使用 “版本 ”下拉列表切换服务。 了解有关导航的详细信息。
适用于: ✅ Microsoft Sentinel
Kusto 查询语言(KQL)是一种功能强大的工具,用于查询和分析Microsoft Sentinel 中的数据。 作为安全分析师,掌握 KQL 可以显著增强检测威胁和有效应对事件的能力。 本文提供了使用 KQL 执行常见任务的综合指南,可帮助你高效操作和分析数据。
在本教程中,你将了解 KQL 的基础知识,包括了解查询结构、获取、限制、排序和筛选数据、汇总数据和联接表。 此外,还可以探索高级概念,例如使用 evaluate 运算符和 let 语句创建更复杂的可维护查询。
先决条件
阅读本文之前,请确保熟悉 Kusto 查询语言(KQL)的基础知识。 如果您是 KQL 的新手,请参阅:
了解查询结构基础知识
开始学习 Kusto 查询语言的一个良好起点是了解整体查询结构。 查看 Kusto 查询时,你注意到的第一件事是使用管道符号 (|)。 Kusto 查询的结构首先从数据源获取数据,然后跨管道传递数据。 每个步骤提供某种级别的处理,然后将数据传递到下一步。 在流水线末尾你将获得最终结果。 实际上,此管道如下所示:
Get Data | Filter | Summarize | Sort | Select
通过将数据沿管道传递的概念,可以形成一种直观的结构,因为这使得在每一步很容易在心中构建数据的图景。
为了说明此概念,请查看以下查询,该查询将查看 Microsoft Entra 登录日志。 当你通读每一行时,可以看到指示数据正在发生什么的关键字。 管道中的相关阶段作为注释包含在每行中。
注释
可以通过用双斜杠//()在查询中的任何行前面添加注释。
SigninLogs // Get data
| evaluate bag_unpack(LocationDetails) // Ignore this line for now; we'll come back to it at the end.
| where RiskLevelDuringSignIn == 'none' // Filter
and TimeGenerated >= ago(7d) // Filter
| summarize Count = count() by city // Summarize
| sort by Count desc // Sort
| take 5 // Select
由于每个步骤的输出都作为下一步的输入,因此步骤的顺序可以确定查询的结果并影响其性能。 您需要根据希望从查询中获得的结果来排序步骤。
尽早筛选数据是一个很好的经验法则,以便在管道中仅传递相关数据。 此方法极大地提高了性能,并确保不会意外地在汇总步骤中包含不相关的数据。 有关详细信息,请参阅 Kusto 查询语言查询的最佳做法。
希望你现在对 Kusto 查询语言中的查询的整体结构表示赞赏。 现在,让我们看看用于创建查询的实际查询运算符本身。
