适用于:✅Azure 数据资源管理器
bag_unpack 插件通过将每个属性包顶级槽视为列来解压缩 dynamic 类型的单个列。 该插件通过 evaluate 运算符调用。
Syntax
T|evaluatebag_unpack(Column [,OutputColumnPrefix] [,columnsConflict] [,ignoredProperties] ) [:OutputSchema]
详细了解语法约定。
Parameters
| Name | 类型 | Required | Description |
|---|---|---|---|
| T | string |
✔️ | 要解压缩其列 Column 的表格输入。 |
| Column | dynamic |
✔️ | 要解压缩的列 T。 |
| OutputColumnPrefix | string |
添加到插件生成的所有列的常见前缀。 | |
| columnsConflict | string |
有关解决列冲突的指导。 有效值:error - 查询生成错误(默认值)replace_source -源列被替换keep_source - 源列被保留 |
|
| ignoredProperties | dynamic |
要忽略的一组可选包属性。 } | |
| OutputSchema | 指定插件输出的 bag_unpack 列名称和类型。 有关语法信息,请参阅 输出架构语法,并了解含义,请参阅 性能注意事项。 |
输出架构语法
(
ColumnName :ColumnType [, ...] )
使用通配符 * 作为第一个参数将源表的所有列包含在输出中,如下所示:
(
*
,
ColumnName :ColumnType [, ...] )
性能注意事项
在没有 OutputSchema 的情况下使用插件可能会对大型数据集产生严重的性能影响,应避免这样做。
提供 OutputSchema 允许查询引擎优化查询执行,因为它可以确定输出架构,而无需分析和分析输入数据。 当输入数据较大或复杂时,OutputSchema 非常有用。 请参阅 示例,其中显示了 在未定义 OutputSchema 的情况下使用插件的性能影响。
Returns
bag_unpack 插件返回一个表,其中包含的记录与其表格输入 (T) 的数量相同。 该表格的架构与表格输入的架构相同,但有以下修改:
- 删除了指定的输入列 (Column)。
- 每个列的名称对应于每个槽的名称,(可选)以 OutputColumnPrefix 作为前缀。
- 如果同一槽的所有值具有相同类型,则每个列的类型都是槽的类型,或者
dynamic,如果值在类型上不同。 - 架构随 T 的顶级属性包值中的不同槽数一样多的列进行扩展。
Note
- 如果未指定 OutputSchema,插件输出架构会因输入数据值而异。 具有不同数据输入的插件的多个执行可以生成不同的输出架构。
- 如果指定 了 OutputSchema ,则插件仅返回 输出架构语法中定义的列,除非使用通配符
*。 - 若要返回输入数据的所有列,以及 OutputSchema 中定义的列,请使用
*中的通配符。
表格架构规则适用于输入数据。 特别是:
- 输出列名称不能与表格输入 T 中的现有列相同,除非它是要解压缩的列(列)。 否则,输出包含两个具有相同名称的列。
- 以 OutputColumnPrefix 为前缀时,所有槽名称必须是有效的实体名称,并遵循标识符命名规则。
该插件忽略 null 值。
Examples
本节中的示例演示如何使用语法帮助你入门。
展开包:
datatable(d:dynamic)
[
dynamic({"Name": "John", "Age":20}),
dynamic({"Name": "Dave", "Age":40}),
dynamic({"Name": "Jasmine", "Age":30}),
]
| evaluate bag_unpack(d)
Output
Age |
Name |
|---|---|
| 20 | John |
| 40 | Dave |
| 30 | Jasmine |
展开包并使用 OutputColumnPrefix 选项生成带有前缀的列名称:
datatable(d:dynamic)
[
dynamic({"Name": "John", "Age":20}),
dynamic({"Name": "Dave", "Age":40}),
dynamic({"Name": "Jasmine", "Age":30}),
]
| evaluate bag_unpack(d, 'Property_')
Output
Property_Age |
Property_Name |
|---|---|
| 20 | John |
| 40 | Dave |
| 30 | Jasmine |
展开包并使用 columnsConflict 选项解决动态列与现有列之间的列冲突:
datatable(Name:string, d:dynamic)
[
'James', dynamic({"Name": "John", "Age":20}),
'David', dynamic({ "Age":40}),
'Emily', dynamic({"Name": "Jasmine", "Age":30}),
]
| evaluate bag_unpack(d, columnsConflict='replace_source') // Replace old column Name by new column
Output
Name |
Age |
|---|---|
| John | 20 |
| 40 | |
| Jasmine | 30 |
datatable(Name:string, d:dynamic)
[
