所有捕获的跟踪都记录到 MLflow 实验。 可以通过 Databricks 工作区中的 MLflow UI 访问它们。
小窍门
如果 MLFLOW_TRACKING_URI 设置为 databricks,则 Databricks 工作区中的托管 MLflow 跟踪服务将存储跟踪信息并提供服务。 此生产就绪后端无需额外的托管。 请参阅 Databricks 上部署的跟踪代理。
导航到实验:转到记录日志追踪的实验。 例如,实验设置
mlflow.set_experiment("/Shared/my-genai-app-traces")。打开“跟踪”选项卡:在试验视图中,单击“ 跟踪 ”选项卡以查看记录到该试验的所有跟踪的列表。
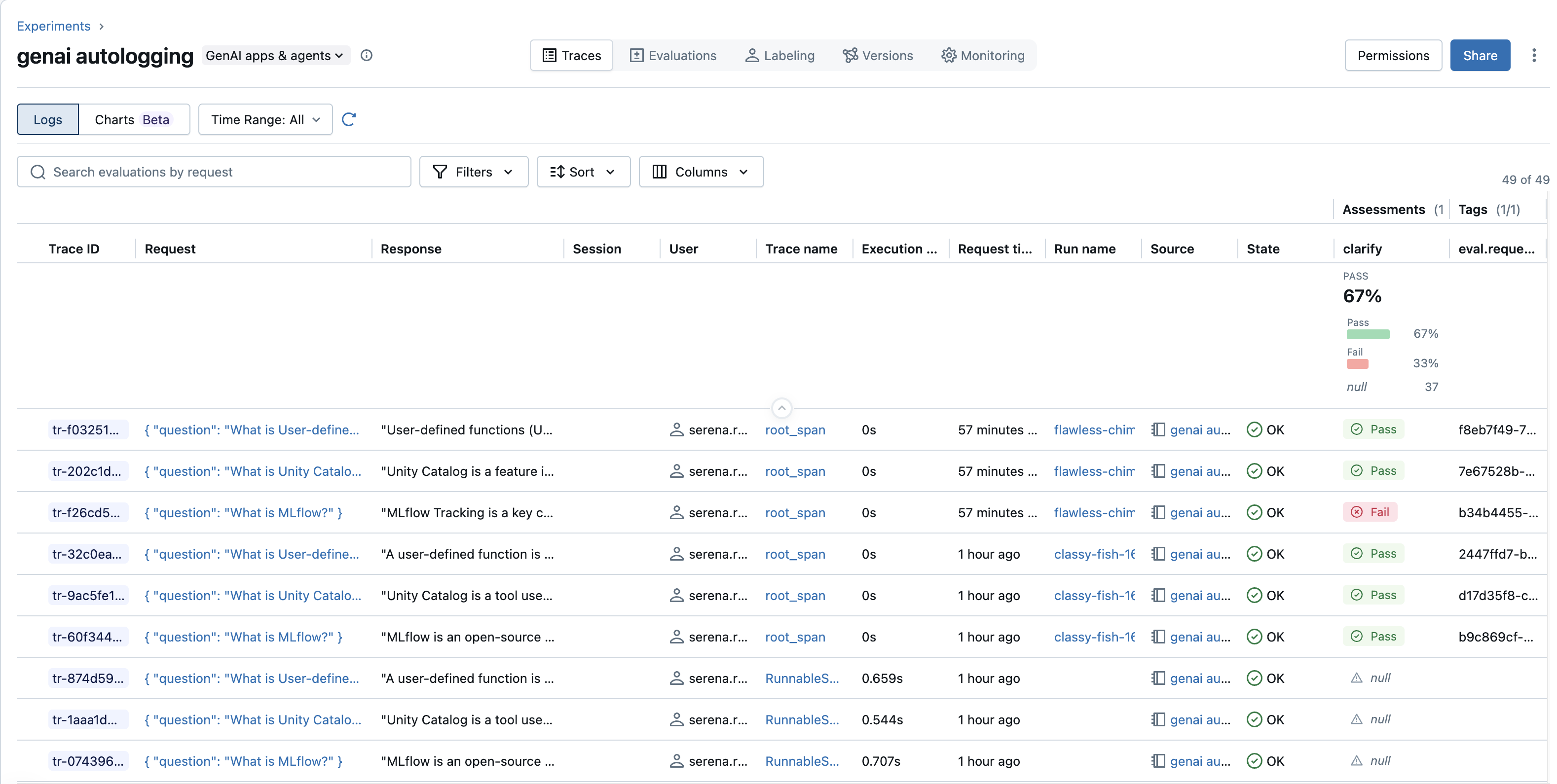
了解跟踪清单
跟踪列表提供您的跟踪的高级概览,通常会包括可排序的列:
- 跟踪 ID:每个跟踪的唯一标识符。
- 请求:预览触发跟踪的初始输入。
- 响应:追踪的最终输出预览。
- 会话:会话标识符(如果提供)对相关跟踪进行分组(例如,在会话中)。
- 用户:用户标识符(如果提供)。
- 执行时间:跟踪完成所花费的总时间。
- 请求时间:启动跟踪时的时间戳。
- 运行名称:如果跟踪与 MLflow Run 相关联,则会在此处显示其名称,并链接它们。
-
源:跟踪的来源,通常指示已检测的库或组件(例如