获取、限制、排序和筛选数据
Kusto 查询语言的核心词汇(可用于完成大部分任务的基础)是用于筛选、排序和选择数据的运算符集合。 剩余的任务要求你扩展语言知识以满足更高级的需求。 让我们对 前面示例中 使用的一些命令进行一些扩展,并查看 take, sort以及 where。
对于这些运算符中的每一个,请检查其在之前的SigninLogs示例中的用法,以学习有用的提示或最佳实践。
获取数据
任何基本查询的第一行会指定您要操作的表。 对于 Microsoft Sentinel,此表可能是工作区中的日志类型的名称,例如 SigninLogs、 SecurityAlert 或 CommonSecurityLog。 例如:
SigninLogs
在 Kusto 查询语言中,日志名称区分大小写,因此SigninLogssigninLogs以不同的方式解释。 为自定义日志选择名称时,请小心,以便可以轻松识别它们,并且与另一个日志不太类似。
限制数据:采取 / 限制
使用 take 运算符(或相同的 限制 运算符)仅返回特定数量的行来限制结果。 紧接着一个整数,该整数指定要返回的行数。 通常,在确定排序顺序后,在查询结束时使用它。 在这种情况下,它将返回排序顺序顶部的指定行数。
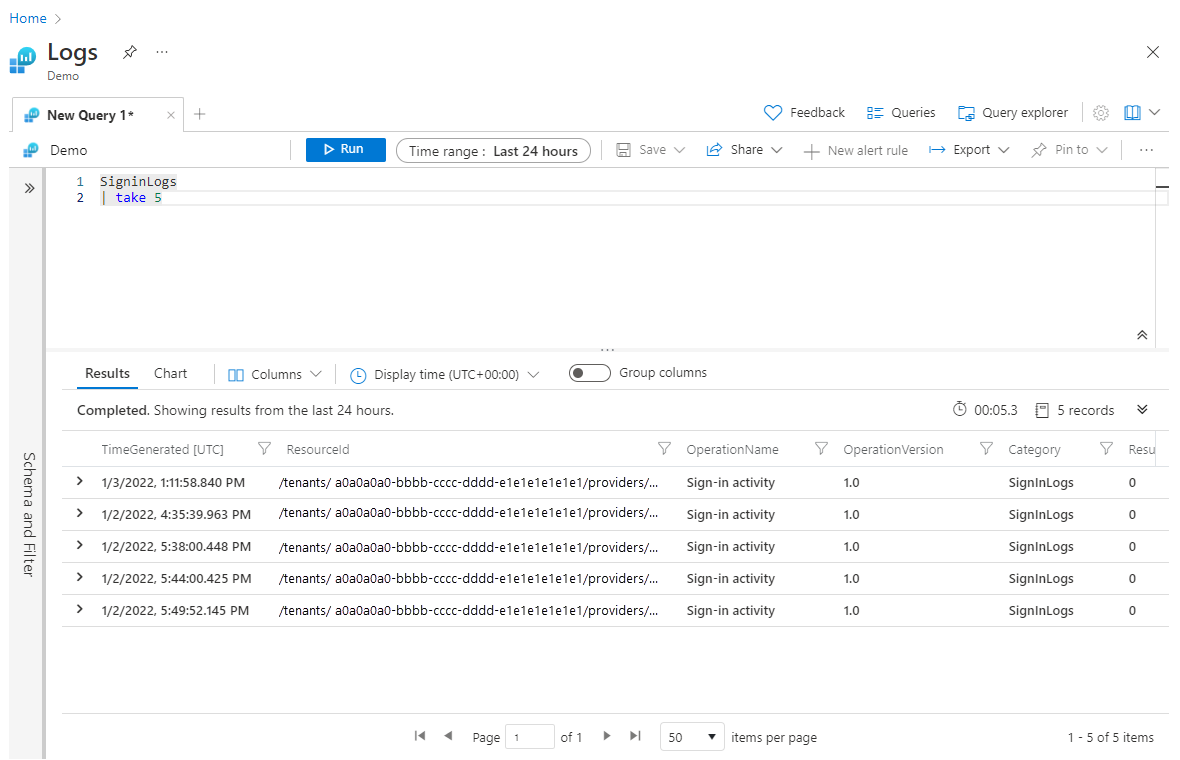
take当不想返回大型数据集时,在查询中使用前面的方法可用于测试查询。 但是,如果将操作置于 take 任何 sort 操作之前, take 则返回随机选择的行,并且每次运行查询时可能都返回一组不同的行。 下面是使用 take的示例:
SigninLogs
| take 5
小窍门
在处理一个你可能不清楚其结构的全新查询时,在开头放一个take语句,有意地限制数据集,这样可以加快处理和实验速度。 对完整查询感到满意后,请删除初始 take 步骤。
排序数据: 排序 / 顺序
使用 排序 运算符(和相同的 顺序 运算符)按指定列对数据进行排序。 在以下示例中,查询按 TimeGenerated 对结果进行排序,并将顺序方向设置为使用 desc 参数降序,首先放置最高值。 对于升序,请使用 asc。
注释
排序的默认方向为降序,因此从技术上而言,只需指定是否要按升序排序。 但是,在任何情况下指定排序方向会使查询更具可读性。
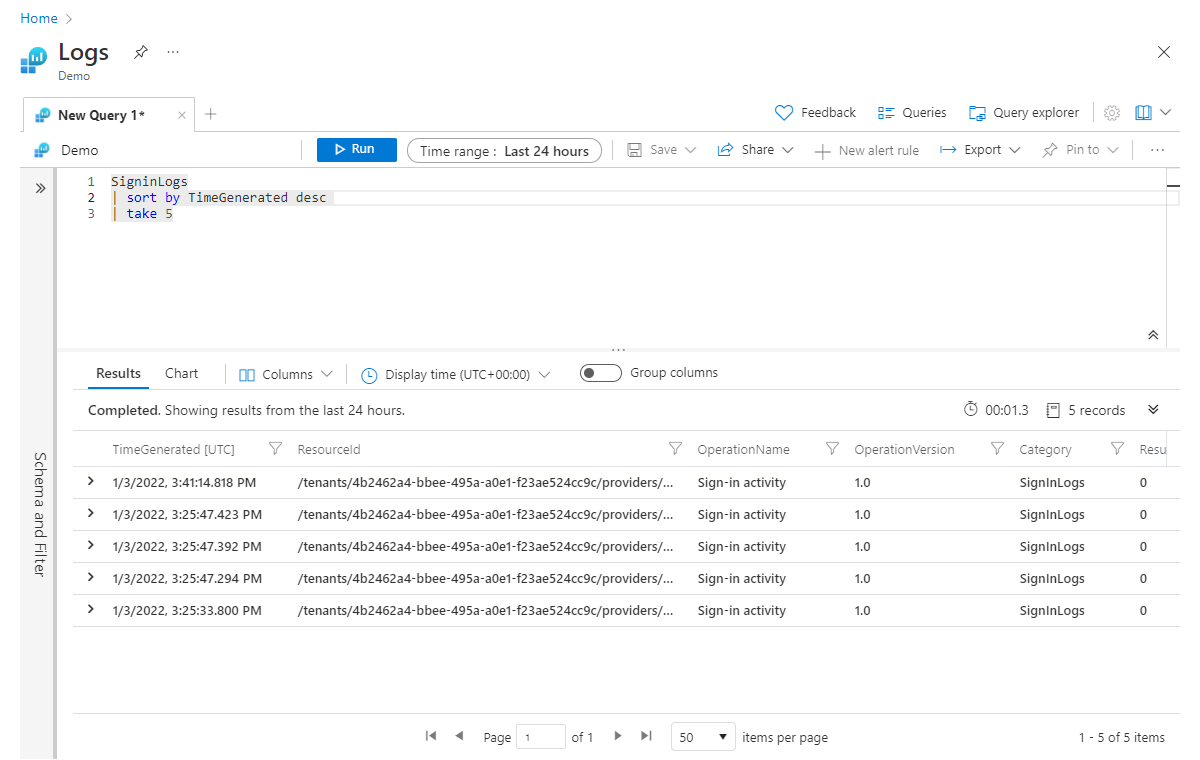
SigninLogs
| sort by TimeGenerated desc
| take 5
如前所述,将 sort 运算符置于 take 运算符之前。 首先需要排序以确保获得相应的五条记录。
顶部
Top运算符将sort和take操作合并为一个运算符:
SigninLogs
| top 5 by TimeGenerated desc
如果两条或更多条记录在排序依据的列中具有相同的值,请添加更多要排序依据的列。 在逗号分隔的列表中添加额外的排序列,该列位于第一个排序列之后,但在排序顺序关键字之前。 例如:
SigninLogs
| sort by TimeGenerated, Identity desc
| take 5
现在,如果 TimeGenerated 在多个记录之间相同,查询会尝试按 Identity 列中的值进行排序。
注释
何时使用 sort , take以及何时使用 top
如果只对一个字段进行排序,请使用
top,因为它提供的性能优于组合sort和take。如果需要对多个字段进行排序(如上一个示例中
top),则无法执行此作,因此必须使用sort和take。
筛选数据: 其中
where 运算符是最重要的运算符,因为它是确保仅处理与方案相关的数据的子集的关键。 尽早在查询中筛选数据,因为它通过减少后续步骤中需要处理的数据量来提高查询性能。 它还可确保仅对所需数据执行计算。 请参阅此示例:
SigninLogs
| where TimeGenerated >= ago(7d)
| sort by TimeGenerated, Identity desc
| take 5
该 where 运算符指定变量、比较(标量)运算符和值。 在此示例中,用于 >= 表示 TimeGenerated 列中的值需要大于(即晚于)或等于七天前。
Kusto 查询语言中有两种类型的比较运算符:字符串和数字。 字符串运算符支持区分大小写、子字符串位置、前缀、后缀及更多功能。
该 == 运算符既是数字运算符,也是字符串运算符,这意味着它可用于数字和文本。 例如,以下两个 where 语句都是有效的语句:
| where ResultType == 0| where Category == 'SignInLogs'
最佳做法: 在大多数情况下,按多个列筛选数据,或以多种方式筛选同一列。 在这些情况下,请记住这两种最佳做法。
使用where多个语句合并为单个步骤。 例如:
SigninLogs
| where Resource == ResourceGroup
and TimeGenerated >= ago(7d)
使用关键字 where 将多个筛选器连接到一个单一的 语句时,通过优先放置只引用单个列的筛选器,可以获得更好的性能。 因此,编写上一个查询的更好方法是:
SigninLogs
| where TimeGenerated >= ago(7d)
and Resource == ResourceGroup
在此示例中,第一个筛选器提到单个列(TimeGenerated),而第二个筛选器引用了两列(Resource 和 ResourceGroup)。
汇总数据
Summarize 是 Kusto 查询语言中最重要的表格运算符之一。 如果你不熟悉一般查询语言,这也是更复杂的运算符之一。
汇总语句的结构
一个summarize语句的基本结构如下所示:
| summarize <aggregation> by <column>
