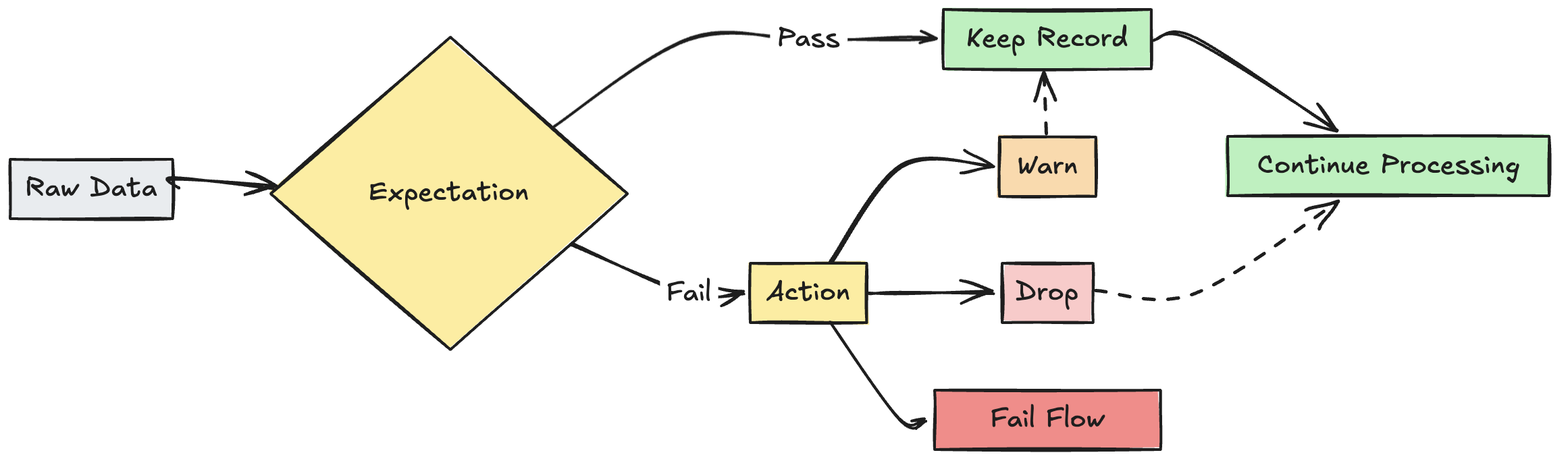
使用期望来应用质量约束条件,以验证数据在流经 ETL 管道时的质量。 预期可对数据质量指标提供更深入的洞察,并在检测到无效记录时允许更新失败或丢弃记录。
本文概述了预期,包括语法示例和行为选项。 有关更高级用例和建议的最佳做法,请参阅 期望建议和高级模式。
什么是期望?
预期是管道具体化视图、流式处理表或视图创建语句中的可选子句,用于对通过查询传递的每个记录应用数据质量检查。 期望使用标准 SQL 布尔语句来指定约束。 可以将单个数据集的多个期望组合在一起,并在管道中的所有数据集声明中设置预期。
以下部分介绍了期望的三个组成部分,并提供语法示例。
期望名称
每个期望都必须有一个名称,该名称用作标识符来跟踪和监视预期。 选择一个用于传达正在验证的指标的名称。 以下示例定义了确认年龄在 0 到 120 年之间的期望 valid_customer_age :
重要
预期名称对于给定数据集必须是唯一的。 可以在管道中的多个数据集中重复使用预期。 请参阅 可移植和可重用的预期。
Python
@dp.table
@dp.expect("valid_customer_age", "age BETWEEN 0 AND 120")
def customers():
return spark.readStream.table("datasets.samples.raw_customers")
SQL
CREATE OR REFRESH STREAMING TABLE customers(
CONSTRAINT valid_customer_age EXPECT (age BETWEEN 0 AND 120)
) AS SELECT * FROM STREAM(datasets.samples.raw_customers);
待评估的限制条件
约束子句是一个 SQL 条件语句,每个记录的计算结果必须为 true 或 false。 该约束包含正在验证的内容的实际逻辑。 当记录不符合此条件时,就会触发预期。
约束必须使用有效的 SQL 语法,并且不能包含以下项:
- 自定义 Python 函数
- 外部服务调用
- 引用其他表的子查询
下面是可添加到数据集创建语句的约束示例:
Python
Python 中约束的语法为:
@dp.expect(<constraint-name>, <constraint-clause>)
可以指定多个约束:
@dp.expect(<constraint-name>, <constraint-clause>)
@dp.expect(<constraint2-name>, <constraint2-clause>)
示例:
# Simple constraint
@dp.expect("non_negative_price", "price >= 0")
