扇入和扇出是用于生成可缩放的可靠数据管道的常见模式。 本页介绍了这两者以及如何在 Lakeflow Spark 声明性管道中实现它们。
什么是扇入和扇出?
扇入 是一种体系结构模式,其中来自多个源的数据在单个管道中引入和处理。
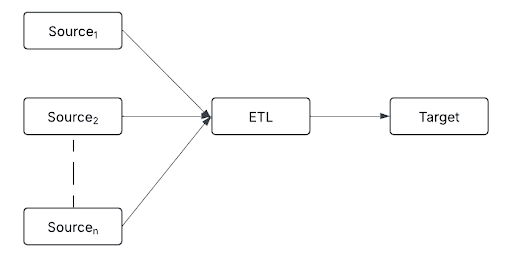
源可以包括:
实时事件流(例如 Kafka 和 Kinesis)
云存储(例如 ADLS)
关系数据库(例如 PostgreSQL、MySQL 和 Snowflake)
IoT 设备(例如传感器、日志和 API)
通过将多样化的数据流整合到单一的处理层中,扇入技术可以在数据下游传输之前实现统一的转换、去重和数据增强。
扇出 遵循一对多方法,将单个已处理的数据流路由到多个目标。
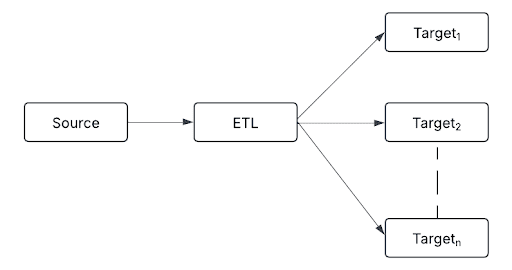
目标可以包括:
- 结构化存储的Delta表
- 用于异常情况检测的实时警报系统
- 用于预测分析的机器学习模型
- 用于报告和分析的数据仓库
- 用于异步通信和分离处理的消息队列
此模式可确保每个下游系统接收所需格式的数据,使组织能够将流式处理数据集成到各种业务应用程序中。
在实践中,管道通常合并这两种模式。 例如:
- 公司从多个应用程序、网站和移动设备(扇入)收集用户活动数据。
- 已处理的数据存储在 Delta Lake 中以供历史分析,而异常活动触发实时警报(扇出)。
使用追加流实现扇入
扇入管道将多个数据流合并到统一目标中。 传统上,这需要复杂的联合查询和手动检查点。 追加流通过使各种数据流能够直接馈送到单个流数据表中,无需显式合并或复杂逻辑,从而简化了此操作。 每个源都是独立管理的,允许增量数据引入和更新。
例如,使用追加流将多个 Kafka 主题或区域数据流合并到统一目标表中。
Python
from pyspark import pipelines as dp
dp.create_streaming_table("all_topics")
# Kafka stream from topic1
@dp.append_flow(target="all_topics")
def topic1():
return spark.readStream.format("kafka") \
.option("kafka.bootstrap.servers", "host1:port1,...") \
.option("subscribe", "topic1") \
.load()
# Kafka stream from topic2
@dp.append_flow(target="all_topics")
def topic2():
return spark.readStream.format("kafka") \
.option("kafka.bootstrap.servers", "host1:port1,...") \
.option("subscribe", "topic2") \
.load()
SQL
CREATE OR REFRESH STREAMING TABLE all_topics;
CREATE FLOW
topic1
AS INSERT INTO
all_topics BY NAME
SELECT * FROM
read_kafka(bootstrapServers => 'host1:port1,...', subscribe => 'topic1');
CREATE FLOW
topic2
AS INSERT INTO
all_topics BY NAME
SELECT * FROM
read_kafka(bootstrapServers => 'host1:port1,...', subscribe => 'topic2');
实现扇出
扇出管道将数据从一个源分发到多个输出。 Lakeflow Spark 声明性管道支持三种方法,具体取决于用例。
使用“for”循环实现通用逻辑
如果 ETL 逻辑在多个目标上相同,请使用 Python for 循环语句通过带参数的循环自动生成多个表。 这可以避免重复编码,并通过配置简化管道缩放。
重要
每个生成的流或表都独立处理整个源数据集。 对于具有共享吞吐量或读取容量限制(如 Kafka)的源,这可能会影响性能。 在使用该方法之前,请仔细评估此类来源。
regions = ["US", "EU", "APAC"]
for region in regions:
@dp.materialized_view(name=f"orders_{region.lower()}_filtered")
def filtered_orders(region_filter=region):
return spark.read.table("combined_orders").filter(f"region = '{region_filter}'")
将独立流用于特定于目标的逻辑
当 ETL 转换因目标而异时,构建独立的数据流。 此方法具有针对每个用例定制的精确控制和优化性能。
from pyspark import pipelines as dp
# Grouped output
@dp.materialized_view(name="orders_sink")
def region_orders():
