本文介绍了在 Azure Databricks 上运行结构化流式处理工作负载时如何将 Apache Kafka 用作源或接收器。
有关 Kafka 的详细信息,请参阅 Kafka 文档。
从 Kafka 读取数据
下面是从 Kafka 进行流式读取的示例:
df = (spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "<server:ip>")
.option("subscribe", "<topic>")
.option("startingOffsets", "latest")
.load()
)
Azure Databricks 还对 Kafka 数据源支持批量读取语义,如以下示例所示:
df = (spark
.read
.format("kafka")
.option("kafka.bootstrap.servers", "<server:ip>")
.option("subscribe", "<topic>")
.option("startingOffsets", "earliest")
.option("endingOffsets", "latest")
.load()
)
对于增量批量加载,Databricks 建议将 Kafka 与 Trigger.AvailableNow 结合使用。 请参阅配置增量批处理。
在 Databricks Runtime 13.3 LTS 及更高版本中,Azure Databricks 提供用于读取 Kafka 数据的 SQL 函数。 只有在 Lakeflow Spark 声明性管道或 Databricks SQL 的流式表中才支持用 SQL 进行流式处理。 请参阅 read_kafka 表值函数。
配置 Kafka 结构化流式处理读取器
Azure Databricks 提供了 kafka 关键字作为数据格式来配置与 Kafka 0.10+ 的连接。
下面是 Kafka 的最常见配置:
有多种方法可以指定要订阅的主题。 你应当只提供以下参数之一:
| 选项 | 值 | 说明 |
|---|---|---|
| 订阅 | 以逗号分隔的主题列表。 | 要订阅的主题列表。 |
| subscribePattern | Java 正则表达式字符串。 | 用来订阅主题的模式。 |
| 分配 | JSON 字符串 {"topicA":[0,1],"topic":[2,4]}。 |
要使用的特定 topicPartition。 |
其他值得注意的配置:
| 选项 | 值 | 默认值 | 说明 |
|---|---|---|---|
| Kafka初始设置服务器 (kafka.bootstrap.servers) | 以逗号分隔的 host:port 列表。 | 空 | [必需] Kafka bootstrap.servers 配置。 如果没有发现来自 Kafka 的数据,请先检查中转站地址列表。 如果中转站地址列表不正确,则可能没有任何错误。 这是因为,Kafka 客户端假设中转站最终将变得可用,并且在出现网络错误的情况下会永远重试。 |
| failOnDataLoss |
true 或 false。 |
true |
[可选] 在数据可能已丢失的情况下是否使查询失败。 在许多情况下(例如主题被删除、主题在处理前被截断,等等),查询可能永远也无法从 Kafka 读取数据。 我们会尝试保守地估计数据是否可能已丢失。 有时这可能会导致误报。 如果此选项无法正常工作,或者你希望查询不管数据是否丢失都继续进行处理,请将此选项设置为 false。 |
| minPartitions | 整数>= 0,0 =已禁用。 | 0(禁用) | [可选] 要从 Kafka 读取的最小分区数。 你可以使用 minPartitions 选项将 Spark 配置为使用任意最少数量的分区从 Kafka 进行读取。 通常,Spark 在 Kafka topicPartitions 与从 Kafka 使用的 Spark 分区之间存在 1-1 映射。 如果将 minPartitions 选项设置为大于 Kafka topicPartitions 的值,则 Spark 会将大型 Kafka 分区拆分为较小的部分。 可以在出现峰值负载时、数据倾斜时以及在流落后时设置此选项以提高处理速度。 这需要在每次触发时初始化 Kafka 使用者。如果你在连接到 Kafka 时使用 SSL,这可能会影响性能。 |