# SQL functions
@dp.expect("valid_date", "year(transaction_date) >= 2020")
# CASE statements
@dp.expect("valid_order_status", """
CASE
WHEN type = 'ORDER' THEN status IN ('PENDING', 'COMPLETED', 'CANCELLED')
WHEN type = 'REFUND' THEN status IN ('PENDING', 'APPROVED', 'REJECTED')
ELSE false
END
""")
# Multiple constraints
@dp.expect("non_negative_price", "price >= 0")
@dp.expect("valid_purchase_date", "date <= current_date()")
# Complex business logic
@dp.expect(
"valid_subscription_dates",
"""start_date <= end_date
AND end_date <= current_date()
AND start_date >= '2020-01-01'"""
)
# Complex boolean logic
@dp.expect("valid_order_state", """
(status = 'ACTIVE' AND balance > 0)
OR (status = 'PENDING' AND created_date > current_date() - INTERVAL 7 DAYS)
""")
SQL
SQL 中约束的语法为:
CONSTRAINT <constraint-name> EXPECT ( <constraint-clause> )
多个约束必须用逗号分隔:
CONSTRAINT <constraint-name> EXPECT ( <constraint-clause> ),
CONSTRAINT <constraint2-name> EXPECT ( <constraint2-clause> )
示例:
-- Simple constraint
CONSTRAINT non_negative_price EXPECT (price >= 0)
-- SQL functions
CONSTRAINT valid_date EXPECT (year(transaction_date) >= 2020)
-- CASE statements
CONSTRAINT valid_order_status EXPECT (
CASE