'James', dynamic({"Name": "John", "Age":20}),
'David', dynamic({"Name": "Dave", "Age":40}),
'Emily', dynamic({"Name": "Jasmine", "Age":30}),
]
| evaluate bag_unpack(d, columnsConflict='keep_source') // Keep old column Name
Output
Name |
Age |
|---|---|
| 詹姆斯 | 20 |
| 大卫 | 40 |
| 艾米丽 | 30 |
展开包并使用 ignoredProperties 选项忽略属性包中的 2 个属性:
datatable(d:dynamic)
[
dynamic({"Name": "John", "Age":20, "Address": "Address-1" }),
dynamic({"Name": "Dave", "Age":40, "Address": "Address-2"}),
dynamic({"Name": "Jasmine", "Age":30, "Address": "Address-3"}),
]
// Ignore 'Age' and 'Address' properties
| evaluate bag_unpack(d, ignoredProperties=dynamic(['Address', 'Age']))
Output
Name |
|---|
| John |
| Dave |
| Jasmine |
展开包并使用 OutputSchema 选项:
datatable(d:dynamic)
[
dynamic({"Name": "John", "Age":20}),
dynamic({ "Name": "Dave", "Height": 170, "Age":40}),
dynamic({"Name": "Jasmine", "Age":30}),
]
| evaluate bag_unpack(d)
Output
Age |
Height |
Name |
|---|---|---|
| 20 | John | |
| 40 | 170 | Dave |
| 30 | Jasmine |
使用 OutputSchema 展开包并使用通配符 * 选项:
此查询返回在 OutputSchema 中定义的原始槽说明和列。
datatable(d:dynamic, Description: string)
[
dynamic({"Name": "John", "Age":20, "height":180}), "Student",
dynamic({"Name": "Dave", "Age":40, "height":160}), "Teacher",
dynamic({"Name": "Jasmine", "Age":30, "height":172}), "Student",
]
| evaluate bag_unpack(d) : (*, Name:string, Age:long)
Output
| Description | Name |
Age |
|---|---|---|
| 学生 | John | 20 |
| Teacher | Dave | 40 |
| 学生 | Jasmine | 30 |
性能影响的示例
使用和不使用定义的 OutputSchema 扩展包以比较性能影响:
此示例使用 帮助群集中的公开可用表。 在 ContosoSales 数据库中,有一个名为 SalesDynamic 的表。 该表包含销售数据,并包含名为 Customer_Properties的动态列。
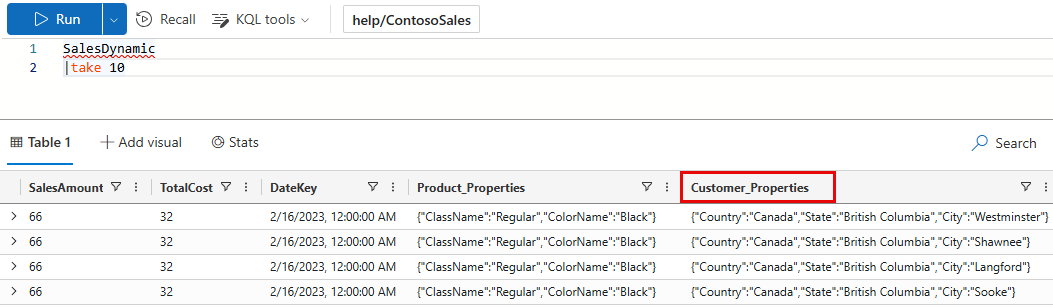
没有输出架构的示例:第一个查询不定义 OutputSchema。 查询需要 5.84 秒的 CPU 并扫描 36.39 MB 的数据。
SalesDynamic | evaluate bag_unpack(Customer_Properties) | summarize Sales=sum(SalesAmount) by Country, State输出架构示例:第二个查询提供 OutputSchema。 查询需要 0.45 秒的 CPU 并扫描 19.31 MB 的数据。 查询不必分析输入表,从而节省处理时间。
SalesDynamic | evaluate bag_unpack(Customer_Properties) : (*, Country:string, State:string, City:string) | summarize Sales=sum(SalesAmount) by Country, State
Output
这两个查询的输出相同。 输出的前 10 行如下所示。
Country/Region |
State |
Sales |
|---|---|---|
| Canada | 不列颠哥伦比亚省 | 56,101,083 |
| 英国 | England | 77,288,747 |
| Australia | Victoria | 31,242,423 |
| Australia | Queensland | 27,617,822 |
| Australia | 南澳大利亚 | 8,530,537 |
| Australia | 新南威尔士州 | 54,765,786 |
| Australia | Tasmania | 3,704,648 |
| Canada | Alberta | 375,061 |
| Canada | Ontario | 38,282 |
| 美国 | Washington | 80,544,870 |
| ... | ... | ... |