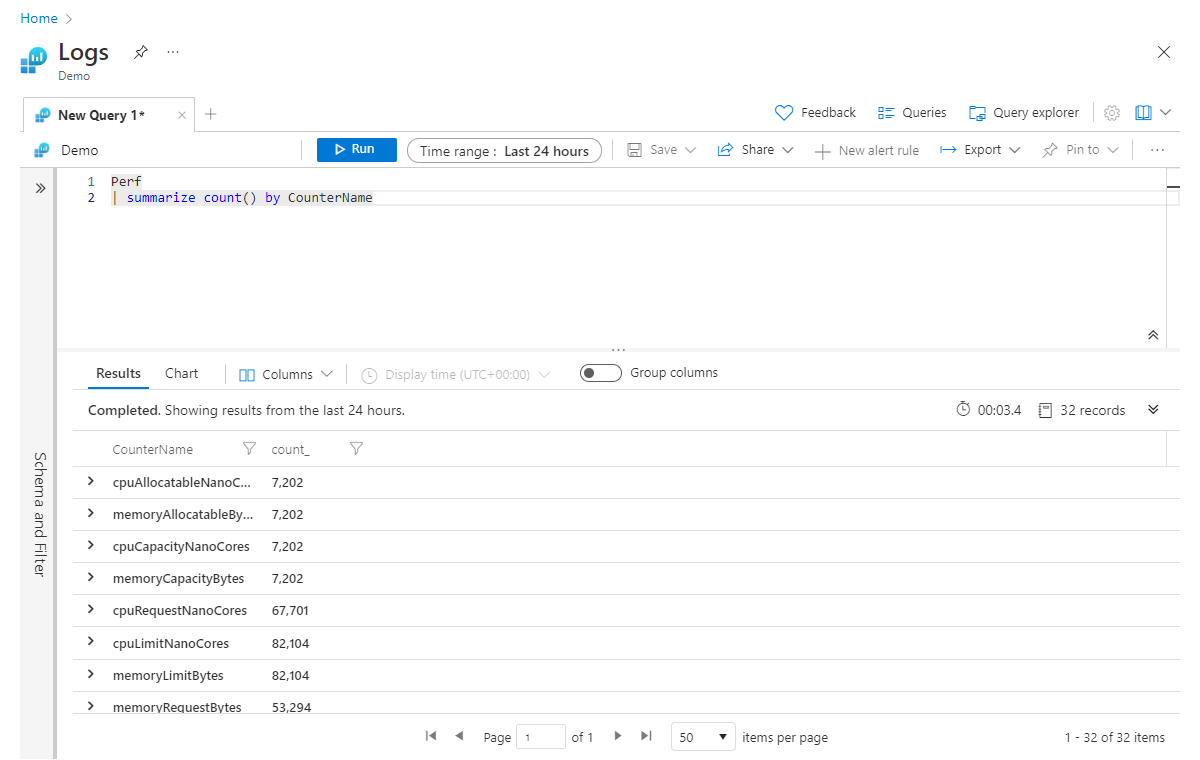
例如,以下查询返回 Perf 表中每个 CounterName 值的记录计数:
Perf
| summarize count() by CounterName
由于输出summarize是一个新表,因此查询不会将未在summarize语句中显式指定的列传递到管道的后续阶段。 若要说明此概念,请考虑以下示例:
Perf
| project ObjectName, CounterValue, CounterName
| summarize count() by CounterName
| sort by ObjectName asc
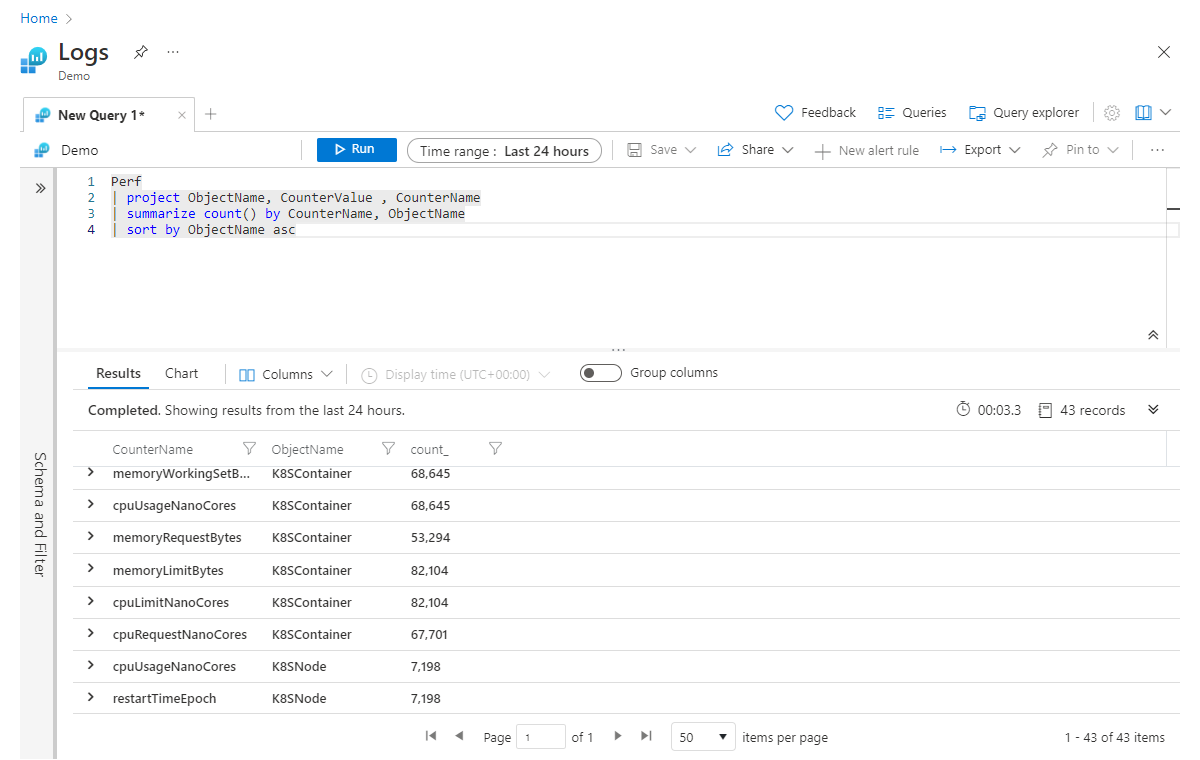
第二行指定只关注 ObjectName、 CounterValue 和 CounterName 列。 然后汇总,按 CounterName 获取记录计数,最后尝试根据 ObjectName 列按升序对数据进行排序。 遗憾的是,此查询失败并显示错误(指示 ObjectName 未知),因为汇总后,您仅在新表中包含 Count 和 CounterName 列。 若要避免此错误,请将 ObjectName 添加到步骤末尾 summarize ,如下所示:
Perf
| project ObjectName, CounterValue , CounterName
| summarize count() by CounterName, ObjectName
| sort by ObjectName asc
您脑海中读取 summarize 行的方式是:“通过 CounterName 汇总记录的计数,并按 ObjectName 分组。” 您可以继续在语句末尾添加用逗号分隔的列。
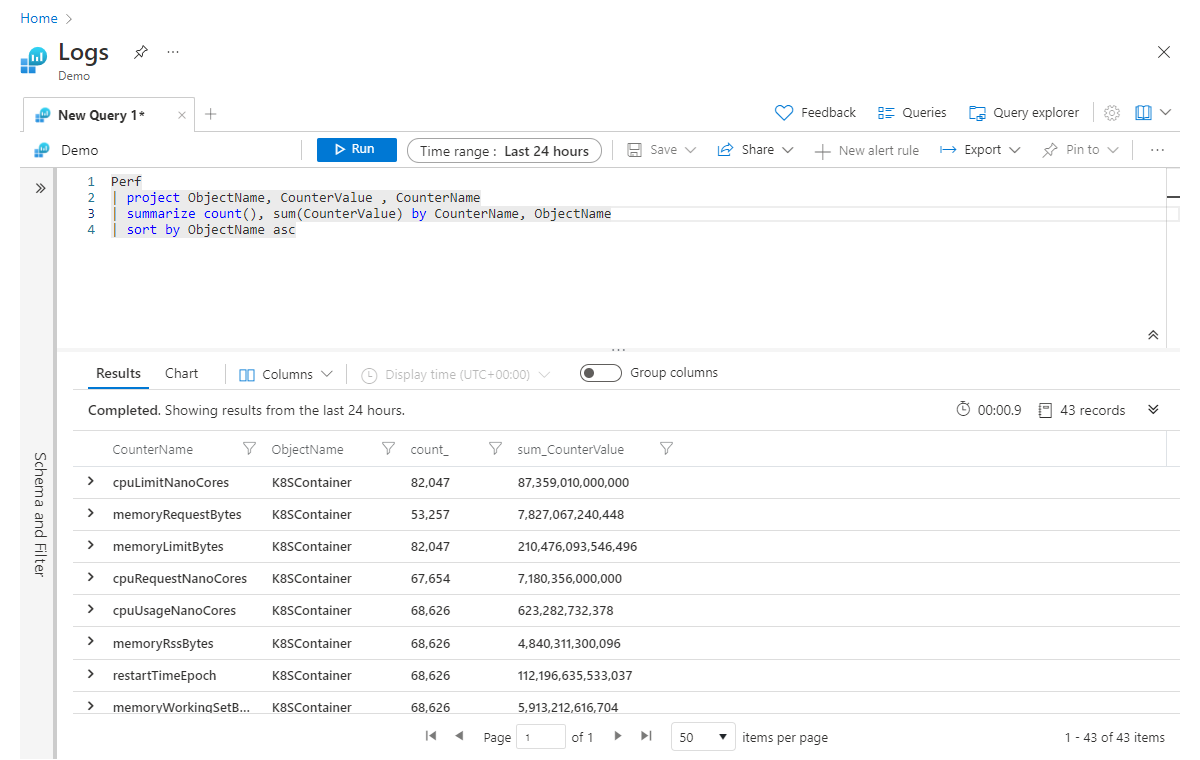
同时聚合多个列时,请在前一个示例的基础上进行操作,向summarize运算符添加聚合,并用逗号分隔。 在下面的示例中,不仅可以获取所有记录的计数,还可以获取所有记录的 CounterValue 列中的值的总和(与查询中的任何筛选器匹配):
Perf
| project ObjectName, CounterValue , CounterName
| summarize count(), sum(CounterValue) by CounterName, ObjectName
| sort by ObjectName asc
重命名聚合列
本部分介绍这些聚合列的列名。
在本部分的开头,你了解 summarize 该运算符在数据表中获取并生成一个新表,并且只有你在语句中指定的 summarize 列继续运行管道。 因此,如果运行前面的示例,则聚合的结果列 count_ 和 sum_CounterValue。
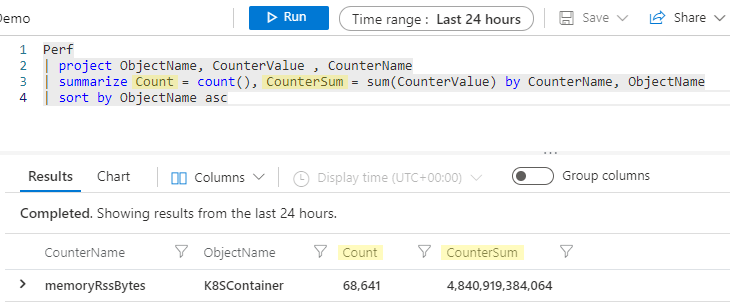
