二进制文件
Databricks Runtime 支持二进制文件数据源,该数据源读取二进制文件并将每个文件转换为包含该文件的原始内容和元数据的单个记录。 二进制文件数据源会生成一个包含以下列和可能的分区列的数据帧:
path (StringType):文件的路径。modificationTime (TimestampType):文件的修改时间。 在某些 Hadoop 文件系统实现中,此参数可能不可用,值将设置为默认值。length (LongType):文件的长度(以字节表示)。content (BinaryType):文件的内容。
若要读取二进制文件,请将数据源 format 指定为 binaryFile。
映像
Databricks 建议使用二进制文件数据源来加载图像数据。
Databricks display 函数支持显示使用二进制数据源加载的图像数据。
如果所有加载的文件具有包含图像扩展名的文件名,则将自动启用图像预览:
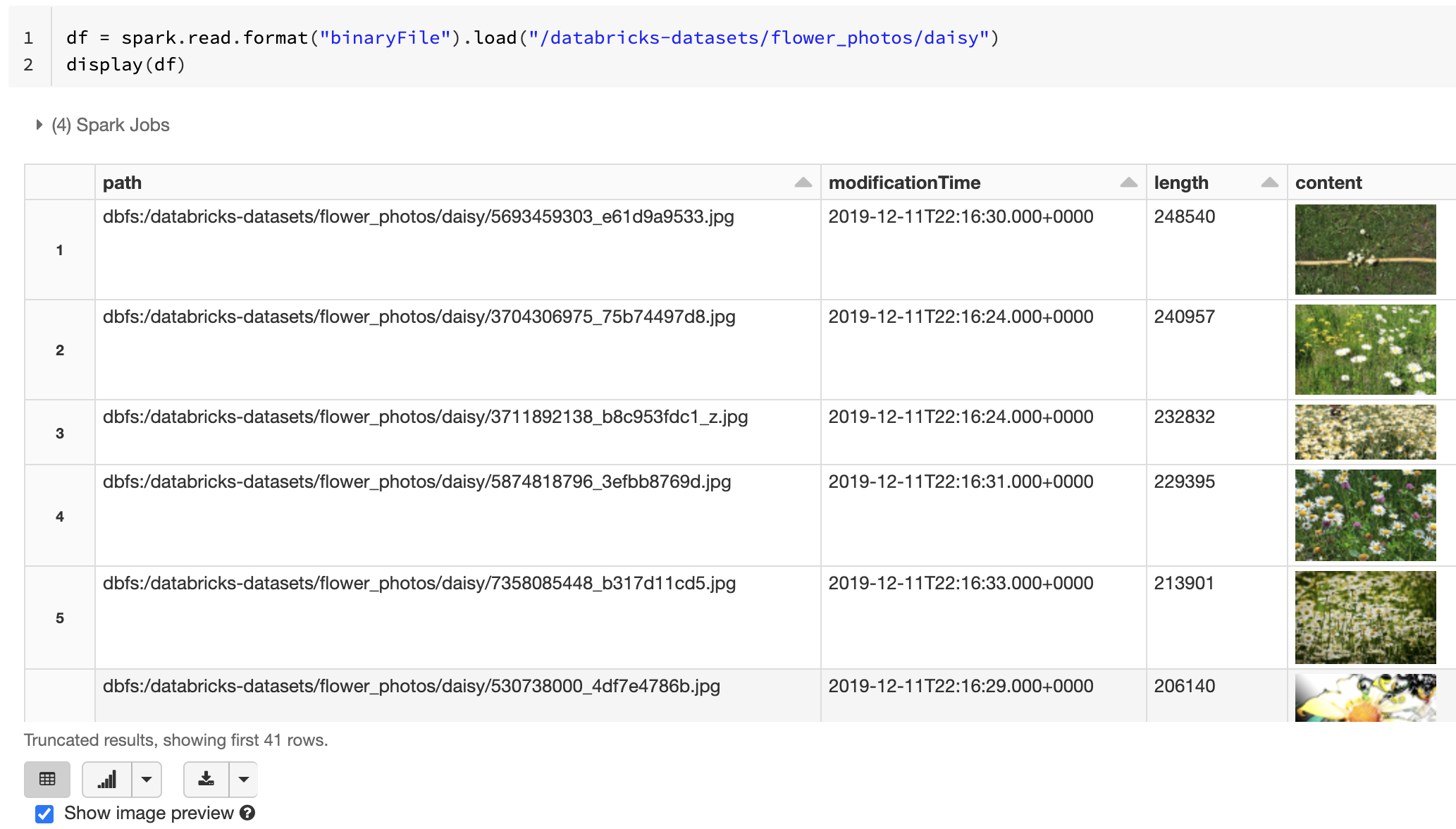
df = spark.read.format("binaryFile").load("<path-to-image-dir>")
display(df) # image thumbnails are rendered in the "content" column
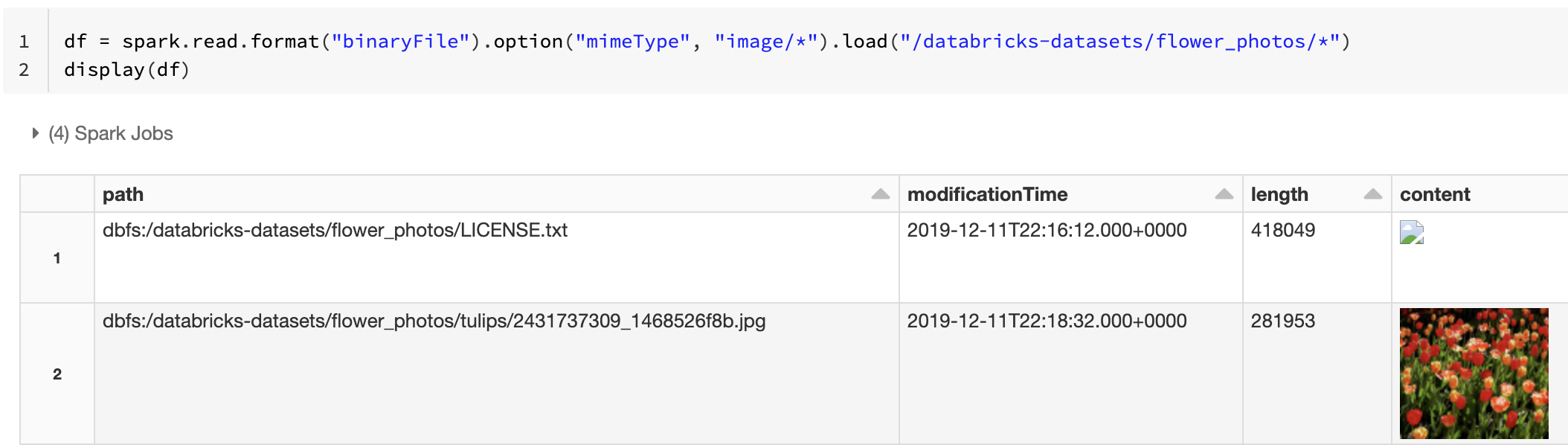
或者,可以通过使用带有字符串值 "image/*" 的 mimeType 选项对二进制列添加批注,从而强制执行图像预览功能。 图像基于二进制内容中的格式信息进行解码。 受支持的图像类型为 bmp、gif、jpeg 和 png。 不受支持的文件显示为损坏的图像图标。
df = spark.read.format("binaryFile").option("mimeType", "image/*").load("<path-to-dir>")
