在此阶段,你将设计工作区体系结构,使其符合组织的结构、安全要求和运营需求。
了解工作区
Azure Databricks工作区是团队开发和运行工作负荷的云区域中的操作边界。 它包含协作项目(例如笔记本、作业、仪表板和存储库)和工作区范围的配置,例如工作区权限、群集策略、机密和 SQL 配置。 工作区是执行和协作环境。 持久性数据通常存储在云服务中,例如对象存储。
管理员根据组织的目标创建和配置工作区。 有些使用单个工作区,而另一些工作区则独立于域、环境(开发/测试/prod)、业务线、地理位置或法规边界。 这些选项决定了管理半径、职责分离、成本归因和复制频率。 从Azure Databricks开始,只需最少的配置,但较大的部署应考虑未来的要求,以及它们如何影响你在启用团队时保护数据的能力。
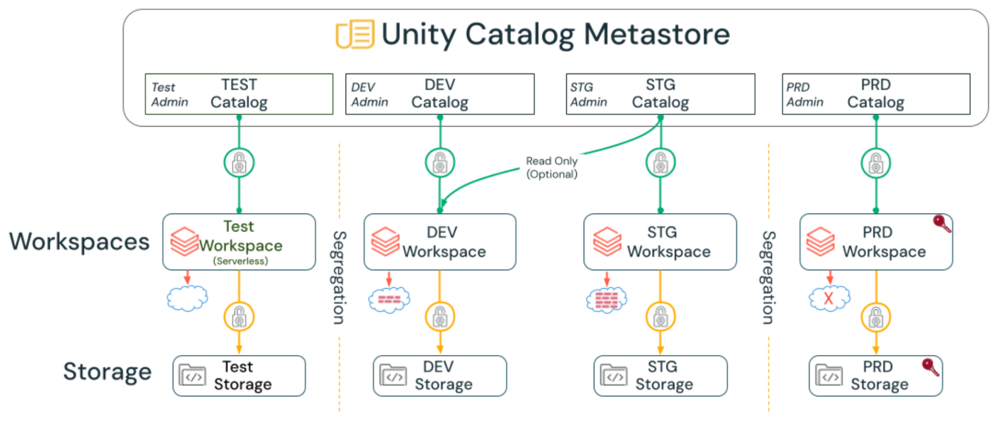
选择工作区部署模型
有以下类型的Azure Databricks工作区可用:
经典工作区
在您的 Azure Databricks 帐户中进行的工作区部署,旨在为您现有的云帐户分配存储和计算资源。 经典工作区中仍提供无服务器计算和服务。
经典工作区特征
- 客户管理的存储:云帐户中的存储。
- 客户管理的计算:云帐户中的计算基础结构。
- 网络控制:对VP/VNet 配置进行完全控制。
- 灵活性:无服务器计算仍可与经典计算一起使用。
工作区部署模型建议
使用这些建议可决定是否为方案部署无服务器工作区或经典工作区:
- 如果打算使用无服务器工作区和无服务器计算,请确认计划使用的区域是否支持无服务器工作区和无服务器计算。
- 查看无服务器工作区限制,以验证它们是否符合你的要求。
- 评估主要用例(例如自动缩放与细粒度群集控制),并相应地选择无服务器或经典工作区。
- 建议:从无服务器工作区开始,提高运营效率。
- 在以下情况下使用经典工作区:需要自定义网络配置、本地连接或特定的符合性要求。
设计工作区拆分策略
将 Lakehouse 设置拆分为不同工作区的原因有多种。 设计工作区体系结构时,请考虑这些模式。
拆分工作区的原因
根据数据保护要求隔离工作区
对于严格执行数据分离的受监管行业,隔离工作区以简化敏感数据的实现控制,而不会干扰风险较低的工作流。
隔离不同的业务部门
确保当组织边界需要完全隔离时,Azure Databricks中没有工作区资产在业务部门之间共享。
隔离具有不同平台需求的团队
如果不同的团队需要访问不同的平台功能集(例如,完全访问管理中心团队的所有功能,但不适用于其他团队或平台测试),则这些团队应由工作区分隔。
隔离软件开发生命周期 (SDLC) 环境
如果具有严格的隔离要求,请分离开发、过渡环境和 Prod 环境。 例如:
- 某些组织在不同的虚拟网络中部署开发/过渡/生产环境,因此每个环境都需要单独的工作区。
- 若要在将新工作区设置应用到 Prod(例如启用或限制功能)之前测试新工作区设置,Prod 必须与开发或暂存工作区不同。
- 许多企业还通过使用不同的存储容器、虚拟网络和Azure Databricks工作区,将这些环境与存储和计算角度隔离开来。
在多个云区域中运行
当一个组织在多个国家或地区为用户提供服务或收集数据时,法规或内部政策可能要求特定数据必须保存在本地区内,这就促使需要在每个云区域中部署单独的工作区来处理或存储这些数据。 拆分每个区域的工作区允许团队将Azure Databricks部署与本地存储帐户和虚拟网络保持一致,同时仍遵循常见的企业标准进行治理和安全性。
区域工作区还有助于减少交互式分析和数据应用程序的延迟,方法是将计算放在更靠近本地用户和数据源的地方,从而提高用户体验和查询性能。
拆分以克服资源限制
云帐户(或订阅)具有资源限制。 将工作区部署到不同的帐户是确保每个工作区有足够的资源可用的方法。 每个Azure Databricks工作区也有限制,例如可以同时运行的任务数或Azure Databricks应用的最大数目。 拆分工作区可确保每个工作区中的工作负荷都有权访问更多资源。
云提供商资源限制
Azure工作区限制
若要克服订阅级别限制(例如,最大存储帐户数或每秒最大请求速率),应在单独的Azure订阅中部署资源需求较高的工作区。
重要限制
- Azure订阅和服务限制。
- Microsoft Azure Databricks工作区限制。
拆分工作区的注意事项
协作限制
工作区之间没有笔记本共享(协作)。 尽可能跨工作区使用 Unity 目录来提升数据共享。 可以在工作区之间使用GitHub共享代码。
管理开销
大量工作区的管理开销可能会变得很大。 通常,拥有 100 多个工作区可能会导致孤立或非托管工作区,这可能会带来成本和/或外泄风险。