WHEN type = 'ORDER' THEN status IN ('PENDING', 'COMPLETED', 'CANCELLED')
WHEN type = 'REFUND' THEN status IN ('PENDING', 'APPROVED', 'REJECTED')
ELSE false
END
)
-- Multiple constraints
CONSTRAINT non_negative_price EXPECT (price >= 0),
CONSTRAINT valid_purchase_date EXPECT (date <= current_date())
-- Complex business logic
CONSTRAINT valid_subscription_dates EXPECT (
start_date <= end_date
AND end_date <= current_date()
AND start_date >= '2020-01-01'
)
-- Complex boolean logic
CONSTRAINT valid_order_state EXPECT (
(status = 'ACTIVE' AND balance > 0)
OR (status = 'PENDING' AND created_date > current_date() - INTERVAL 7 DAYS)
)
对无效记录的操作
必须指定一个操作以确定当记录未能通过验证检查时会发生什么情况。 下表描述了可用操作:
| Action | SQL 语法 | Python 语法 | 结果 |
|---|---|---|---|
| 警告 (默认值) | EXPECT |
dp.expect |
将无效记录写入目标。 |
| 下拉 | EXPECT ... ON VIOLATION DROP ROW |
dp.expect_or_drop |
在将数据写入目标之前,将删除无效记录。 已删除记录的计数与其他数据集指标一起记录。 |
| 失败 | EXPECT ... ON VIOLATION FAIL UPDATE |
dp.expect_or_fail |
无效记录阻止更新成功。 在重新处理之前需要手动干预。 此预期会导致单个流失败,并且不会导致管道中的其他流失败。 |
您还可以实施高级逻辑来隔离无效记录,并确保不导致失败或数据丢失。 请参阅隔离无效记录。
期望值跟踪指标
可以从管道 UI 查看 warn 或 drop 操作的跟踪指标。 由于 fail 导致检测到无效记录时更新失败,因此不会记录指标。
若要查看预期指标,请完成以下步骤:
在 Azure Databricks 工作区的边栏中,单击作业和管道。
单击管道的名称。
单击具有定义期望的数据集。
在右侧栏中选择 “数据质量 ”选项卡。
