注释
本文中的手动优化建议不适用于使用自动文件大小优化的 Unity 目录托管表。 对于新表,请使用具有默认设置的 Unity 目录托管表。
在 Databricks Runtime 13.3 及更高版本中,Databricks 建议对表布局使用聚类分析。 请参阅对表使用 liquid 聚类分析。
在 Databricks Runtime 10.4 LTS 及更高版本中,MERGE、UPDATE 和 DELETE 操作的自动压缩和优化写入功能始终处于启用状态。 不能禁用此功能。
有一些选项可用于手动或自动配置写入和 OPTIMIZE 操作的目标文件尺寸。 Azure Databricks 会自动优化其中的许多设置,并启用通过找出适当文件大小来自动提高表性能的功能。
对于 Unity Catalog 托管表,如果你使用的是 SQL 仓库或 Databricks Runtime 11.3 LTS 或更高版本,则 Databricks 会自动优化其中的大部分配置。
如果要从 Databricks Runtime 10.4 LTS 或更低版本升级工作负荷,请参阅 升级到后台自动压缩。
何时运行 OPTIMIZE
自动压缩和优化写入都可以减少小文件存在的问题,但不能完全替代 OPTIMIZE。 特别是对于大于 1 TB 的表,Databricks 建议按计划运行 OPTIMIZE 以进一步合并文件。 Databricks 建议使用液体聚类来增强数据跳过功能。 启用液体聚类分析后, OPTIMIZE 自动按聚类分析键重新组织数据。 请参阅对表使用 liquid 聚类分析。
什么是 Azure Databricks 的自动优化?
术语“自动优化”有时用于描述由设置 和 autoOptimize.autoCompact 控制的功能。 此术语现已弃用,取而代之的是对每个设置进行单独描述。 请参阅 自动压缩 和 优化写入。
自动压缩
自动压缩将表分区中的小文件合并,以减少小文件问题。 它在写入成功后在执行写入的群集上同步运行,并且仅压缩以前未压缩的文件。
自动压缩和预测优化是可以单独或一起使用的独立功能。 自动压缩在执行写入操作的群集上运行,而预测优化过程则使用无服务器计算异步运行维护操作。
使用以下设置配置自动压缩:
| 设置 | Delta | Iceberg | Description |
|---|---|---|---|
| 启用自动压缩(表属性) | autoOptimize.autoCompact |
autoOptimize.autoCompact |
在表级别启用自动压缩。 |
| 启用 Spark 会话的自动压缩 | spark.databricks.delta.autoCompact.enabled |
spark.databricks.iceberg.autoCompact.enabled |
在会话级别启用自动压缩。 |
| 最大输出文件大小 | spark.databricks.delta.autoCompact.maxFileSize |
spark.databricks.iceberg.autoCompact.maxFileSize |
控制目标输出文件大小。 |
| 触发压缩的最小文件 | spark.databricks.delta.autoCompact.minNumFiles |
spark.databricks.iceberg.autoCompact.minNumFiles |
设置分区或表中触发自动压缩所需的小文件的最低数量。 |
这些设置接受以下选项:
| 选项 | Behavior |
|---|---|
auto(推荐) |
在遵循其他自动调优功能的同时调整目标文件大小。 需要 Databricks Runtime 10.4 LTS 或更高版本。 |
legacy |
true 的别名。 需要 Databricks Runtime 10.4 LTS 或更高版本。 |
true |
使用 128 MB 作为目标文件大小。 不进行动态大小调整。 |
false |
关闭自动压缩。 可以在会话级别设置,以覆盖工作负载中所有被修改表的自动压缩功能。 |
注释
Azure Databricks 建议使用自动调整来控制基于表大小的输出文件大小。 请参阅 基于表大小的自动优化文件大小。
优化写入
优化后的写入在数据写入时可以优化文件大小,并提升对表的后续读取性能。
优化写入对已分区表的效果最好,因为它们可以减少写入每个分区的小文件数。 写入较少的大文件比写入大量的小文件更为有效,但写入延迟仍可能会增加,因为数据在写入之前会随机排列。
下图演示了优化的写入操作的工作原理:
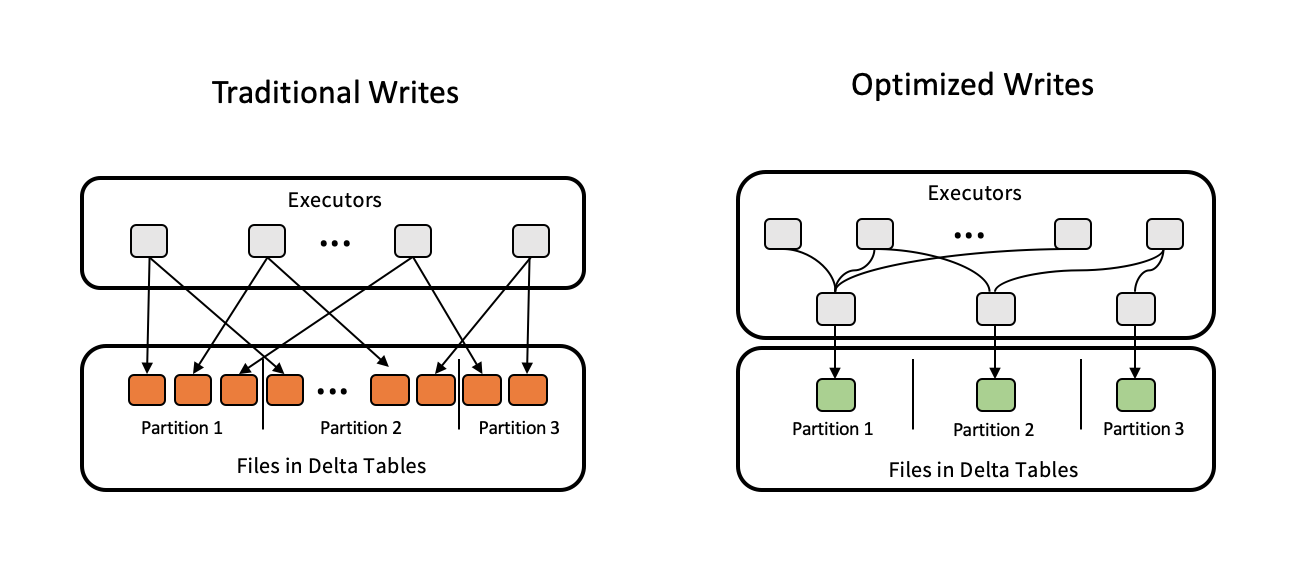
注释
在你写出数据之前,代码可能会运行 coalesce(n) 或 repartition(n) 以控制写入的文件数。 优化写入消除了使用该模式的必要性。
默认情况下,Databricks Runtime 9.1 LTS 及以上版本在以下操作中启用优化写入。
MERGE-
UPDATE与子查询 -
DELETE与子查询
使用 SQL 数据仓库时,还会为 CTAS 语句和 INSERT 操作启用优化写入。 在 Databricks Runtime 13.3 LTS 及更高版本中,注册在 Unity Catalog 中的所有表都启用了针对语句CTAS和已分区表的INSERT操作的优化写入。
可以使用以下设置在表或会话级别启用优化写操作:
- 表属性:
autoOptimize.optimizeWrite - SparkSession 设置:
spark.databricks.delta.optimizeWrite.enabled(Delta)或spark.databricks.iceberg.optimizeWrite.enabled(Iceberg)
这些设置接受以下选项:
| 选项 | Behavior |
|---|---|
true |
使用 128 MB 作为目标文件大小。 |
false |
关闭优化写入。 可以在会话级别设置,以覆盖工作负载中所有被修改表的自动压缩功能。 |
设置目标文件大小
如果要调整表中文件大小,请将 表属性targetFileSize 设置为所需大小。 设置后,所有数据布局优化操作都会尽力生成指定大小的文件,包括优化、液态聚类、自动压缩和优化写入。
注释
使用 Unity Catalog 托管表和 SQL 仓库或 Databricks Runtime 11.3 LTS 及更高版本时,只有 OPTIMIZE 命令遵循 targetFileSize 设置。
| 属性 | Description |
|---|---|
delta.targetFileSize (Delta)iceberg.targetFileSize (冰山) |
类型:大小(以字节为单位或更大的单位)。 说明:目标文件大小。 例如: 104857600(字节)或 100mb。默认值:无 |
对于现有表,你可以使用 SQL 命令 ALTER TABLE SET TBL PROPERTIES 设置和取消设置属性。 使用 Spark 会话配置创建新表时,还可以自动设置这些属性。 有关详细信息,请参阅 表属性参考 。
根据表大小自动优化文件大小
为了最大程度地减少手动优化的需求,Azure Databricks 会根据表的大小自动调整表的文件大小。 Azure Databricks 对较小的表使用较小的文件大小,对较大的表使用较大的文件大小,以便表中的文件数不会太大。 Azure Databricks 不会自动调整已使用 特定目标大小的表。
目标文件大小基于表的当前大小。 对于小于 2.56 TB 的表,自动调整后的目标文件大小为 256 MB。 对于大小介于 2.56 TB 和 10 TB 之间的表,目标大小将从 256 MB 线性增长到 1 GB。 对于大于 10 TB 的表,目标文件大小为 1 GB。
注释
当表的目标文件大小增加时,OPTIMIZE 命令不会将现有文件重新优化为较大的文件。 因此,大型表始终有可能包含一些小于目标大小的文件。 如果还需要将这些较小文件优化为较大的文件,则可以使用表属性 targetFileSize 为表配置固定的目标文件大小。
当以增量方式写入表时,根据表大小,目标文件大小和文件计数将大致如下所示。 此表中的文件计数只是一个示例。 实际结果会因许多因素而异。
| 表大小 | 目标文件大小 | 表中的大致文件数 |
|---|---|---|
| 10 GB | 256 MB | 40 |
| 1 TB(兆字节) | 256 MB | 4096 |
| 2.56 TB | 256 MB | 10240 |
| 3 TB | 307 MB | 12108 |
| 5 TB(兆字节) | 512 MB | 17339 |
| 7 兆字节 | 716 MB | 20784 |
| 10 兆字节 | 1GB | 24437 |
| 20 TB | 1GB | 34437 |
| 50 TB | 1GB | 64437 |
| 100 TB | 1GB | 114437 |
限制写入数据文件的行数
包含窄数据的表偶尔会遇到这种错误:给定数据文件中的行数超过 Parquet 格式的支持限制。 为了避免此错误,可以使用 SQL 会话配置 spark.sql.files.maxRecordsPerFile 指定要写入表单个文件的最大记录数。 指定零值或负值表示无限制。
在 Databricks Runtime 11.3 LTS 及更高版本中,在使用 DataFrame API 写入表时,也可以使用 DataFrameWriter 选项 maxRecordsPerFile 。 指定后 maxRecordsPerFile,SQL 会话配置 spark.sql.files.maxRecordsPerFile 的值将被忽略。
注释
除非有必要避免上述错误,否则 Databricks 不建议使用此选项。 对于某些包含非常窄的数据的 Unity Catalog 托管表,可能仍有必要使用此设置。
升级到后台自动压缩
在 Databricks Runtime 11.3 LTS 及更高版本中,Unity Catalog 托管的表可以进行后台自动压缩。 迁移旧工作负荷或表时,请执行以下操作:
- 从群集或笔记本配置设置中删除 Spark 配置
spark.databricks.delta.autoCompact.enabled(Delta)或spark.databricks.iceberg.autoCompact.enabled(Iceberg)。 - 对于每个表,运行
ALTER TABLE <table_name> UNSET TBLPROPERTIES (delta.autoOptimize.autoCompact)(Delta) 或ALTER TABLE <table_name> UNSET TBLPROPERTIES (iceberg.autoOptimize.autoCompact)(Iceberg) 以删除任何旧的自动压缩设置。
移除这些旧配置后,你会看到为所有 Unity Catalog 管理表后台自动压缩功能被自动触发。