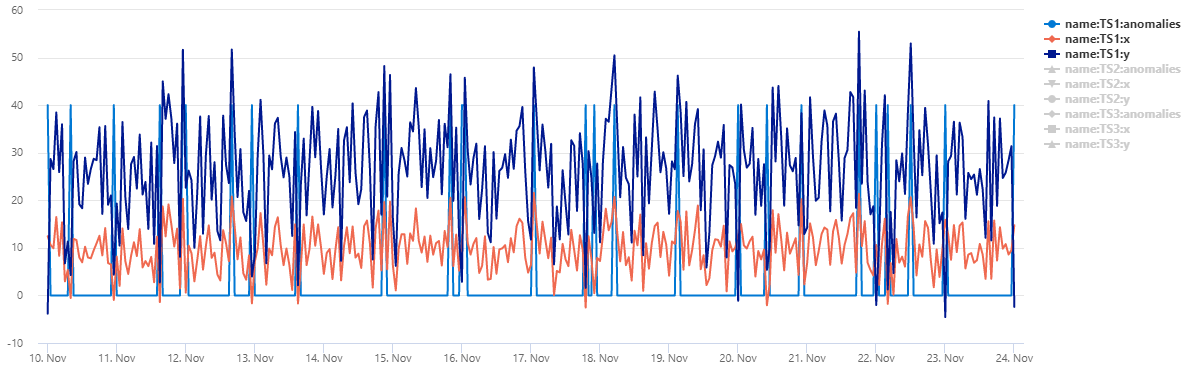
若要将数据作为散点图查看,请将用法代码替换为以下内容:
normal_2d_with_anomalies
| extend anomalies=dynamic(null)
| invoke series_mv_if_anomalies_fl(pack_array('x', 'y'), 'anomalies')
| where name == 'TS1'
| project x, y, anomalies
| mv-expand x to typeof(real), y to typeof(real), anomalies to typeof(string)
| render scatterchart with(series=anomalies)
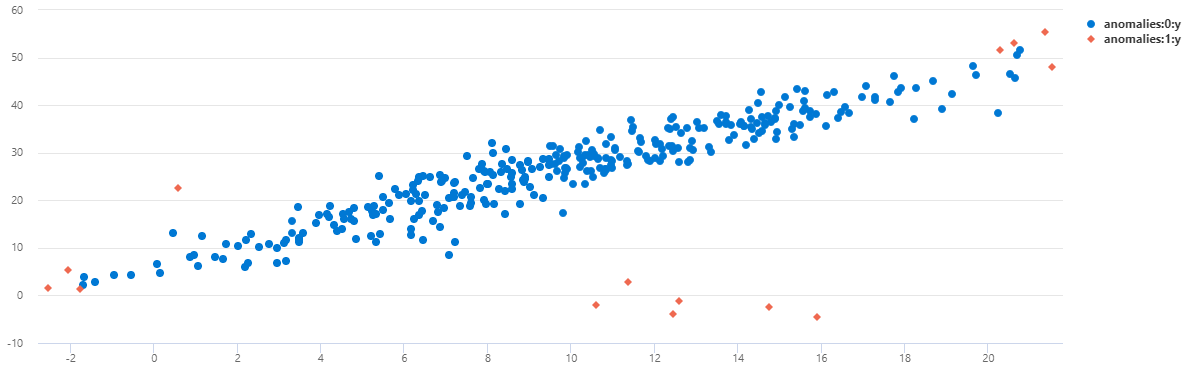
可以看到,在 TS2 上,大多数在上午 8 点发生的异常都是使用此多变量模型检测到的。