适用于: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
通过使用映射数据流中的代码片段,可以轻松执行重复数据删除和 null 筛选等常见任务。 本文介绍如何使用数据流脚本代码片段轻松地将这些功能添加到管道。
创建管道
选择“新建管道”。
添加数据流活动。
选择“源设置”选项卡,添加源转换,然后将其连接到某个数据集。
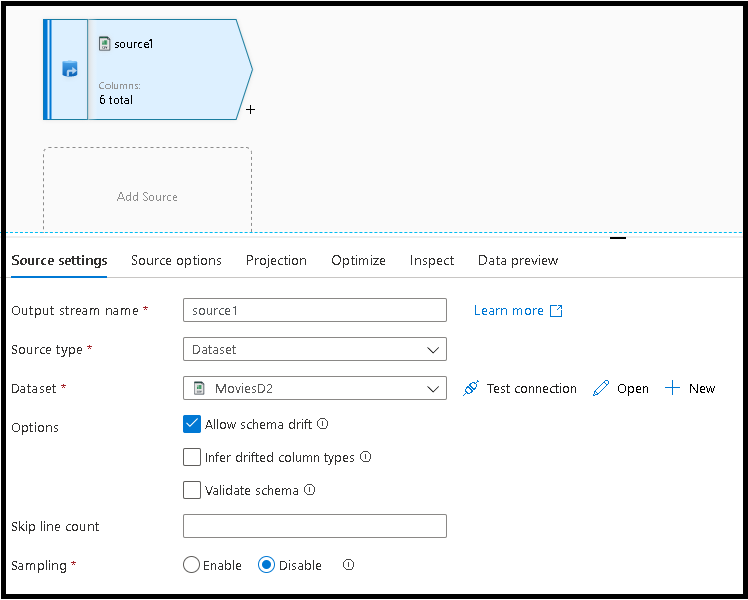
去重和空值检查代码片段使用通用模式来利用数据流架构漂移。 代码片段适用于数据集中的任何架构,或没有预定义架构的数据集。
在数据流脚本 (DFS) 的“使用所有列的不同行”部分中,复制 DistinctRows 的代码片段。
-

在脚本中,在
source1的定义后,按 Enter,然后粘贴代码片段。执行以下操作之一:
将此粘贴的代码片段连接到你之前在图中创建的源转换,方法是在粘贴的代码前输入 source1。
或者,可以通过从图中的新转换节点选择传入流,在设计器中连接新转换。
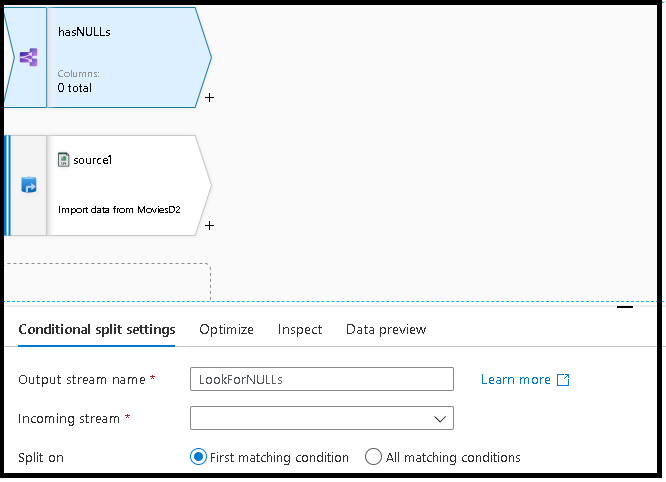
现在,数据流将使用聚合转换从源删除重复行,聚合转换通过对所有列值使用通用哈希来按所有行分组。
添加一个代码片段,用于将数据拆分为一个包含带 null 的行的流,以及另一个不含 null 的流。 为此,请执行以下操作:
-
b. 在数据流设计器中,再次选择“脚本”,然后在底部粘贴此新转换代码。 此操作通过将该转换的名称置于粘贴的代码片段前面,将脚本连接到之前的转换。
数据流图现在应如下所示:
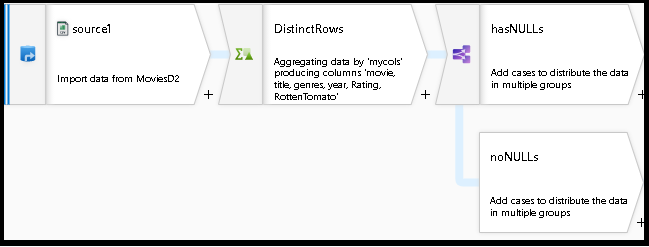
现在,你已从数据流脚本库获取现有代码片段并将其添加到现有设计,从而创建了一个工作数据流,并进行了泛型去重和空值检查。
相关内容
- 使用映射数据流转换来构建数据流逻辑的其余部分。