openai,langchain或自定义跟踪名称)。 -
状态:跟踪的当前状态(例如,
OK、ERROR、IN_PROGRESS)。 - 跟踪名称:分配给此跟踪的特定名称,通常是根范围的名称。
-
评估:每个评估类型的单个列(例如,
my_scorer,professional)。 UI 还经常显示列表上方的摘要部分,其中显示当前可见跟踪的聚合评估指标(如平均值或通过/失败率)。 -
标记:单个标记可以显示为列(例如,
persona,style)。 可能还存在标记的汇总计数。
搜索和筛选日志
用户界面提供了多种查找和聚焦相关跟踪的方法:
-
搜索栏(通常标记为“按请求搜索评估”或类似):这样,您可以通过搜索其
Request(输入)字段的内容快速找到痕迹。 -
筛选器下拉列表:有关更结构化的筛选,请使用“筛选器”下拉列表。 这通常允许基于以下项生成查询:
-
属性:例如
Request内容、Session time或Execution timeRequest time。 -
评估:按评估的状态或特定值进行筛选,例如
my_scorer或professional。 - 其他字段,如
State,,Trace nameSession,User和Tags(例如,tags.persona = 'expert')。
-
属性:例如
-
排序下拉列表:使用“排序”下拉列表按各种列(例如
