使用 Azure DevOps 在 Azure Databricks 上进行持续集成和交付
注意
本文介绍了 Databricks 既不提供也不支持的 Azure DevOps。 若要联系提供商,请参阅 Azure DevOps Services 支持。
持续集成和持续交付 (CI/CD) 指的是,通过使用自动化管道,在较短且频繁的周期中开发和交付软件的过程。
持续集成始于将代码频繁提交到源代码存储库中的分支。 每个提交将与其他开发人员的提交合并,以确保不会造成冲突。 通过创建生成并针对该生成运行自动测试,更改会被进一步验证。 此过程最终会导致将项目部署到目标(在本文中为 Azure Databricks 工作区)。
CI/CD 开发工作流
Databricks 建议使用 Azure DevOps 进行以下 CI/CD 开发工作流:
- 通过第三方 Git 提供程序创建存储库或使用现有存储库。
- 将本地开发计算机连接到同一第三方存储库。 有关说明,请参阅第三方 Git 提供商的文档。
- 将任何现有的已更新工件(例如笔记本、代码文件和生成脚本)从第三方存储库向下拉取到本地开发计算机。
- 根据需要,在本地开发计算机上创建、更新、测试项目。 然后将任何新的和已更改的项目从本地开发计算机推送到第三方存储库。 有关说明,请参阅第三方 Git 提供商的文档。
- 根据需要重复步骤 3 和步骤 4。
- 定期使用 Azure DevOps 作为集成方法,从第三方存储库自动拉取项目、在 Azure Databricks 工作区中生成、测试和运行代码,并报告测试和运行结果。 虽然可以手动运行 Azure DevOps,但在实际的实现中,你会指示第三方 Git 提供程序在每次发生特定事件(例如存储库拉取请求)时运行 Azure DevOps。
有大量的 CI/CD 工具可用于管理和执行管道。 本文说明了如何使用 Azure DevOps。 CI/CD 是一种设计模式,因此在其他各工具中使用本文示例所概述的步骤和阶段时,应当对相应的管道定义语言进行一些更改。 此外,此示例管道中的大部分代码都是可在其他工具中调用的标准 Python 代码。
提示
有关将 Jenkins 与 Azure Databricks(而不是 Azure DevOps)配合使用的信息,请参阅在 Azure Databricks 上使用 Jenkins 进行 CI/CD。
本文的其余部分介绍了 Azure DevOps 中的一对示例管道,你可以根据自己对 Azure Databricks 的需求进行调整。
关于示例
本文的示例使用两个管道来收集、部署和运行存储在远程 Git 存储库中的一些示例 Python 代码和 Python 笔记本。
第一个管道(称为“生成”管道)为第二个管道(称为“发布”管道)准备生成项目。 通过将生成管道与发布管道分离,可以创建一个生成项目而无需部署它,或者同时部署来自多个生成的项目。
在此示例中,创建生成和发布管道,这将执行以下操作:
- 为生成管道创建 Azure 虚拟机。
- 将文件从 Git 存储库复制到虚拟机。
- 创建包含 Python 代码、Python 笔记本和相关生成、部署和运行设置文件的 gzip tar 文件。
- 将压缩的 tar 文件作为 zip 文件复制到发布管道可访问的位置。
- 为发布管道创建另一个 Azure 虚拟机。
- 从生成管道所在的位置获取 zip 文件,然后解压缩该 zip 文件,以获取 Python 代码、Python 笔记本以及相关的生成、部署和运行设置文件。
- 将 Python 代码、Python 笔记本和相关的生成、部署和运行设置文件部署到远程 Azure Databricks 工作区。
- 将 Python wheel 库的组件代码文件生成到 Python wheel 文件中。
- 对组件代码运行单元测试,以检查 Python wheel 文件中的逻辑。
- 运行 Python 笔记本,其中一个笔记本调用 Python wheel 文件的功能。
关于 Databricks CLI
本文中的示例演示如何在管道中的非交互式模式下使用 Databricks CLI。 本文中的示例管道部署代码、生成库并在 Azure Databricks 工作区中运行笔记本。
如果在管道中使用 Databricks CLI 而不实现本文中的示例代码、库和笔记本,请执行以下步骤:
- 准备 Azure Databricks 工作区,以使用 OAuth 计算机到计算机 (M2M) 身份验证对服务主体进行身份验证。 在开始之前,请确认你拥有 Microsoft Entra ID(以前称为 Azure Active Directory)服务主体以及 Azure Databricks OAuth 机密。
在管道中安装 Databricks CLI。 若要执行此操作,请将“Bash 脚本”任务添加到运行以下脚本的管道:
curl -fsSL https://raw.githubusercontent.com/databricks/setup-cli/main/install.sh | sh要向管道添加 Bash 脚本任务,请参阅步骤 3.6.安装 Databricks CLI 和 Python wheel 生成工具。
配置管道,使已安装的 Databricks CLI 能够通过工作区对服务主体进行身份验证。 若要执行此操作,请参阅步骤 3.1:为发布管道定义环境变量。
根据需要向管道添加更多“Bash 脚本”任务,以运行 Databricks CLI 命令。 请参阅 Databricks CLI 命令。
开始之前
若要使用本文的示例,必须满足以下条件:
- 现有的 Azure DevOps 项目。 如果还没有项目,请在 Azure DevOps 中创建项目。
- 具有 Azure DevOps 支持的 Git 提供程序的现有存储库。 你需要将 Python 示例代码、示例 Python 笔记本和相关发布设置文件添加到此存储库。 如果你还没有存储库,请按照 Git 提供程序的说明创建一个。 然后,将 Azure DevOps 项目连接到此存储库(如果尚未连接)。 有关说明,请按照支持的源存储库中的链接操作。
- 本文中的示例使用 OAuth 计算机到计算机 (M2M) 身份验证对 Azure Databricks 工作区的 Microsoft Entra ID(以前称为 Azure Active Directory)服务主体进行身份验证。 必须为该服务主体提供具有 Azure Databricks OAuth 机密的 Microsoft Entra ID 服务主体。
步骤 1:将示例中的文件添加到存储库
在此步骤中,你将在包含第三方 Git 提供程序的存储库中,添加 Azure DevOps 管道在远程 Azure Databricks 工作区中生成、部署和运行的所有示例文件。
步骤 1.1:添加 Python wheel 组件文件
在本文的示例中,Azure DevOps 管道将生成 Python wheel 文件并对其进行单元测试。 然后,Azure Databricks 笔记本将调用生成的 Python wheel 文件的功能。
要定义运行笔记本时所依据的 Python wheel 的逻辑和单元测试,请在存储库的根目录中创建两个名为 addcol.py 和 test_addcol.py 的文件,并将它们添加到 Libraries 文件夹中名为 python/dabdemo/dabdemo 的文件夹结构中,如下所示:
└── Libraries
└── python
└── dabdemo
└── dabdemo
├── addcol.py
└── test_addcol.py
addcol.py 文件包含一个库函数,它可以稍后内置到 Python wheel 文件中,然后安装在 Azure Databricks 群集上。 它是一个简单函数,可将由文本填充的新列添加到 Apache Spark 数据帧中:
# Filename: addcol.py
import pyspark.sql.functions as F
def with_status(df):
return df.withColumn("status", F.lit("checked"))
test_addcol.py 文件包含用于将模拟数据帧对象传递给 with_status 函数的测试,在 addcol.py 中定义。 然后,结果将与一个包含预期值的数据帧对象进行比较。 如果值匹配,则测试通过:
# Filename: test_addcol.py
import pytest
from pyspark.sql import SparkSession
from dabdemo.addcol import *
class TestAppendCol(object):
def test_with_status(self):
spark = SparkSession.builder.getOrCreate()
source_data = [
("paula", "white", "paula.white@example.com"),
("john", "baer", "john.baer@example.com")
]
source_df = spark.createDataFrame(
source_data,
["first_name", "last_name", "email"]
)
actual_df = with_status(source_df)
expected_data = [
("paula", "white", "paula.white@example.com", "checked"),
("john", "baer", "john.baer@example.com", "checked")
]
expected_df = spark.createDataFrame(
expected_data,
["first_name", "last_name", "email", "status"]
)
assert(expected_df.collect() == actual_df.collect())
要使 Databricks CLI 能够正确将此库代码打包到 Python wheel 文件中,请在与前两个文件相同的文件夹中创建两个名为 __init__.py 和 __main__.py 的文件。 此外,在 python/dabdemo 文件夹中创建一个名为 setup.py 的文件,如下所示:
└── Libraries
└── python
└── dabdemo
├── dabdemo
│ ├── __init__.py
│ ├── __main__.py
│ ├── addcol.py
│ └── test_addcol.py
└── setup.py
__init__.py 文件包含库的版本号和作者。 将 <my-author-name> 替换为你的名称:
# Filename: __init__.py
__version__ = '0.0.1'
__author__ = '<my-author-name>'
import sys, os
sys.path.append(os.path.join(os.path.dirname(__file__), "..", ".."))
__main__.py 文件包含库的入口点:
# Filename: __main__.py
import sys, os
sys.path.append(os.path.join(os.path.dirname(__file__), "..", ".."))
from addcol import *
def main():
pass
if __name__ == "__main__":
main()
setup.py 文件包含用于将库生成到 Python wheel 文件中的其他设置。 将 <my-url>、<my-author-name>@<my-organization> 和 <my-package-description> 替换为有效值:
# Filename: setup.py
from setuptools import setup, find_packages
import dabdemo
setup(
name = "dabdemo",
version = dabdemo.__version__,
author = dabdemo.__author__,
url = "https://<my-url>",
author_email = "<my-author-name>@<my-organization>",
description = "<my-package-description>",
packages = find_packages(include = ["dabdemo"]),
entry_points={"group_1": "run=dabdemo.__main__:main"},
install_requires = ["setuptools"]
)
步骤 1.2:为 Python wheel 文件添加单元测试笔记本
稍后,Databricks CLI 会运行笔记本作业。 此作业运行文件名为 run_unit_tests.py 的 Python 笔记本。 此笔记本针对 Python wheel 库的逻辑运行 pytest。
若要对本文的示例运行单元测试,请将包含以下内容的名为 run_unit_tests.py 的笔记本文件添加到存储库的根目录:
# Databricks notebook source
# COMMAND ----------
# MAGIC %sh
# MAGIC
# MAGIC mkdir -p "/Workspace${WORKSPACEBUNDLEPATH}/Validation/reports/junit/test-reports"
# COMMAND ----------
# Prepare to run pytest.
import sys, pytest, os
# Skip writing pyc files on a readonly filesystem.
sys.dont_write_bytecode = True
# Run pytest.
retcode = pytest.main(["--junit-xml", f"/Workspace{os.getenv('WORKSPACEBUNDLEPATH')}/Validation/reports/junit/test-reports/TEST-libout.xml",
f"/Workspace{os.getenv('WORKSPACEBUNDLEPATH')}/files/Libraries/python/dabdemo/dabdemo/"])
# Fail the cell execution if there are any test failures.
assert retcode == 0, "The pytest invocation failed. See the log for details."
步骤 1.3:添加调用 Python wheel 文件的笔记本
稍后,Databricks CLI 会运行另一个笔记本作业。 此笔记本创建一个数据帧对象,将其传递给 Python wheel 库的 with_status 函数,输出结果并报告作业的运行结果。 在存储库的根目录创建名为 dabdemo_notebook.py 的笔记本文件,其中包含以下内容:
# Databricks notebook source
# COMMAND ----------
# Restart Python after installing the Python wheel.
dbutils.library.restartPython()
# COMMAND ----------
from dabdemo.addcol import with_status
df = (spark.createDataFrame(
schema = ["first_name", "last_name", "email"],
data = [
("paula", "white", "paula.white@example.com"),
("john", "baer", "john.baer@example.com")
]
))
new_df = with_status(df)
display(new_df)
# Expected output:
#
# +------------+-----------+-------------------------+---------+
# │ first_name │ last_name │ email │ status │
# +============+===========+=========================+=========+
# │ paula │ white │ paula.white@example.com │ checked │
# +------------+-----------+-------------------------+---------+
# │ john │ baer │ john.baer@example.com │ checked │
# +------------+-----------+-------------------------+---------+
步骤 1.4:创建捆绑包配置
本文的示例使用 Databricks 资产捆绑包来定义用于生成、部署和运行 Python wheel 文件、两个笔记本和 Python 代码文件的设置和行为。 Databricks 资产捆绑包(简称“捆绑包”)可将完整的数据、分析和 ML 项目表示为源文件的集合。 请参阅什么是 Databricks 资产捆绑包?。
若要为本文的示例配置捆绑包,请在存储库的根目录中创建一个名为 databricks.yml 的文件。 在此示例 databricks.yml 文件中,替换以下占位符:
- 将
<bundle-name>替换为捆绑包的唯一编程名称。 例如azure-devops-demo。 - 将
<job-prefix-name>替换为一些字符串,帮助唯一地标识本示例中在 Azure Databricks 工作区中创建的作业。 例如azure-devops-demo。 - 将
<spark-version-id>替换为作业群集的 Databricks Runtime 版本 ID,例如13.3.x-scala2.12。 - 将
<cluster-node-type-id>替换为作业群集的群集节点类型 ID,例如Standard_DS3_v2。 - 请注意,
targets映射中的dev指定主机和相关部署行为。 在实际实现中,可以在自己的捆绑包中将此目标命名为不同的名称。
下面是此示例的 databricks.yml 文件内容:
# Filename: databricks.yml
bundle:
name: <bundle-name>
variables:
job_prefix:
description: A unifying prefix for this bundle's job and task names.
default: <job-prefix-name>
spark_version:
description: The cluster's Spark version ID.
default: <spark-version-id>
node_type_id:
description: The cluster's node type ID.
default: <cluster-node-type-id>
artifacts:
dabdemo-wheel:
type: whl
path: ./Libraries/python/dabdemo
resources:
jobs:
run-unit-tests:
name: ${var.job_prefix}-run-unit-tests
tasks:
- task_key: ${var.job_prefix}-run-unit-tests-task
new_cluster:
spark_version: ${var.spark_version}
node_type_id: ${var.node_type_id}
num_workers: 1
spark_env_vars:
WORKSPACEBUNDLEPATH: ${workspace.root_path}
notebook_task:
notebook_path: ./run_unit_tests.py
source: WORKSPACE
libraries:
- pypi:
package: pytest
run-dabdemo-notebook:
name: ${var.job_prefix}-run-dabdemo-notebook
tasks:
- task_key: ${var.job_prefix}-run-dabdemo-notebook-task
new_cluster:
spark_version: ${var.spark_version}
node_type_id: ${var.node_type_id}
num_workers: 1
spark_env_vars:
WORKSPACEBUNDLEPATH: ${workspace.root_path}
notebook_task:
notebook_path: ./dabdemo_notebook.py
source: WORKSPACE
libraries:
- whl: "/Workspace${workspace.root_path}/files/Libraries/python/dabdemo/dist/dabdemo-0.0.1-py3-none-any.whl"
targets:
dev:
mode: development
有关 databricks.yml 文件语法的详细信息,请参阅 Databricks 资产捆绑包配置。
步骤 2:定义生成管道
Azure DevOps 提供一个云托管用户界面,用于使用 YAML 定义 CI/CD 管道的阶段。 有关 Azure DevOps 和管道的详细信息,请参阅 Azure DevOps 文档。
在此步骤中,使用 YAML 标记定义生成管道,该管道生成部署项目。 若要将代码部署到 Azure Databricks 工作区,请将此管道的生成工件指定为发布管道的输入。 稍后将定义此发布管道。
若要运行生成管道,Azure DevOps 提供了云托管的按需执行代理,这些代理支持部署到 Kubernetes、VM、Azure Functions、Azure Web 应用等目标。 在此示例中,使用按需代理自动生成部署项目。
如下所示定义本文的示例生成管道:
登录到 Azure DevOps,然后单击“登录”链接,打开 Azure DevOps 项目。
注意
如果显示 Azure 门户而不是 Azure DevOps 项目,请单击“更多服务”>“Azure DevOps 组织”“我的 Azure DevOps 组织”>”,然后打开 Azure DevOps 项目。
单击边栏中的“管道”,然后单击“管道”菜单上的“管道”。
单击“新建管道”按钮,然后按照屏幕上的说明进行操作。 (如果已有管道,请单击“创建管道”。)按照这些说明操作之后,将打开管道编辑器。 在这里,你将在出现的
azure-pipelines.yml文件中定义生成管道脚本。 如果管道编辑器在指令末尾不可见,请选择生成管道的名称,然后单击“编辑”。你可以使用 Git 分支选择器
 为 Git 存储库中的每个分支自定义生成进程。 CI/CD 最佳做法是不要直接在存储库的
为 Git 存储库中的每个分支自定义生成进程。 CI/CD 最佳做法是不要直接在存储库的 main分支中执行生成工作。 此示例假定存储库中存在一个名为release的分支可以使用,而不是main。
默认情况下,
azure-pipelines.yml生成管道脚本存储在与管道关联的远程 Git 存储库的根目录中。使用以下定义覆盖管道的
azure-pipelines.yml文件的入门内容,然后单击“保存”。# Specify the trigger event to start the build pipeline. # In this case, new code merged into the release branch initiates a new build. trigger: - release # Specify the operating system for the agent that runs on the Azure virtual # machine for the build pipeline (known as the build agent). The virtual # machine image in this example uses the Ubuntu 22.04 virtual machine # image in the Azure Pipeline agent pool. See # https://learn.microsoft.com/azure/devops/pipelines/agents/hosted#software pool: vmImage: ubuntu-22.04 # Download the files from the designated branch in the remote Git repository # onto the build agent. steps: - checkout: self persistCredentials: true clean: true # Generate the deployment artifact. To do this, the build agent gathers # all the new or updated code to be given to the release pipeline, # including the sample Python code, the Python notebooks, # the Python wheel library component files, and the related Databricks asset # bundle settings. # Use git diff to flag files that were added in the most recent Git merge. # Then add the files to be used by the release pipeline. # The implementation in your pipeline will likely be different. # The objective here is to add all files intended for the current release. - script: | git diff --name-only --diff-filter=AMR HEAD^1 HEAD | xargs -I '{}' cp --parents -r '{}' $(Build.BinariesDirectory) mkdir -p $(Build.BinariesDirectory)/Libraries/python/dabdemo/dabdemo cp $(Build.Repository.LocalPath)/Libraries/python/dabdemo/dabdemo/*.* $(Build.BinariesDirectory)/Libraries/python/dabdemo/dabdemo cp $(Build.Repository.LocalPath)/Libraries/python/dabdemo/setup.py $(Build.BinariesDirectory)/Libraries/python/dabdemo cp $(Build.Repository.LocalPath)/*.* $(Build.BinariesDirectory) displayName: 'Get Changes' # Create the deployment artifact and then publish it to the # artifact repository. - task: ArchiveFiles@2 inputs: rootFolderOrFile: '$(Build.BinariesDirectory)' includeRootFolder: false archiveType: 'zip' archiveFile: '$(Build.ArtifactStagingDirectory)/$(Build.BuildId).zip' replaceExistingArchive: true - task: PublishBuildArtifacts@1 inputs: ArtifactName: 'DatabricksBuild'
