流式处理表是 Delta 表,具有支持流式或增量数据处理的额外功能。 流式处理表可由管道中的一个或多个流作为目标。
流式处理表是数据导入的理想选择,原因如下:
- 每个输入行只处理一次,这对绝大多数引入工作负载建模(即,通过将行追加或插入更新到表中来实现)。
- 它们可以处理大量仅追加的数据。
要实现低延迟流式处理转换,流式处理表也是一个不错的选择,原因如下:
- 基于行和时段进行推理
- 处理大量数据
- 低延迟
下列图表展示了流式处理表的工作原理。

每次更新时,与流式处理表关联的流读取流源中已更改的信息,并将新信息追加到该表。
流式处理表由单个管道定义和更新。 你需要在管道的源代码中明确定义流式表。 管道定义的表不能由任何其他管道更改或更新。 可以定义多个流以追加到单个流式处理表。
注释
使用 Databricks SQL 在管道外部创建流式处理表时,Azure Databricks 会创建用于更新表的管道。 可以通过从工作区左侧导航中选择ETL. 在 Databricks SQL 中创建的流表的类型为 MV/ST.
有关流的详细信息,请参阅 使用 Lakeflow Spark 声明性管道流以增量方式加载和处理数据。
用于引入的流式处理表
流式处理表专为仅追加的数据源设计,并且仅处理一次输入。
以下示例演示如何使用流式处理表从云存储引入新文件。
Python
from pyspark import pipelines as dp
# create a streaming table
@dp.table
def customers_bronze():
return (
spark.readStream.format("cloudFiles")
.option("cloudFiles.format", "json")
.option("cloudFiles.inferColumnTypes", "true")
.load("/Volumes/path/to/files")
)
若要创建流式处理表,数据集定义必须是流类型。 在数据集定义中使用 spark.readStream 函数时,它将返回流数据集。
SQL
-- create a streaming table
CREATE OR REFRESH STREAMING TABLE customers_bronze
AS SELECT * FROM STREAM read_files(
"/volumes/path/to/files",
format => "json"
);
流式处理表需要流式处理数据集。
STREAM 关键字在 read_files 之前告知查询将数据集视为流。
有关将数据加载到流表中的更多详细信息,请参阅在管道中加载数据。
下列图表展示了仅追加流式处理表的工作原理。
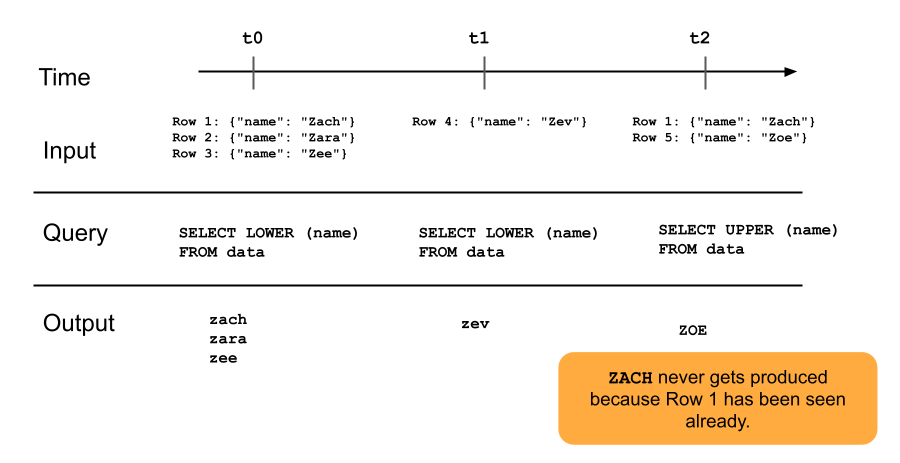
在以后更新管道时,已追加到流式处理表中的行不会被重新查询。 如果修改查询(例如,从 SELECT LOWER (name) 改为 SELECT UPPER (name)),现有行不会更新为大写,但新行将大写。 可以触发完全刷新以重新查询源表中的所有以前的数据,以更新流式处理表中的所有行。
流式处理表和低延迟流式处理
流式处理表适用于针对有界状态的低延迟流式处理。 流式处理表使用检查点管理,因此非常适合实现低延迟流式处理。 但是,它们期望的是自然有界流或带有水印的有界流。
自然有界流由具有明确定义的开始和结束的流式处理数据源生成。 自然有界流的一个示例是从文件目录读取数据,这种文件目录在放置初始批文件后不会添加新文件。 由于文件数有限,因此将流视为有限,然后,流将在处理所有文件后结束。
还可以使用水印来设置流的边界。 在 Spark 结构化流处理框架中,水印是一种机制,通过指定系统在判定时间窗口已完成之前应等待延迟事件的时间长度,以帮助处理迟到的数据。 没有时间戳的无界流可能会导致管道因内存压力而失败。
有关有状态流处理的详细信息,请参阅 使用水印优化有状态处理。
流-快照联接
流-快照联接是流与流开始时拍摄快照的维度之间的联接。 如果维度在流启动后发生更改,则不会重新计算这些联接,因为维度表被视为一个快照,并且流启动后对维度表所做的更改不会反映,除非重新加载或刷新维度表。 如果可以接受联接中的小差异,则这是合理的行为。 例如,当事务数量比客户数量大几个数量级时,可接受近似联接。
在下面的代码示例中,我们将包含两行的“客户”维度表与不断扩大的“事务”数据集进行联接。 我们在名为 sales_report 的表中实现这两个数据集之间的联接。 请注意,如果外部进程通过添加新行来更新客户表(customer_id=3, name=Zoya),则联接中不会显示此新行,因为启动流时快照了静态维度表。
from pyspark import pipelines as dp
@dp.temporary_view
# assume this table contains an append-only stream of rows about transactions
# (customer_id=1, value=100)
# (customer_id=2, value=150)
# (customer_id=3, value=299)
# ... <and so on> ...
def v_transactions():
return spark.readStream.table("transactions")
# assume this table contains only these two rows about customers
# (customer_id=1, name=Bilal)
# (customer_id=2, name=Olga)
@dp.temporary_view
def v_customers():
return spark.read.table("customers")
@dp.table
def sales_report():
facts = spark.readStream.table("v_transactions")
dims = spark.read.table("v_customers")
return facts.join(dims, on="customer_id", how="inner")
流式处理表的限制
流式处理表具有以下限制:
-
有限的演变: 无需重新计算整个数据集即可更改查询。 如果没有完全刷新,流式处理表只看到每一行一次,因此不同的查询将处理不同的行。 例如,如果在查询中的字段添加了
UPPER(),那么只有在该更改后处理的行会显示为大写。 这意味着必须了解数据集上运行的所有以前版本的查询。 若要在更改之前重新处理已处理的现有行,需要完全刷新。 - 状态管理:流式处理表具有低延迟,因此你需要确保它们处理的流是自然有界表或带水印的有界表。 更多信息,请参阅使用水印优化有状态处理。
- 联接不会重新计算: 当维度发生更改时,流式处理表中的联接不会重新计算。 这种特性在“快速但错误”的情境下可能是有益的。 如果希望视图始终正确,可能需要使用具体化视图。 具体化视图始终正确,因为它们在维度更改时自动重新计算联接。 有关详细信息,请参阅 具体化视图。