Request time,Execution time等)对跟踪进行排序。 - 列下拉列表:自定义跟踪列表中可见的列,包括特定的标记或评估指标。
元数据筛选器
在 MLflow UI (跟踪选项卡)中,可以查看附加的元数据:
在 MLflow UI 中,使用以下搜索查询筛选跟踪:
# Find all traces for a specific user
metadata.`mlflow.trace.user` = 'user-123'
# Find all traces in a session
metadata.`mlflow.trace.session` = 'session-abc-456'
# Find traces for a user within a specific session
metadata.`mlflow.trace.user` = 'user-123' AND metadata.`mlflow.trace.session` = 'session-abc-456'
# Find traces from production environment
metadata.`mlflow.source.type` = 'production'
# Find traces from a specific app version
metadata.app_version = '1.0.0'
浏览单个踪迹
若要深入了解特定跟踪,请单击列表中的 “请求 ”或 “跟踪名称 ”。 这会打开详细的跟踪视图,其中包含两个主要选项卡:
- 摘要:对跟踪记录的高级别概览。 此选项卡显示根跨度的输入和输出、任何关键中间跨度,以及追踪期间引发的任何异常。 使用 “默认”、“ JSON”和 “表 ”切换来更改选项卡呈现输入和输出的方式。
- 详情和时间线:各时间段的完整细分情况,包含每个时间段的详细信息。 以下部分介绍此视图。
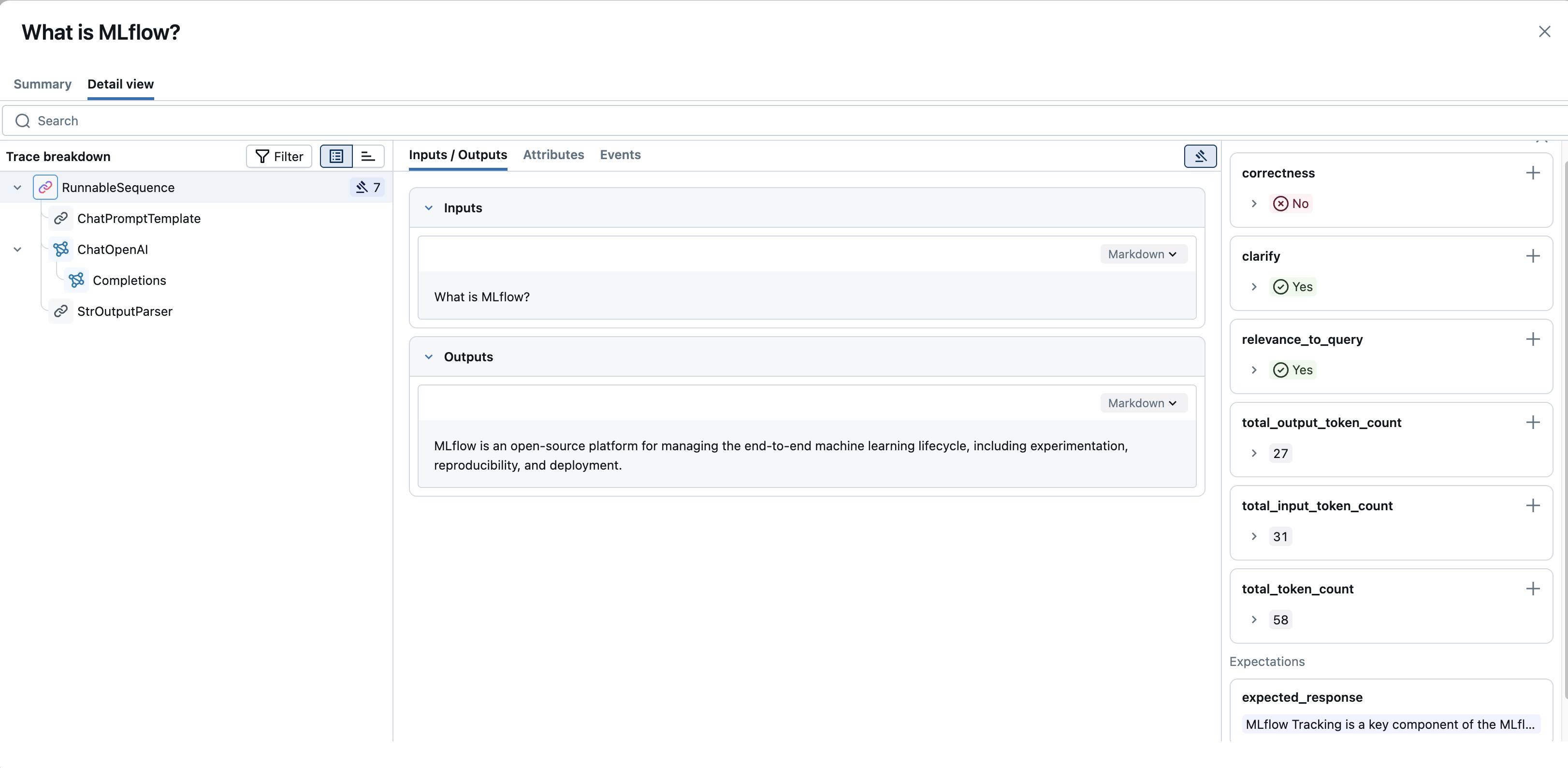
“ 详细信息和时间线 ”选项卡包含几个主面板:
跟踪细分(左面板):
- 此面板(通常标题为“跟踪细分”)将 跨度层次结构 显示为树形图或瀑布图。 它显示跟踪中的所有操作(跨度)、它们的父子关系以及它们的执行顺序和持续时间。
- 可以从此细分中选择单个片段来检查其特定详细信息。
跨度详细信息(中心面板):
从“跟踪细分”中选择范围时,此面板会显示其详细信息,通常按以下选项卡进行组织:
聊天:对于基于聊天的 LLM 交互,此选项卡通常提供聊天流(用户、助理、工具消息)的呈现视图。
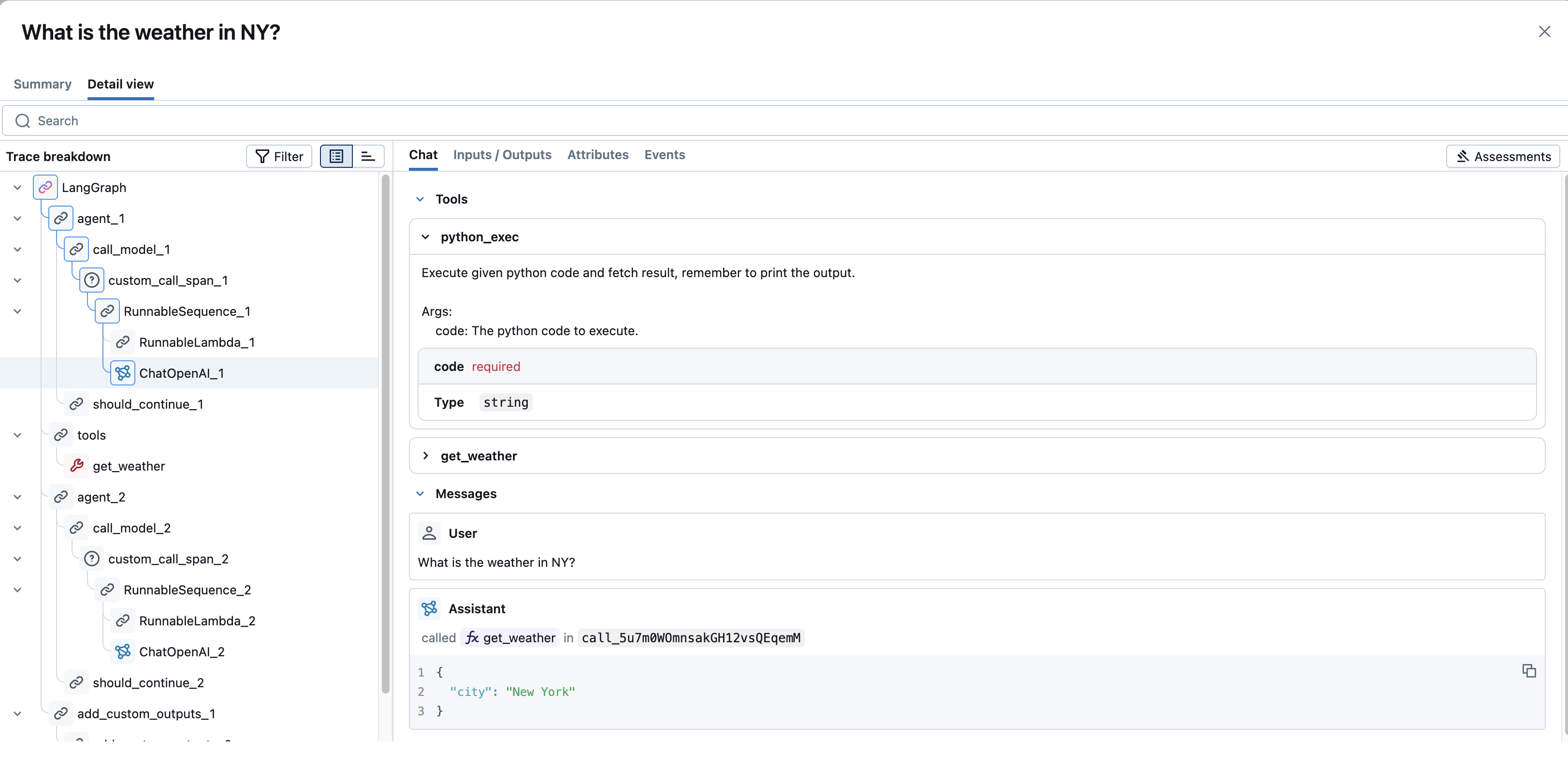
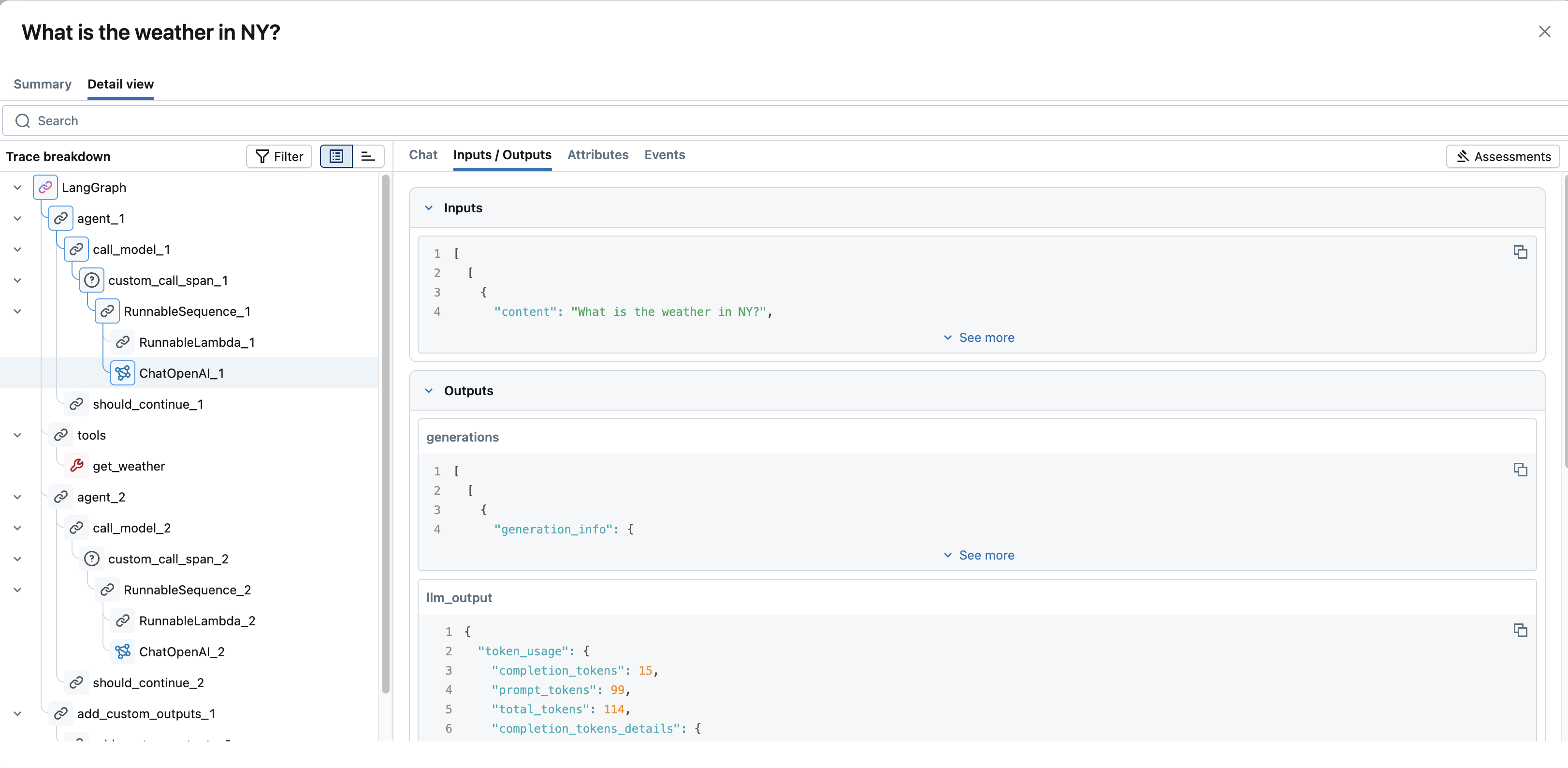
输入/输出:显示传递给作的原始输入数据和返回的原始输出数据。 对于大型内容,“查看更多”/“查看更少”切换可用于展开或折叠视图。