| kafka.group.id | Kafka 使用者组 ID。 | 未设置 | [可选] 从 Kafka 进行读取时要使用的组 ID。 请谨慎使用此项。 默认情况下,每个查询都会生成用于读取数据的唯一组 ID。 这样可以确保每个查询都有其自己的使用者组,不会受到任何其他使用者的干扰,因此可以读取其订阅的主题的所有分区。 某些情况下(例如,在进行基于 Kafka 组的授权时),你可能希望使用特定的授权组 ID 来读取数据。 你还可以设置组 ID。 但是,执行此操作时要格外小心,因为它可能会导致意外的行为。
|
| 起始偏移 | 最早、最新 | 最新 | [可选] 启动查询时的起点,可以是“最早”(从最早偏移开始),也可以是 json 字符串(指定每个 TopicPartition 的起始偏移)。 在 json 中,可使用 -2 作为偏移量来表示最早,使用 -1 表示最新。 注意:对于批处理查询,不允许使用最新(无论是隐式还是在 json 中使用 -1)。 对于流式处理查询,这仅在启动新查询时适用,并且恢复始终从查询停止的位置开始。 查询期间新发现的分区将最早启动。 |
有关其他可选配置,请参阅结构化流式处理 Kafka 集成指南。
Kafka 记录的架构
Kafka 记录的架构为:
| 列 | 类型 |
|---|---|
| 关键值 | 二进制 |
| 价值 | 二进制 |
| 主题 | 字符串 |
| 分区 | 整数 (int) |
| 偏移 | 长整型 |
| 时间戳 | 长整型 |
| 时间戳类型 | 整数 (int) |
始终使用 key 将 value 和 ByteArrayDeserializer 反序列化为字节数组。 请使用数据帧操作(例如 cast("string"))显式反序列化键和值。
将数据写入到 Kafka
下面是流式写入 Kafka 的示例:
(df
.writeStream
.format("kafka")
.option("kafka.bootstrap.servers", "<server:ip>")
.option("topic", "<topic>")
.start()
)
Azure Databricks 还对 Kafka 数据接收器支持批量写入语义,如以下示例所示:
(df
.write
.format("kafka")
.option("kafka.bootstrap.servers", "<server:ip>")
.option("topic", "<topic>")
.save()
)
配置 Kafka 结构化流式处理写入器
重要
Databricks Runtime 13.3 LTS 及更高版本包含一个较新版本的 kafka-clients 库,该库默认启用幂等写入。 如果 Kafka 接收器使用 2.8.0 或更低版本,并且配置了 ACL 但未启用 IDEMPOTENT_WRITE,则写入将会失败并出现错误消息 org.apache.kafka.common.KafkaException:Cannot execute transactional method because we are in an error state。
通过升级到 Kafka 2.8.0 或更高版本或者在配置结构化流式处理写入器时设置 .option("kafka.enable.idempotence", "false") 来解决此错误。
提供给 DataStreamWriter 的架构与 Kafka 接收器交互。 可以使用以下字段:
| 列名称 | 必需还是可选 | 类型 |
|---|---|---|
key |
可选 |
STRING 或 BINARY |
value |
必需 |
STRING 或 BINARY |
headers |
可选 | ARRAY |
topic |
可选(如果将 topic 设置为写入器选项,则忽略) |
STRING |
partition |
可选 | INT |
下面是写入 Kafka 时设置的常见选项:
| 选项 | 值 | 默认值 | 说明 |
|---|---|---|---|
kafka.boostrap.servers |
逗号分隔的 <host:port> 列表 |
无 | [必需] Kafka bootstrap.servers 配置。 |
topic |
STRING |
未设置 | [可选] 设置要写入的所有行的主题。 此选项会替代数据中存在的任何主题列。 |
includeHeaders |
BOOLEAN |
false |
[可选] 是否在行中包含 Kafka 标头。 |
有关其他可选配置,请参阅结构化流式处理 Kafka 集成指南。
检索 Kafka 指标
可以获得流式查询在所有订阅主题中最新可用偏移量之后使用的偏移量的平均值、最小值和最大值,即 avgOffsetsBehindLatest、maxOffsetsBehindLatest 和 minOffsetsBehindLatest 指标。 请参阅以交互方式读取指标。
注意
可在 Databricks Runtime 9.1 及更高版本中使用。
通过检查 estimatedTotalBytesBehindLatest 的值,获取查询进程尚未从订阅主题使用的估计总字节数。 此估计值基于在过去 300 秒内处理的批。 通过将选项 bytesEstimateWindowLength 设置为其他值,可以更改估计值所基于的时间范围。 例如,将其设置为 10 分钟:
df = (spark.readStream
.format("kafka")
.option("bytesEstimateWindowLength", "10m") # m for minutes, you can also use "600s" for 600 seconds
)
如果在笔记本中运行流,可在流式处理查询进度仪表板中的“原始数据”选项卡下查看这些指标:
{
"sources": [
{
"description": "KafkaV2[Subscribe[topic]]",
"metrics": {
"avgOffsetsBehindLatest": "4.0",
"maxOffsetsBehindLatest": "4",
"minOffsetsBehindLatest": "4",
"estimatedTotalBytesBehindLatest": "80.0"
}
}
]
}
使用 SSL 将 Azure Databricks 连接到 Kafka
若要启用到 Kafka 的 SSL 连接,请按照 Confluent 文档使用 SSL 进行加密和身份验证中的说明进行操作。 你可以提供此处所述的配置(带前缀 kafka.)作为选项。 例如,在属性 kafka.ssl.truststore.location 中指定信任存储位置。
Databricks 建议你:
- 将证书存储在云对象存储中。 你可以仅允许能够访问 Kafka 的群集访问这些证书。 请参阅 使用 Azure Databricks 进行数据管理。
- 将证书密码存储为机密作用域中的机密。
以下示例使用对象存储位置和 Databricks 机密启用 SSL 连接:
df = (spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", ...)
.option("kafka.security.protocol", "SASL_SSL")
.option("kafka.ssl.truststore.location", <truststore-location>)
.option("kafka.ssl.keystore.location", <keystore-location>)
.option("kafka.ssl.keystore.password", dbutils.secrets.get(scope=<certificate-scope-name>,key=<keystore-password-key-name>))
.option("kafka.ssl.truststore.password", dbutils.secrets.get(scope=<certificate-scope-name>,key=<truststore-password-key-name>))
)
将 Kafka on HDInsight 连接到 Azure Databricks
创建 HDInsight Kafka 群集。
有关说明,请参阅通过 Azure 虚拟网络连接到 Kafka on HDInsight。
对 Kafka 中转站进行配置以播发正确的地址。
按照为 IP 播发配置 Kafka 中的说明进行操作。 如果在 Azure 虚拟机上自行管理 Kafka,请确保将中转站的
advertised.listeners配置设置为主机的内部 IP。创建 Azure Databricks 群集。
将 Kafka 群集与 Azure Databricks 群集进行对等互连。
按照将虚拟网络对等互连中的说明进行操作。
Kafka 身份验证
使用 Microsoft Entra ID 和 Azure 事件中心的服务主体身份验证
Azure Databricks 支持使用事件中心服务对 Spark 作业进行身份验证。 需通过带有 Microsoft Entra ID 的 OAuth 完成此身份验证。
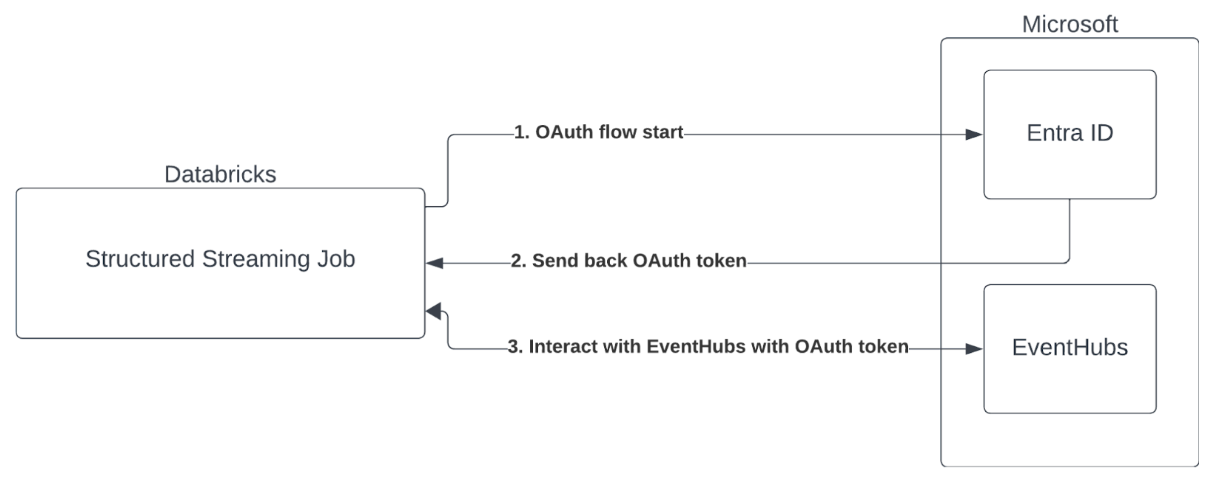
Azure Databricks 支持在以下计算环境中使用客户端 ID 和机密进行 Microsoft Entra ID 身份验证:
- Databricks Runtime 12.2 LTS 及更高版本的计算资源配置了专用访问模式(之前称为单用户访问模式)。
- 在配置为标准访问模式(以前共享访问模式)的计算节点上使用的 Databricks Runtime 14.3 LTS 及更高版本。
- 未配置 Unity Catalog 的 Lakeflow Spark 声明式管道。
Azure Databricks 不支持在任何计算环境中使用证书进行 Microsoft Entra ID 身份验证,也不支持在使用 Unity Catalog 配置的 Lakeflow Spark 声明性管道中使用。
此身份验证不适用于使用标准访问模式或 Unity Catalog Lakeflow Spark 声明性管道的计算。
Unity Catalog 服务凭证验证身份
自 Databricks Runtime 16.1 发布以来,Azure Databricks 支持 Unity Catalog 服务凭据,用于验证对 AWS 托管的 Apache Kafka 流式处理(MSK)和 Azure 事件中心的访问权限。 Databricks Runtime 18.0 中添加了对 Apache Kafka 的 GCP 托管服务的支持。 Databricks 建议使用此方法在共享群集上运行 Kafka 流式处理,并在支持的情况下使用无服务器计算。
若要使用 Unity 目录服务凭据进行身份验证,请执行以下步骤:
- 创建新的 Unity Catalog 服务凭据。 如果不熟悉此过程,请参阅 “创建服务凭据 ”,获取有关创建服务凭据的说明。
- 在 Kafka 配置中,提供 Unity 目录服务凭据的名称作为源选项。 将选项
databricks.serviceCredential设置为服务凭据的名称。
以下示例使用服务凭据将 Kafka 配置为源:
Python
kafka_options = {
"kafka.bootstrap.servers": "<bootstrap-hostname>:9092",
"subscribe": "<topic>",
"databricks.serviceCredential": "<service-credential-name>",
# Optional: set this only if Databricks can't infer the scope for your Kafka service.
# "databricks.serviceCredential.scope": "https://<event-hubs-server>/.default",
}
df = spark.read.format("kafka").options(**kafka_options).load()
Scala(编程语言)
val kafkaOptions = Map(
"kafka.bootstrap.servers" -> "<bootstrap-hostname>:9092",
"subscribe" -> "<topic>",
"databricks.serviceCredential" -> "<service-credential-name>",
// Optional: set this only if Databricks can't infer the scope for your Kafka service.
// "databricks.serviceCredential.scope" -> "https://<event-hubs-server>/.default",
)
val df = spark.read.format("kafka").options(kafkaOptions).load()
Azure Databricks 支持 Unity 目录服务凭据,用于对 DBR 16.1 及更高版本中的 Azure 事件中心的访问权限进行身份验证。
注意:向 Kafka 提供 Unity 目录服务凭据时, 请不要 指定这些选项,因为它们不再需要:
kafka.sasl.mechanismkafka.sasl.jaas.configkafka.security.protocolkafka.sasl.client.callback.handler.classkafka.sasl.oauthbearer.token.endpoint.url
配置结构化流式处理 Kafka 连接器
若要使用 Microsoft Entra ID 执行身份验证,必须具有以下值:
租户 ID。 可以在 Microsoft Entra ID 服务选项卡中找到此项。
clientID(也称为应用程序 ID)。
客户端密码。 拥有此密码后,应将其作为机密添加到 Databricks 工作区。 若要添加此机密,请参阅机密管理。
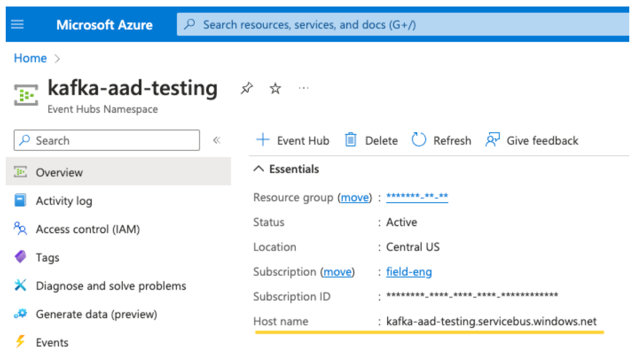
EventHubs 主题。 可以在特定“事件中心命名空间”页上“实体”部分下的“事件中心”部分找到主题列表。 若要处理多个主题,可以在事件中心级别设置 IAM 角色。
EventHubs 服务器。 可以在特定“事件中心命名空间”的概述页面找到此项:
此外,若要使用 Entra ID,我们需要告知 Kafka 使用 OAuth SASL 机制(SASL 是通用协议,而 OAuth 是一种 SASL“机制”):
-
kafka.security.protocol应为SASL_SSL -
kafka.sasl.mechanism应为OAUTHBEARER -
kafka.sasl.login.callback.handler.class应该是 Java 类的完全限定名称,值为kafkashaded表示遮蔽 Kafka 类的登录回调处理程序。 有关确切的类,请参阅以下示例。
示例
接下来,让我们看一个正在运行的示例:
Python
# This is the only section you need to modify for auth purposes!
# ------------------------------
tenant_id = "..."
client_id = "..."
client_secret = dbutils.secrets.get("your-scope", "your-secret-name")
event_hubs_server = "..."
event_hubs_topic = "..."
# -------------------------------
sasl_config = f'kafkashaded.org.apache.kafka.common.security.oauthbearer.OAuthBearerLoginModule required clientId="{client_id}" clientSecret="{client_secret}" scope="https://{event_hubs_server}/.default" ssl.protocol="SSL";'
kafka_options = {
# Port 9093 is the EventHubs Kafka port
"kafka.bootstrap.servers": f"{event_hubs_server}:9093",
"kafka.sasl.jaas.config": sasl_config,
"kafka.sasl.oauthbearer.token.endpoint.url": f"https://login.partner.microsoftonline.cn/{tenant_id}/oauth2/v2.0/token",
"subscribe": event_hubs_topic,
# You should not need to modify these
"kafka.security.protocol": "SASL_SSL",
"kafka.sasl.mechanism": "OAUTHBEARER",
"kafka.sasl.login.callback.handler.class": "kafkashaded.org.apache.kafka.common.security.oauthbearer.secured.OAuthBearerLoginCallbackHandler"
}
df = spark.readStream.format("kafka").options(**kafka_options)
display(df)
Scala(编程语言)
// This is the only section you need to modify for auth purposes!
// -------------------------------
val tenantId = "..."
val clientId = "..."
val clientSecret = dbutils.secrets.get("your-scope", "your-secret-name")
val eventHubsServer = "..."
val eventHubsTopic = "..."
// -------------------------------
val saslConfig = s"""kafkashaded.org.apache.kafka.common.security.oauthbearer.OAuthBearerLoginModule required clientId="$clientId" clientSecret="$clientSecret" scope="https://$eventHubsServer/.default" ssl.protocol="SSL";"""
val kafkaOptions = Map(
// Port 9093 is the EventHubs Kafka port
"kafka.bootstrap.servers" -> s"$eventHubsServer:9093",
"kafka.sasl.jaas.config" -> saslConfig,
"kafka.sasl.oauthbearer.token.endpoint.url" -> s"https://login.partner.microsoftonline.cn/$tenantId/oauth2/v2.0/token",
"subscribe" -> eventHubsTopic,
// You should not need to modify these
"kafka.security.protocol" -> "SASL_SSL",
"kafka.sasl.mechanism" -> "OAUTHBEARER",
"kafka.sasl.login.callback.handler.class" -> "kafkashaded.org.apache.kafka.common.security.oauthbearer.secured.OAuthBearerLoginCallbackHandler"
)
val scalaDF = spark.readStream
.format("kafka")
.options(kafkaOptions)
.load()
display(scalaDF)
处理潜在错误
不支持流式处理选项。
如果尝试在配置了 Unity 目录的 Lakeflow Spark 声明性管道中使用此身份验证机制,可能会收到以下错误:
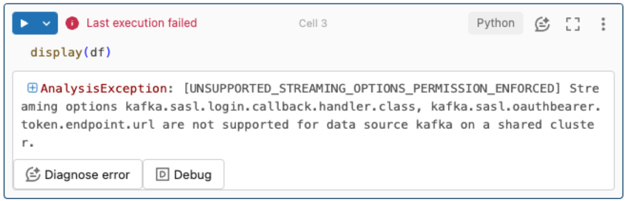
若要解决此错误,请使用支持的计算配置。 请参阅 Kafka 身份验证。
无法创建新
KafkaAdminClient。此为内部错误,以下任一身份验证选项不正确时 Kafka 都会抛出该错误:
- 客户端 ID(也称为应用程序 ID)
- 租户 ID
- EventHubs 服务器
若要解决此错误,请验证这些选项的值是否正确。
此外,如果修改示例中默认提供的配置选项(系统要求你不进行修改),例如
kafka.security.protocol,你可能会看到此错误。未返回任何记录
如果你尝试显示或处理 DataFrame 但未获得结果,则将在 UI 中看到以下内容。
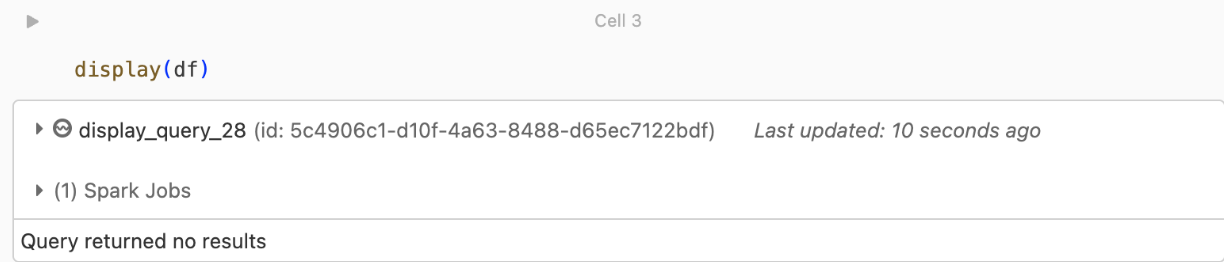
此消息表示身份验证成功,但 EventHubs 未返回任何数据。 一些可能的(尽管并不详尽)原因包括:
- 指定的 EventHubs 主题错误。
-
startingOffsets的默认 Kafka 配置选项是latest,你目前尚未通过主题接收任何数据。 可以将startingOffsets设置为earliest,以便从Kafka的最早偏移量开始读取数据。