Azure Databricks 的默认部署会创建由 Databricks 管理的新虚拟网络。 本快速入门介绍如何改为在自己的虚拟网络中创建 Azure Databricks 工作区。 你还会在该工作区中创建 Apache Spark 群集。
若要详细了解为什么可以选择在自己的虚拟网络中创建 Azure Databricks 工作区,请参阅在 Azure 虚拟网络中部署 Azure Databricks(VNet 注入)。
先决条件
如果没有 Azure 订阅,请创建一个试用版订阅。 不能使用 Azure 试用版订阅完成本教程。 如果你有试用版订阅,请转到个人资料,将订阅更改为“标准预付费套餐”。 有关详细信息,请参阅 Azure 试用版订阅。 然后,移除支出限制,并为你所在区域的 vCPU 请求增加配额。 创建 Azure Databricks 工作区时,可以选择“试用版(高级 - 14天免费 DBU)”定价层,让工作区访问免费的高级 Azure Databricks DBU 14 天。
必须是 Azure 参与者或所有者,或者必须在订阅中注册 Microsoft.ManagedIdentity 资源提供程序。 有关说明,请查看注册资源提供程序。
登录到 Azure 门户
登录 Azure 门户。
注意
如果要在持有美国政府合规性认证(如 FedRAMP High)的 Azure 商业云中创建 Azure Databricks 工作区,请联系你的 Azure 或 Databricks 客户团队以获得这种体验的访问权限。
创建虚拟网络
在 Azure 门户菜单中,选择“创建资源”。 然后选择“网络”>“虚拟网络”。
在“创建虚拟网络”下,应用以下设置:
设置 建议值 描述 订阅 用户的订阅<> 选择要使用的 Azure 订阅。 资源组 Databricks 快速入门 选择“新建”,然后输入帐户的新资源组名称。 