属性:显示特定于范围(例如
modelLLM 调用的名称temperature)的键值元数据;doc_uri对于检索器范围。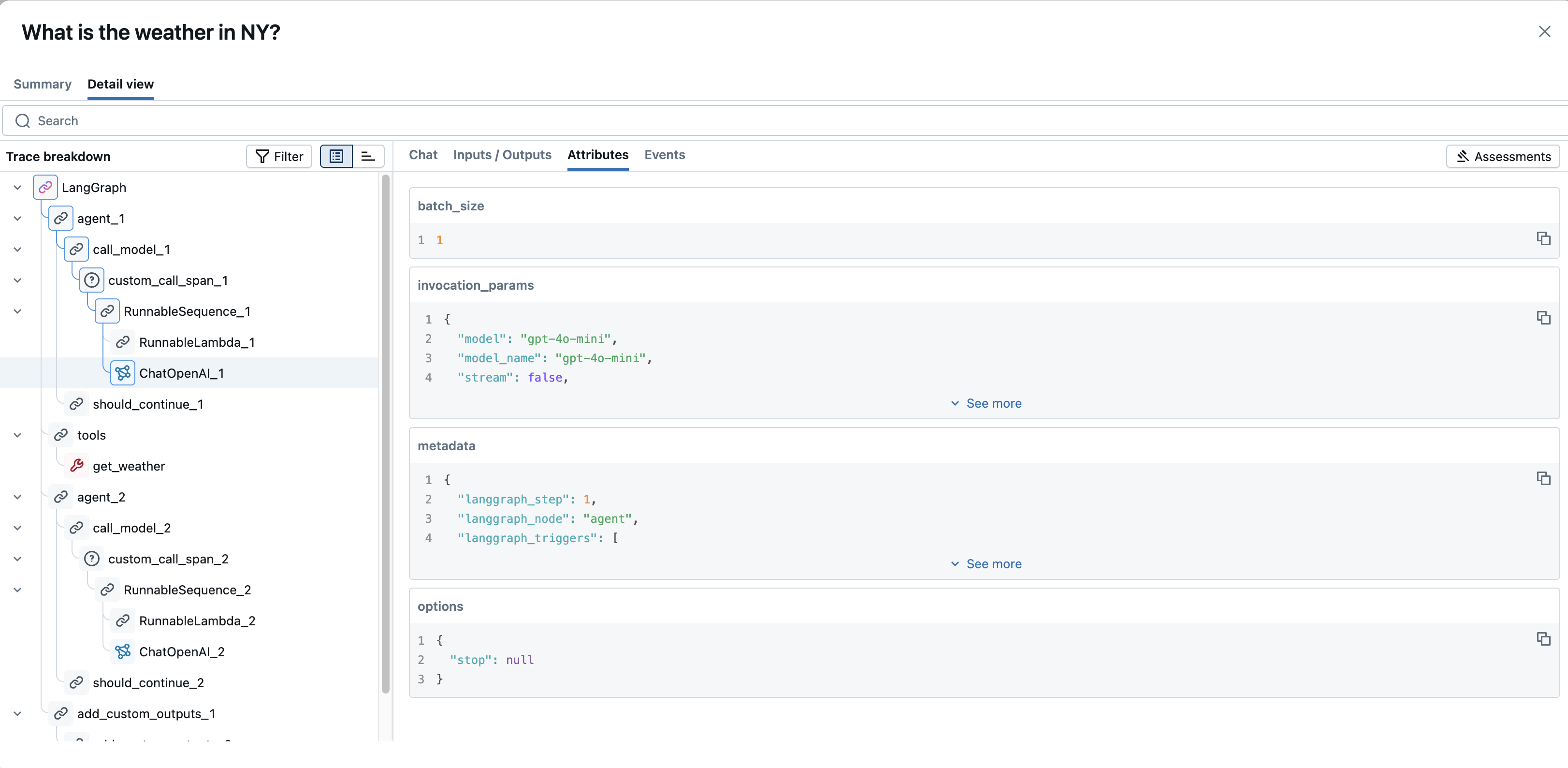
事件:对于遇到错误的跨度,此选项卡通常显示异常详细信息和堆栈跟踪。 对于流式数据范围,它可能会在产出单个数据区块时显示它们。
如果内容采用 Markdown 格式,某些输出字段可能还有 一个 Markdown 切换, 可在原始视图和呈现视图之间切换。
评估(右侧面板):
- 此面板显示已针对 整个跟踪 或 当前所选范围记录的任何评估(用户反馈或评估)。
- 关键是,此面板通常包括 “+ 添加新评估” 按钮,允许你在查看跟踪时直接从 UI 记录新的反馈或评估分数。 这对于手动评审和标记工作流非常有用。
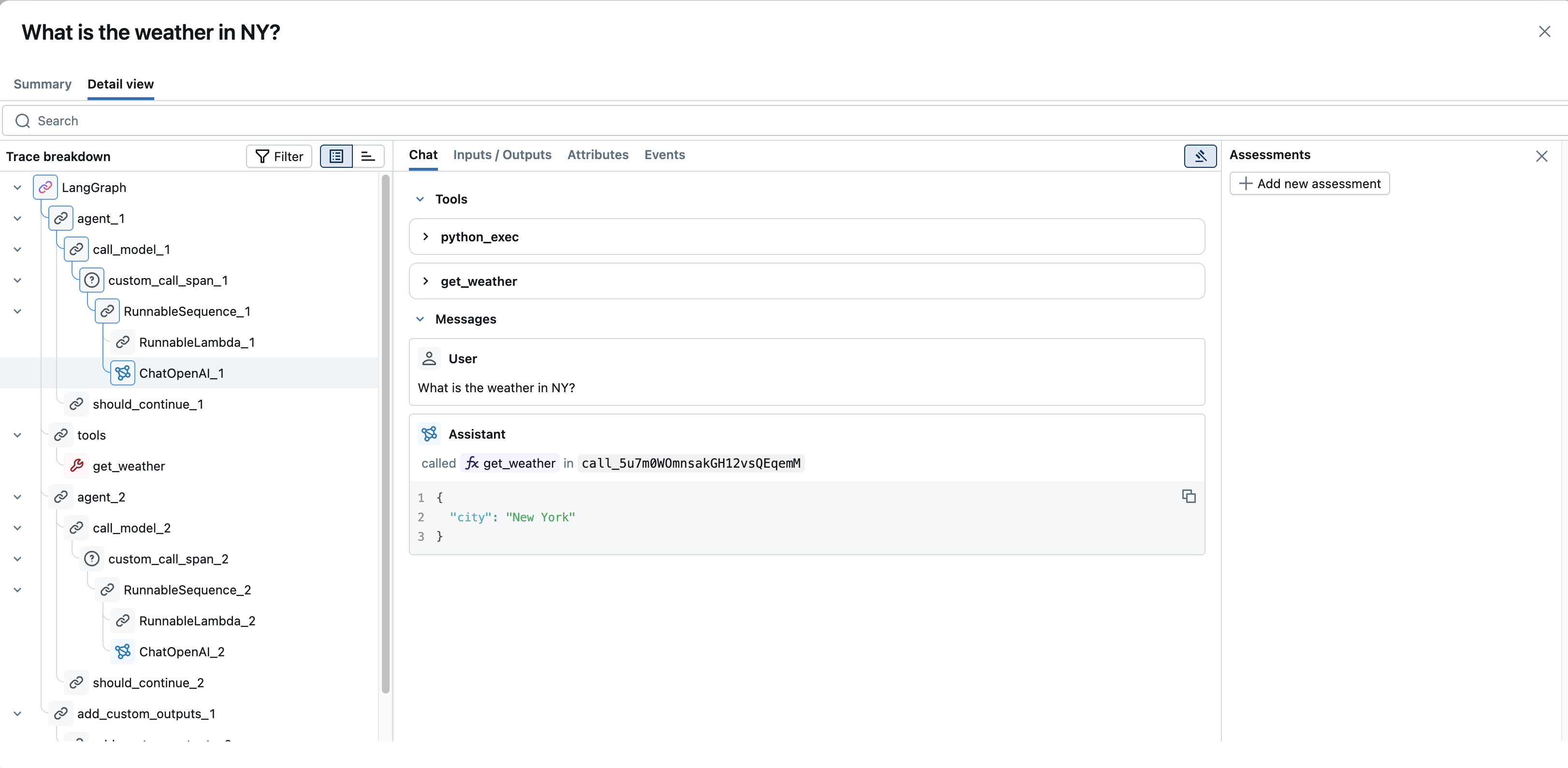
Trace-Level 信息:除了单个范围详细信息之外,视图还提供对整体跟踪信息的访问。 这包括整个跟踪的跟踪级别标记和任何评估(通常在未选择特定跨度或根跨度时显示在评估窗格中),这些可能源自直接用户反馈或系统评估。
常见调试方案
下面介绍如何使用 MLflow 跟踪 UI 解决常见的调试和可观测性需求:
确定慢速跟踪(延迟瓶颈):
- 在跟踪列表视图中:使用“排序”下拉列表按降序按“执行时间”对跟踪进行排序。 这会将最慢的记录带到顶部。