Kusto 引擎会自动创建列名称,而无需显式,但通常,你更喜欢新列具有更友好的名称。 您可以在summarize语句中通过指定一个新名称(后跟=和聚合)轻松重命名列,如下所示:
Perf
| project ObjectName, CounterValue , CounterName
| summarize Count = count(), CounterSum = sum(CounterValue) by CounterName, ObjectName
| sort by ObjectName asc
现在,汇总的列名为 Count 和 CounterSum。
关于 summarize 操作员,本文无法涵盖全部内容,但你应该投入时间来学习,因为它是对 Microsoft Sentinel 数据进行任何数据分析的重要组成部分。
聚合参考
许多聚合函数都可用,但一些最常用的函数是 sum(), count()以及 avg()。 有关详细信息,请参阅 聚合函数类型一目了然。
选择:添加和删除列
当你更多地使用查询时,你可能会发现,你拥有的信息比所需的更多(即表中有太多的列)。 或者,可能需要比你拥有的更多信息(也就是说,需要添加包含其他列分析结果的新列)。 让我们看一下列操作的一些关键运算符。
Project和投射
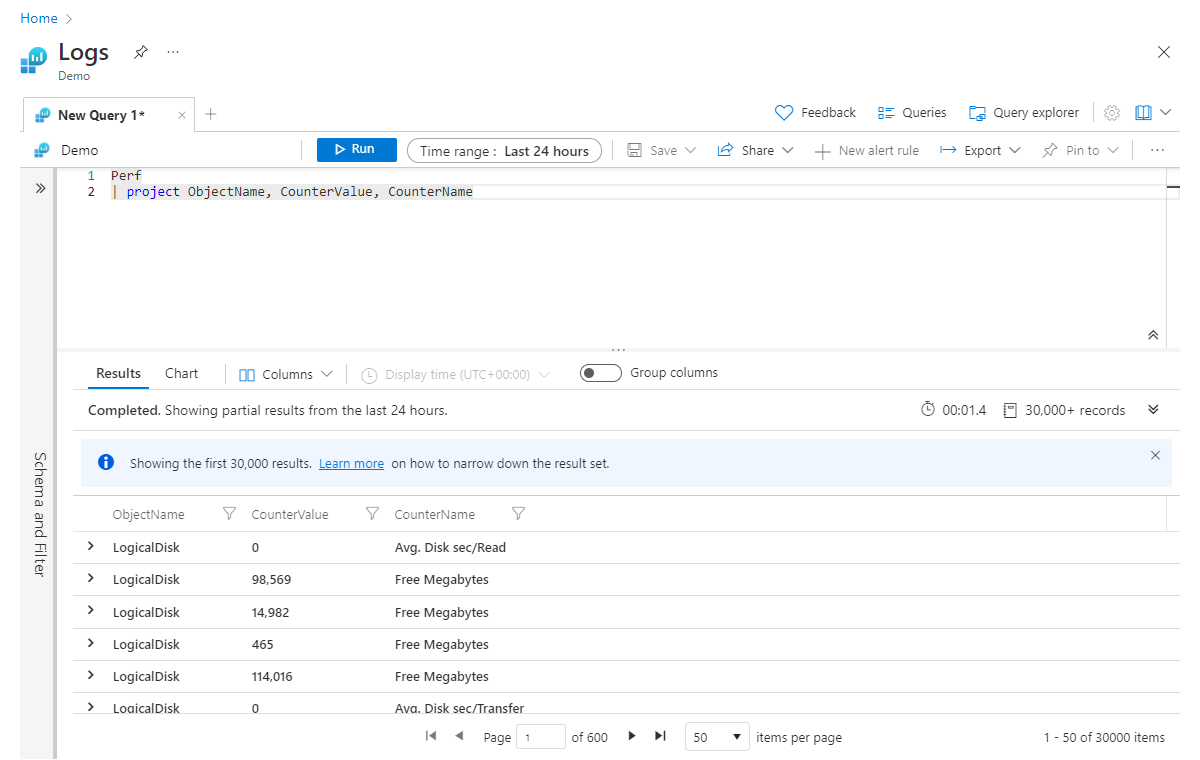
Project大致相当于多种语言的选择语句。 它允许您选择保留哪些列。 返回的列的顺序与语句中 project 列出列的顺序匹配,如以下示例所示:
Perf
| project ObjectName, CounterValue, CounterName
可以想象,使用宽数据集时,你可能有很多要保留的列,并按名称指定所有这些列需要大量键入。 对于这些情况,你有 project-away,这样就可以指定要删除的列,而不是要保留哪些列,如下所示:
Perf
| project-away MG, _ResourceId, Type
小窍门
在查询中,在开头和末尾使用project会很有用。 在查询开始时使用 project 可以通过去除无需传递到流水线的大数据块来提高性能。 在最后再次使用它,可以去除之前步骤中创建并在最终输出中不需要的任何列。
Extend
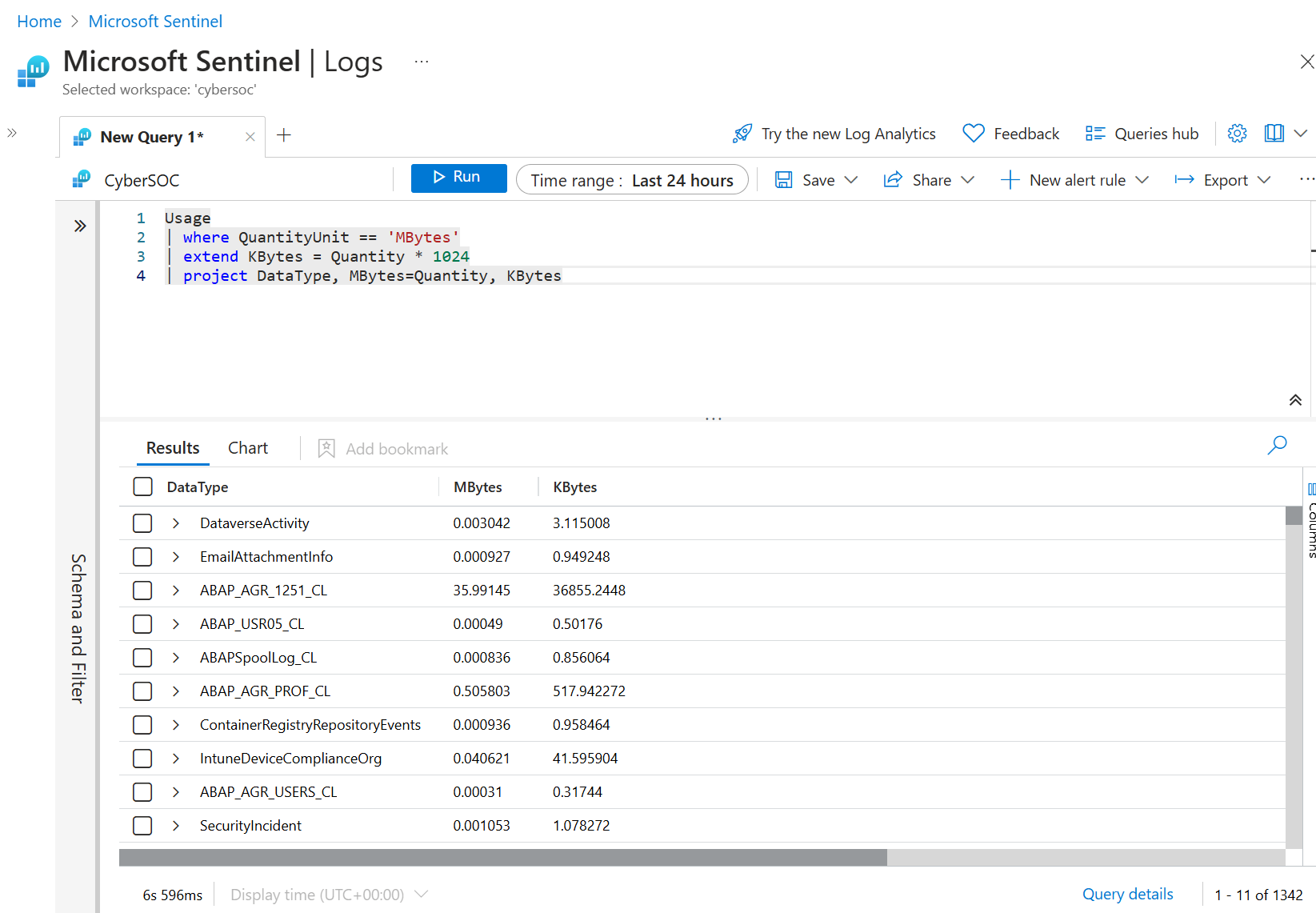
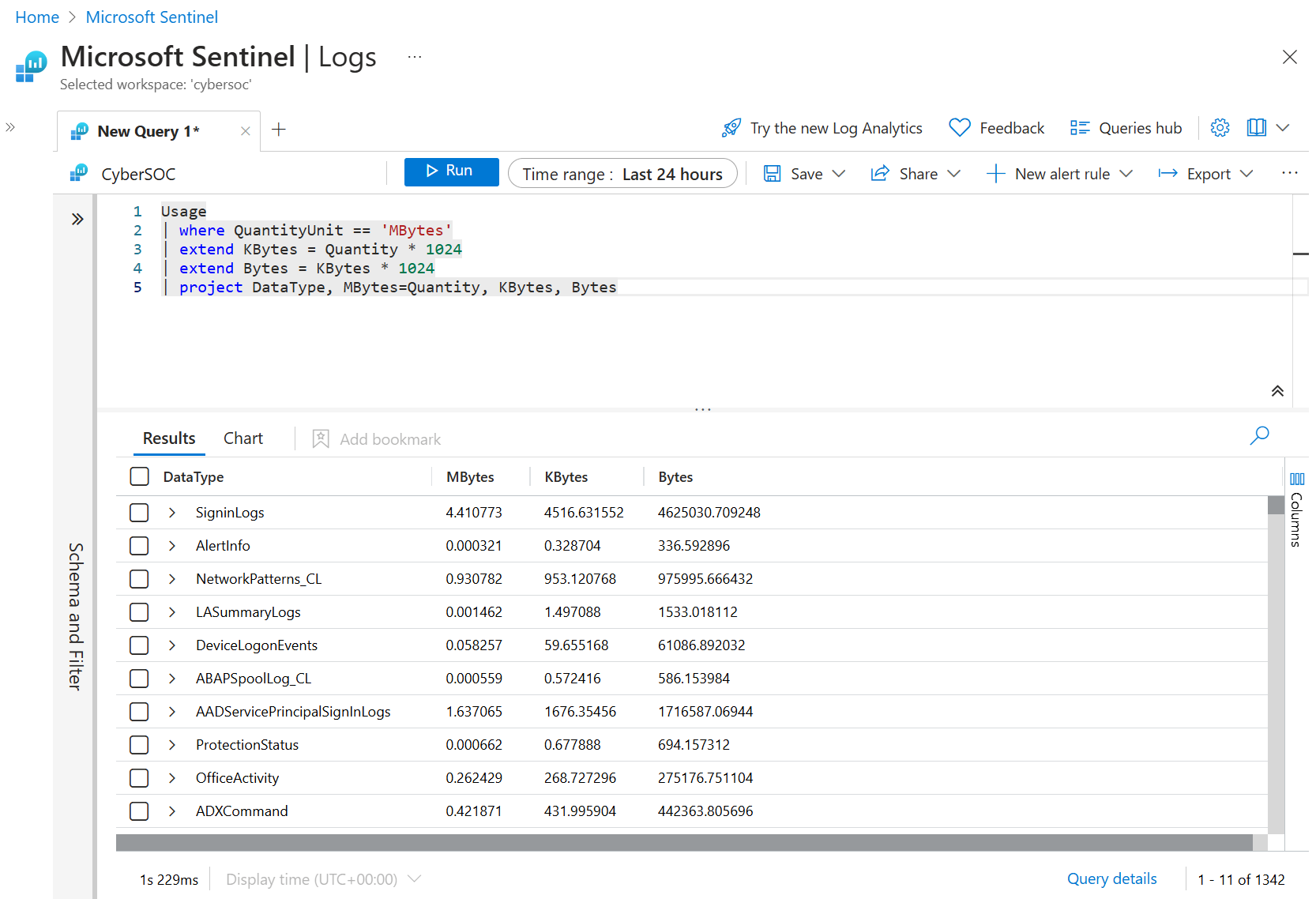
使用 Extend 创建新的计算列。 如果要对现有列执行计算,并查看每行的输出,此方法非常有用。 让我们看一个简单的示例,在其中计算一个名为 Kbytes 的新列,通过将 MB 值(在现有 数量 列中)乘以 1,024 来计算该列。
Usage
| where QuantityUnit == 'MBytes'
| extend KBytes = Quantity * 1024
| project DataType, MBytes=Quantity, KBytes
在语句的最后一行 project 中,将 Quantity 列重命名为 Mbytes,以便可以轻松判断哪个度量单位与每列相关。
值得注意的是,extend 也适用于已经计算过的列。 例如,可以添加一个名为 Bytes 的列,该列是从 Kbytes 计算得出的:
Usage
| where QuantityUnit == 'MBytes'
| extend KBytes = Quantity * 1024
| extend Bytes = KBytes * 1024
| project DataType, MBytes=Quantity, KBytes, Bytes
联接表
可以使用单个日志类型在 Microsoft Sentinel 中执行大量工作,但有时需要将数据关联在一起,或者对另一组数据执行查找。 与大多数查询语言一样,Kusto 查询语言提供了一些可用于执行各种类型的联接的运算符。 在本部分中,你将了解最常用的运算符和 unionjoin。
Union
并集 结合两个或多个表并返回所有行。 例如:
OfficeActivity
| union SecurityEvent
此查询返回 OfficeActivity 和 SecurityEvent 表中的所有行。
Union 提供了一些参数,可用于调整联合的行为方式。 其中两个最有用的参数是 包含源代码 和 种类:
OfficeActivity
| union withsource = SourceTable kind = inner SecurityEvent
使用 withsource 参数指定新列的名称,该列在给定行中的值是行所在的表的名称。 在此示例中,将列 SourceTable命名,并且根据行,该值为 OfficeActivity 或 SecurityEvent。
指定的另一个参数是 类型,它具有两个选项: 内部 或 外部。 在该示例中,指定 内,这意味着合并时只保留两个表中都存在的列。 或者,如果指定 外部 值(即默认值),则查询将返回这两个表中的所有列。
加入
联接 的工作方式与 union 类似,但不是通过联接表来创建新表,而是通过联接 行 来创建新表。 与大多数数据库语言一样,可以执行多种类型的联接。
join 的一般语法为:
T1
| join kind = <join type>
(
T2
) on $left.<T1Column> == $right.<T2Column>
在 join 运算符之后,指定要执行的联接类型,后接一个左括号。 在括号中,指定要联接的表,并在 该 表上添加任何其他查询语句。 在右括号后,使用on关键字,然后使用左侧$left.<columnName>关键字和右侧$right.<columnName>关键字之间的==运算符将两列分隔开。 下面是 内部联接的示例:
OfficeActivity
| where TimeGenerated >= ago(1d)
