适用于: Azure Data Factory
Azure Data Factory  Azure Synapse Analytics
Azure Synapse Analytics
pipeline 中的 Azure Synapse Notebook 活动在 Azure Synapse Analytics 工作区中运行 Synapse 笔记本。 本文基于数据转换活动一文,它概述了数据转换和受支持的转换活动。
可以通过 Azure Data Factory Studio 用户界面直接创建Azure Synapse Analytics笔记本活动。 有关如何使用用户界面创建 Synapse 笔记本活动的分步演练,可以参考以下内容。
使用 UI 向管道添加一个 Synapse 笔记本活动
若要在管道中使用 Synapse 的笔记本活动,请完成以下步骤:
常规设置
- 在管道“活动”窗格中搜索笔记本,然后将 Synapse 下的笔记本活动拖动到管道画布上。
- 在画布上选择新的“Notebook”活动(如果尚未选择)。
- 在“常规”设置中,输入 sample 作为名称。
- (选项)也可以输入说明。
- 超时:活动可以运行的最长时间。 默认值为 12 小时,允许的最大时间为 7 天。 格式为 D.HH:MM:SS。
- 重试:最大重试尝试次数。
- 重试间隔(秒):两次重试尝试之间的时间,以秒为单位。
- 选中“安全输出”后,活动输出将不会被日志记录捕获。
- 安全输入:选中后,活动的输入将不会记录到日志中。
Azure Synapse Analytics(工件)设置
选择Azure Synapse Analytics(Artifacts)选项卡,以选择或创建新的Azure Synapse Analytics 连接服务来执行 Notebook 活动。

“设置”选项卡
在画布上选择新的 Synapse 笔记本功能(如果尚未选择的话)。
选择“设置”选项卡。
展开笔记本列表后,您可以在链接的 Azure Synapse Analytics(Artifacts)中选择已有的笔记本。
单击“打开”按钮,打开所选笔记本所在的链接服务页面。
注意
如果链接服务中的工作区资源 ID 为空,将禁用“打开”按钮。

选择“设置”选项卡并选择笔记本和要传递给笔记本的可选基参数。
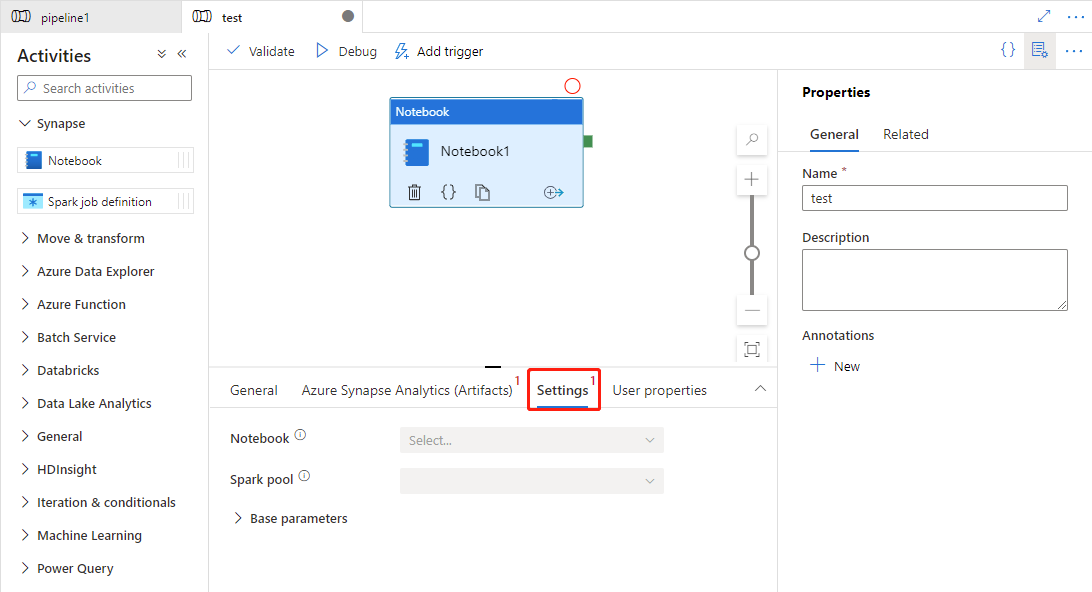
(可选)您可以填写 Synapse 笔记本的信息。 如果以下设置为空,将使用 Synapse 笔记本本身的设置来运行;如果以下设置不为空,这些设置将替换 Synapse 笔记本本身的设置。
属性 说明 Spark 池 对 Spark 池的引用。 可以从列表中选择 Apache Spark 池。 执行器大小 用于为会话在指定 Apache Spark 池中分配的执行程序的内核和内存数量。 对于动态内容,有效值为 Small/Medium/Large/XLarge/XXLarge。 动态分配执行器 此设置映射到用于 Spark 应用程序执行工具分配的 Spark 配置中的动态分配属性。 最小执行器数 要在作业的指定 Spark 池中分配的最小执行程序数。 最大执行程序数 要为作业在指定的 Spark 池中分配的最大执行程序数。 驱动程序大小 指定作业的 Apache Spark 池中用于驱动程序的核心数量和内存量。

