make-series 运算符
沿指定的轴创建指定聚合值的序列。
语法
T| make-series [MakeSeriesParameters] [Column=] Aggregation [default=DefaultValue] [, ...] onAxisColumn [fromstart] [toend] stepstep [by [Column=] GroupExpression [, ...]]
详细了解语法约定。
参数
| 客户 | 类型 | 必需 | 说明 |
|---|---|---|---|
| 列 | string |
结果列的名称。 默认为派生自表达式的名称。 | |
| DefaultValue | 标量 (scalar) | 缺少值时要使用的默认值。 如果没有任何行包含特定的 AxisColumn 和 GroupExpression 值,则会为数组的相应元素分配 DefaultValue。 默认为 0。 | |
| 聚合 | string |
✔ | 对聚合函数(例如 count() 或 avg())的调用,以列名作为参数。 请参阅聚合函数列表。 只能将返回数值结果的聚合函数与 make-series 运算符配合使用。 |
| AxisColumn | string |
✔ | 将用作序列排序依据的列。 通常,列值的类型为 datetime 或 timespan,但接受所有数值类型。 |
| start | 标量 (scalar) | ✔ | 要生成的每个序列的 AxisColumn 下限值。 如果未指定 start,则它将是每个序列中具有数据的第一个箱或步长。 |
| end | 标量 (scalar) | ✔ | AxisColumn 的上限值(不含端值)。 时序的最后一个索引小于此值,并且将是小于 end 的以下值:start 加上 step 的整数倍。 如果未指定 end,则它将是每个序列中具有数据的最后一个箱的上限,或将是步长。 |
| step | 标量 (scalar) | ✔ | AxisColumn 数组中两个连续元素之间的差异(即箱大小)。 有关可能的时间间隔的列表,请参阅时间间隔。 |
| GroupExpression | 各列的表达式,提供一组非重复值。 通常,它是已提供一组受限值的列名。 | ||
| MakeSeriesParameters | 用于控制行为的两个或多个以空格分隔的参数,采用 Name=Value 形式。 请参阅支持的 make series 参数。 |
注意
start、end 和 step 参数用来生成 AxisColumn 值的数组。 此数组包含介于 start 和 end 之间的值,step 值表示一个数组元素与下一个元素之间的差值。 所有 Aggregation 值分别按顺序排列到此数组。
支持的 make series 参数
| 名称 | 描述 |
|---|---|
kind |
当 make-series 运算符的输入为空时,生成默认结果。 值:nonempty |
hint.shufflekey=<key> |
shufflekey 查询使用键将数据分区,在群集节点上共享查询负载。 请参阅 shuffle 查询 |
注意
make-series 生成的数组的值数量上限为 1048576 (2^20)。 尝试使用 make-series 生成更大的数组将导致错误或数组被截断。
替代语法
T| make-series [Column=] Aggregation [default=DefaultValue] [, ...] onAxisColumninrange(start,stop,step) [by [Column=] GroupExpression [, ...]]
