适用于: Azure 数据工厂 Azure Synapse Analytics
Azure 数据工厂 Azure Synapse Analytics
通过在 Azure 数据工厂中使用映射数据流,可以从定宽的文本文件转换数据。 在以下任务中,我们将为不带分隔符的文本文件定义数据集,然后基于序号位置设置子字符串拆分。
创建管道
选择“+新建管道”以创建新管道。
添加一个数据流活动,该活动将用于处理定宽的文件:

在数据流活动中,选择“新建映射数据流”。
添加源、派生列、选择和接收器转换:
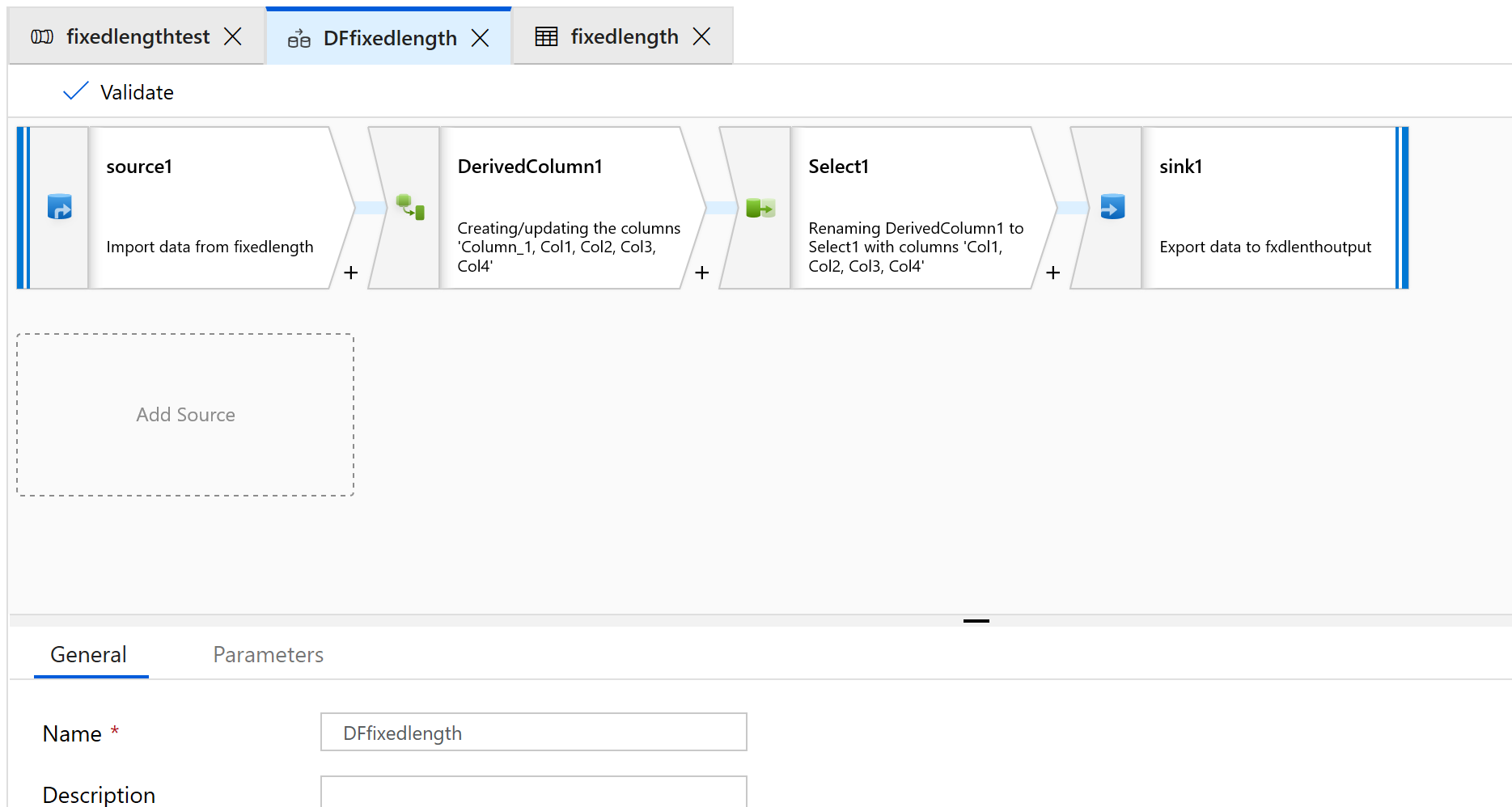
配置源转换以使用新的数据集,该数据集将是带分隔符的文本类型。
不要设置任何列分隔符或标头。
现在,我们将为该文件的内容设置字段起点和长度:
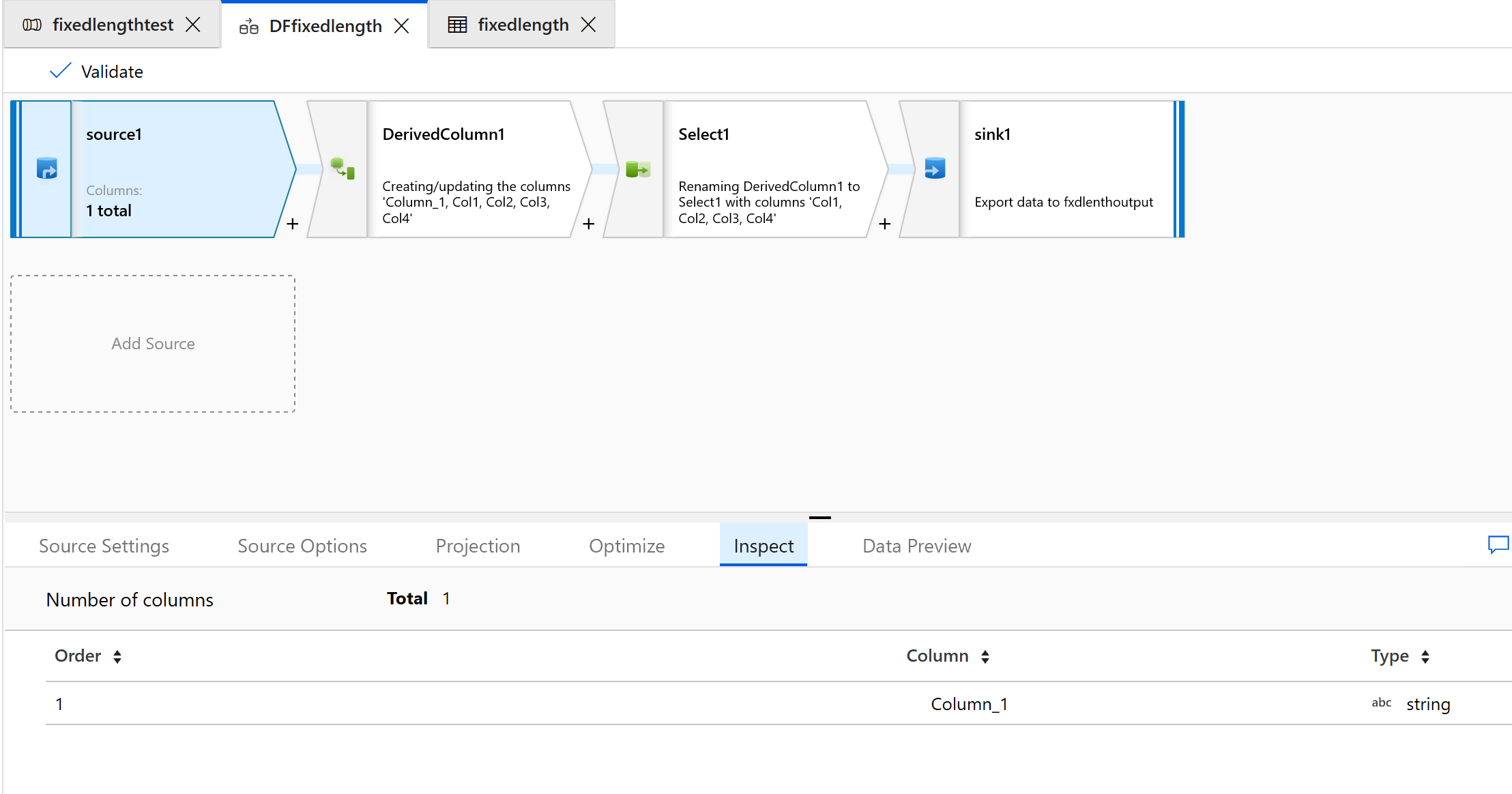
1234567813572468 1234567813572468 1234567813572468 1234567813572468 1234567813572468 1234567813572468 1234567813572468 1234567813572468 1234567813572468 1234567813572468 1234567813572468 1234567813572468 1234567813572468在源转换的“投影”选项卡上,应该可以看到名为“Column_1”的字符串列。
在派生列中,创建一个新列。
我们将为列指定简单名称,如 col1。
在表达式生成器中,键入以下内容:
substring(Column_1,1,4)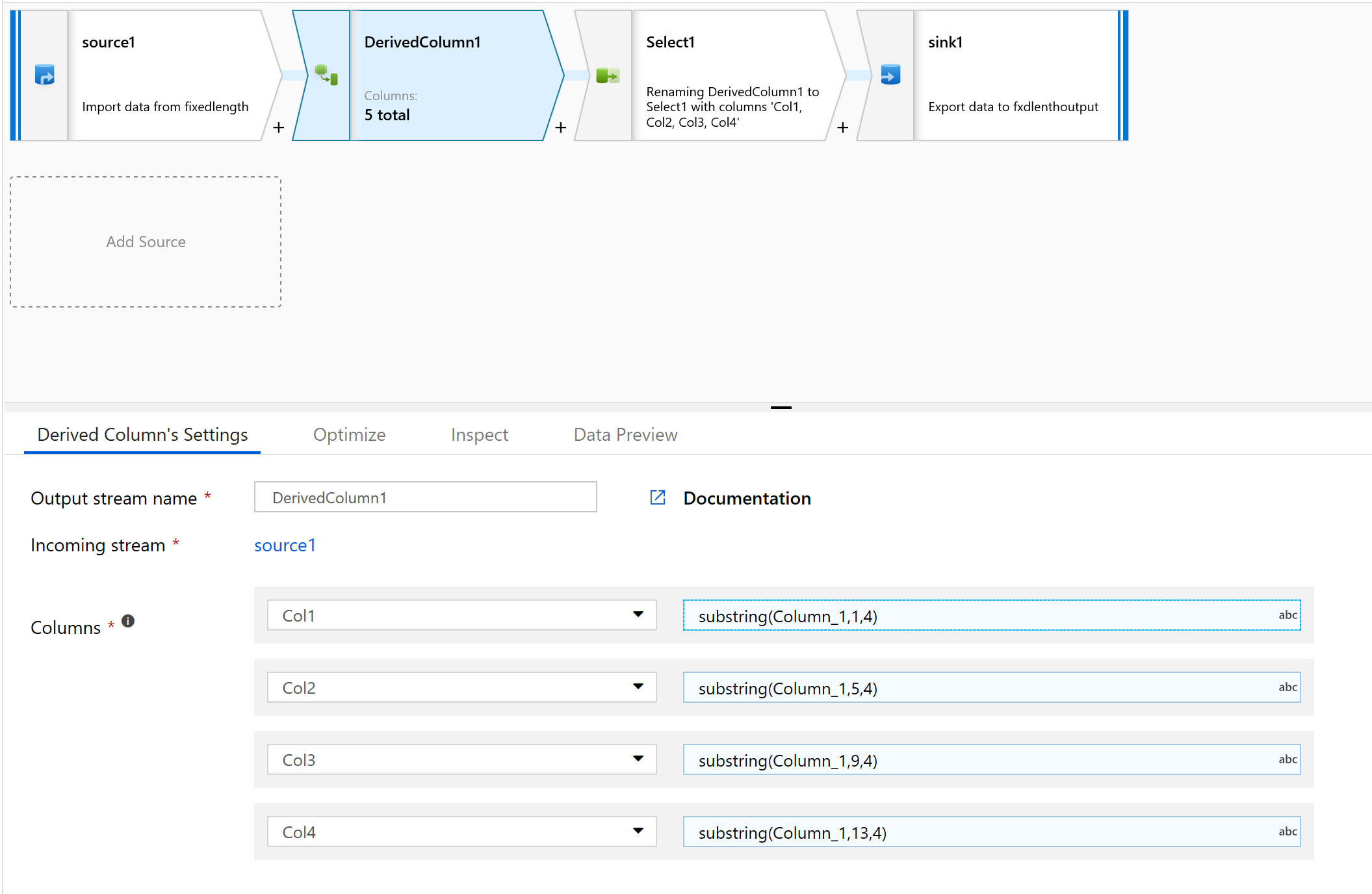
对需要解析的所有列重复步骤 10。
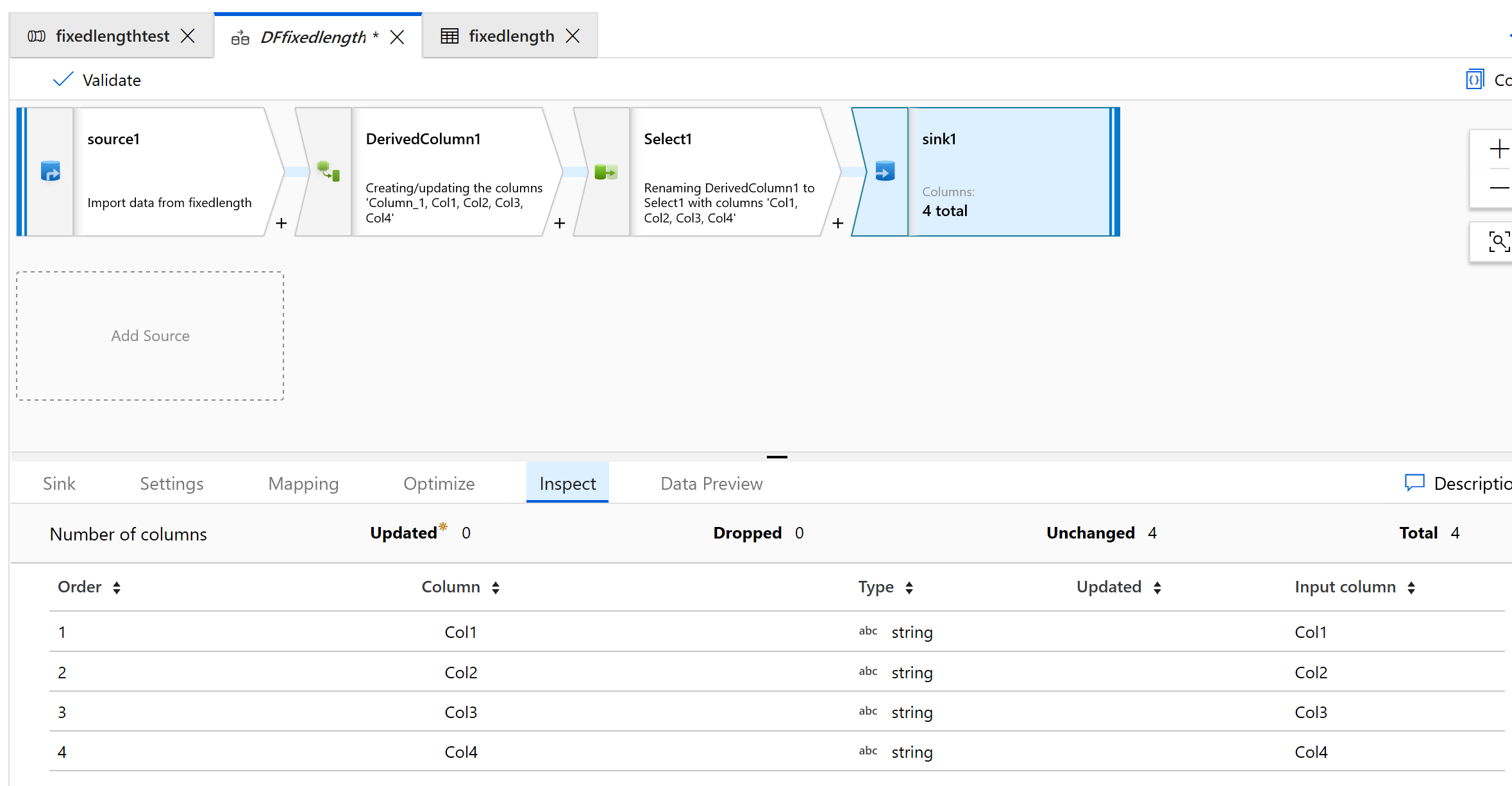
选择“检查”选项卡以查看将要生成的新列:
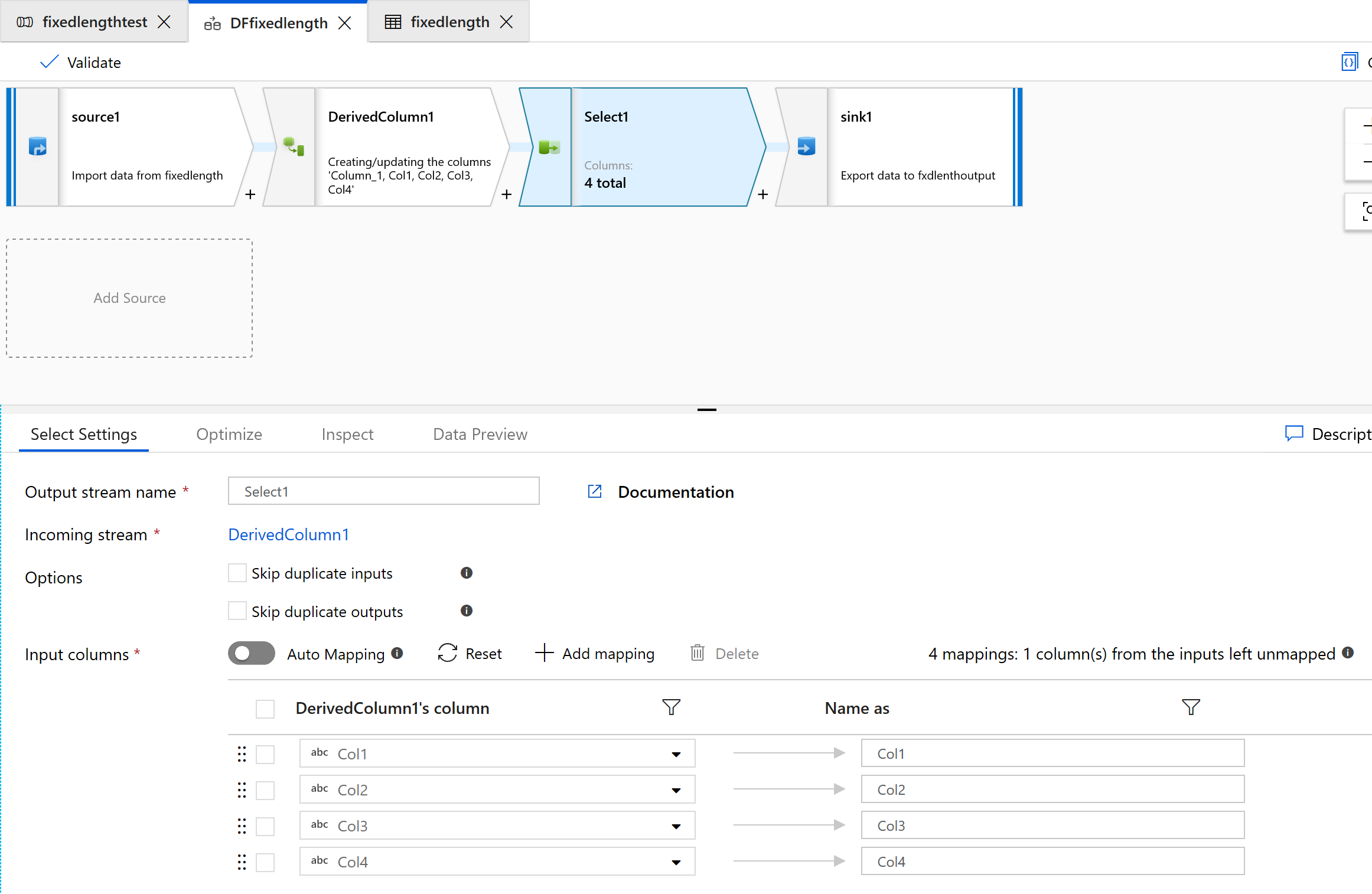