Azure Synapse Analytics Notebook 活动定义
以下是 Azure Synapse Analytics 笔记本活动的示例 JSON 定义:
{
"activities": [
{
"name": "demo",
"description": "description",
"type": "SynapseNotebook",
"dependsOn": [],
"policy": {
"timeout": "7.00:00:00",
"retry": 0,
"retryIntervalInSeconds": 30,
"secureOutput": false,
"secureInput": false
},
"userProperties": [
{
"name": "testproperties",
"value": "test123"
}
],
"typeProperties": {
"notebook": {
"referenceName": {
"value": "Notebookname",
"type": "Expression"
},
"type": "NotebookReference"
},
"parameters": {
"test": {
"value": "testvalue",
"type": "string"
}
},
"snapshot": true,
"sparkPool": {
"referenceName": {
"value": "SampleSpark",
"type": "Expression"
},
"type": "BigDataPoolReference"
}
},
"linkedServiceName": {
"referenceName": "AzureSynapseArtifacts1",
"type": "LinkedServiceReference"
}
}
]
}
Azure Synapse Analytics Notebook 活动属性
下表描述了 JSON 定义中使用的 JSON 属性:
| 属性 | 说明 | 必需 |
|---|---|---|
| 名称 | 管道中活动的名称。 | 是 |
| 描述 | 描述活动用途的文本。 | 否 |
| 类型 | 对于 Azure Synapse Analytics 笔记本活动,活动类型为 SynapseNotebook。 | 是 |
| 笔记本 | 要在Azure Synapse Analytics中运行的笔记本的名称。 | 是 |
| sparkPool | Azure Synapse Analytics Notebook 运行所需的 Spark 池。 | 否 |
| 参数 | 运行 Azure Synapse Analytics Notebook 所需的参数。 有关详细信息,请参阅通过运行 Synapse 笔记本转换数据 | 否 |
指定参数单元格
Azure Data Factory查找参数单元格,并使用值作为执行时传入的参数的默认值。 执行引擎将使用输入参数在参数单元格下面添加新的单元格,以覆盖默认值。 可以参阅运行 Synapse 笔记本以转换数据。
读取 Synapse 笔记本单元输出值
您可以在活动中读取笔记本单元格的输出值,对于此面板,您可以参考通过运行 Synapse 笔记本转换数据。
运行另一个 Synapse 笔记本
可以通过调用 %run magic 或 mssparkutils 笔记本实用程序,在 Synapse 笔记本活动中引用其他笔记本。 两者都支持嵌套函数调用。 根据你的方案,你应该考虑的这两种方法的主要区别是:
-
%run magic 将引用的笔记本中的所有单元格复制到 %run 单元格,并共享变量上下文。 当 notebook1 通过
%run notebook2引用 notebook2,以及 notebook2 调用 mssparkutils.notebook.exit 函数时,将停止 notebook1 中的单元格执行。 如果要“包含”笔记本文件,建议使用 %run magic。 -
mssparkutils 笔记本实用程序将引用的笔记本作为方法或函数进行调用。 变量上下文不共享。 当 notebook1 通过
mssparkutils.notebook.run("notebook2")引用 notebook2,并且 notebook2 调用 mssparkutils.notebook.exit 函数时,notebook1 中的单元格将继续执行。 如果要“导入”笔记本,建议使用 mssparkutils 笔记本实用程序。
请参阅 Azure Synapse Analytics Notebook 活动运行历史记录
转到“监视”选项卡下的“管道运行”,将看到已触发的管道。 打开包含笔记本任务的管道以查看运行记录。

对于“打开笔记本快照”,当前不支持此功能。
可以通过选择“输入”或“输出”按钮查看笔记本活动输入或输出 。 如果管道因用户错误而失败,可以选择“输出”来检查“结果”字段,以查看详细的用户错误回溯 。