display(df) # unsupported files are displayed as a broken image icon
如需了解建议的用于处理图像数据的工作流,请参阅图像应用程序的参考解决方案。
选项
若要加载其路径与给定 glob 模式匹配的文件,同时保留分区发现行为,可以使用 pathGlobFilter 选项。 以下代码使用分区发现从输入目录读取所有 JPG 文件:
df = spark.read.format("binaryFile").option("pathGlobFilter", "*.jpg").load("<path-to-dir>")
如果要忽略分区发现并以递归方式搜索输入目录下的文件,请使用 recursiveFileLookup 选项。 此选项会搜索整个嵌套目录,即使这些目录的名称不遵循 date=2019-07-01 之类的分区命名方案。
以下代码从输入目录中以递归方式读取所有 JPG 文件,并忽略分区发现:
df = spark.read.format("binaryFile") \
.option("pathGlobFilter", "*.jpg") \
.option("recursiveFileLookup", "true") \
.load("<path-to-dir>")
Scala、Java 和 R 存在类似的 API。
注意
若要在重新加载数据时提高读取性能,Azure Databricks 建议你在保存从二进制文件加载的数据时禁用压缩:
spark.conf.set("spark.sql.parquet.compression.codec", "uncompressed")
df.write.format("delta").save("<path-to-table>")