df = spark.read.table("combined_orders").groupBy("region").count()
# Add additional logic here
return df
# BI materialized view
@dp.materialized_view(name="orders_bi_materialized")
def orders_bi():
return spark.read.table("combined_orders").select("order_id", "amount", "region")
# ML feature table
@dp.materialized_view(name="orders_ml_features")
def orders_ml():
return (
spark.read.table("combined_orders")
.withColumn("high_value_order", col("amount") > 1000)
.select("order_id", "high_value_order", "region")
)
将 ForEachBatch 用于自定义路由
重要
foreach_batch_sink 可通过 Lakeflow Spark 声明性管道 PREVIEW 频道进行公开预览获取。 请参阅channel管道配置。
foreach_batch_sink 会将自定义逻辑应用于每个微批次,从而实现复杂的转换、合并,或将数据路由到多个目标,包括没有内置流式处理支持的目标,例如 JDBC 接收器。
重要
每个批处理独立运行多个写入操作。 一个操作中的失败不会自动回滚以前成功的写入。 这可能会导致跨目标的部分或不一致的数据,尤其是在处理 Kafka 等共享源时。 在设计管道时,务必细致地处理错误并进行全面测试。 请参阅 使用 ForEachBatch 写入管道中的任意数据接收器。
from pyspark import pipelines as dp
@dp.foreach_batch_sink(name="user_events_feb")
def user_events_handler(batch_df, batch_id):
# Write to Delta table
batch_df.write.format("delta").mode("append").saveAsTable("my_catalog.my_schema.my_delta_table")
# Write to JSON files
batch_df.write.format("json").mode("append").save("/Volumes/path/to/json_target")
@dp.append_flow(target="user_events_feb", name="user_events_flow")
def read_user_events():
return (
spark.readStream.format("cloudFiles")
.option("cloudFiles.format", "json")
.load("/data/incoming/events")
)
常见 ForEachBatch 模式
foreach_batch_sink 支持多种模式。 一些常见模式包括:
单流至多目标汇聚:一个
append_flow从流式来源读取并将数据路由到一个foreach_batch_sink。 汇聚器处理写入多个目标(例如 Delta、JSON 和外部系统)。 这非常适合使用共享转换逻辑的简单多输出用例。多个流汇入统一接收器:多个
append_flow源(例如不同的目录、格式、Kafka 主题或外部 API)汇入单个foreach_batch_sink。 这集中了常见的转换逻辑、输出管理和错误处理。 由于只需要维护一个检查点,因此此方法可显著降低协调复杂性。 处理 Kafka 或外部 API 等消息队列时,它特别有用。一个流到一个接收器(许多独立对):每个
append_flow都有一个专用的foreach_batch_sink,在单个源与其目标之间建立明确、独立的关系。 这非常适合具有许多独立流的管道,这些流需要独特的处理逻辑、简化的故障排除和隔离的错误处理。
在实践中,这些方法通常相互补充。 例如,使用循环为大规模扇入方案动态生成多个追加流,然后使用循环或 foreach_batch_sink 扇出分发结果。
最佳做法
- 追加流要求源架构与目标流式处理表保持一致,以防止处理错误。 使用 Lakeflow Spark 声明性管道架构预期来主动检测和处理异常,确保整个管道的架构一致性。
- 保持循环逻辑定义明确且简单。
- 明确命名每个流和表以保持可读性。
- 监视资源利用率以高效扩展并避免性能瓶颈。
- 写入消息队列时,将一个
foreach_batch_sink与合并所有输入流的单个append_flow一起使用。 这简化了下游状态和检查点管理。
局限性
- Lakeflow Spark 声明性管道世系 UI 可能不会显示新追加流源的指标和流级别元数据。
- 展开而不是减少 for 循环中使用的值列表。 如果后续管道运行中省略以前定义的数据集,则会自动从目标架构中删除该数据集,从而导致意外数据丢失。