了解 Lakeflow Spark 声明性管道(SDP)是什么、定义它的核心概念(如管道、流式处理表和具体化视图),以及这些概念之间的关系以及在数据处理工作流中使用它的好处。
注释
Lakeflow Spark 的声明式管道需订购 高级版。 有关详细信息,请联系 Databricks 帐户团队。
什么是 SDP?
Lakeflow Spark 声明性管道是一个声明性框架,用于在 SQL 和 Python 中开发和运行批处理和流式处理数据管道。 Lakeflow SDP 扩展并可与 Apache Spark 声明性管道互作,同时在性能优化的 Databricks 运行时上运行,Lakeflow Spark 声明性管道 flows API 使用与 Apache Spark 和结构化流相同的数据帧 API。 SDP 的常见用例包括从各种源(如云存储和消息总线)增量引入数据。云存储的例子包括 Azure ADLS Gen2,而消息总线的例子包括 Apache Kafka、Amazon Kinesis、Azure EventHub 和 Apache Pulsar。它还包括使用无状态和有状态操作符进行增量批处理和流转换,以及在消息总线和数据库等事务存储之间进行实时流处理。
有关声明性数据处理的更多详细信息,请参阅 Databricks 中的过程与声明性数据处理。
SDP 有什么好处?
与使用 Apache Spark 和 Spark Structured Streaming API 开发数据流程并通过 Lakeflow Jobs 手动编排在 Databricks Runtime 上运行相比,SDP 的声明性特性提供了以下优势。
- 自动业务流程:SDP 自动协调处理步骤(称为“流”),以确保正确的执行顺序和最大并行度级别以实现最佳性能。 此外,管道会自动高效地重试暂时性故障。 重试过程从最精细且经济高效的单元开始:Spark 任务。 如果任务级重试失败,SDP 会继续重试流,然后在必要时重试整个管道。
- 声明性处理:SDP 提供声明性函数,可将数百甚至数千行手动 Spark 和结构化流式处理代码减少到几行。 SDP AUTO CDC API 简化了变更数据捕获(CDC)事件的处理,同时支持 SCD 类型 1 和 SCD 类型 2。 它无需手动代码来处理无序事件,并且不需要了解流式处理语义或水印等概念。
关键概念
下图演示了 Lakeflow Spark 声明性管道最重要的概念。
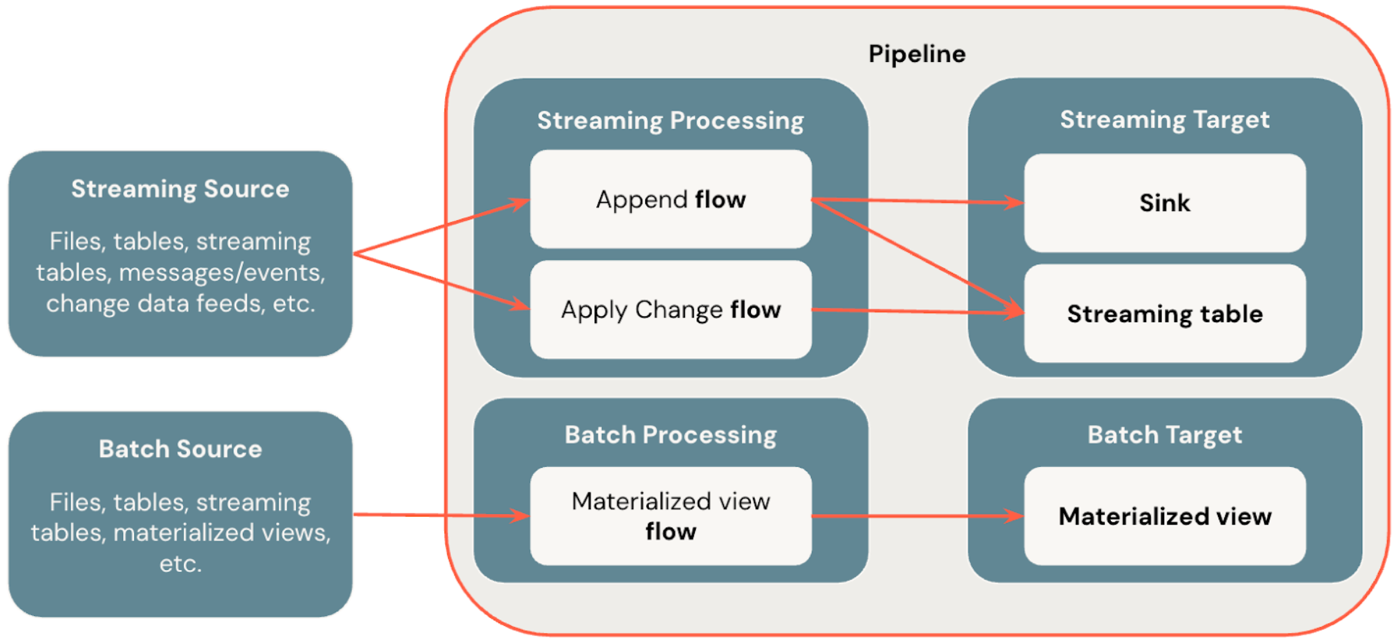
Flows
流是 SDP 中支持流式处理和批处理语义的基础数据处理概念。 流从源读取数据,应用用户定义的处理逻辑,并将结果写入目标。 SDP 与 Spark 结构化流共享相同的流式处理类型(追加、 更新、 完成)。 (目前,仅公开 追加 流。有关详细信息,请参阅 结构化流式处理中的输出模式。
Lakeflow Spark 声明性管道还提供其他流类型:
- AUTO CDC 是 Lakeflow SDP 中唯一的流式处理流,可处理无序 CDC 事件,并支持 SCD 类型 1 和 SCD 类型 2。 自动 CDC 在 Apache Spark 声明性管道中不可用。
- 具体化视图 是 SDP 中的批处理流,仅尽可能处理源表中的新数据和更改。
有关更多详细信息,请参阅:
水槽
汇是管道的流式传输目标,目前支持 Delta 表、Apache Kafka 主题、Azure EventHubs 主题和自定义的 Python 数据源。 接收器可以写入其中一个或多个流式处理流(追加)。
有关更多详细信息,请参阅:
Pipelines
管道是在 Lakeflow Spark 声明性管道中开发和执行的单元。 管道可以包含一个或多个流、流式处理表、具体化视图和汇聚点。 通过在管道源代码中定义流、流式处理表、具体化视图和接收器,然后运行管道,来使用 SDP。 管道运行时,它会分析定义的流、流式处理表、具体化视图和接收器的依赖关系,并自动协调其执行顺序和并行化。
有关更多详细信息,请参阅: