注意
Databricks 建议使用审核日志系统表 (system.access.audit) 访问帐户的审核日志。 请参阅审核日志系统表参考。 Databricks 强烈建议不要将此数据移出平台,因为它可能会公开敏感数据,并使部署面临风险。 由于审核日志内容的性质,系统会提醒你负责维护任何导出的审核日志的安全,并防止滥用。
本文介绍如何为Azure Databricks工作区启用诊断日志传送。
注意
诊断日志需要高级计划。
以所有者、参与者或具有Azure Databricks工作区
Microsoft.Databricks/workspaces/assignWorkspaceAdmin/action权限的自定义角色的身份登录到Azure门户。 然后单击您的 Azure Databricks 服务资源。在侧栏的“监视”部分中,单击“诊断设置”选项卡。
单击“添加诊断设置”。
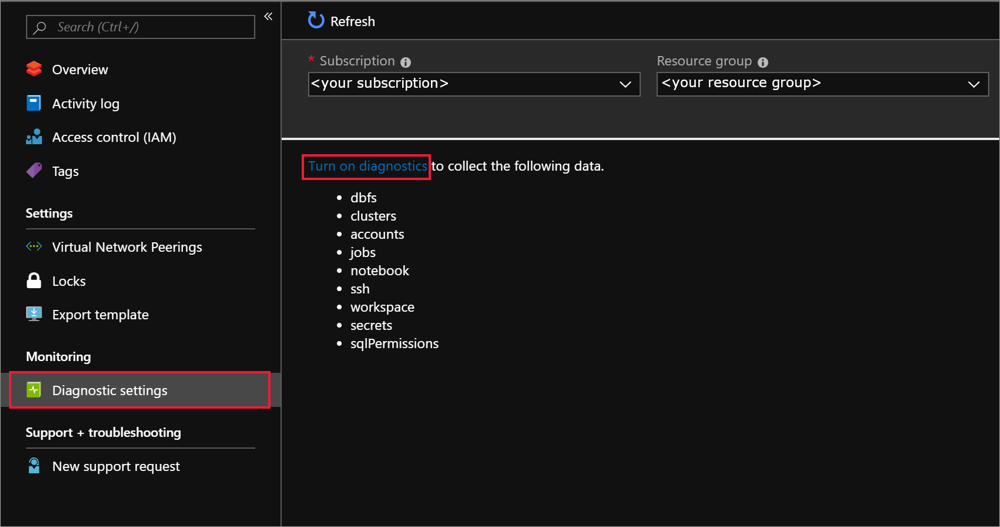
在“诊断设置”页上,提供以下配置:
名字
为要创建的日志输入名称。
存档到存储帐户
要使用此选项,需要一个可连接到的现有存储帐户。 若要在门户中创建新的存储帐户,请参阅 创建存储帐户并按照说明创建Azure 资源管理器常规用途帐户。 然后在门户中返回到此页,选择存储帐户。 新创建的存储帐户可能几分钟后才会显示在下拉菜单中。 有关写入存储帐户产生的额外费用的信息,请参阅 Azure 存储 定价。
流式传输到事件中心
要使用此选项,您需要一个现有的 Azure 事件中心 命名空间和事件中心,以便进行连接。 若要创建事件中心命名空间,请参阅使用 Azure 门户创建事件中心命名空间和事件中心。 然后,在门户中返回到此页,选择事件中心命名空间和策略名称。 有关写入事件中心 (Event Hubs) 所产生的额外费用的信息,请参阅 Azure 事件中心 定价。
发送至 Log Analytics 工作区
若要使用此选项,请使用现有的 Log Analytics 工作区,或按照门户中的步骤创建新工作区。 有关将日志发送到Log Analytics产生的附加成本的信息,请参阅 Azure Monitor 定价。
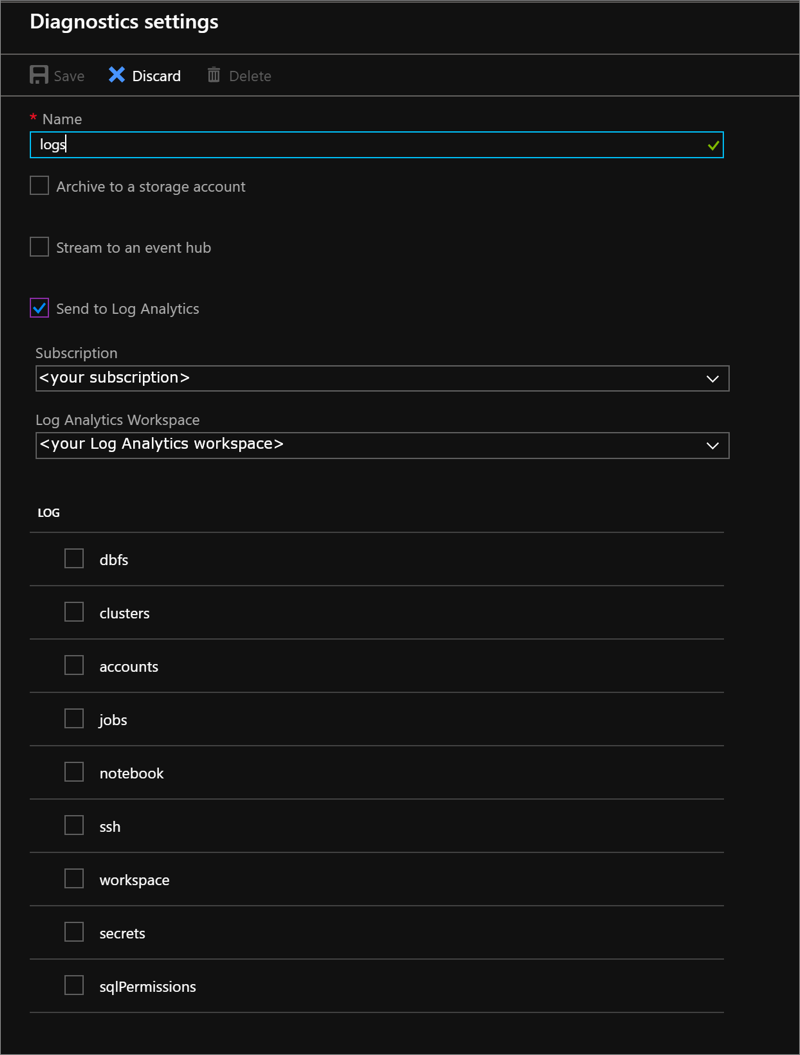
选择需要诊断日志的服务。
选择“保存”。
如果收到一条错误信息,表示“无法更新
<workspace name>的诊断。 订阅<subscription id>没有注册以使用 microsoft.insights,请按照 Troubleshoot Azure 诊断说明注册帐户,然后重试该过程。若要更改在将来的任意时间点保存诊断日志的方式,可以返回到此页,修改帐户的诊断日志设置。
注意
若要设置存储保留策略,请配置 Azure 生命周期管理策略。
使用 PowerShell 启用日志记录
使用以下命令启动Azure PowerShell会话并登录到Azure帐户:
Connect-AzAccount -Environment AzureChinaCloud若要使用用户帐户或服务主体登录到Azure帐户,请参阅 Authenticate with Azure PowerShell。
如果尚未安装Azure Powershell,请使用以下命令安装Azure PowerShell。
Install-Module -Name Az -AllowClobber在弹出窗口中,输入Azure帐户用户名和密码。 Azure PowerShell获取与此帐户关联的所有订阅,默认情况下使用第一个订阅。
如果有多个订阅,可能需要指定用于创建Azure 密钥保管库的特定订阅。 若要查看帐户的订阅,请键入以下命令:
Get-AzSubscription若要指定与 Azure Databricks 帐户关联的订阅,请键入以下命令:
Set-AzContext -SubscriptionId <subscription ID>将Log Analytics资源名称设置为名为
logAnalytics的变量,其中ResourceName是Log Analytics工作区的名称。$logAnalytics = Get-AzResource -ResourceGroupName <resource group name> -ResourceName <resource name> -ResourceType "Microsoft.OperationalInsights/workspaces"将Azure Databricks服务资源名称设置为名为
databricks的变量,其中ResourceName是Azure Databricks服务的名称。$databricks = Get-AzResource -ResourceGroupName <your resource group name> -ResourceName <your Azure Databricks service name> -ResourceType "Microsoft.Databricks/workspaces"若要为 Azure Databricks 启用日志记录,请使用 New-AzDiagnosticSetting cmdlet 指令,并为新存储帐户、Azure Databricks 服务以及要启用日志记录的类别分别设置变量。 运行以下命令,并将
-Enabled标志设置为$true:New-AzDiagnosticSetting -ResourceId $databricks.ResourceId -WorkspaceId $logAnalytics.ResourceId -Enabled $true -name "<diagnostic setting name>" -Category <comma separated list>
使用 Azure CLI 启用日志记录
打开 PowerShell。
使用以下命令连接到Azure帐户:
az cloud set -n AzureChinaCloud az login # az cloud set -n AzureCloud //means return to Azure Public Cloud.若要使用用户帐户或服务主体进行连接,请参阅 使用 Azure CLI 登录。
运行以下诊断设置命令:
az monitor diagnostic-settings create --name <diagnostic name> --resource-group <log analytics workspace resource group> --workspace <log analytics name or object ID> --resource <target resource object ID> --logs '[ { \"category\": <category name>, \"enabled\": true } ]'
REST API
使用 LogSettings API。
请求
PUT https://management.chinacloudapi.cn/{resourceUri}/providers/microsoft.insights/diagnosticSettings/{name}?api-version=2017-05-01-preview
请求正文
{
"properties": {
"workspaceId": "<log analytics resourceId>",
"logs": [
{
"category": "<category name>",
"enabled": true,
"retentionPolicy": {
"enabled": false,
"days": 0
}
}
]
}
}
诊断日志延迟
为您的帐户启用日志记录后,Azure Databricks 会自动将诊断日志发送到日志传输位置。 日志通常会在激活后的 15 分钟内可用。 Azure Databricks可审核事件通常在 Azure 商业区域中的 15 分钟内出现在诊断日志中。
SSH 登录日志的传送延迟很高。
注意
虽然预计大多数日志将在 15 分钟内传递,但Azure Databricks不能保证日志传递的时限。
诊断日志架构注意事项
- 如果操作花费很长时间,则会单独记录请求和响应,但请求和响应对具有相同的
requestId。 - 自动化操作(例如,由于自动缩放而重设群集大小,或由于调度而启动作业)由用户
System-User执行。 - 字段
requestParams的内容可能会被截断。 如果其 JSON 表示形式的大小超过 100 KB,则值会截断,字符串... truncated会追加到截断的条目。 在极少数情况下,如果截断后的映射仍然大于 100 KB,则会用一个具有空值的单个TRUNCATED键来代替。
诊断日志示例架构
审计日志以 JSON 格式输出事件。 属性serviceNameactionName标识事件。 命名约定遵循 Databricks REST API。
以下 JSON 示例是用户创建作业时记录的事件示例:
{
"TenantId": "<your-tenant-id>",
"SourceSystem": "|Databricks|",
"TimeGenerated": "2019-05-01T00:18:58Z",
"ResourceId": "/SUBSCRIPTIONS/SUBSCRIPTION_ID/RESOURCEGROUPS/RESOURCE_GROUP/PROVIDERS/MICROSOFT.DATABRICKS/WORKSPACES/PAID-VNET-ADB-PORTAL",
"OperationName": "Microsoft.Databricks/jobs/create",
"OperationVersion": "1.0.0",
"Category": "jobs",
"Identity": {
"email": "mail@example.com",
"subjectName": null
},
"SourceIPAddress": "131.0.0.0",
"LogId": "201b6d83-396a-4f3c-9dee-65c971ddeb2b",
"ServiceName": "jobs",
"UserAgent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.108 Safari/537.36",
"SessionId": "webapp-cons-webapp-01exaj6u94682b1an89u7g166c",
"ActionName": "create",
"RequestId": "ServiceMain-206b2474f0620002",
"Response": {
"statusCode": 200,
"result": "{\"job_id\":1}"
},
"RequestParams": {
"name": "Untitled",
"new_cluster": "{\"node_type_id\":\"Standard_DS3_v2\",\"spark_version\":\"5.2.x-scala2.11\",\"num_workers\":8,\"spark_conf\":{\"spark.databricks.delta.preview.enabled\":\"true\"},\"cluster_creator\":\"JOB_LAUNCHER\",\"spark_env_vars\":{\"PYSPARK_PYTHON\":\"/databricks/python3/bin/python3\"},\"enable_elastic_disk\":true}"
},
"Type": "DatabricksJobs"
}