步骤 3:定义发布管道
发布管道将生成项目从生成管道部署到 Azure Databricks 环境。 通过将此步骤中的发布管道与前面步骤中的生成管道分开,可以创建一个生成而不部署它,或者同时部署来自多个生成的项目。
在 Azure DevOps 项目中,在边栏中的“管道”菜单上,单击“发布”。
单击“新建”>“新建发布管道””。 (如果已有管道,请改为单击“新建管道”。)
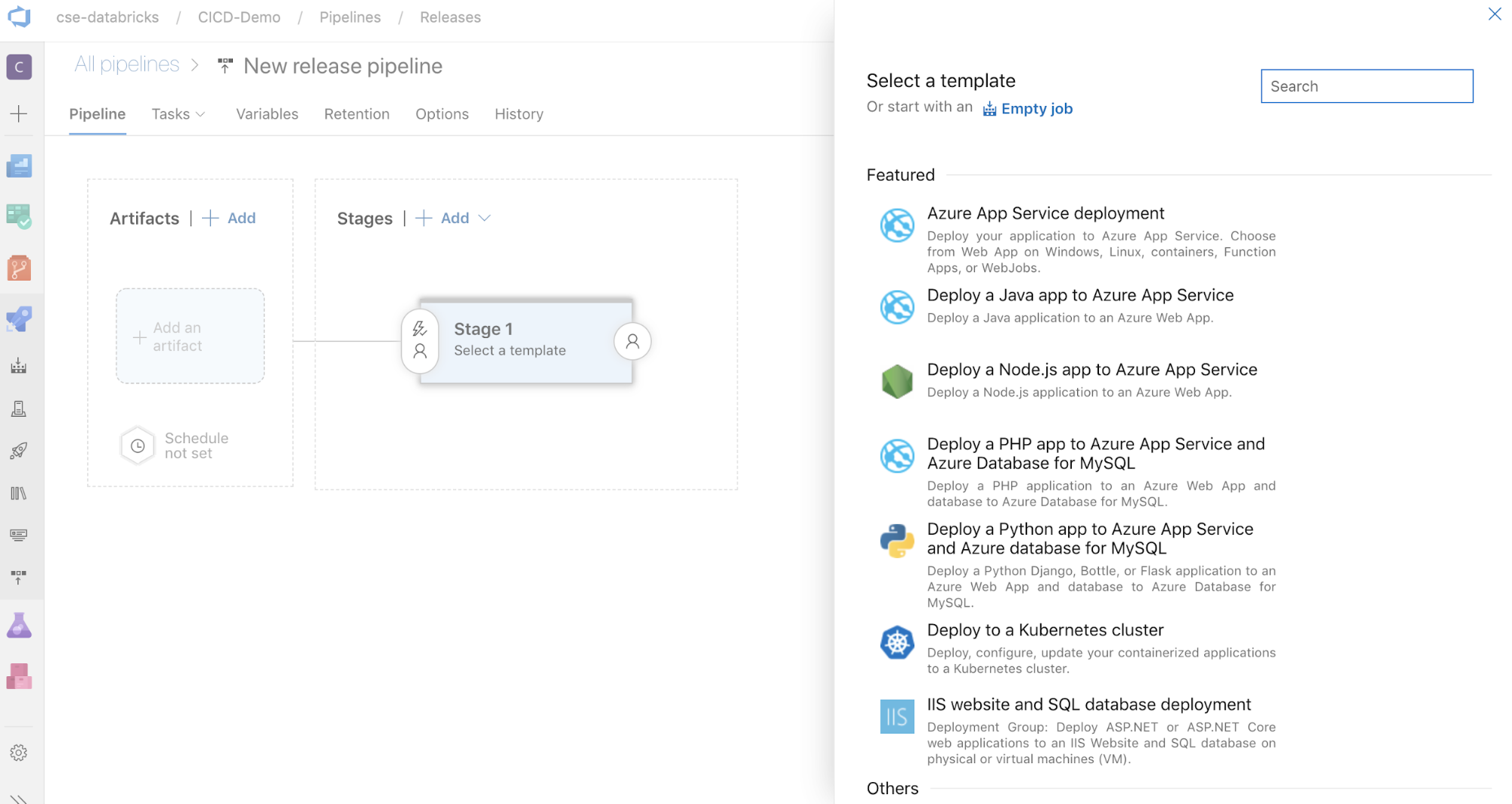
屏幕一侧是为常见部署模式特别推荐的模板的列表。 对于本示例发布管道,请单击
 。
。
在屏幕一侧的“项目”框中,单击
 。 在“添加项目”窗格中,对于“源(生成管道)”,选择之前创建的生成管道。 然后单击“添加” 。
。 在“添加项目”窗格中,对于“源(生成管道)”,选择之前创建的生成管道。 然后单击“添加” 。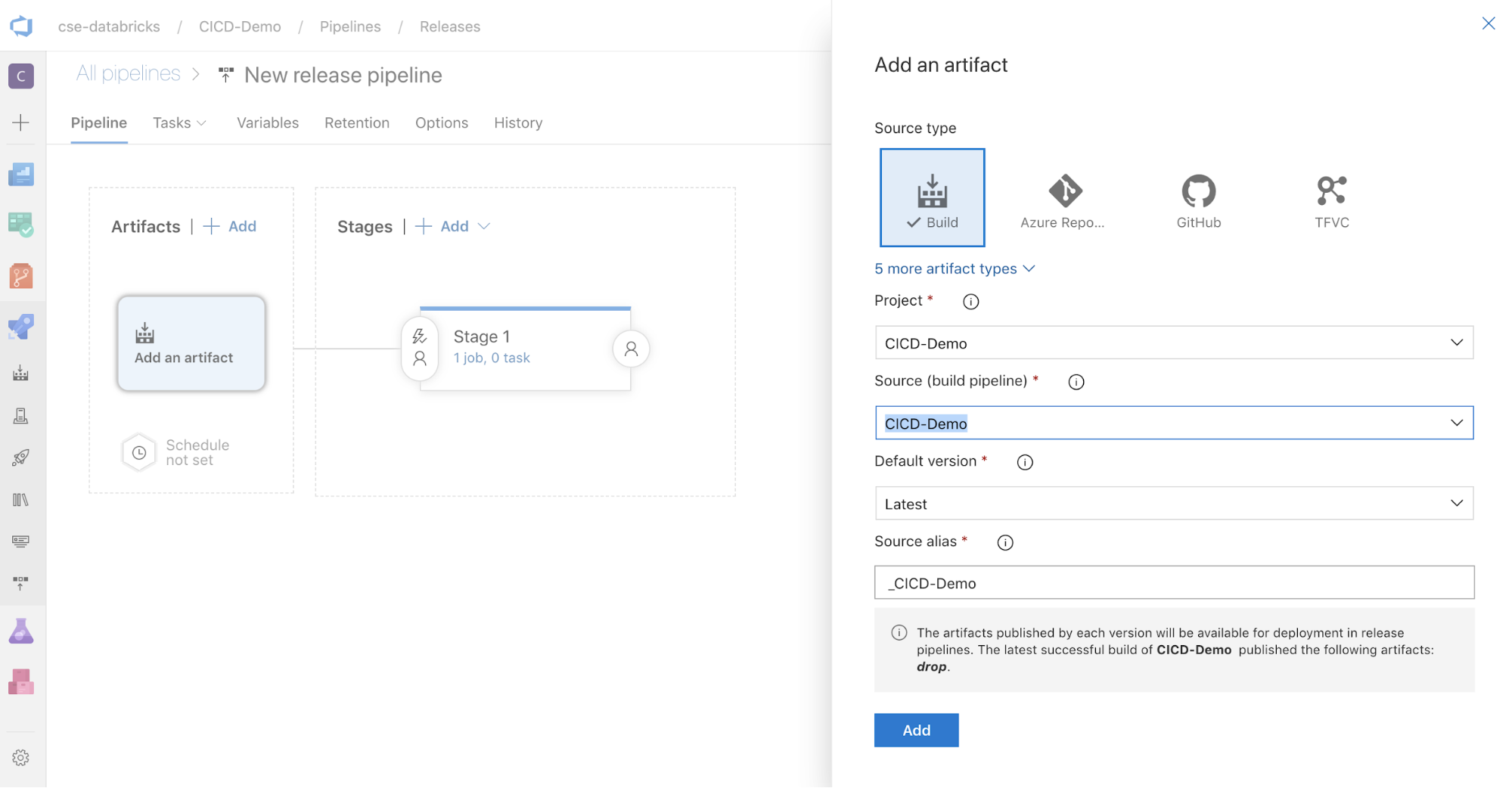
你可以通过单击
 来配置如何触发管道,在屏幕侧面显示触发选项。 如果希望根据生成项目的可用性或在某个拉取请求工作流后自动启动发布,请启用适当的触发器。 现在,在本示例的最后一步中,手动触发生成管道,然后触发发布管道。
来配置如何触发管道,在屏幕侧面显示触发选项。 如果希望根据生成项目的可用性或在某个拉取请求工作流后自动启动发布,请启用适当的触发器。 现在,在本示例的最后一步中,手动触发生成管道,然后触发发布管道。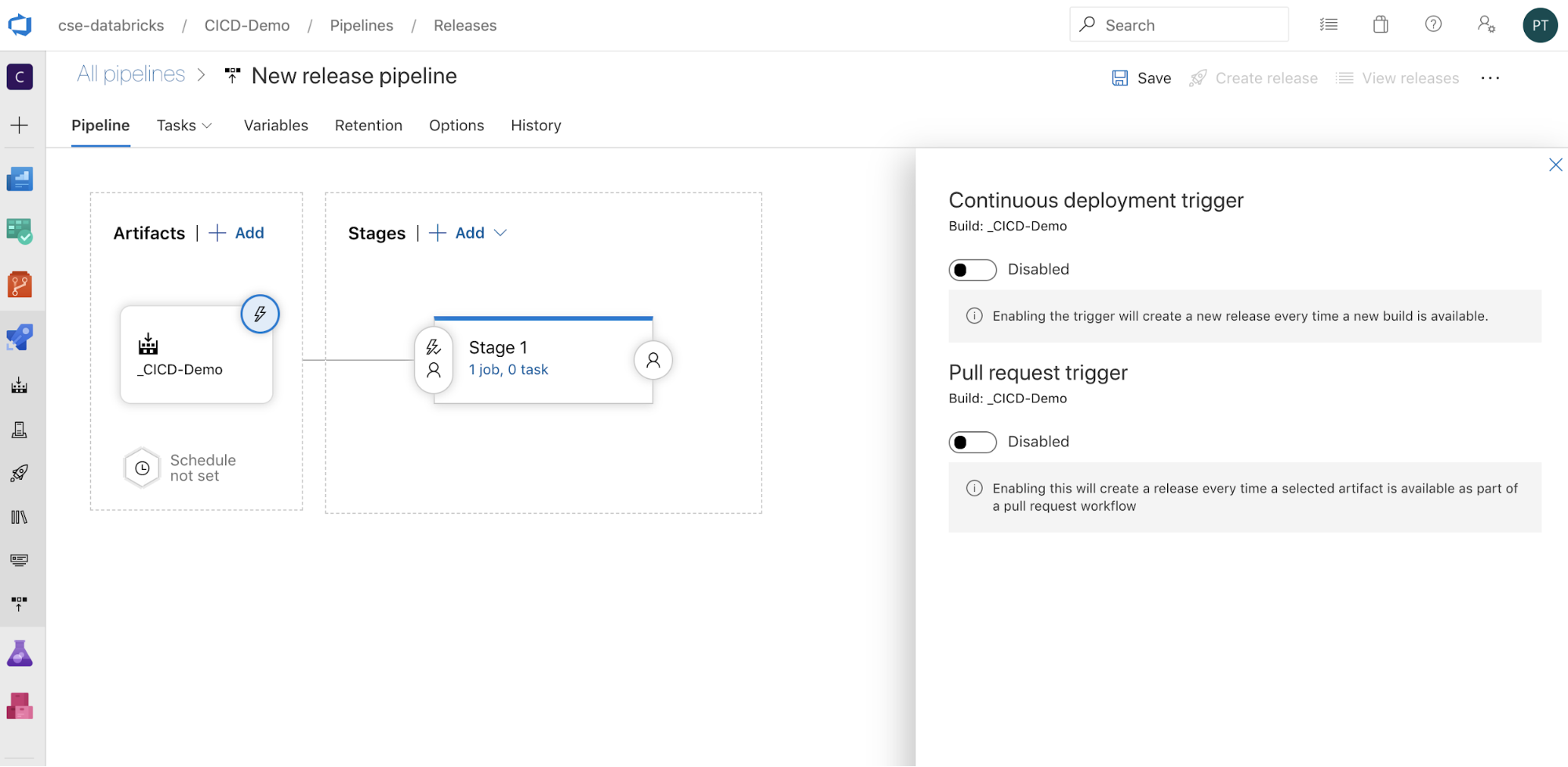
单击“保存”>“确定”。
步骤 3.1:为发布管道定义环境变量
此示例的发布管道依赖于以下三个环境变量,可以通过单击“变量”选项卡上的“管道变量”部分中的“添加”(“范围”设置为“阶段 1”)来添加这些环境变量:
BUNDLE_TARGET,它应与databricks.yml文件中的target名称匹配。 在本文的示例中,它是dev。DATABRICKS_HOST:表示 Azure Databricks 工作区的每工作区 URL,以https://开头,例如https://adb-<workspace-id>.<random-number>.databricks.azure.cn。 不要在.net后包含尾随/。DATABRICKS_CLIENT_ID,表示 Microsoft Entra ID 服务主体的应用程序 ID。DATABRICKS_CLIENT_SECRET,表示 Azure Databricks OAuth 密钥用于 Microsoft Entra ID 服务主体。
步骤 3.2:为发布管道配置发布代理
单击“阶段 1”对象中的“1 个作业,0 个任务”链接。
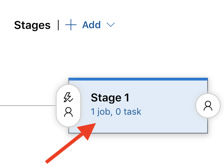
在“任务”选项卡上,单击“代理作业”。
在“代理选择”部分,对于“代理池”,选择“Azure Pipelines”。
对于“代理规范”,请选择与之前为生成代理指定的相同代理,在本例中为 ubuntu-22.04。
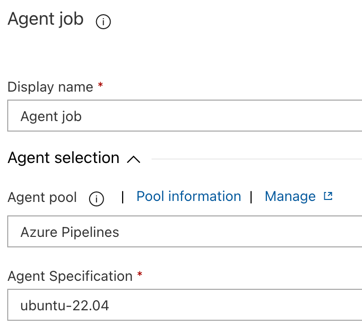
单击“保存”>“确定”。
步骤 3.3:设置发布代理的 Python 版本
在“代理作业”部分中单击加号,如下图中的红色箭头所指示。 此时将显示可用任务的可搜索列表。 还有一个“市场”选项卡,其中提供可用于补充标准 Azure DevOps 任务的第三方插件。 在接下来的几个步骤中,将向发布代理添加多个任务。
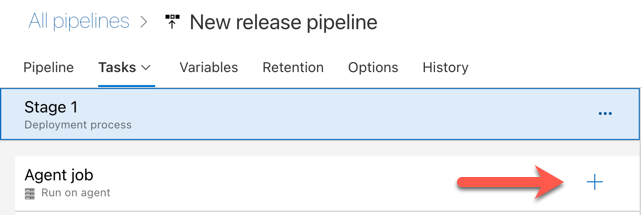
添加的第一个任务是位于“工具”选项卡上的“使用 Python 版本”。如果找不到此任务,请使用“搜索”框进行查找。 找到该选项后,选择它,然后单击“使用 Python 版本”任务旁边的“添加”按钮。
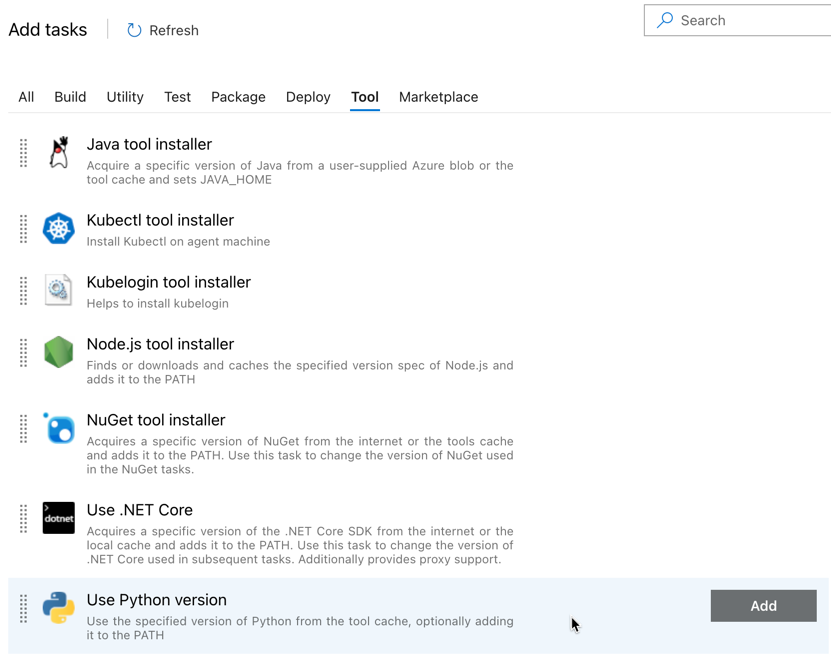
与生成管道一样,你需要确保 Python 版本与后续任务中调用的脚本兼容。 在本例中,请单击“代理作业”旁边的“使用 Python 3.x”任务,然后将“版本规范”设置为