- 在详细跟踪视图中:打开慢速跟踪后,请检查“跟踪细分”面板。 跨度的瀑布图将直观地突出显示花费时间最长的操作,帮助你查明你的应用程序流中的延迟瓶颈。
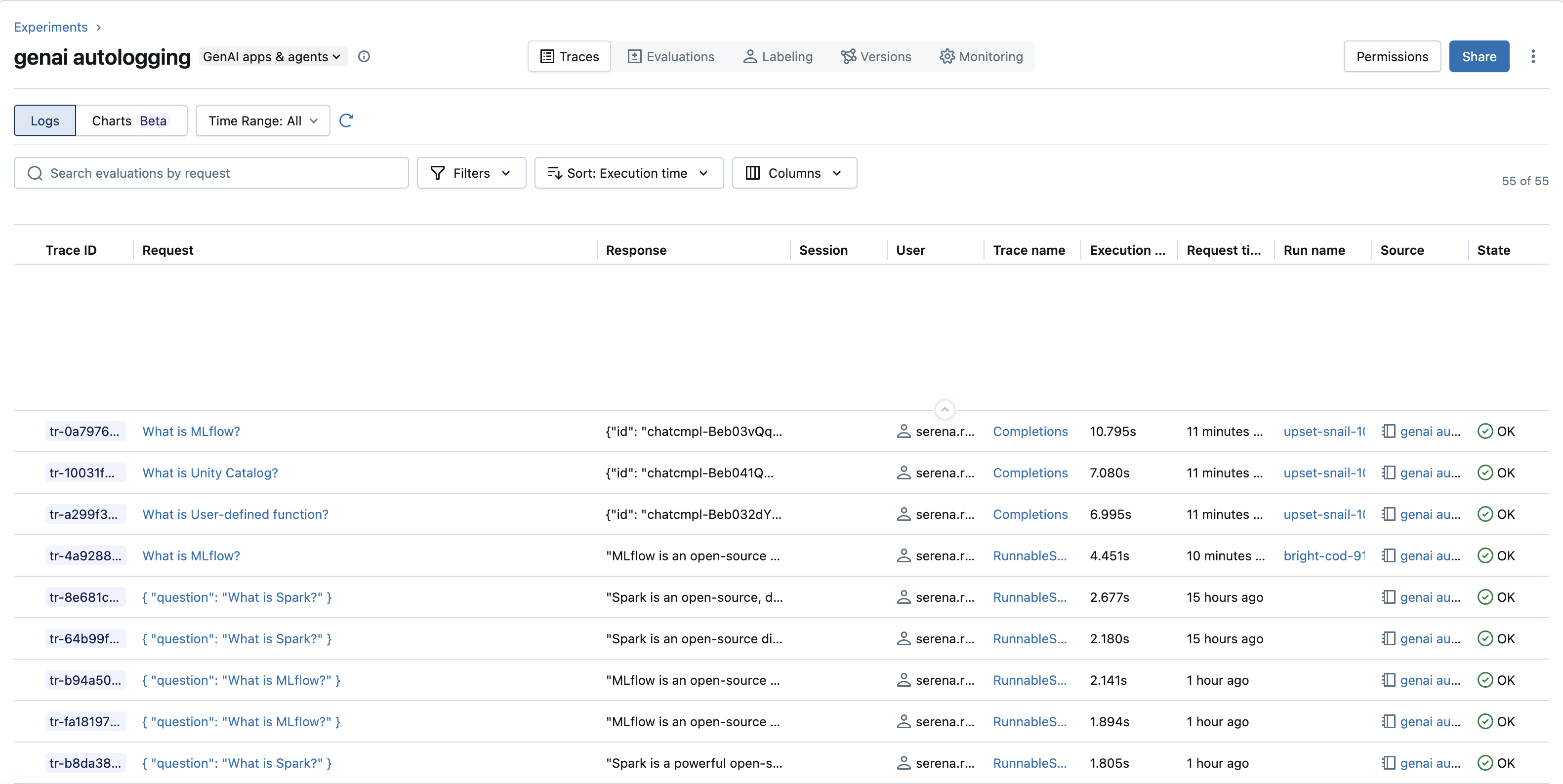
查找来自特定用户的追踪:
- 使用筛选器:如果 跟踪了用户信息 ,并且它可用作筛选器选项(例如,在“筛选器”下拉列表中的“属性”或专用的“用户”筛选器下),则可以选择或输入特定的用户 ID。
-
使用搜索和标记:或者,如果将用户 ID 存储为标记(例如,
mlflow.trace.user),请使用包含类似tags.mlflow.trace.user = 'user_example_123'查询的搜索栏。
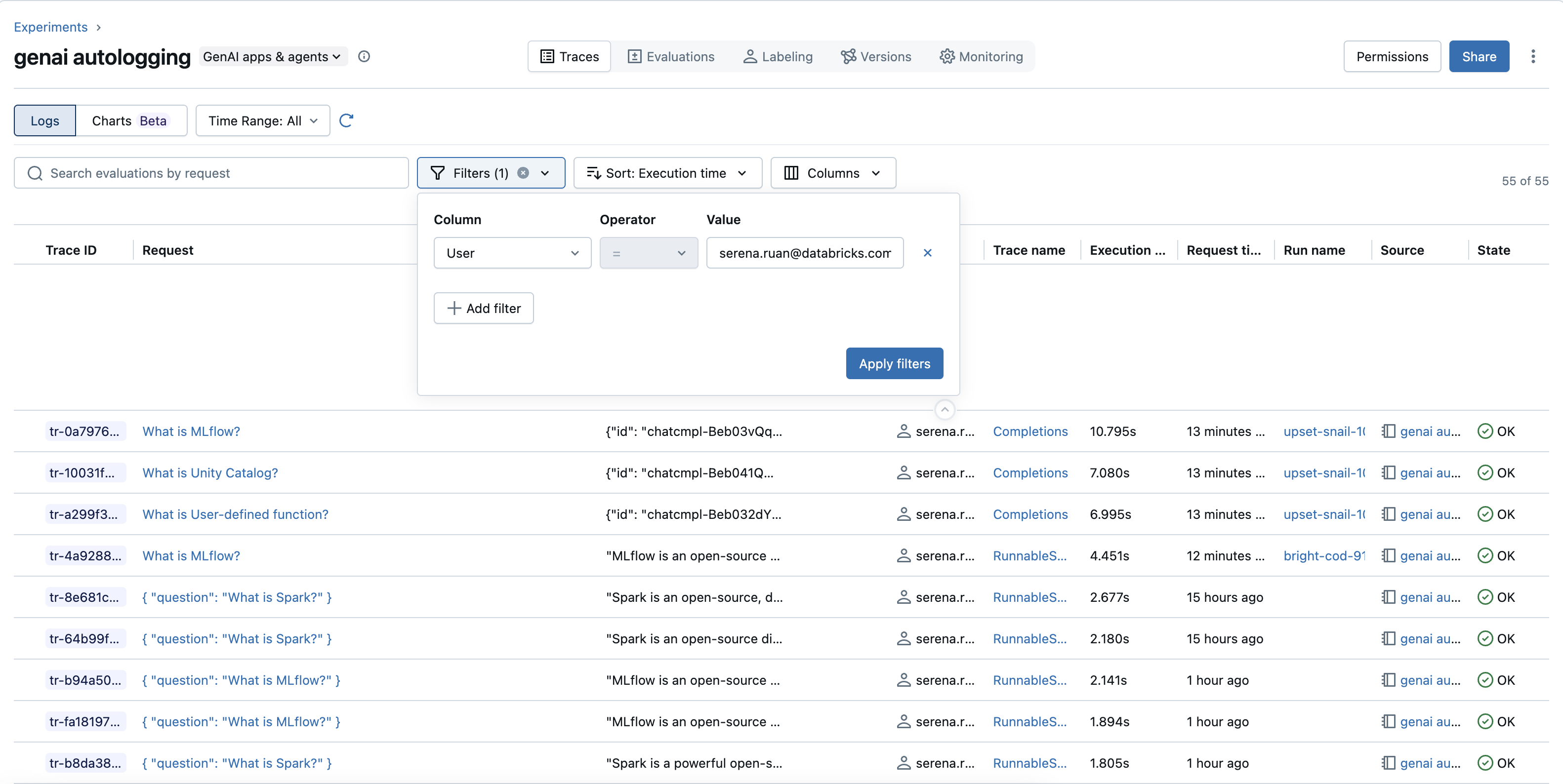
查找故障记录(错误):
-
使用筛选器:在“筛选器”下拉列表中,选择
State属性,然后选择ERROR以仅查看失败的痕迹。 - 在详细跟踪视图中:对于错误跟踪,请选择“跟踪明细”中标记有错误的跨度。 导航到“范围详细信息”面板中的“事件”选项卡以查看异常消息和堆栈跟踪,这对于诊断故障的根本原因至关重要。
-
使用筛选器:在“筛选器”下拉列表中,选择
识别有负面反馈或问题的踪迹:
-
使用评估筛选器:如果要收集导致评估的用户反馈或运行评估(例如布尔值
is_correct或数字relevance_score),“筛选器”下拉列表可能会允许你按这些评估名称及其值进行筛选(例如,筛选或is_correct = false筛选relevance_score < 0.5)。 - 查看评估:打开追踪,检查“评估”面板(详细视图右侧)或检查单个跨度的评估。 这将显示任何记录的反馈、分数和理由,帮助你了解为什么响应被标记为质量差。
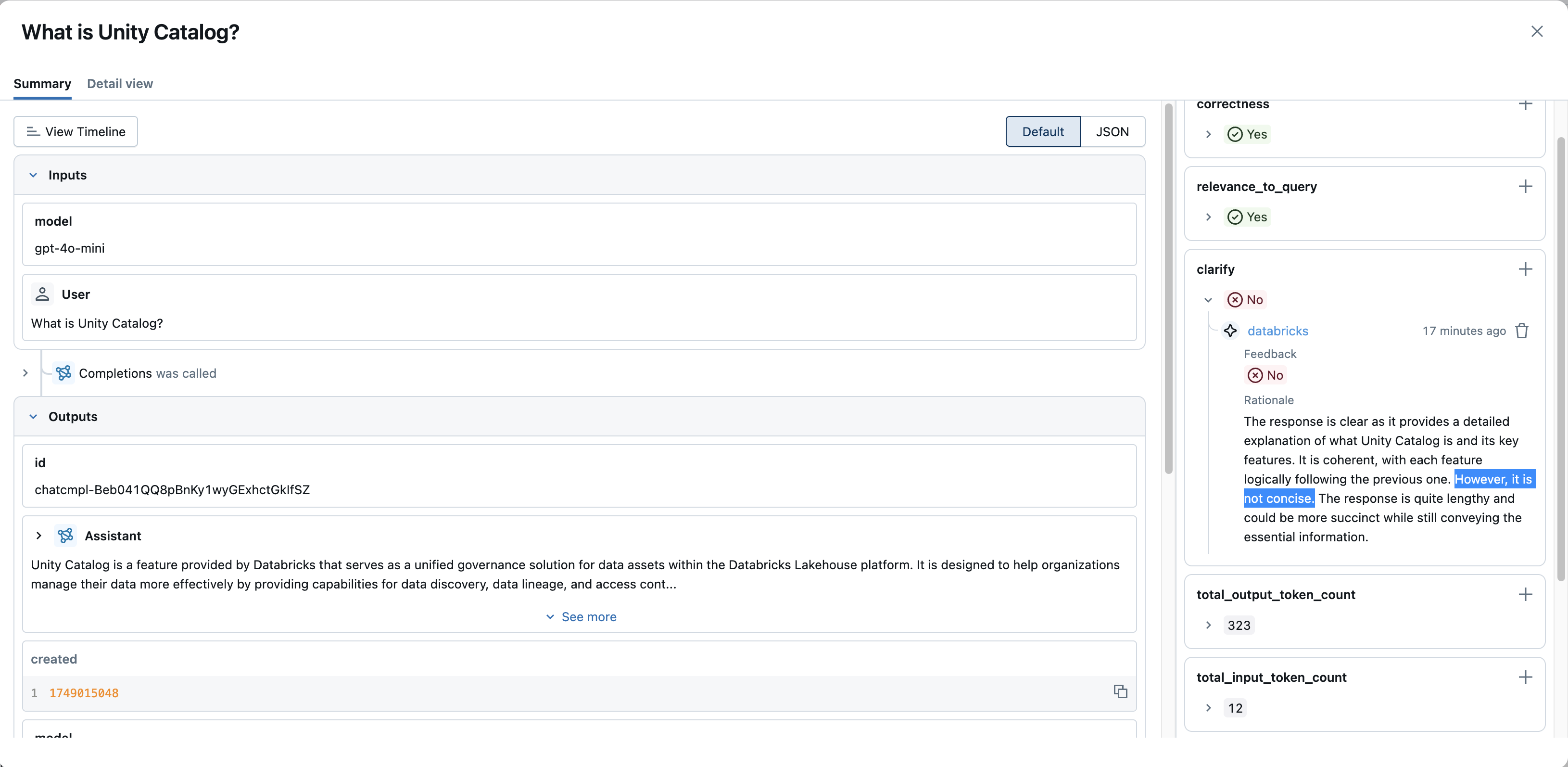
-
使用评估筛选器:如果要收集导致评估的用户反馈或运行评估(例如布尔值
这些示例演示了 MLflow 跟踪捕获的详细信息(与 UI 的查看和筛选功能相结合)如何有效地调试问题并观察应用程序的行为。
Databricks 笔记本中的追踪
MLflow 跟踪在 Databricks 笔记本中提供无缝体验,使你可以直接将跟踪作为开发和试验工作流的一部分进行查看。
注释
MLflow Tracing 功能在 MLflow 2.20 及更高版本中,支持与 Databricks Notebook 的集成。
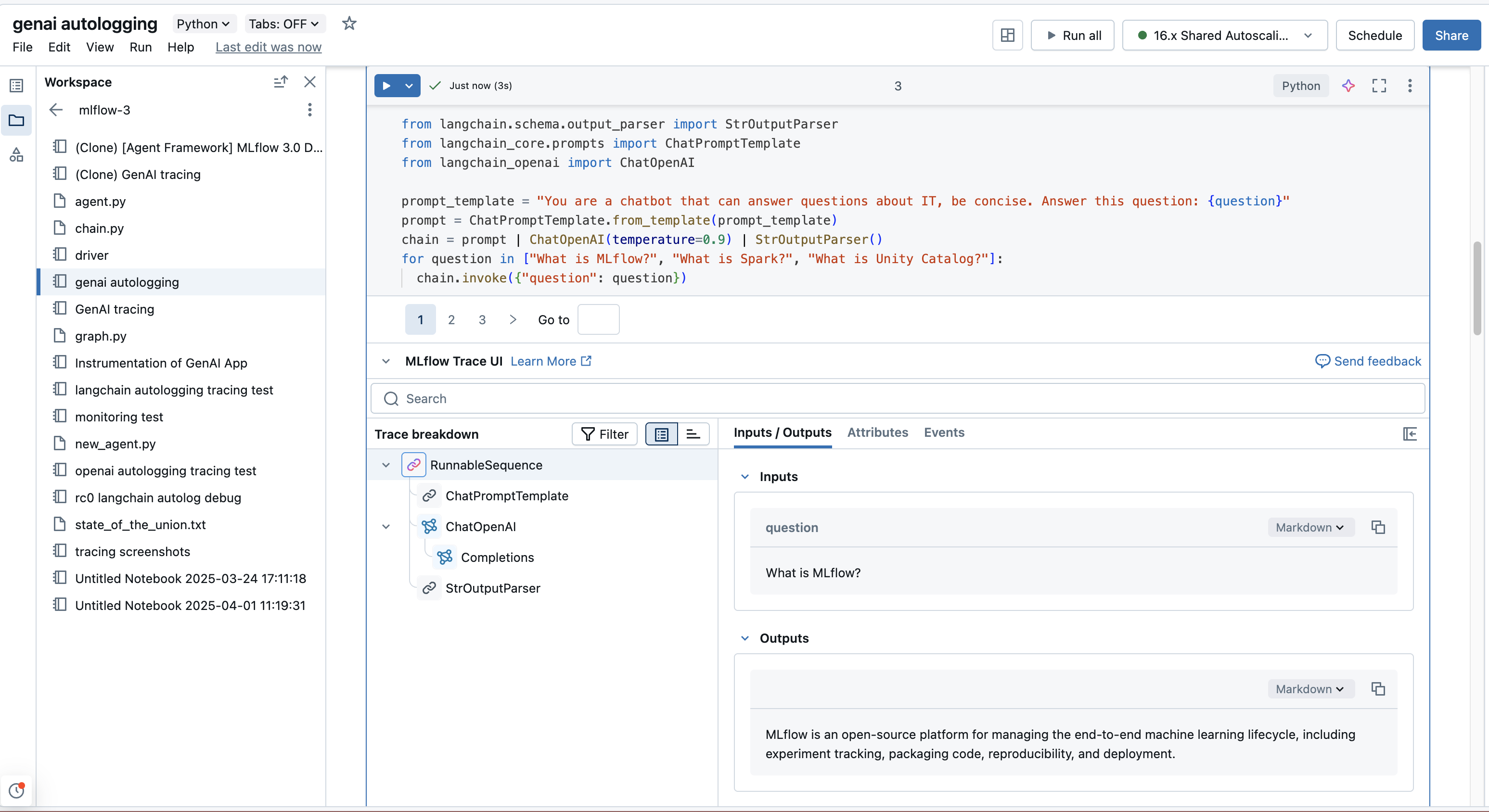
在 Databricks 笔记本中工作时,如果您的 MLflow 跟踪 URI 设置为 "databricks" (这通常是默认设置,或可以通过 mlflow.set_tracking_uri("databricks") 设置),跟踪 UI 就可以自动显示在单元格的输出中。