可以通过查询 Lakeflow Spark 声明性管道事件日志来查看数据质量指标。 请参阅 查询数据质量或预期指标。
保留无效记录
保留无效记录是默认的预期行为。 如果您想要保留违反期望的记录,同时收集通过或未通过约束的记录数量的指标,请使用expect运算符。 违反预期的记录以及有效记录将一起添加到目标数据集。
Python
@dp.expect("valid timestamp", "timestamp > '2012-01-01'")
SQL
CONSTRAINT valid_timestamp EXPECT (timestamp > '2012-01-01')
删除无效记录
expect_or_drop使用运算符防止进一步处理无效记录。 违反预期的记录将从目标数据集中删除:
Python
@dp.expect_or_drop("valid_current_page", "current_page_id IS NOT NULL AND current_page_title IS NOT NULL")
SQL
CONSTRAINT valid_current_page EXPECT (current_page_id IS NOT NULL and current_page_title IS NOT NULL) ON VIOLATION DROP ROW
无效记录失败
如果无效记录不可接受,请使用 expect_or_fail 运算符在记录失败验证时立即停止执行。 如果作是表更新,则系统以原子方式回滚事务:
Python
@dp.expect_or_fail("valid_count", "count > 0")
SQL
CONSTRAINT valid_count EXPECT (count > 0) ON VIOLATION FAIL UPDATE
重要
如果在管道中定义了多个并行流,则单个流的失败不会导致其他流失败。
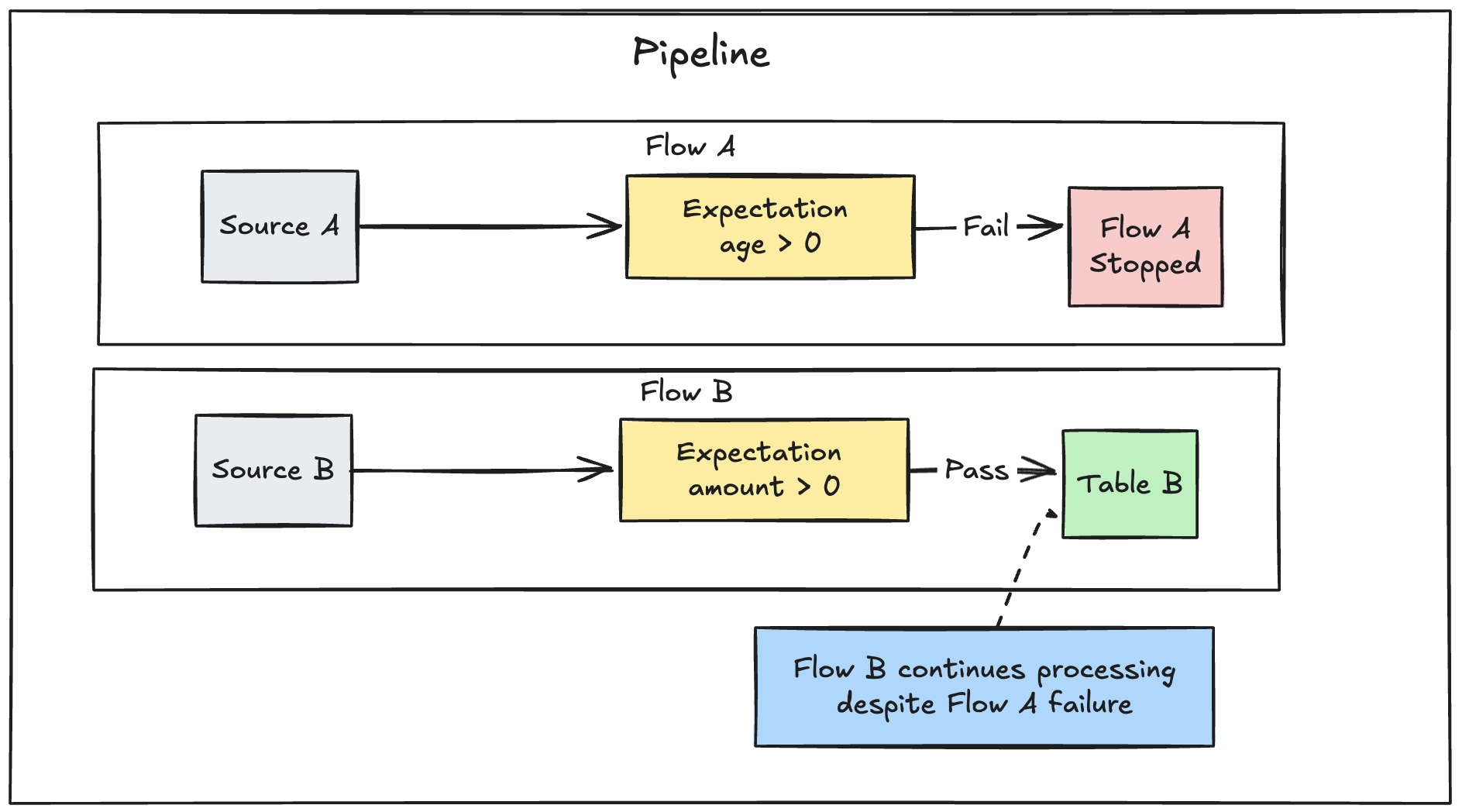
排查预期更新失败的问题
如果管道因预期冲突而失败,则必须修复管道代码,以在重新运行管道之前正确处理无效数据。
配置预期以应对管道失败,会修改转换中的 Spark 查询计划,以跟踪并检测及报告违规所需的信息。 可以使用此信息来识别哪个输入记录导致多个查询的违规。 Lakeflow Spark 声明性管道提供一条专用错误消息来报告此类违规。 下面是预期冲突错误消息的示例:
[EXPECTATION_VIOLATION.VERBOSITY_ALL] Flow 'sensor-pipeline' failed to meet the expectation. Violated expectations: 'temperature_in_valid_range'. Input data: '{"id":"TEMP_001","temperature":-500,"timestamp_ms":"1710498600"}'. Output record: '{"sensor_id":"TEMP_001","temperature":-500,"change_time":"2024-03-15 10:30:00"}'. Missing input data: false