名称 Databricks 快速入门 选择虚拟网络的名称。 区域 <选择离用户最近的区域> 选择可以在其中托管虚拟网络的地理位置。 使用最靠近用户的位置。 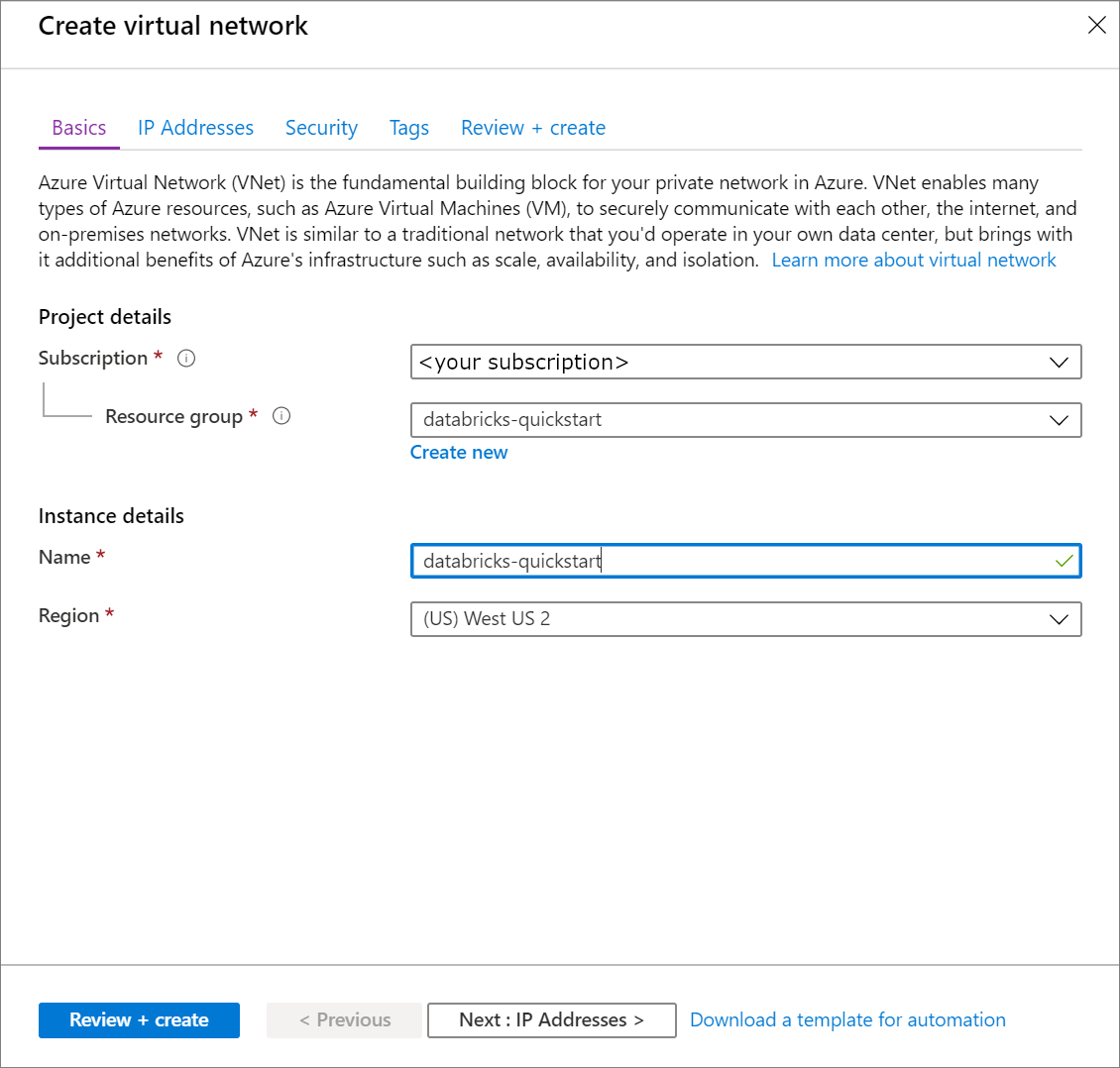
选择“下一步: IP 地址 >”并应用以下设置。 然后选择“查看 + 创建”。
设置 建议值 描述 IPv4 地址空间 10.2.0.0/16 用 CIDR 标记来表示的虚拟网络地址范围。 CIDR 范围必须介于 /16 和 /24 之间 子网名称 默认 选择虚拟网络中默认子网的名称。 子网地址范围 10.2.0.0/24 以 CIDR 表示法表示的子网地址范围, 它必须包含在虚拟网络的地址空间中。 不能编辑使用中的子网的地址范围。 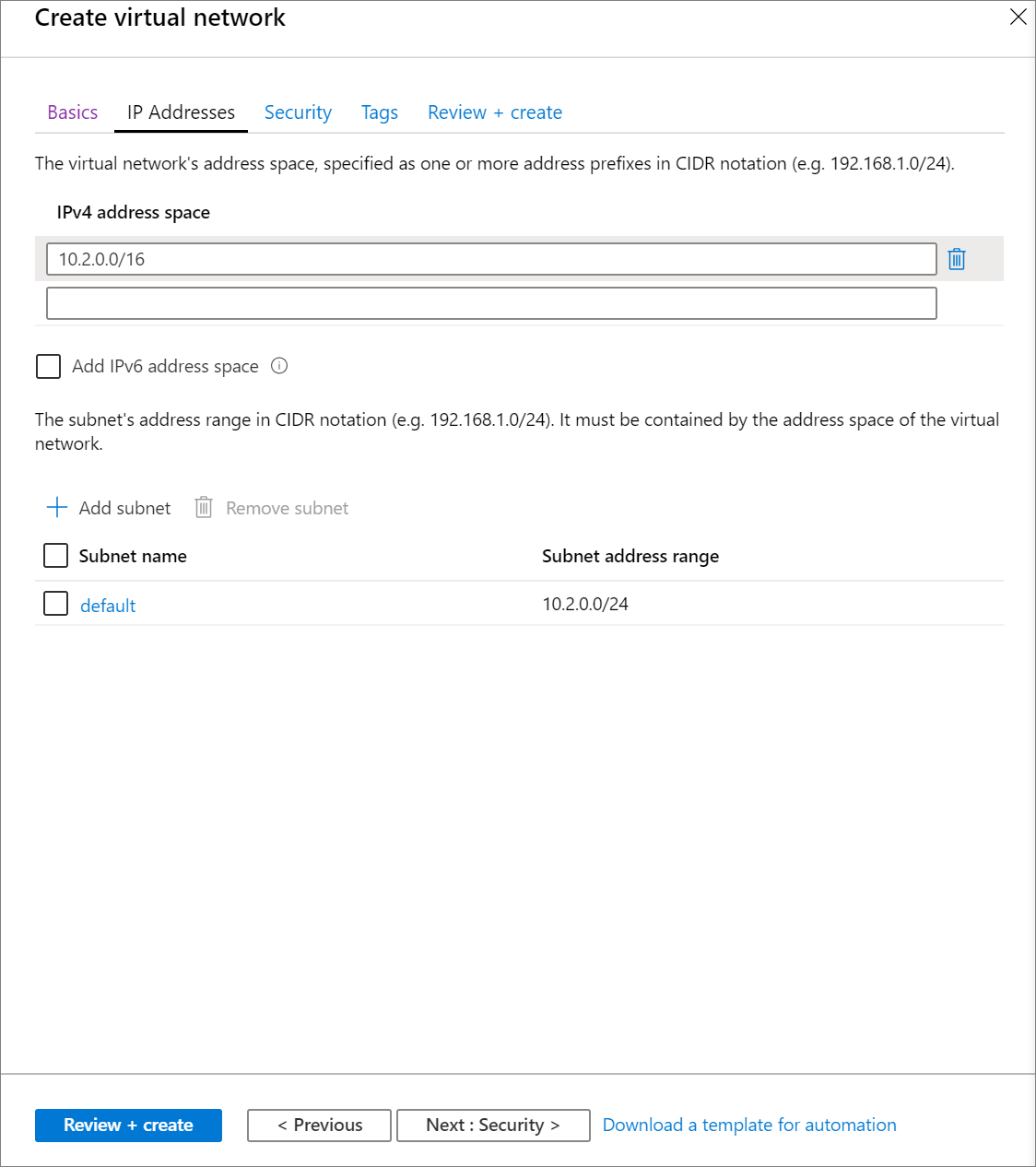
在“查看 + 创建”选项卡中,选择“创建”以部署虚拟网络。 部署完成后,导航到虚拟网络,并在“设置”下选择“地址空间”。 在显示“添加其他地址范围”的框中,插入 并选择“保存”。
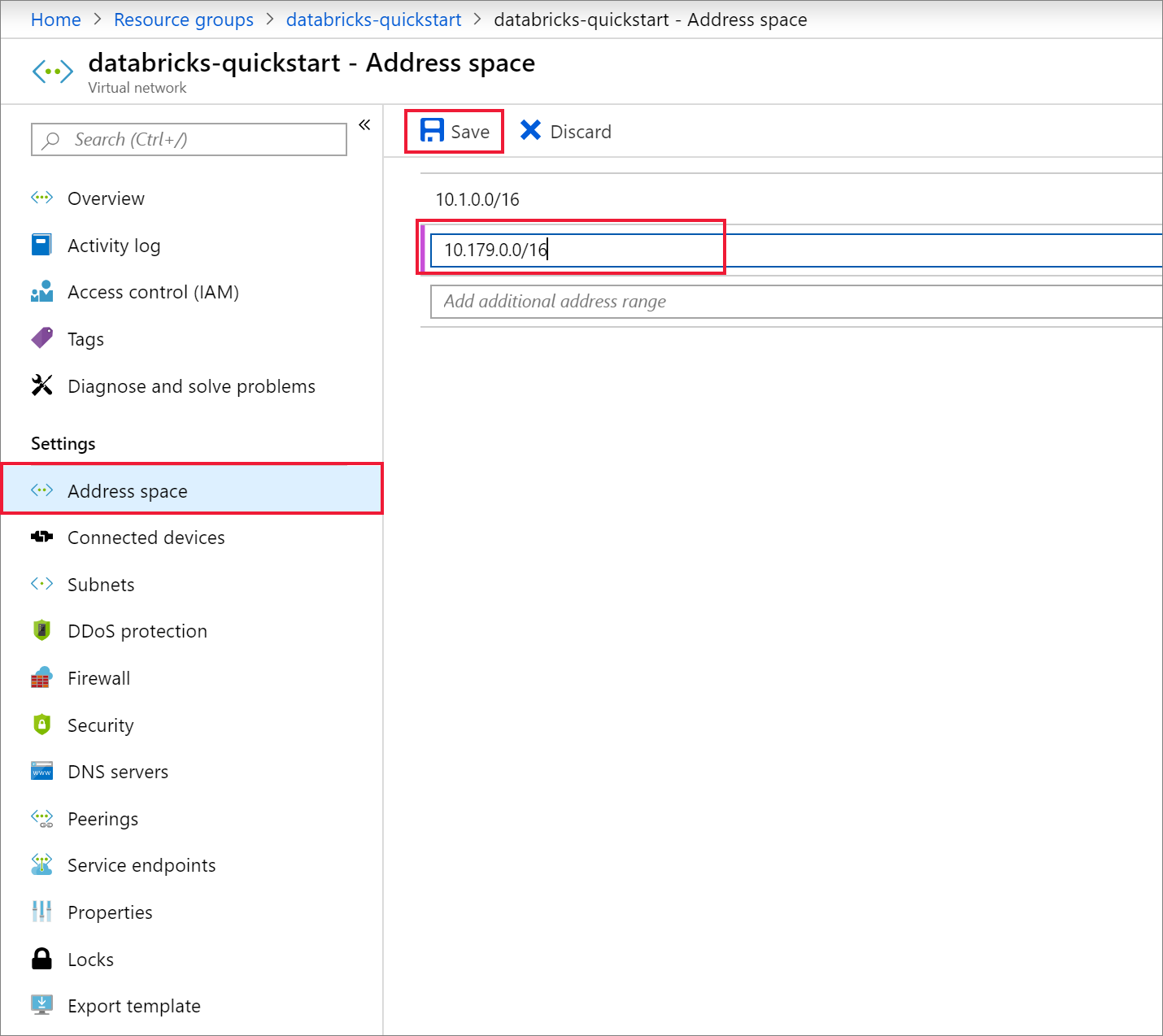
创建 Azure Databricks 工作区
在 Azure 门户菜单中,选择“创建资源”。 然后选择“分析”>“Databricks”。
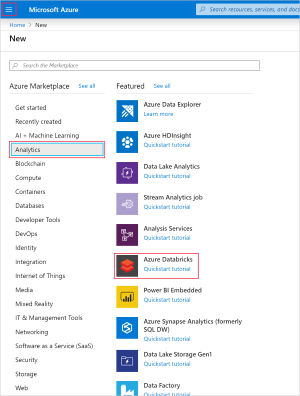
在“Azure Databricks 服务”下,应用以下设置:
设置 建议值 描述 工作区名称 Databricks 快速入门 选择 Azure Databricks 工作区的名称。 订阅 用户的订阅<> 选择要使用的 Azure 订阅。 资源组 Databricks 快速入门 选择用于虚拟网络的资源组。 位置 <选择离用户最近的区域> 使用与虚拟网络相同的位置。 定价层 选择“标准”或“高级”。 有关定价层的详细信息,请参阅 Databricks 定价页。 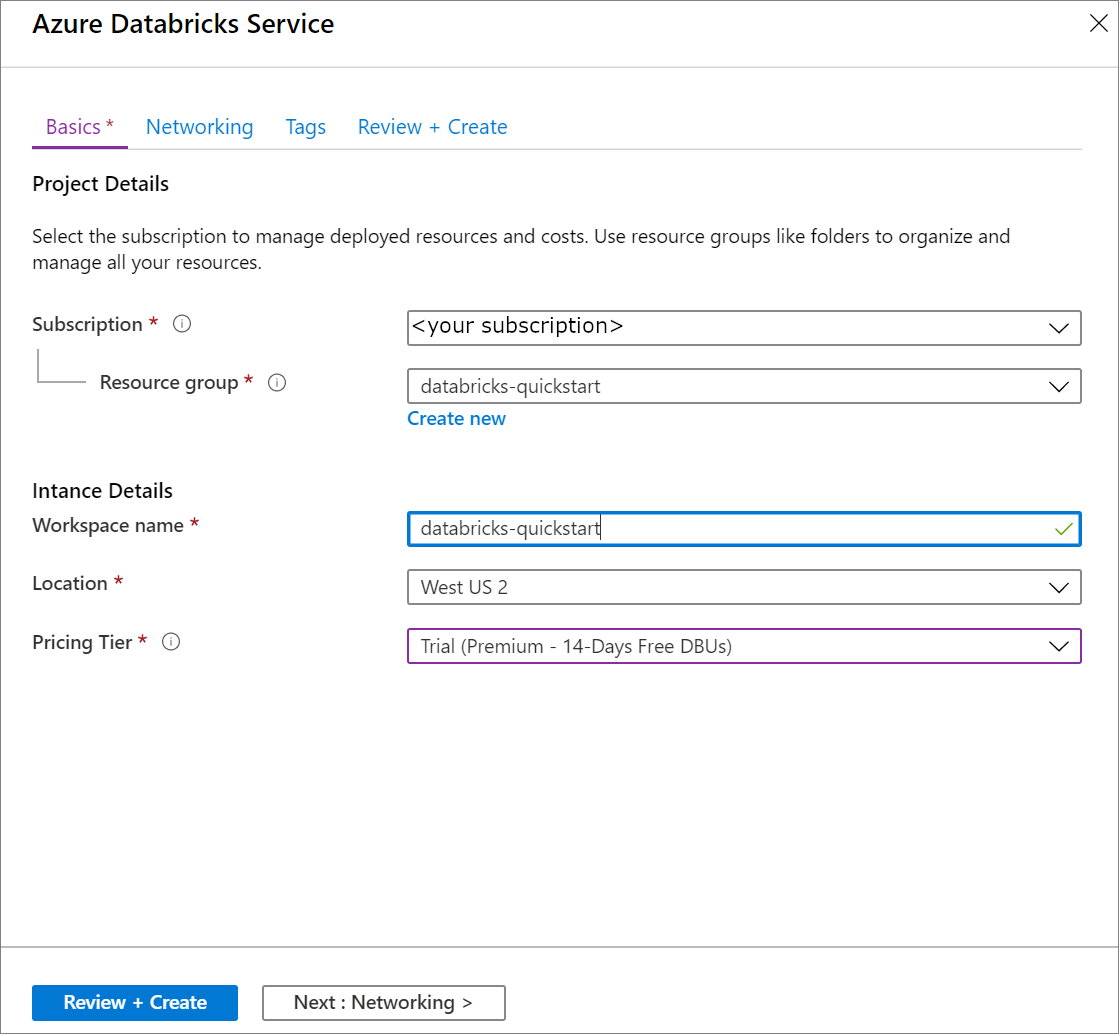
在“基本信息”页上完成输入设置后,选择“下一步: 网络 ”并应用以下设置:
设置 建议值 描述 在你的虚拟网络 (VNet) 中部署 Azure Databricks 工作区 是 通过此设置,可在你的虚拟网络中部署 Azure Databricks 工作区。 虚拟网络 Databricks 快速入门 选择你在上一部分中创建的虚拟网络。 公共子网名称 公共子网 使用默认公共子网名称。 公共子网 CIDR 范围 10.179.64.0/18 使用 /26 及以下的 CIDR 范围。 专用子网名称 私有子网 使用默认专用子网名称。 专用子网 CIDR 范围 10.179.0.0/18 使用 /26 及以下的 CIDR 范围。 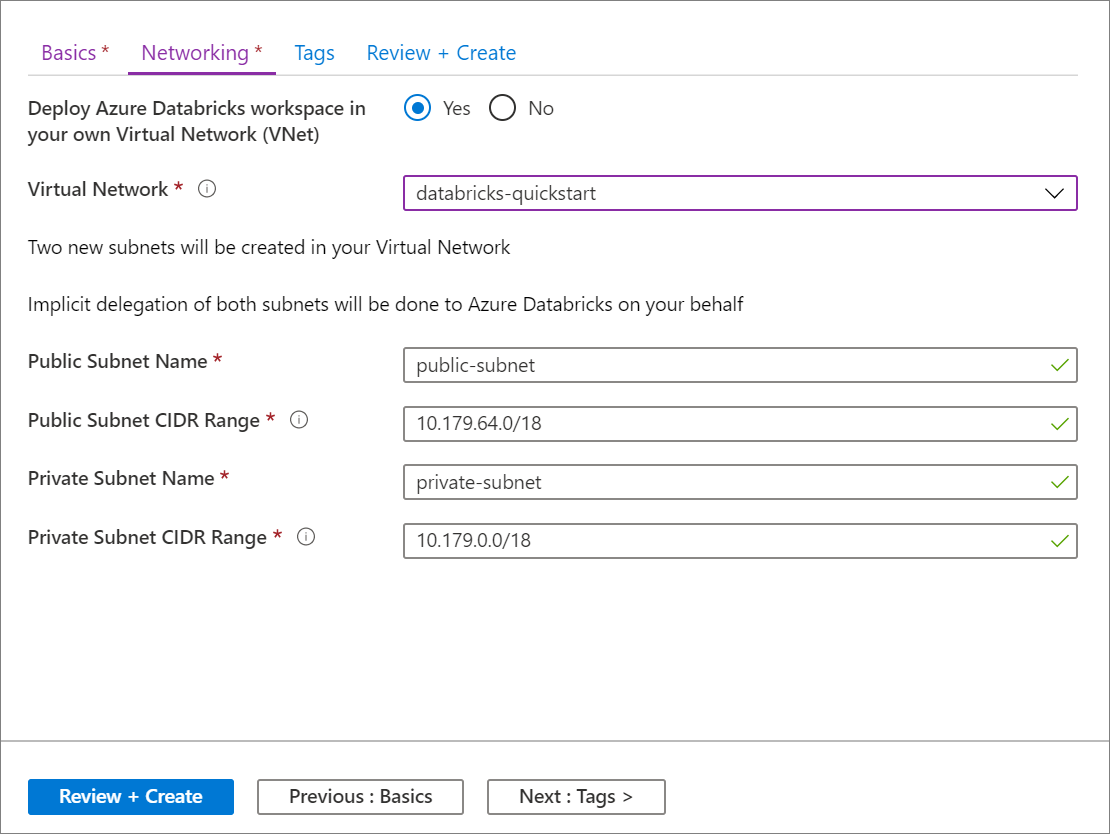
部署完成后,导航到 Azure Databricks 资源。 请注意已禁用虚拟网络对等互连。 另请注意概述页面中的资源组和托管资源组。
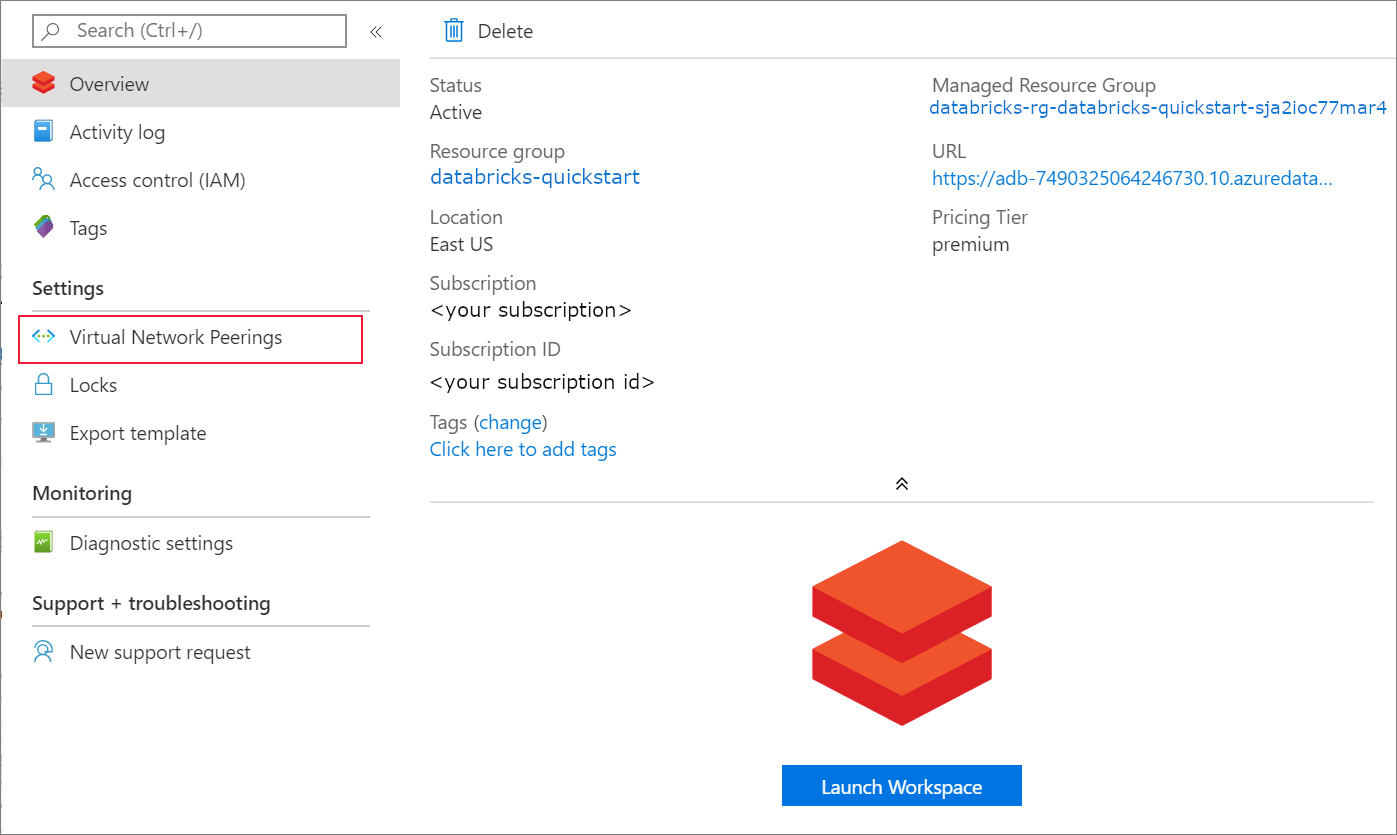
托管资源组不可修改,并且不用于创建虚拟机。 只能在由你管理的资源组中创建虚拟机。
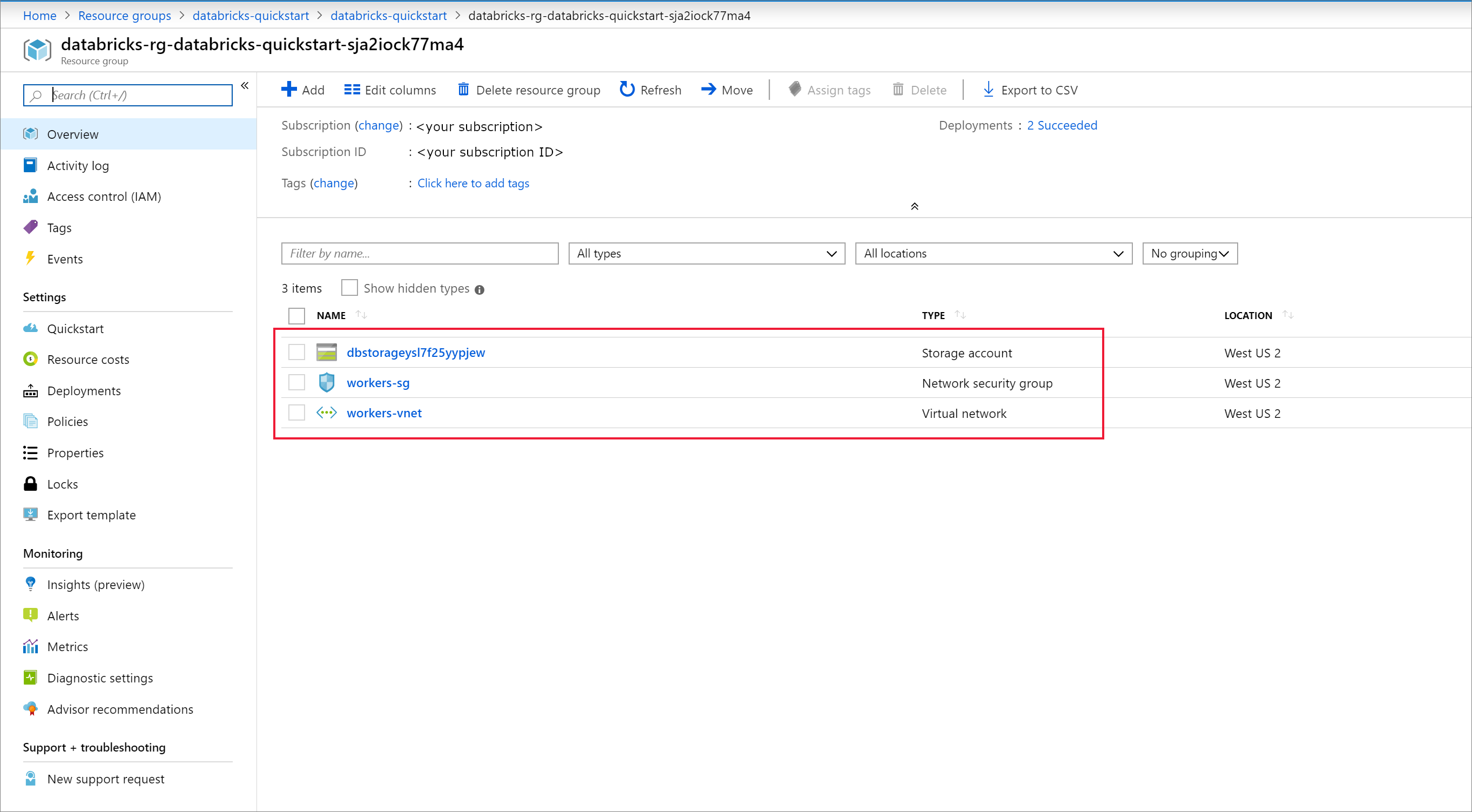
当工作区部署失败时,仍然会在失败状态下创建工作区。 删除失败的工作区,并创建一个解决部署错误的新工作区。 删除失败的工作区时,托管资源组和任何成功部署的资源也将被删除。
创建群集
注意
若要使用试用版订阅创建 Azure Databricks 群集,请在创建群集前转到个人资料,将订阅更改为“标准预付费套餐”。 有关详细信息,请参阅 Azure 试用版订阅。
返回到 Azure Databricks 服务,并在“概述”页面上选择“启动工作区”。
选择“群集”“创建群集”。 然后创建群集名称(例如 databricks-quickstart-cluster),并接受其余默认设置。 选择“创建群集”。
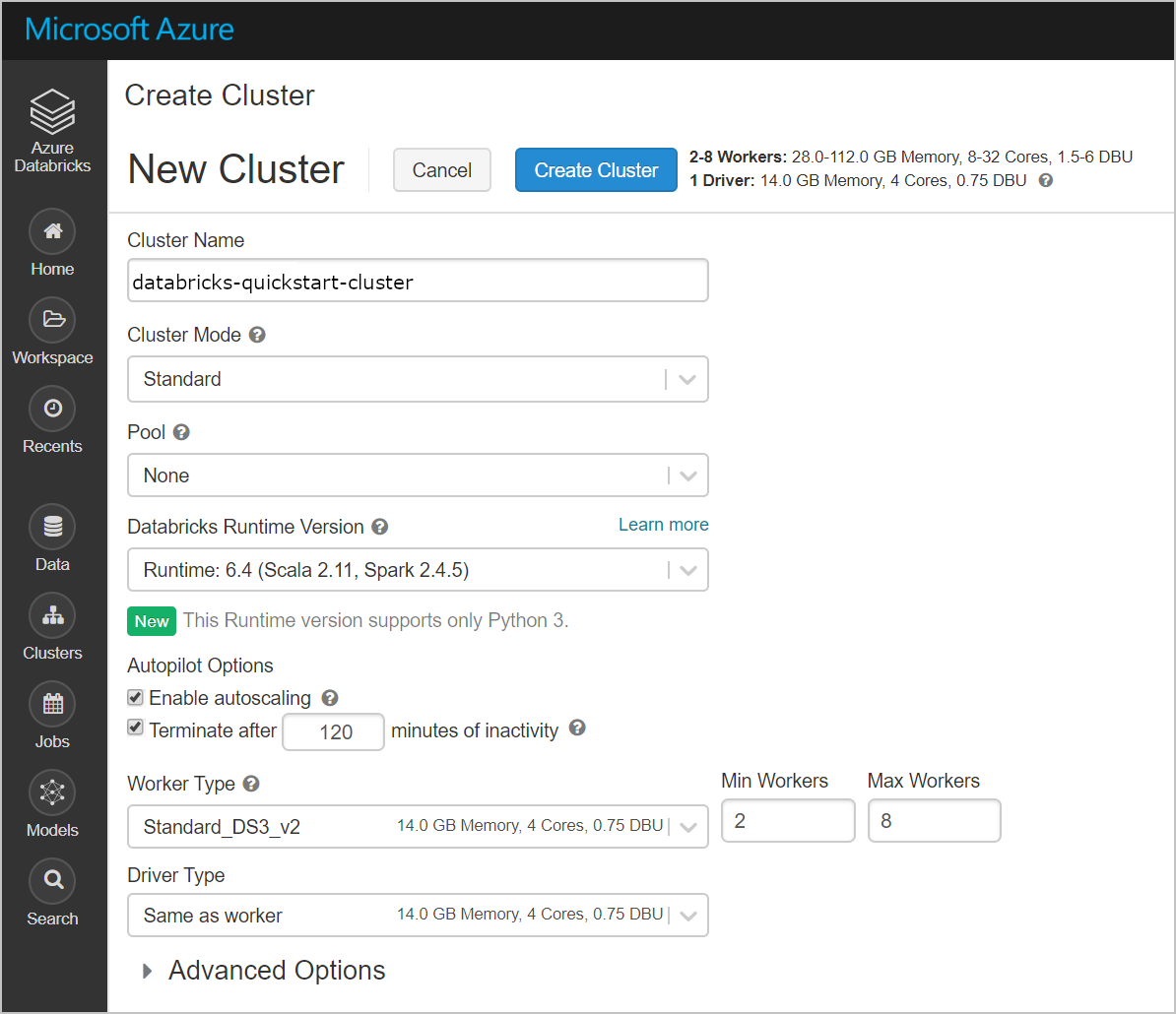
群集运行后,在 Azure 门户中返回到托管资源组。 请注意新的虚拟机、磁盘、IP 地址和网络接口。 将在具有 IP 地址的每个公共子网和专用子网中创建一个网络接口。
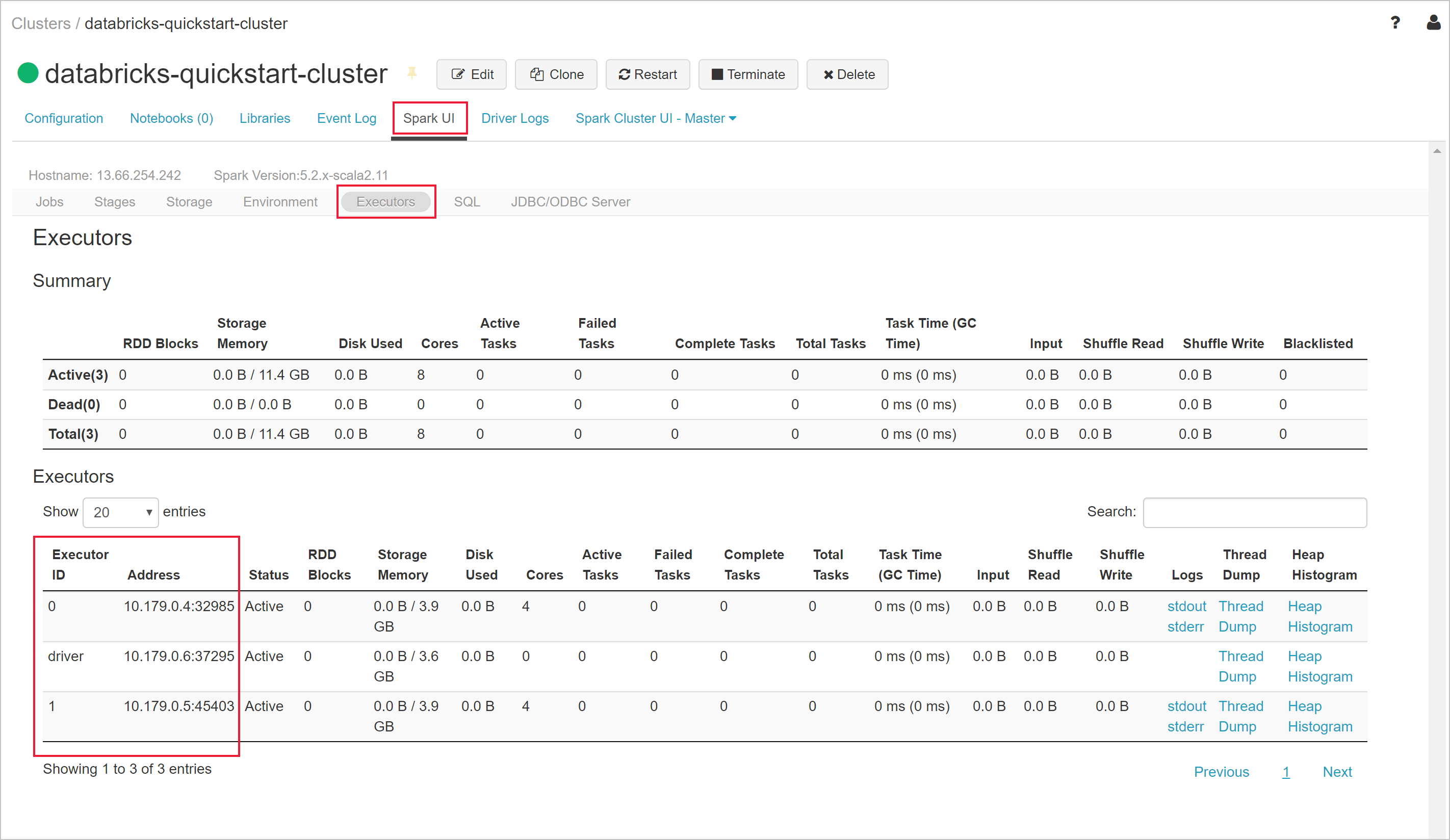
返回到 Azure Databricks 工作区,然后选择所创建的群集。 然后在“Spark UI”页面上导航到“执行程序”选项卡。 请注意,驱动程序和执行程序的地址在专用子网范围内。 在此示例中,驱动程序为 10.179.0.6,执行器为10.179.0.4 和 10.179.0.5。 你的 IP 地址可能不同。
清理资源
完成本文后,可以终止群集。 为此,请在 Azure Databricks 工作区的左窗格中选择“群集” 。 针对想要终止的群集,将光标移到“操作” 列下面的省略号上,选择“终止” 图标。 这将停止群集。
如果不手动终止群集,但在创建群集时选中了“在不活动 __ 分钟后终止”复选框,则该群集会自动停止。 在这种情况下,如果群集保持非活动状态超过指定的时间,则会自动停止。
如果不希望重复使用群集,可以删除你在 Azure 中创建的资源组。
后续步骤
在本文中,你在部署到虚拟网络的 Azure Databricks 中创建了 Spark 群集。 请继续学习下一篇文章,了解如何通过 Azure Databricks 笔记本使用 JDBC 查询虚拟网络中的 SQL Server Linux Docker 容器。