适用于: Azure 数据工厂 Azure Synapse Analytics
Azure 数据工厂 Azure Synapse Analytics
管道中的 Azure Databricks Python 活动在 Azure Databricks 群集中运行 Python 文件。 本文基于数据转换活动一文,它概述了数据转换和受支持的转换活动。 Azure Databricks 是一个用于运行 Apache Spark 的托管平台。
使用 UI 将 Azure Databricks 的 Python 活动添加到管道
若要在管道中使用 Azure Databricks 的 Python 活动,请完成以下步骤:
在“管道活动”窗格中搜索“Python”,然后将“Python”活动拖到管道画布上。
在画布上选择新的 Python 任务(如果尚未选中)。
选择“Azure Databricks”选项卡,选择或创建将执行 Python 活动的新 Azure Databricks 链接服务。
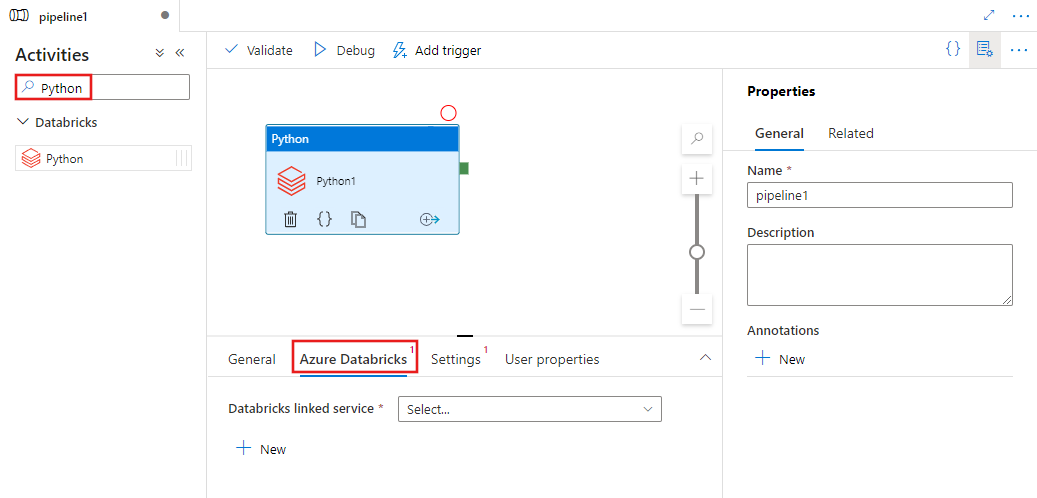
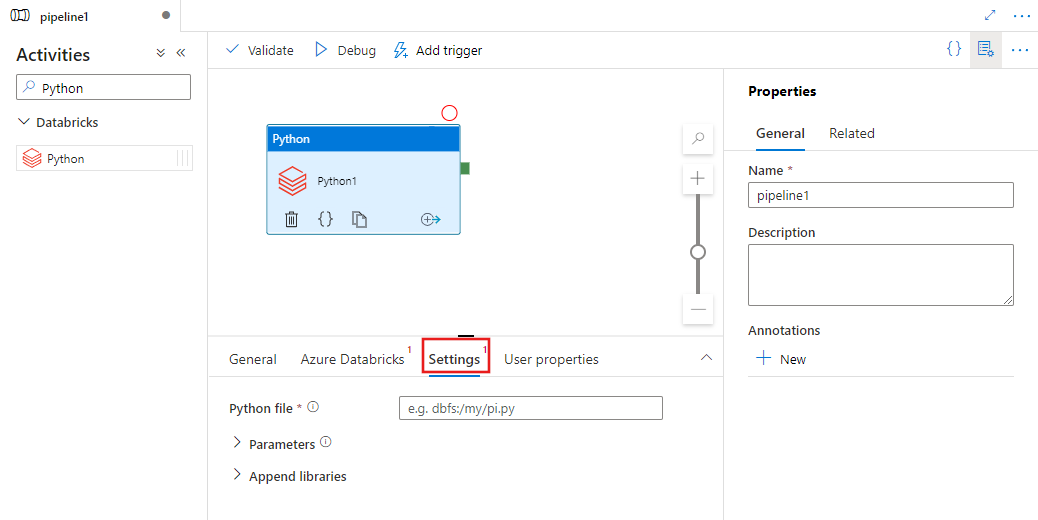
选择“设置”选项卡并指定 Azure Databricks 中要执行的 Python 文件的路径、要传递的可选参数以及要安装在群集上以执行作业的任何其他库。
Databricks Python 活动定义
下面是 Databricks Python 活动的示例 JSON 定义:
{
"activity": {
"name": "MyActivity",
"description": "MyActivity description",
"type": "DatabricksSparkPython",
"linkedServiceName": {
"referenceName": "MyDatabricksLinkedService",
"type": "LinkedServiceReference"
},
"typeProperties": {
"pythonFile": "dbfs:/docs/pi.py",
"parameters": [
"10"
],
"libraries": [
{
"pypi": {
"package": "tensorflow"
}
}
]
}
}
}
Databricks Python 活动属性
下表描述了 JSON 定义中使用的 JSON 属性:
| 属性 | 描述 | 必填 |
|---|---|---|
| 名称 | 管道中活动的名称。 | 是 |
| 描述 | 描述活动用途的文本。 | 否 |
| 类型 | 对于 Databricks Python 活动,活动类型是 DatabricksSparkPython。 | 是 |
| 关联服务名称 | Databricks 链接服务的名称,Python 活动在其上运行。 若要了解此链接服务,请参阅计算链接服务一文。 | 是 |
| pythonFile | 要执行的 Python 文件的 URI。 仅支持 DBFS 路径。 | 是 |
| 参数 | 将传递到 Python 文件的命令行参数。 这是一个字符串数组。 | 否 |
| 库 | 要安装在将执行作业的群集上的库列表。 它可以是 <字符串、对象> 数组。 | 否 |
Databricks 活动中支持的库
在以上 Databricks 活动定义中,指定这些库类型:jar、egg、maven、pypi、cran。
{
"libraries": [
{
"jar": "dbfs:/mnt/libraries/library.jar"
},
{
"egg": "dbfs:/mnt/libraries/library.egg"
},
{
"maven": {
"coordinates": "org.jsoup:jsoup:1.7.2",
"exclusions": [ "slf4j:slf4j" ]
}
},
{
"pypi": {
"package": "simplejson",
"repo": "http://my-pypi-mirror.com"
}
},
{
"cran": {
"package": "ada",
"repo": "https://cran.us.r-project.org"
}
}
]
}
有关详细信息,请参阅库类型的 Databricks 文档。
如何上传 Databricks 中的库
可以使用工作区用户界面:
若要获取使用 UI 添加的库的 dbfs 路径,可以使用 Databricks CLI。
使用 UI 时,Jar 库通常存储在 dbfs:/FileStore/jars 下。 可以通过 CLI 列出所有内容:databricks fs ls dbfs:/FileStore/job-jars
或者,可以使用 Databricks CLI:
请跟随使用 Databricks CLI 复制库的步骤进行操作
使用 Databricks CLI(安装步骤)
例如,将 JAR 复制到 dbfs:
dbfs cp SparkPi-assembly-0.1.jar dbfs:/docs/sparkpi.jar