适用于: Azure 数据工厂 Azure Synapse Analytics
Azure 数据工厂 Azure Synapse Analytics
使用映射数据流时数据工厂中的一个常见场景是,将转换后的数据写入 Azure SQL 数据库中的数据库。 在此场景中,必须防止的一种常见错误情况是可能的列截断。
在 ADF 数据流中将数据写入数据库接收器时,有两种主要方法可用于正常处理错误:
- 在处理数据库数据时,将接收器错误行处理设置为“出错时继续”。 这是一种自动的综合方法,不需要在数据流中使用自定义逻辑。
- 也可按照以下步骤提供不适合目标字符串列的列日志记录,从而允许数据流继续运行。
注意
启用自动错误行处理时,与下面编写你自己的错误处理逻辑这一方法不同,数据工厂执行 2 阶段操作以捕获错误时将引起较小的性能损失,并且将采取额外的步骤。
场景
我们有一个包含名为“name”的
nvarchar(5)列的目标数据库表。在数据流中,我们想要将接收器中的电影标题映射到该目标“name”列。
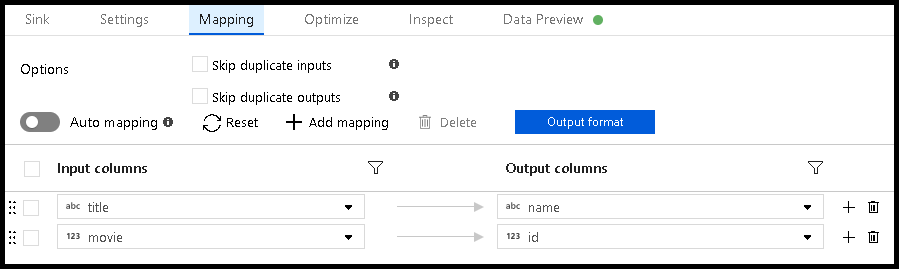
问题在于,电影标题无法全部放在接收器列中,这一列只能容纳 5 个字符。 在执行此数据流时,你回收到如下错误:
"Job failed due to reason: DF-SYS-01 at Sink 'WriteToDatabase': java.sql.BatchUpdateException: String or binary data would be truncated. java.sql.BatchUpdateException: String or binary data would be truncated."
如何围绕此情况进行设计
在此场景中,“name”列的最大长度为 5 个字符。 因此,让我们添加一个有条件拆分转换,该转换允许我们记录“title”长度超过 5 个字符的行,同时还允许可以放入该空间的其余行写入数据库。
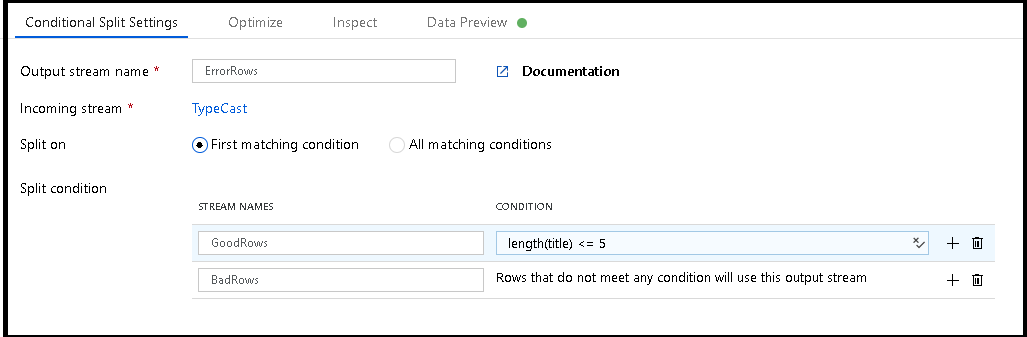
此有条件拆分转换将“title”的最大长度定义为 5 个字符。 任何小于或等于 5 的行都会进入
GoodRows流中。 任何大于 5 的行都会进入BadRows流中。现在,我们需要记录失败的行。 将接收器转换添加到
BadRows流以进行日志记录。 在这里,我们“自动映射”所有字段,以便记录完整的事务记录。 这是一个以文本分隔的 CSV 文件输出,流向 Blob 存储中的单个文件。 我们调用日志文件“badrows.csv”。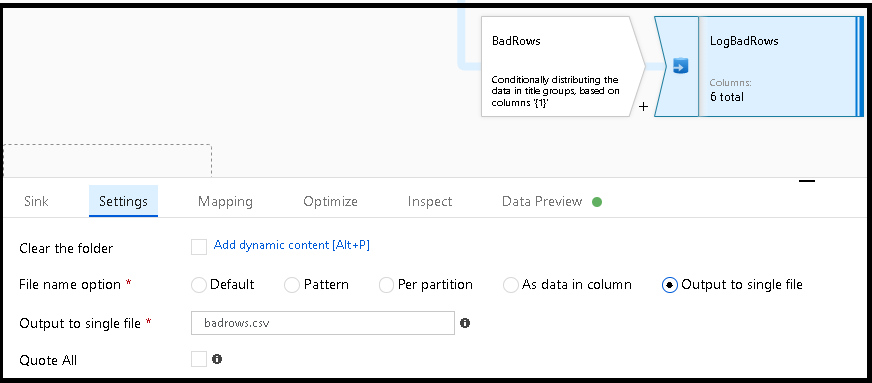
已完成的数据流如下所示。 现在,我们可以拆分错误行以避免 SQL 截断错误,并将这些条目放入日志文件中。 同时,成功的行可以继续写入目标数据库。
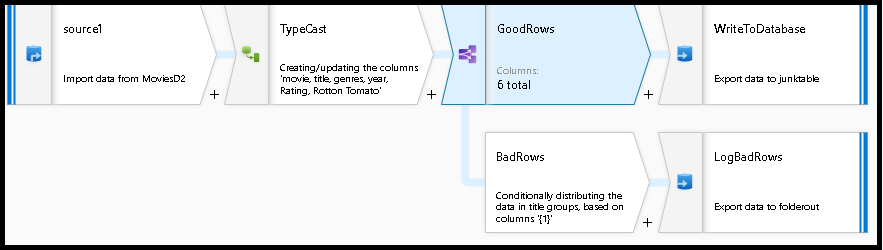
如果在接收器转换中选择“错误行处理”选项并设置“输出错误行”,Azure 数据工厂将自动生成行数据的 CSV 文件输出以及驱动程序报告的错误消息。 无需手动将该逻辑添加到具有该替代选项的数据流。 使用此选项时,ADF 可以实现一种两阶段方法来捕获错误并记录这些错误,但会导致轻微的性能损失。

相关内容
- 使用映射数据流转换来生成数据流逻辑的其余部分。