使用选择转换来删除不需要转换的任何列:
使用接收器将数据输出到文件夹:
下面是输出的效果:
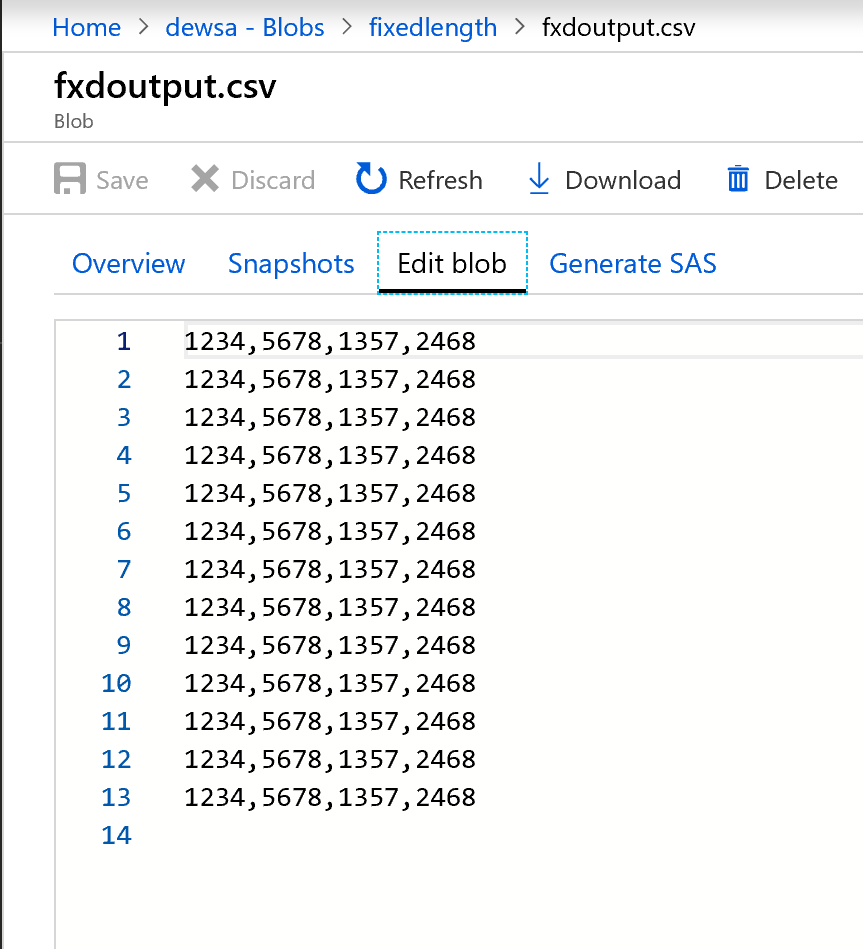
现在,将定宽数据拆分,每个有四个字符,并分配到 Col1、Col2、Col3、Col4 等。 根据前面的示例,将数据拆分为四列。
相关内容
- 使用映射数据流转换来生成数据流逻辑的其余部分。