自动化要求
对于多个工作区,必须完全自动化设置和维护(使用 Terraform、云特定的工具或 REST API 等工具)。 这对于移动性目的和灾难恢复(DR)方案尤其重要,其中跨区域或云的快速工作区预配、故障转移和配置复制是关键操作要求。
网络基础结构成本
如果需要在网络层(例如数据外泄保护)保护每个工作区,则如果你有数百个工作区,必要的网络基础结构可能会非常昂贵。
功能限制
某些功能具有有限的跨工作区支持,例如使用无服务器出口控件(访问 Unity 目录托管服务)的无服务器计算。 某些功能(如 AI 功能、Azure Private Link 和加密密钥)在工作区级别定义。 如果企业需要其他团队的不同安全设置,则这些功能的批准将定义工作区拆分。
SDLC 和业务部门矩阵
如果要为 Dev/Staging/Prod 分隔工作区,并且还希望按工作区隔离业务部门,请考虑不同的云提供商的工作区限制。 矩阵可以快速生成大量工作区。
了解工作区安全模式
分配给 Unity 目录的工作区支持群集的以下访问模式:
| 安全模式 | 特征 |
|---|---|
| 标准 | 多个用户可以在同一群集上运行。 适用于常规工作负荷(例如 ETL、数据浏览)。 仅支持 SQL、Python 和 Scala。 支持精细访问控制(FGAC),包括基于视图的权限和基于属性的/基于表的访问控制(ABAC)。 不支持 Machine Learning ML DBR(但许多 ML 库可以安装在标准 DBR 上)。 |
| 专用 | 支持 ML DBR 和所有语言。 专用于单个用户:群集只能由一个用户访问(在创建群集期间分配)。 专用于单个组:同一组的多个用户可以在同一群集上工作(组是在创建群集期间分配的)。 |
示例工作区部署
Azure Databricks入门时,大多数组织都会在单个云区域中部署单租户 lakehouse。 但是,随着组织的增长,管理员可以定制部署以满足其复杂的用例。
单租户单区域部署
- 一个生产工作区。
- 一个开发工作区。
- 单个云区域中的所有资源。
多区域部署
- 美国区域中的生产工作区。
- 欧盟区域中的生产工作区(符合 GDPR 要求)。
- 共享开发工作区。
- 用于每个区域的 Unity Catalog 元存储和用于跨区域数据访问的 D2D Delta Sharing。
多业务部门部署
- 每个业务部门的一个工作区(例如销售、营销、工程)。
- 所有团队的共享开发工作区。
- 具有目录级隔离的 Central Unity Catalog 元存储。
基于环境的部署
- 生产工作区(所有业务部门)。
- 过渡工作区(预生产测试)。
- 开发工作区(共享开发)。
- 为每个环境分隔网络和存储。
定义工作区命名约定
为工作区建立一致的命名约定,以提高可发现性和管理性。
建议的命名模式
{organization}-{environment}-{region}-{purpose}
示例
acme-prod-us-west-analyticsacme-dev-sharedacme-prod-eu-west-gdpracme-staging-us-east-dataeng
工作区命名的最佳做法
- 使用小写字母和连字符。
- 包括环境名称(例如 prod、staging、dev)。
- 包括多区域部署的区域。
- 如果适用,请包括业务部门或用途。
- 将名称限制在 50 个字符以内。
- 在您的执行手册中记录文档命名约定。
工作区策略建议
推荐
- 将 SDLC 环境拆分为单独的工作区(至少开发与 Prod,但可能更多取决于要求)。
- 尽可能使用自动化工具(如 Terraform)来最大程度地减少人为错误并建立可重复的部署模式。
- 从无服务器工作区开始,仅在具有特定的网络或符合性要求时切换到经典工作区。
- 文档工作区拆分策略和命名约定。
- 为每个区域创建一个管理工作区,用于管理 Unity 目录资源。
避免这些模式
- 不要为单个团队或小型项目创建单独的工作区(请改用 Unity 目录目录和架构进行隔离)。
- 不要部署超过 50-100 个工作区,而无需强大的理由和可靠的自动化。
- 不要不必要的拆分工作区(平衡隔离需求与操作复杂性)。
- 避免在不遵循命名约定的情况下创建即席工作区。
阶段 2 结果
完成第 2 阶段后,应具备:
- 已选择工作区部署模型(无服务器与经典工作区)。
- 根据组织需求设计的工作区拆分策略(例如环境、业务部门、区域、合规性)。
- 了解资源限制和缓解策略。
- 定义的工作区命名约定。
- 安全模式已理解(标准模式与专用模式)。
- 记录的示例部署体系结构。
- 规划用于工作区配置的自动化战略。