3.10。 此外,将“显示名称”设置为Use Python 3.10。 此管道假定你在安装了 Python 3.10.12 的群集上使用 Databricks Runtime 13.3 LTS。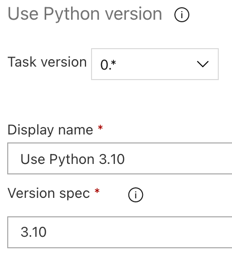
单击“保存”>“确定”。
步骤 3.4:从生成管道中解压缩生成项目
接下来,让发布代理使用“提取文件”任务从 zip 文件中提取 Python wheel 文件、相关发布设置文件、笔记本和 Python 代码文件:单击“代理作业”部分中的加号,选择“实用程序”选项卡上的“提取文件”任务,然后单击“添加”。
单击“代理作业”旁边的“解压缩文件”任务,将“存档文件模式”设置为
**/*.zip,并将“目标文件夹”设置为系统变量$(Release.PrimaryArtifactSourceAlias)/Databricks。 此外,将“显示名称”设置为Extract build pipeline artifact。注意
$(Release.PrimaryArtifactSourceAlias)表示 Azure DevOps 生成的别名,用于标识发布代理上的主要项目源位置,例如_<your-github-alias>.<your-github-repo-name>。 发布管道在发布代理的“初始化作业”阶段将此值设置为环境变量RELEASE_PRIMARYARTIFACTSOURCEALIAS。 请参阅经典发布和项目变量。将“显示名称”设置为
Extract build pipeline artifact。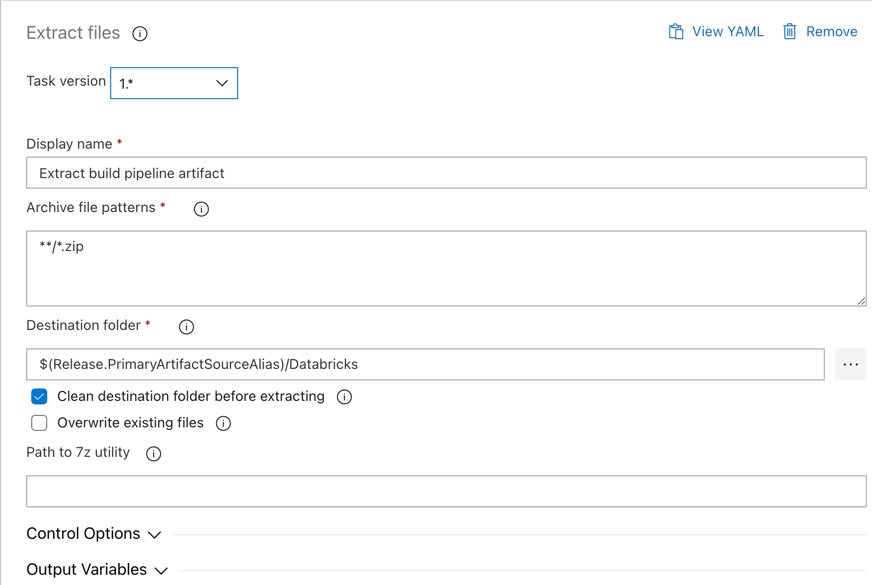
单击“保存”>“确定”。
步骤 3.5:设置 BUNDLE_ROOT 环境变量
要使本文的示例按预期运行,必须在发布管道中设置名为 BUNDLE_ROOT 的环境变量。 Databricks 资产捆绑包使用此环境变量来确定 databricks.yml 文件所在的位置。 若要设置此环境变量:
使用“环境变量”任务:再次单击“代理作业”部分中的加号,在“实用工具”选项卡上选择“环境变量”任务,然后单击“添加”。
注意
如果“环境变量”任务在“实用工具”选项卡上不可见,请在“搜索”框中输入
Environment Variables,然后按照屏幕上的说明将任务添加到“实用工具”选项卡。这可能需要离开 Azure DevOps,然后返回到离开的位置。对于“环境变量”(以逗号分隔),请输入以下定义:
BUNDLE_ROOT=$(Agent.ReleaseDirectory)/$(Release.PrimaryArtifactSourceAlias)/Databricks。注意
$(Agent.ReleaseDirectory)表示 Azure DevOps 生成的别名,用于标识发布代理上的发布目录位置,例如/home/vsts/work/r1/a。 发布管道在发布代理的“初始化作业”阶段将此值设置为环境变量AGENT_RELEASEDIRECTORY。 请参阅经典发布和项目变量。 有关$(Release.PrimaryArtifactSourceAlias)的详细信息,请参阅上一步中的说明。将“显示名称”设置为
Set BUNDLE_ROOT environment variable。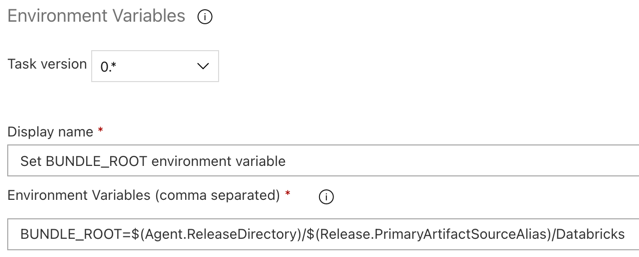
单击“保存”>“确定”。
步骤 3.6: 安装 Databricks CLI 和 Python wheel 生成工具
接下来,在发布代理上安装 Databricks CLI 和 Python wheel 生成工具。 在后续的几个步骤中,发布代理将调用 Databricks CLI 和 Python wheel 生成工具。 为此,请使用“Bash”任务:再次单击“代理作业”部分中的加号,在“实用工具”选项卡上选择“Bash”任务,然后单击“添加”。
单击“代理作业”旁边的“Bash 脚本”任务。
对于“类型”,选择“内联”。
将“脚本”的内容替换为以下命令,以安装 Databricks CLI 和 Python Wheel 生成工具:
curl -fsSL https://raw.githubusercontent.com/databricks/setup-cli/main/install.sh | sh pip install wheel将“显示名称”设置为
Install Databricks CLI and Python wheel build tools。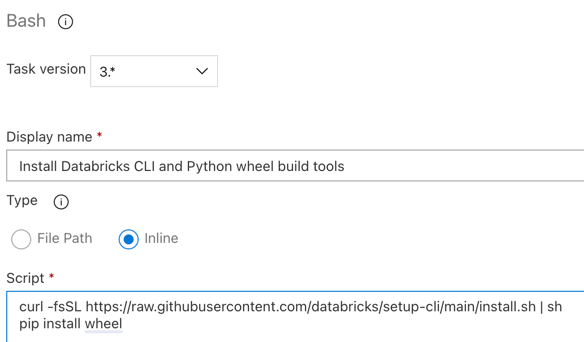
单击“保存”>“确定”。
步骤 3.7:验证 Databricks 资产捆绑包
在此步骤中,请确保 databricks.yml 文件语法正确。
请使用“Bash”任务:再次单击“代理作业”部分中的加号,在“实用工具”选项卡上选择“Bash”任务,然后单击“添加”。
单击“代理作业”旁边的“Bash 脚本”任务。
对于“类型”,选择“内联”。
用以下命令替换“脚本”中的内容,该命令使用 Databricks CLI 检查
databricks.yml文件语法是否正确:databricks bundle validate -t $(BUNDLE_TARGET)将“显示名称”设置为
Validate bundle。单击“保存”>“确定”。
步骤 3.8:部署捆绑包
在此步骤中,你将生成 Python wheel 文件,然后会将生成的 Python wheel 文件、两个 Python 笔记本以及发布管道中的 Python 文件部署到 Azure Databricks 工作区。
请使用“Bash”任务:再次单击“代理作业”部分中的加号,在“实用工具”选项卡上选择“Bash”任务,然后单击“添加”。
单击“代理作业”旁边的“Bash 脚本”任务。
对于“类型”,选择“内联”。
将“脚本”的内容替换为以下命令,以使用 Databricks CLI 生成 Python wheel 文件,并将本文的示例文件从发布管道部署到 Azure Databricks 工作区:
databricks bundle deploy -t $(BUNDLE_TARGET)将“显示名称”设置为
Deploy bundle。单击“保存”>“确定”。
步骤 3.9:为 Python wheel 运行单元测试笔记本
在此步骤中,你将运行一个作业,在 Azure Databricks 工作区中运行单元测试笔记本。 此笔记本针对 Python wheel 库的逻辑运行单元测试。
请使用“Bash”任务:再次单击“代理作业”部分中的加号,在“实用工具”选项卡上选择“Bash”任务,然后单击“添加”。
单击“代理作业”旁边的“Bash 脚本”任务。
对于“类型”,选择“内联”。
用以下命令替换“脚本”的内容,该命令使用 Databricks CLI 在 Azure Databricks 工作区中运行作业:
databricks bundle run -t $(BUNDLE_TARGET) run-unit-tests将“显示名称”设置为
Run unit tests。单击“保存”>“确定”。
步骤 3.10:运行调用 Python wheel的笔记本
在此步骤中,你将运行一个作业,在 Azure Databricks 工作区中运行另一个笔记本。 此笔记本调用 Python wheel 库。
请使用“Bash”任务:再次单击“代理作业”部分中的加号,在“实用工具”选项卡上选择“Bash”任务,然后单击“添加”。
单击“代理作业”旁边的“Bash 脚本”任务。
对于“类型”,选择“内联”。
用以下命令替换“脚本”的内容,该命令使用 Databricks CLI 在 Azure Databricks 工作区中运行作业:
databricks bundle run -t $(BUNDLE_TARGET) run-dabdemo-notebook将“显示名称”设置为
Run notebook。单击“保存”>“确定”。
你已经完成了发布管道的配置。 它应如下所示:

步骤 4:运行生成和发布管道
在此步骤中,你将手动运行管道。 若要了解如何自动运行管道,请参阅指定触发管道和发布触发器的事件。
若要手动运行生成管道:
- 在边栏的“管道”菜单上,单击“管道”。
- 单击生成管道名称,然后单击“运行管道”。
- 对于“分支/标记”,选择 Git 存储库中包含添加的所有源代码的分支名称。 此示例假定这是在
release分支中。 - 单击 “运行” 。 此时会显示生成管道的运行页面。
- 要查看生成管道的进度并查看相关日志,请单击“作业”旁边的旋转图标。
- 在“作业”图标变为绿色复选标记后,继续运行发布管道。
若要手动运行发布管道:
- 成功运行生成管道后,在侧栏中的“管道”菜单单击“发布”。
- 单击发布管道的名称,然后单击“创建发布”。
- 单击 “创建” 。
- 若要查看发布管道的进度,请在发布列表中单击最新发布的名称。
- 在“阶段”框中单击“阶段 1”,然后单击“日志”。