and LogonUserSid != ''
| join kind = inner (
SecurityEvent
| where TimeGenerated >= ago(1d)
and SubjectUserSid != ''
) on $left.LogonUserSid == $right.SubjectUserSid
注释
如果两个表对要对其执行联接的列具有相同的名称,则无需使用 $left 和 $right。 你只需指定列名。 但是,使用 $left 和 $right 更为明确,通常被视为一种好的做法。
小窍门
最佳做法是将最小的表放在左侧。 在某些情况下,遵循此规则可以带来巨大的性能优势,具体取决于要执行的联接类型以及表的大小。
有关详细信息,请参阅 联接运算符。
Evaluate
你可能记得,在第一个示例中,你看到其中一行有评估运算符。 运算符 evaluate 的用法不如前面讨论的运算符少。 但是,了解 evaluate 运算符的工作方式非常值得投入时间。 再次,这是第一个查询,可以在第二行看到 evaluate。
SigninLogs
| evaluate bag_unpack(LocationDetails)
| where RiskLevelDuringSignIn == 'none'
and TimeGenerated >= ago(7d)
| summarize Count = count() by city
| sort by Count desc
| take 5
此运算符调用可用的插件(内置函数)。 其中许多插件侧重于数据科学,例如 autocluster、 diffpatterns 和 sequence_detect。 使用这些插件,可以执行高级分析和发现统计异常和离群值。
此示例中使用的插件称为 bag_unpack。 它使获取一大块动态数据并将其转换为列变得简单。 请记住, 动态数据 是类似于 JSON 的数据类型,如以下示例所示:
{
"countryOrRegion":"US",
"geoCoordinates": {
"longitude":-122.12094116210936,
"latitude":47.68050003051758
},
"state":"Washington",
"city":"Redmond"
}
在这种情况下,你想要按城市汇总数据,但 城市 作为 LocationDetails 列中的属性包含。 若要在查询中使用 城市 属性,需要先使用 bag_unpack将其转换为列。
返回到原始管道步骤,你看到的是:
Get Data | Filter | Summarize | Sort | Select
现在,你已考虑了evaluate运算符后,可以看到它表示管道中的新阶段,如下所示:
Get Data | Parse | Filter | Summarize | Sort | Select
