指导原则是定义和影响体系结构的零级规则。 若要构建一个帮助企业在现在和将来取得成功的数据湖屋,组织中利益干系人之间的共识至关重要。
整理和优化数据并提供受信任的数据即产品
管理数据对于为商业智能 (BI) 和机器学习/人工智能 (ML/AI) 创建高价值数据湖至关重要。 将数据视为具有明确定义、架构和生命周期的产品。 确保语义一致性,并确保数据质量逐层提高,以便业务用户能够完全信任数据。
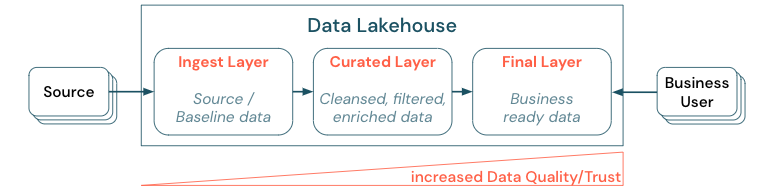
通过建立分层(或多层次)体系结构来管理数据是 Lakehouse 的一个关键最佳实践,因为这允许数据团队根据质量级别整理数据,并定义每一层的角色和职责。 一种常见的分层方法是:
- 摄取层:源数据摄取进入湖仓的第一层,并应在那里持久化。 当所有下游数据都从引入层创建时,可根据需要从该层重新构建后续层。
- 精心管理层:第二层的目的是存储已清理、精炼、筛选和汇总的数据。 此层的目的是为跨所有角色和功能的分析和报告提供健全、可靠的基础。
- 最终层:围绕业务或项目需求创建第三层;它为其他业务部门或项目提供不同的数据产品视图,围绕安全需求准备数据(例如匿名化数据)或优化性能(例如使用预聚合视图)。 此层的数据产品被视为业务的事实。
所有层的管道均需要确保满足数据质量约束,这意味着数据始终准确、完整、可访问且一致,即使在并发读取和写入期间也是如此。 新数据的验证发生在数据进入特选层时,并且以下 ETL 步骤可提高此数据的质量。 数据质量必须随着数据的层层递进而提高,因此,从业务角度来看,数据的可信度也会随之提高。
消除数据孤岛,并最大程度地减少数据移动
不要创建数据集的副本,尤其是业务流程依赖这些不同副本时。 副本可能会成为无法同步的数据孤岛,从而导致数据湖质量较低,最终导致出现过时或不正确的见解。 此外,若要与外部合作伙伴共享数据,请使用企业共享机制,以安全的方式直接访问数据。
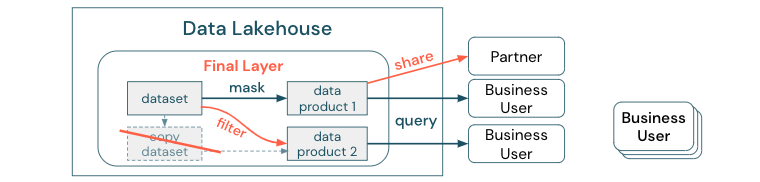
为了明确数据副本与数据孤岛之间的区别:独立或一次性的数据副本本身并不具有危害性。 有时有必要提高敏捷性、试验性和创新性。 然而,如果这些副本与依赖它们的下游业务数据产品一起投入运营,它们就会成为数据孤岛。
为了防止出现数据孤岛,数据团队通常会尝试构建机制或数据管道,以将所有副本与原始数据保持同步。 由于这种情况不太可能持续发生,数据质量最终会下降。 这也可能导致更高的成本,并导致显著的用户信任流失。 另一方面,一些业务用例要求与合作伙伴或供应商共享数据。
一个重要方面是安全可靠地共享最新版本的数据集。 数据集的副本通常并不足够,因为它们可能很快会脱离同步。 反之,应通过企业数据共享工具对数据进行共享。
通过自助服务实现价值创造的民主化
如果用户无法轻松访问其 BI 和 ML/AI 任务的平台或数据,则最佳数据湖无法提供足够的价值。 降低访问所有业务部门的数据和平台的障碍。 考虑精简数据管理过程并为平台和基础数据提供自助服务访问。
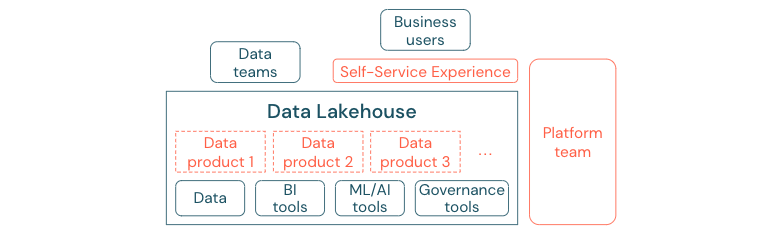
成功转向数据驱动文化的企业将蓬勃发展。 这意味着每个业务部门都从分析模型或分析自己的或集中提供的数据中派生其决策。 对使用者而言,数据必须是易于发现且易于访问的。
对于数据生产者来说,一个很好的概念是“数据即产品”:数据像产品一样由一个业务部门或业务合作伙伴提供和维护,由具有适当权限控制的其他方使用。 这些数据产品必须通过自助服务体验来创建、提供、发现和使用,而不是依赖中心团队和可能很缓慢的请求流程。
然而,重要的不仅仅是数据。 数据的民主化需要适当的工具,使每个人都能够生成或使用和理解数据。 为此,你需要让数据湖屋成为一个现代数据和 AI 平台,它提供用于构建数据产品的基础结构和工具,而无需费力重复设置另一个工具堆栈。
采用全组织范围的数据和 AI 治理策略
数据对任何组织而言都是重要资产,但不能向所有人授予对所有数据的访问权限。 必须主动管理数据访问。 访问控制、审核和世系跟踪是正确安全地使用数据的关键。
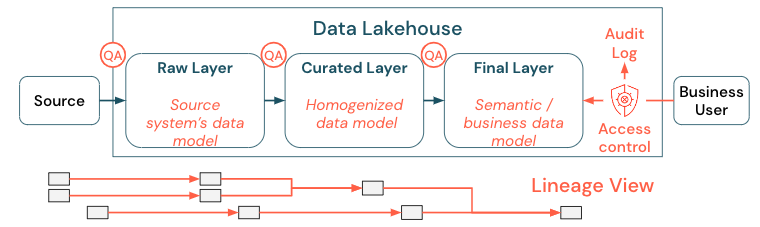
数据治理是一个广泛的话题。 湖屋涵盖以下维度:
数据质量
正确且有意义的报表、分析结果和模型最重要的先决条件是高质量的数据。 质量保证 (QA) 需要存在于所有管道步骤中。 如何实现这一点的示例包括具有数据协定、满足 SLA、保持架构稳定以及以受控方式进行演变。
数据目录
另一个重要的方面是数据发现:所有业务领域的用户(特别是在自助服务模型中)必须能够轻松发现相关数据。 因此,湖屋需要一个涵盖所有业务相关数据的数据目录。 设置数据目录的主要目标如下:
- 确保在整个业务中统一调用并声明相同的业务概念。 你可能会将其视为特选层和最终层中的语义模型。
- 精确跟踪数据世系,以便用户可以说明这些数据是如何到达其当前形态和形式的。
- 维护高质量的元数据,对于正确使用数据来说,这与数据本身一样重要。
访问控制
由于湖仓中的数据创造的价值贯穿所有业务领域,因此湖仓的构建必须将安全性视为首要因素。 公司可能具有更开放的数据访问策略,或严格遵循最低特权原则。 除此之外,每一层都必须有数据访问控制。 必须从头开始实施精细级别权限方案(列级和行级访问控制、基于角色或基于属性的访问控制)。 公司可以从不太严格的规则开始。 但是,随着湖屋平台的发展,更复杂的安全制度的所有机制和过程都应该到位。 此外,对湖屋中数据的所有访问都必须从一开始就受到审核日志的约束。
鼓励开放接口和开放格式
开放接口和数据格式对于湖屋和其他工具之间的互操作性至关重要。 它简化了与现有系统的集成,并开辟了将工具与平台集成的合作伙伴的生态系统。
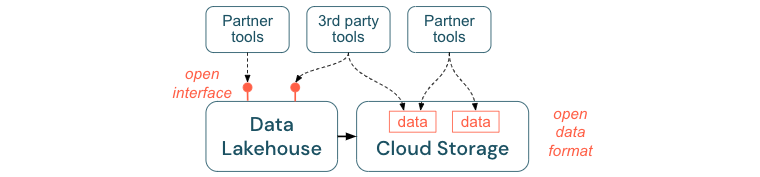
开放接口对于启用互操作性并防止依赖于任何单个供应商至关重要。 传统上,供应商构建专有技术和封闭接口,以限制企业存储、处理和共享数据的方式。
构建开放接口有助于为未来进行建设:
- 它增加了数据的持久性和可移植性,使你可以在更多应用程序和更多使用场景中使用它。
- 它将打开合作伙伴的生态系统,这些合作伙伴可以快速利用开放接口将其工具集成到湖屋平台中。
最后,通过对数据开放格式的标准化,总成本将大大降低;人们可以直接在云存储上访问数据,而无需通过可能产生高流出量和计算成本的专有平台来传输数据。
构建以实现规模化并优化性能和成本
数据不可避免地会继续增长,变得更加复杂。 为了满足组织的未来需求,你的湖仓应该具备扩展能力。 例如,你应该能够按需轻松添加新资源。 成本应限制为实际消耗。
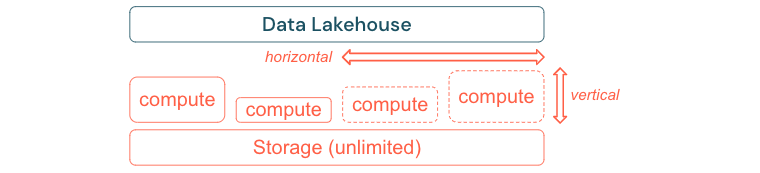
标准 ETL 流程、业务报表和仪表板通常在内存和计算方面具有可预测的资源需求。 但是,新项目、季节性任务或新式方法,如模型训练(流失、预测、维护)会生成资源需求的峰值。 为了使企业能够执行所有这些工作负载,需要一个可缩放的内存和计算平台。 必须能够按需轻松添加新资源,并且只有实际消耗才会产生成本。 一旦高峰期结束,即可重新释放资源,并相应降低成本。 通常,这称为水平缩放(较少或更多的节点)和垂直缩放(较大或较小的节点)。
缩放还使企业可以通过选择具有更多资源或具有更多节点的群集来提高查询的性能。 但是,与其永久提供大型机器和集群,不如根据需要按需配置它们,以便仅在优化整体性能与成本比所需的时间内使用。 优化的另一个方面是存储与计算资源之间的权衡。 由于使用此数据的数据量与工作负荷之间没有明确的关系(例如,仅使用部分数据或对小型数据执行密集计算),因此,选择一个能分拆存储和计算资源的基础架构平台是一种很好的做法。