多重期望管理
注释
虽然 SQL 和 Python 都支持单个数据集中的多个预期,但只有 Python 允许对多个期望进行分组并指定集体作。
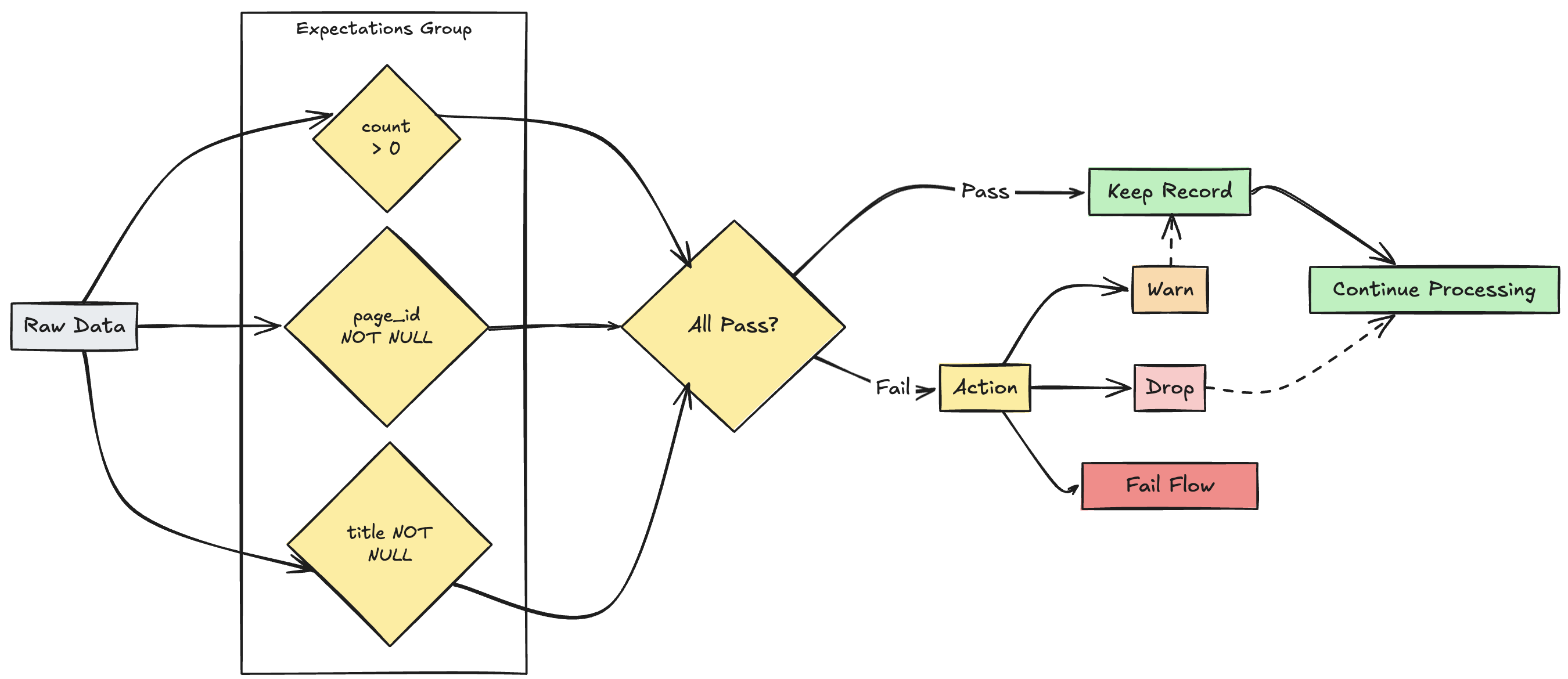
可以将多个期望组合在一起,并使用函数 expect_all、expect_all_or_drop 和 expect_all_or_fail 指定集体操作。
这些修饰器接受 Python 字典作为参数,其中键是预期名称和值是预期约束。 可以在管道中的多个数据集中重复使用相同的预期集。 下面显示了每个 expect_all Python 运算符的示例:
valid_pages = {"valid_count": "count > 0", "valid_current_page": "current_page_id IS NOT NULL AND current_page_title IS NOT NULL"}
@dp.table
@dp.expect_all(valid_pages)
def raw_data():
# Create a raw dataset
@dp.table
@dp.expect_all_or_drop(valid_pages)
def prepared_data():
# Create a cleaned and prepared dataset
@dp.table
@dp.expect_all_or_fail(valid_pages)
def customer_facing_data():
# Create cleaned and prepared to share the dataset
局限性
- 由于只有流式处理表、具体化视图和临时视图支持预期,因此仅支持这些对象类型的数据质量指标。
- 数据质量指标在以下情况下不可用:
- 查询上未定义任何期望值。
- 流使用不支持期望的运算符。
- 流类型(如 sinks)不支持期望。
- 给定的流运行中未出现对关联流表或物化视图的更新。
- 管道配置不包括用于捕获指标(例如
pipelines.metrics.flowTimeReporter.enabled)所需的必要设置。
- 在某些情况下,
COMPLETED流可能不包含指标。 相反,指标会在每个微批处理的flow_progress事件中以RUNNING状态报告。 - 由于视图仅在查询时计算,因此数据质量指标可能不适用于定义的视图。 或者,在多个下游数据集中查询的视图可能具有多个数据质量指标集。