使用替代语法生成的序列与使用主语法生成的序列有两个方面的差异:
- stop 值包含在内。
- 使用 bin() 而不是 bin_at() 生成索引轴分箱,这意味着生成的序列中可能不包括 start。
建议使用 make-series 的主要语法,而不是替代语法。
返回
输入行将排列成与 by 表达式以及 bin_at(AxisColumn,step,start) 表达式具有相同值的组 。 然后,对每个组计算指定的聚合函数,从而为每组生成行。 结果包含 by 列和 AxisColumn 列,还至少包含用于每个计算聚合的一列。 (不支持聚合多个列或非数值结果。)
此中间结果包含的行数与 by 和 bin_at(AxisColumn,step,start) 值的不同组合数相同 。
最后,中间结果中的行被排列为具有相同 by 表达式值的组,且所有聚合值都排列为数组(dynamic 类型的值)。 对于每个聚合,都有一个列包含其同名数组。 最后一列是一个数组,其中包含根据指定步骤装箱的 AxisColumn 的值 。
注意
尽管可为聚合和分组表达式提供任意表达式,但使用简单的列名更加高效。
聚合函数列表
| 函数 | 说明 |
|---|---|
| avg() | 返回整个组的平均值 |
| avgif() | 返回具有组谓词的平均值 |
| count() | 返回组的计数 |
| countif() | 返回具有组谓词的计数 |
| dcount() | 返回组元素的近似非重复计数 |
| dcountif() | 返回具有组谓词的近似非重复计数 |
| max() | 返回组内的最大值 |
| maxif() | 返回具有组谓词的最大值 |
| min() | 返回组内的最小值 |
| minif() | 返回具有组谓词的最小值 |
| percentile() | 返回组中的百分位数值 |
| take_any() | 返回组的随机非空值 |
| stdev() | 返回整个组的标准偏差 |
| sum() | 返回组中元素的总和 |
| sumif() | 返回具有组谓词的元素的总和 |
| variance() | 返回整个组的方差 |
序列分析函数列表
| 函数 | 描述 |
|---|---|
| series_fir() | 应用有限脉冲响应筛选器 |
| series_iir() | 应用有限脉冲响应筛选器 |
| series_fit_line() | 查找与输入最近似的直线 |
| series_fit_line_dynamic() | 查找与输入最近似的线,返回动态对象 |
| series_fit_2lines() | 查找与输入最近似的两条线 |
| series_fit_2lines_dynamic() | 查找与输入最近似的两条线,返回动态对象 |
| series_outliers() | 对序列中的异常点进行评分 |
| series_periods_detect() | 找出一个时序中最重要的周期 |
| series_periods_validate() | 检查时序是否包含给定长度的定期模式 |
| series_stats_dynamic() | 返回包含常用统计信息(最小值/最大值/方差/标准偏差/平均值)的多个列 |
| series_stats() | 生成包含常用统计信息(最小值/最大值/方差/标准偏差/平均值)的动态值 |
有关序列分析功能的完整列表,请参阅:序列处理函数
序列内插函数列表
| 函数 | 描述 |
|---|---|
| series_fill_backward() | 在序列中对缺失值执行后向填充内插 |
| series_fill_const() | 用指定的常数值替换序列中缺失的值 |
| series_fill_forward() | 在序列中对缺失值执行前向填充内插 |
| series_fill_linear() | 在序列中对缺失值执行线性内插 |
- 注意:默认情况下,内插函数假定
null为缺失值。 因此,如果要对序列使用内插函数,请在make-series中指定default=double(null)。
示例
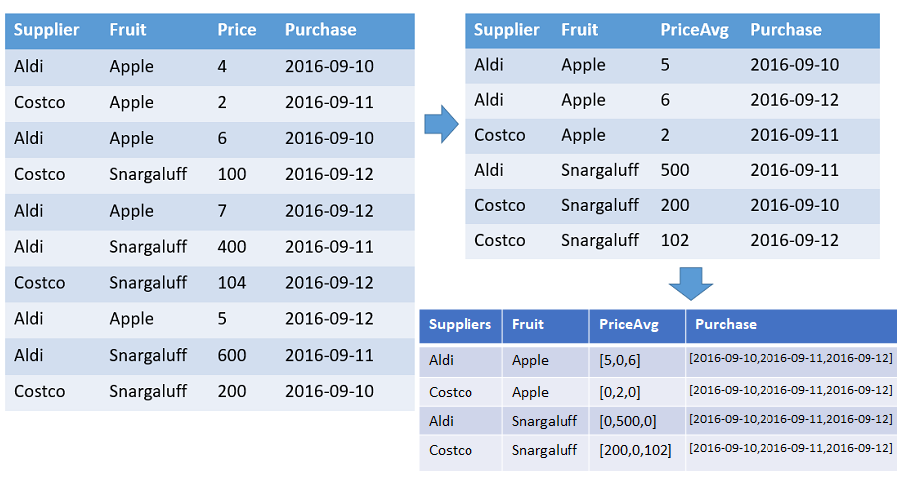
一张表,其中显示了从每家供应商订购的每种水果的数量和平均价格组成的数组,该表的排序依据是指定范围的时间戳。 水果与供应商的每个不同组合在输出中都占一行。 输出列显示水果、供应商,以及由以下元素组成的数组:计数、平均值和整个时间线 (2016-01-01 - 2016-01-10)。 所有数组都按各自的时间戳排序,并且所有间隙均用默认值(在本示例中为 0)填充。 忽略所有其他输入列。
T | make-series PriceAvg=avg(Price) default=0
on Purchase from datetime(2016-09-10) to datetime(2016-09-13) step 1d by Supplier, Fruit
let data=datatable(timestamp:datetime, metric: real)
[
datetime(2016-12-31T06:00), 50,
datetime(2017-01-01), 4,
datetime(2017-01-02), 3,
datetime(2017-01-03), 4,
datetime(2017-01-03T03:00), 6,
datetime(2017-01-05), 8,
datetime(2017-01-05T13:40), 13,
datetime(2017-01-06), 4,
datetime(2017-01-07), 3,
datetime(2017-01-08), 8,