存在许多其他运算符和函数示例,可用于将数据源分析为更具可读性和可操作的格式。 在 Kusto 查询语言学习资源和工作簿中了解它们以及 Kusto 查询语言的其余部分。
Let 语句
现在,我们已经介绍了许多主要的运算符和数据类型,让我们总结一下 let 语句,这是让你的查询更易于读取、编辑和维护的好方法。
允许 创建和设置变量,或将名称分配给表达式。 此表达式可以是单个值,但它也可以是整个查询。 下面是一个简单示例:
let aWeekAgo = ago(7d);
SigninLogs
| where TimeGenerated >= aWeekAgo
在这里,我们指定了 aWeekAgo 的名称,并将其设置为等于 时间跨度 函数的输出,该函数返回 日期/时间 值。 然后,我们使用分号终止 let 语句。 现在,我们有一个名为 aWeekAgo 的新变量,可在查询中的任何位置使用。
如前所述,可以使用 let 语句获取整个查询,并为结果命名。 由于查询结果(作为表格表达式)可用作查询的输入,因此可以将此命名结果视为表,以便运行另一个查询。 下面是对上一个示例的轻微修改:
let aWeekAgo = ago(7d);
let getSignins = SigninLogs
| where TimeGenerated >= aWeekAgo;
getSignins
在本例中,我们创建了第二个 let 语句,在该语句中,我们将整个查询包装成名为 getSignins 的新变量。 就像以前一样,我们用分号终止第二个 let 语句。 然后,我们在运行查询的最后一行上调用变量。 请注意,我们能够在第二个 let 语句中使用 aWeekAgo。 这是因为我们在上一行中指定了它;如果我们要交换 let 语句,以便 getSignins 先来,我们将收到错误。
现在,我们可以使用 getSignins 作为另一个查询的基础(在同一窗口中):
let aWeekAgo = ago(7d);
let getSignins = SigninLogs
| where TimeGenerated >= aWeekAgo;
getSignins
| where level >= 3
| project IPAddress, UserDisplayName, Level
Let 语句可让你更强大和灵活地帮助组织查询。 让我们 定义标量值和表格值,以及创建用户定义的函数。 当你构建可能执行多个联接的更复杂查询时,它们非常有用。
后续步骤
充分利用 Microsoft Sentinel 自带的 Kusto 查询语言工作簿——Microsoft Sentinel 的高级 KQL 工作簿。 它为你提供了许多在日常安全作中可能遇到的情况的分步帮助和示例,并指出了大量现成的现成分析规则、工作簿、搜寻规则以及更多使用 Kusto 查询的元素示例。 从Microsoft Sentinel 中的 “工作簿 ”页启动此工作簿。
有关详细信息,请参见: