数据工程师通常需要将数据从 Azure Databricks 上游的源(例如关系数据库(Oracle、Postgres、SQL Server)复制到 Azure Databricks 进行分析、报告和机器学习。 随着操作系统的变化,分析表必须与这些更改保持同步。
某些团队需要反映其操作数据库的当前状态,以便进行报告和分析。 其他人需要保留完整的可审核性、法规要求或客户分析更改历史记录。
更改数据捕获(CDC)将数据库视为一组更改,而不是将数据库视为完整的静态数据库。 下图显示,当源表中包含员工数据的行更新时,它会在只包含更改的 CDC 数据流中生成新的行集。 CDC 数据流的每一行通常包含其他元数据,包括操作(例如 UPDATE)以及一个列,可以用于确定 CDC 数据流中每一行的顺序,以便有效处理无序更新。 例如,sequenceNum 下图所示列用于确定 CDC 数据流中的行顺序:

CDC 允许在更新下游系统中的数据库时查看对数据所做的更改,以便进行更简单的事务。 如果这是一项要求,还可以允许你查看数据库的历史记录。
挑战在于源系统以不同的格式提供数据。 有些会发出捕获单个更改(插入、更新、删除)的更改流。 其他人仅提供整个表的定期快照。 每种格式都需要不同的处理方法,以使下游表准确且最新。
从历史上看,团队一直依赖于自定义 MERGE INTO 逻辑来应用这些更改——无论是来自变更源还是通过比较快照。 此方法非常复杂且容易出错,需要使用过渡表、窗口函数和排序假设,而这些假设在随着管道演变时难以理解和维护。
本页介绍两种 CDC 格式(SCD 类型 1 和类型 2),什么是 CDC 的详细信息,以及如何使用快照获取 CDC 的优势,即使源数据不支持它。
CDC 有什么好处?
变更数据捕获在工作负载中提供了多项优势。
- 更改数据通常小于完整数据集,下游查询可以处理更改作为对数据的增量更新。
- 可以通过某种方式存储更改数据,以便在特定时间重新构造记录,从而提供审核、时间点报告或趋势分析的完整历史记录。
- 更改数据允许一段时间内的稳定代理项密钥。
如何应用更改:更改的当前状态或完整历史记录
慢慢变化的维度(SCD)定义上游更改在到达数据表后如何应用和建模。 组织可以根据数据需求使用不同的方法。 SCD 类型 1 仅允许保存数据集的当前状态。 SCD 类型 2 保存数据集更改的完整历史记录。 本部分更详细地介绍了这些内容。
SCD 类型 1:仅当前状态
SCD 类型 1 会在发生更改时用新数据覆盖旧数据,只保留每个记录的最新版本。 历史记录不会保留。
在以下情况下使用 SCD 类型 1:
- 只需要数据的当前状态。
- 希望下游具体化视图以增量方式刷新,而不是完全重新计算。
- 需要稳定的代理键用于连接。
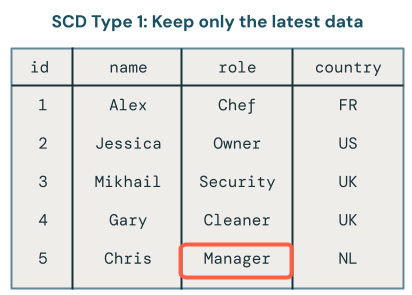
SCD1 中仅提供最新版本的数据。 这是一种简单的方法,你可以将其视为仅存储最终结果表。 如果记录从Owner更改为Manager,,则只有Manager保留在表中。
SCD 类型 2:历史跟踪
SCD 类型 2 通过创建多个版本的数据(每个版本都带有元数据时间戳)来维护完整的历史记录。
__START_AT和__END_AT列定义了记录每个版本的有效期。 活动记录具有 __END_AT = NULL。 可以在任何时间点查看数据集的状态。
在以下情况下使用 SCD 类型 2:
- 可审核性或法规要求需要历史跟踪。
- 客户分析需要了解实体随时间变化的方式。
- 业务逻辑需要时点报告。
- 你需要分析趋势或比较历史状态。
SCD 类型 2 处理用于维护数据变更的历史记录。 例如,如果记录当前已将角色字段设置为 Manager,您还可以看到该角色字段以前已设置为 Owner。 在下图中,这就是 Chris记录中发生的事情。 您可以识别当前记录,因为它的null字段具有end_at值。

什么是 CDC 数据流?
变更数据捕获(CDC)是一种数据集成模式,用于捕获对源系统中数据所做的更改-插入、更新和删除。 CDC 生成只包含已修改记录的数据流,而不是处理整个数据全集。
例如,如果 Oracle 中有一个员工表,其中包含 50 行,而一个员工的职务更改,则 CDC 源包含该员工的单个 UPDATE 记录。 这允许 Azure Databricks 仅处理已更改的记录,而不是在每次运行时读取整个源表。
源数据库中的每个 CDC 记录包括:
- 操作类型 (
INSERT,UPDATE,DELETE) - 记录的数据值
- 用于确定性排序的序列号或时间戳
序列号可确保正确应用延迟或无序到达。 事务数据库(如 SQL Server、MySQL 和 Oracle)以本机方式生成 CDC 源。 Delta 表还生成自己的 CDC 供稿,称为更改数据供稿(CDF),因此可以轻松处理来自 Delta 源的更改。
什么是快照?
快照表示特定时间点表的完整状态。 与仅捕获更改的 CDC 数据流不同,快照包含源表中的每一行。
由于各种原因,Teams 并不总是在操作数据库上启用 CDC 数据流。
- 成本(CDC 可以增加生产数据库的负载)
- 源数据库的性能问题
- 不支持 CDC 的旧系统
- 组织约束(管理引入的团队不拥有上游数据库)
当更改源不可用时,基于快照的引入是唯一的选项。 快照可以来自:
- 从关系数据库定期导出(Oracle、Postgres、SQL Server)
- 来自上游系统的云存储文件导出
- 增量表(每个表版本实际上是快照)
- 来自上游租户的增量共享
由于快照不会捕获记录级更改,因此确定更改需要比较快照中的记录,以推断插入、更新和删除。
自动处理 CDC 数据流
Azure Databricks 通过使用 Lakeflow Spark 声明性管道中的 AUTO CDC API 简化了 CDC 处理流程。 此 API 旨在处理源数据库或已启用更改数据流的 Delta 表上的 CDC 数据流的更改。
当以下任一项为 true 时使用 AUTO CDC :
- 源系统生成更改数据流(CDF)
- 您正在从一个启用了更改数据馈送的 Delta 表读取数据。
- 你有来自关系数据库的 CDC 流(通过 Debezium 或 Oracle GoldenGate 等工具)
AUTO CDC 通过按排序列定义的顺序处理事件,自动处理序列外记录。 序列列必须是正确事件顺序的单调递增表示,每个键在每个序列值上都有一次不同的更新。
NULL 不支持序列化值。 对于 SCD 类型 2,Lakeflow Spark 的声明性管道将序列值传播到__START_AT__END_AT目标表的列。
初始冻结: 将现有操作数据库表复制到 Azure Databricks 时,首先需要加载所有历史数据,然后再处理正在进行的更改。
AUTO CDC 通过 一次性流 支持该功能,这是一种一次性处理所有可用数据并随后停止的模式。 初始加载完成后,使用触发模式或连续模式流进行持续 CDC 处理。 这可确保批量加载和增量加载的一致逻辑。
自动处理快照
当 CDC 数据流不可用时,Azure Databricks 提供 AUTO CDC FROM SNAPSHOT API。 此 API 专为基于快照的引入而设计;它将 连续快照进行比较,生成综合更改源,并将 SCD 类型 1 或类型 2 逻辑应用到目标表中。 目标表可以为下游查询提供 SCD 类型 1 或类型 2 的 CDC 数据流(在 Delta 表中称为 更改数据馈送(CDF)。
AUTO CDC FROM SNAPSHOT 仅在 Python 管道接口中受支持。 快照必须按版本按升序处理;如果检测到无序快照,则忽略该快照。 后续处理(例如查询数据集输出 AUTO CDC FROM SNAPSHOT 的物化视图)可获得 CDC 的优势,例如增量更新能力和稳定的代理键。
注释
AUTO CDC FROM SNAPSHOT 不仅用于初始加载。 它被设计用于快照是您唯一可用的格式时的持续处理。 每次新快照到达时,API 都会将其与以前的快照进行比较,以派生更改和更改数据馈送。
在以下情况下使用 AUTO CDC FROM SNAPSHOT:
- 源数据库上未启用 CDC
- 只能访问定期快照(完整表转储)
- 你希望利用 CDC 的优势来进行增量处理,或者获得完整的更改历史记录。
AUTO CDC FROM SNAPSHOT 自动处理以下内容:
- 比较连续快照以标识插入、更新和删除的记录。
- 根据快照之间的差异产生合成变更源。
- 应用与
AUTO CDC相同的SCD逻辑来计算SCD类型1或类型2。
注释
AUTO CDC FROM SNAPSHOT 仅了解从一个快照到下一个快照的更改,并且不会获得临时更改。 例如,如果您获取每日快照,并且用户在一天内两次更改其地址(从A到B,然后从B到C),则您的更改源可能会直接从A到C,因为您只在那些时间段收到了快照。
快照处理模式
AUTO CDC FROM SNAPSHOT 支持两种用于确定快照版本的模式。
使用管道引入时间进行快照处理
在管道运行时读取快照,引入时间用作快照版本。 每次管道更新时都会纳入新的快照。 在连续工作模式下运行数据管道时,会根据流的触发器间隔设置采集多个快照。
当快照定期到达并按顺序到达时使用此模式,可以依赖管道运行时间戳进行版本控制。
使用版本函数进行快照处理
提供一个函数,用于指定要在管道运行时处理的快照版本。 该函数返回元组: (DataFrame, version_number)。 API 按版本号定义的顺序处理快照。 如果检测到无序快照,则忽略快照。
在以下情况下使用此模式:
- 多个快照可以同时到达,需要顺序处理。
- 快照可能会乱序到达。
- 您需要对快照排序进行显式控制。
其他 CDC 功能
针对 AUTO CDC 目标的操作变更
与标准流式处理表不同,作为目标的 Unity 目录表即使在管道运行期间也支持 AUTO CDC、INSERT、UPDATE、DELETE 和 MERGE 语句。 有关详细信息和限制,请参阅 在目标流式处理表中添加、更改或删除数据。
从 AUTO CDC 目标读取变更数据流
AUTO CDC 目标流式处理表可以发出自己的更改数据馈送 (CDF),允许下游管道使用 AUTO CDC 输出中的更改。 有关详细信息,请参阅 从 AUTO CDC 目标表读取变更数据流。
指标和监视
AUTO CDC 在每个管道运行中自动捕获 num_upserted_rows 和 num_deleted_rows 指标。 有关详细信息,请参阅 高级 AUTO CDC 主题。
跟踪 SCD 类型 2 的列子集
默认情况下,SCD 类型 2 会在任何列值发生更改时创建新版本。
AUTO CDC 允许您指定要跟踪历史记录的列,以便未跟踪列的更改直接更新当前版本,而不是创建新的历史记录。 这样可以降低存储成本和查询复杂性,同时保留关键属性的历史记录。 有关示例,请参阅 使用 SCD 类型 2 跟踪列子集。
建议
当你想要只处理数据更改时,请使用变更数据捕获(CDC),例如,以允许下游物化视图逐步更新。 如果要维护数据更改的历史记录,例如,若要知道谁在特定时间点具有什么角色,请使用 CDC。
需要将上游数据复制到 Azure Databricks 中并使其与源更改保持同步时,请使用 AUTO CDC API。 正确的 API 取决于源系统公开更改的方式:
-
使用
AUTO CDC当你的源发出更改馈送时——例如,使用像 Debezium 或 Oracle GoldenGate 这样的工具启用了 CDC 的关系数据库,启用了更改数据馈送的 Delta 表,或任何产生带有排序列的插入、更新和删除流的源。 -
使用
AUTO CDC FROM SNAPSHOT当数据源不支持 CDC,且仅提供定期的完整表转储时。 此 API 通过比较连续快照并生成合成更改流来推断出更改,因此即使没有本地的 CDC 数据流,也能获得与 SCD 处理相同的优势。
在这两种情况下,如果只需要每个记录的当前状态,请选择 SCD 类型 1;如果需要保留审核更改的完整历史记录、时间点报告或趋势分析,请选择 SCD 类型 2。
后续步骤
-
AUTO CDC API:使用管道简化变更数据捕获:了解如何结合使用
AUTO CDC和AUTO CDC FROM SNAPSHOTAPI 实现 CDC。 - 高级 AUTO CDC 主题:了解高级 CDC 主题,例如使用 DML 操作、读取更改数据馈送和监视指标。