datetime(2017-01-08T21:00), 8,
datetime(2017-01-09), 2,
datetime(2017-01-09T12:00), 11,
datetime(2017-01-10T05:00), 5,
];
let interval = 1d;
let stime = datetime(2017-01-01);
let etime = datetime(2017-01-10);
data
| make-series avg(metric) on timestamp from stime to etime step interval
| avg_metric | timestamp |
|---|---|
| [ 4.0, 3.0, 5.0, 0.0, 10.5, 4.0, 3.0, 8.0, 6.5 ] | [ "2017-01-01T00:00:00.0000000Z", "2017-01-02T00:00:00.0000000Z", "2017-01-03T00:00:00.0000000Z", "2017-01-04T00:00:00.0000000Z", "2017-01-05T00:00:00.0000000Z", "2017-01-06T00:00:00.0000000Z", "2017-01-07T00:00:00.0000000Z", "2017-01-08T00:00:00.0000000Z", "2017-01-09T00:00:00.0000000Z" ] |
当 make-series 的输入为空时,make-series 的默认行为是生成一个空结果。
let data=datatable(timestamp:datetime, metric: real)
[
datetime(2016-12-31T06:00), 50,
datetime(2017-01-01), 4,
datetime(2017-01-02), 3,
datetime(2017-01-03), 4,
datetime(2017-01-03T03:00), 6,
datetime(2017-01-05), 8,
datetime(2017-01-05T13:40), 13,
datetime(2017-01-06), 4,
datetime(2017-01-07), 3,
datetime(2017-01-08), 8,
datetime(2017-01-08T21:00), 8,
datetime(2017-01-09), 2,
datetime(2017-01-09T12:00), 11,
datetime(2017-01-10T05:00), 5,
];
let interval = 1d;
let stime = datetime(2017-01-01);
let etime = datetime(2017-01-10);
data
| take 0
| make-series avg(metric) default=1.0 on timestamp from stime to etime step interval
| count
输出
| 计数 |
|---|
| 0 |
在 make-series 中使用 kind=nonempty 将生成默认值的非空结果:
let data=datatable(timestamp:datetime, metric: real)
[
datetime(2016-12-31T06:00), 50,
datetime(2017-01-01), 4,
datetime(2017-01-02), 3,
datetime(2017-01-03), 4,
datetime(2017-01-03T03:00), 6,
datetime(2017-01-05), 8,
datetime(2017-01-05T13:40), 13,
datetime(2017-01-06), 4,
datetime(2017-01-07), 3,
datetime(2017-01-08), 8,
datetime(2017-01-08T21:00), 8,
datetime(2017-01-09), 2,
datetime(2017-01-09T12:00), 11,
datetime(2017-01-10T05:00), 5,
];
let interval = 1d;
let stime = datetime(2017-01-01);
let etime = datetime(2017-01-10);
data
| take 0
| make-series kind=nonempty avg(metric) default=1.0 on timestamp from stime to etime step interval
输出
| avg_metric | timestamp |
|---|---|
| [ 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0 ] |
[ "2017-01-01T00:00:00.0000000Z", "2017-01-02T00:00:00.0000000Z", "2017-01-03T00:00:00.0000000Z", "2017-01-04T00:00:00.0000000Z", "2017-01-05T00:00:00.0000000Z", "2017-01-06T00:00:00.0000000Z", "2017-01-07T00:00:00.0000000Z", "2017-01-08T00:00:00.0000000Z", "2017-01-09T00:00:00.0000000Z" ] |