这通常在以下情况下发生:
- 单元格的代码执行生成跟踪(例如,通过调用修饰的
@mlflow.trace函数或 自动检测的库调用)。 - 显式调用
mlflow.search_traces()并显示结果。 - 对象
mlflow.entities.Trace(例如,frommlflow.get_trace()是单元格中的最后一个表达式或传递给display()。
此笔记本内视图提供了在主 MLflow 试验 UI 中找到的相同丰富交互式跟踪浏览功能,帮助你在不切换上下文的情况下更快地循环访问。
控制笔记本显示
若要启用或禁用笔记本单元输出中跟踪的自动显示,请运行: mlflow.tracing.disable_notebook_display()mlflow.tracing.enable_notebook_display()
局限性
- 追踪列表最多返回 1,000 条追踪。 筛选器和跟踪 ID 搜索仅适用于此集,而不适用于完整试验,因此大型试验中的较旧跟踪可能不会显示。 若要查找较旧的跟踪记录,请将时间范围缩小到包含该记录的时间段。
- 不在 Unity Catalog 中的实验最多只能包含 100,000 个跟踪。
后续步骤
- 通过 SDK 查询跟踪 - 以编程方式搜索和分析自定义工作流的跟踪
- 生成评估数据集 - 选择跟踪并将其转换为测试数据,以便系统评估和质量改进