适用于: Azure 数据工厂 Azure Synapse Analytics
Azure 数据工厂 Azure Synapse Analytics
本文帮助你了解 Azure 数据工厂和 Azure Synapse Analytics 中的管道参数和变量之间的差异,以及如何使用它们来控制管道行为。
管道参数
参数在管道级别定义,在管道运行期间无法修改。 管道参数可用于控制管道的行为及其活动,例如通过传入数据集的连接详细信息或要处理的文件的路径。
如何定义管道参数
若要定义管道参数,请执行以下步骤:
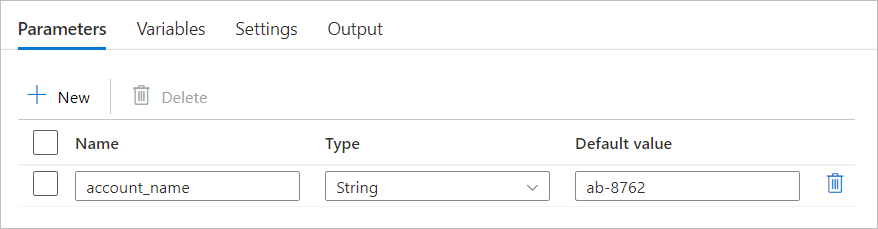
- 选择管道以查看其配置选项卡。
- 选择“参数”选项卡,然后选择“+ 新建”按钮以定义新参数。
- 输入参数的名称和说明,然后从下拉菜单中选择其数据类型。 数据类型可以是 String、Int、Float、Bool、Array、Object 或 SecureString。
- (可选)还可为参数分配默认值。
定义管道参数后,可以在管道运行期间使用管道活动中的 @pipeline().parameters.<parameter name> 表达式访问该参数的值。 例如,如果你定义了一个名为 account_name、类型为 String 的参数,可以使用表达式 @pipeline().parameters.account_name 在活动中访问其值。
在每个管道运行之前,可以在右侧面板中为参数分配一个新值,否则管道将使用默认值或之前定义的值。
管道变量
管道变量是可以在管道运行期间设置和修改的值。 与管道参数不同,这些参数在管道级别定义,在管道运行期间无法更改,可以使用 “设置变量” 活动在管道中设置和修改管道变量。
管道变量可用于在管道运行期间存储和操作数据,例如通过存储计算结果或进程的当前状态。
注意
变量目前在管道级别范围内。 这意味着,如果从并行迭代活动(如 foreach 循环)中访问它们,则它们不是线程安全的,并且可能会导致意外和不需要的行为,尤其是在该值也在该 foreach 活动中修改时。
若要定义管道变量,请执行以下步骤:
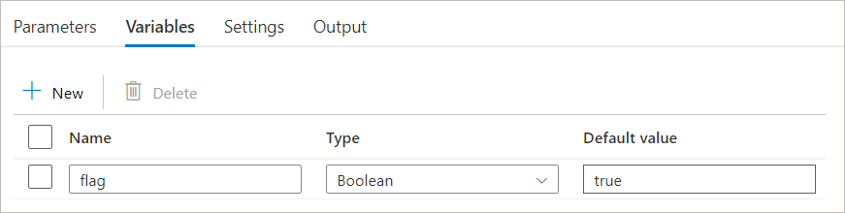
选择管道以查看其配置选项卡。
选择“变量”选项卡,然后选择“+ 新建”按钮以定义新变量。
输入变量的名称和说明,然后从下拉菜单中选择其数据类型。 数据类型可以是 String、Bool 或 Array。
(可选)还可为变量分配默认值。 在管道运行开始时,此值将用作变量的初始值。
定义管道变量后,可以在管道运行期间使用管道活动中的 @variables('<variable name>') 表达式访问该变量的值。 例如,如果你定义了一个名为 flag 的、类型为 Array 的变量,可以使用表达式 @variables('flag') 在活动中访问其值。 还可以使用“设置变量”活动在管道中修改变量的值。
相关内容
参阅以下教程,了解创建包含以下活动的管道的分步说明: