本页介绍如何配置和管理网络策略,以控制Azure Databricks中无服务器工作负荷的出站网络连接。
有关入口控件,请参阅 基于上下文的入口控件。
要求
- Azure Databricks工作区必须位于高级层。
- 管理网络策略的权限仅限于帐户管理员。
访问网络策略
要在帐户中创建、查看和更新网络策略,请执行以下操作:
- 在 account 控制台中,单击 Security。
- 单击“ 网络 ”选项卡。
- 在 “策略”下,单击 “基于上下文的入口和出口”控件。
创建网络策略
单击 创建新网络策略。
输入 策略名称。
单击 “出口 ”选项卡。
若要设置入口规则,请参阅 “设置入口规则”。
选择网络访问模式:
- 允许访问所有目的地:不受限制的出站互联网访问。 如果选择Full access,出站互联网访问将保持不受限制。
- 特定目的地的受限访问:出站访问限制到指定目的地。
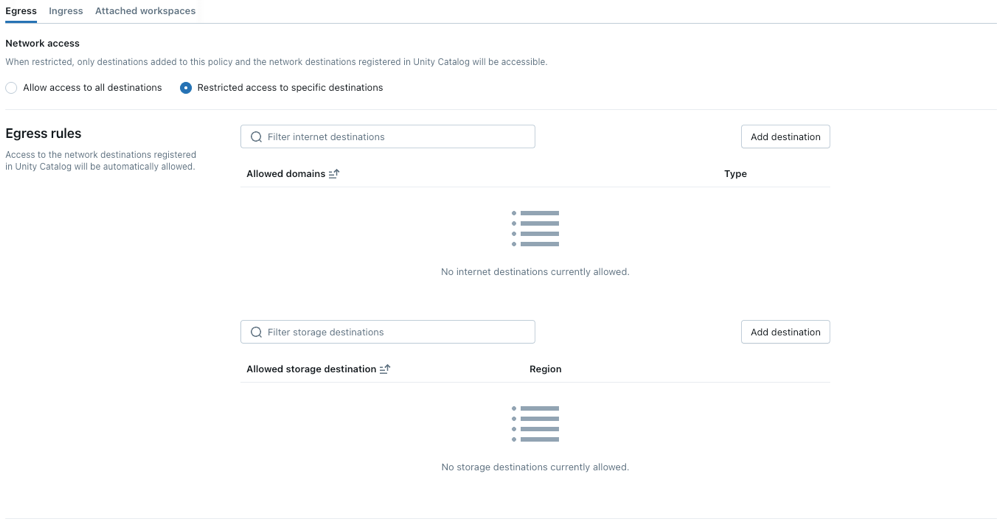
配置网络策略
以下步骤概述了受限访问模式的可选设置:
设置出口规则
在设置出口规则之前,请注意:
- 在元存储中使用 S3 存储桶时,必须使用 REST API 显式将存储桶添加到出口允许名单中,以便访问成功。
- 支持的最大目标数为 2500。
- 可以添加的存储目标数
allowed_storage_destinations限制为每个策略 100 个。 - 可以添加为允许域的 FQDN 数限制为每个策略 100 个。
- 作为专用链接负载均衡器条目添加的域在网络策略中隐式列入允许列表。 删除域或删除专用终结点时,网络策略控制可能需要长达 24 小时才能完全强制实施更改。 请参阅 配置 VNet 中资源的专用连接。
- OpenSharing 存储桶在网络策略中会被默认加入允许名单。
注释
Unity Catalog 连接的隐式加入允许列表已被弃用。 对于那些包含在弃用之前使用隐式白名单的工作区的帐户,此行为将在有限的过渡期内继续有效。
若要向无服务器计算授予访问其他域的权限,请单击已允许的域列表上方的添加目标。
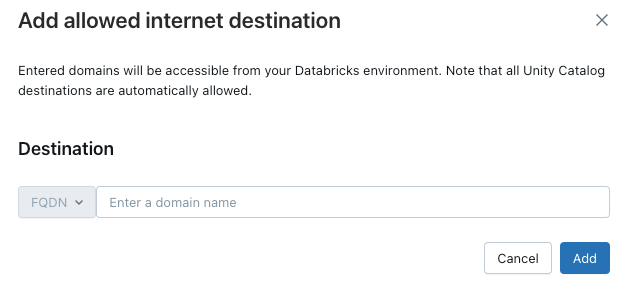
FQDN 筛选器允许访问所有共享同一 IP 地址的域名。
注释
提供预配的吞吐量终结点的模型不支持精细 FQDN 筛选。 将网络访问设置为受限时,将阻止这些终结点的所有 Internet 访问。
若要允许工作区访问其他Azure存储帐户,请单击所有存储目标列表上方的Add destination按钮。
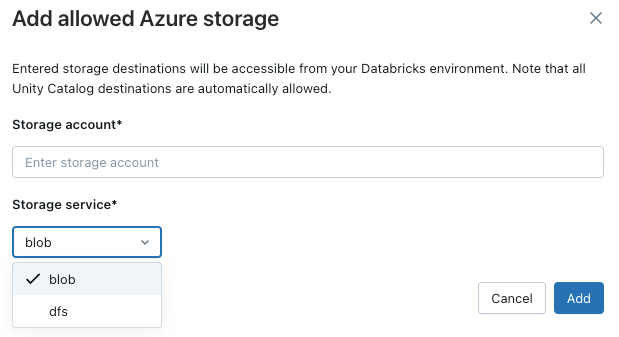
注释
默认情况下,用户代码容器(如 REPL 或 UDF)无法直接访问云存储服务。 若要启用此访问,请在策略中的 Allowed Domains 下添加 FQDN 的 storage 资源。 仅添加存储资源的基础域名可能会无意中授予该区域中所有存储资源的访问权限。
策略执行
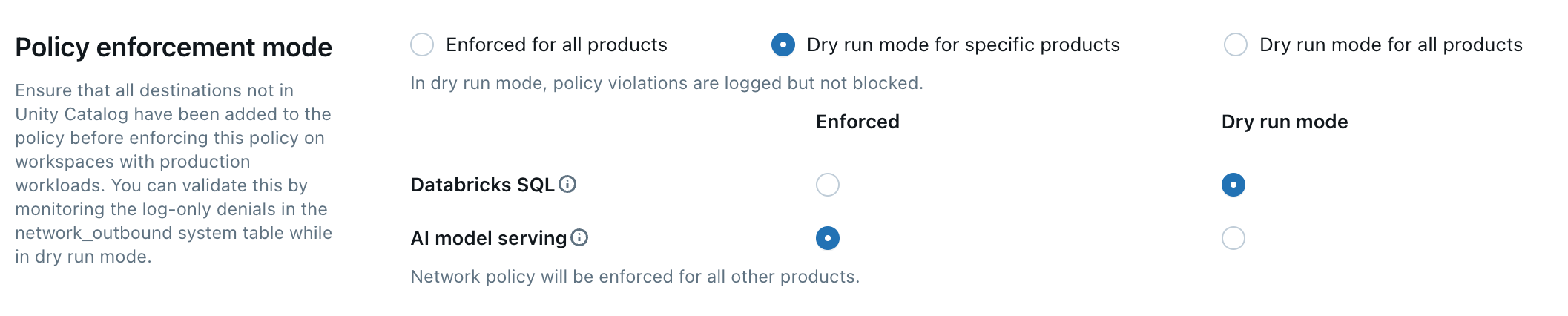
使用“干运行”模式可以测试策略配置并监控出站连接,从而不会中断对资源的访问。 启用干运行模式后,将记录违反策略但未阻止的请求。 您可以选择以下选项:
Databricks SQL:Databricks SQL 仓库在干运行模式下运行。
AI 模型服务:为终结点提供服务的模型在干运行模式下运行。
所有产品:所有Azure Databricks服务都以干运行模式运行,覆盖所有其他选择。
阻止 Internet 目标
注释
此功能以公共预览版提供,可供符合 SEG 条件的工作区使用。 对于尚不支持 SEG 的 Premium 层级工作区,仅当网络访问设置为 Full access 时,才仅在默认策略中支持被阻止的目标地址。
阻止您的无服务器工作负载访问特定的互联网目标地址。 使用被阻止的目标作为 受限访问 模式的轻量替代方法,以阻止已知错误的域,而无需切换整体强制模式。
通过 网络策略 REST API 配置被阻止的目标地址。 API 需要帐户管理员 OAuth 令牌。 帐户级 API 不支持个人访问令牌。
请参阅 OAuth 机器间身份验证。
被阻止的目标其行为如下:
- 每个条目指定一个
destination(完全限定域名,即 FQDN)和一个internet_destination_type为DNS_NAME。 - 不支持 IP 范围和存储目标。
- 无论策略的网络访问模式如何,被阻止的目标地址始终会被强制执行。
- 被阻止的目标优先于允许的目标。
- API 会拒绝以下配置:允许的目标属于被阻止目标的子域。 但是,允许采用“宽松允许、严格阻止”的模式(例如,允许
example.com并阻止api.example.com)。
即使网络访问被设置为 system.access.outbound_network,拒绝事件也会记录在 Unity Catalog 的 表中。 请参阅 检查拒绝日志。
要阻止互联网目标:
检索网络策略。 运行下面的命令:
将
<ACCOUNT_HOST>替换为accounts.databricks.azure.cn。curl --location --request GET \ 'https://<ACCOUNT_HOST>/api/2.0/accounts/<ACCOUNT_ID>/network-policies/<NETWORK_POLICY_ID>' \ --header 'Authorization: Bearer <OAUTH_TOKEN>'将响应正文另存为
network-policy.json。编辑
network-policy.json,以在blocked_internet_destinations下添加egress.network_access。 以下示例在 完全访问 模式下阻止单个域:{ "network_policy_id": "my-policy", "account_id": "...", "egress": { "network_access": { "restriction_mode": "FULL_ACCESS", "blocked_internet_destinations": [ { "destination": "malicious-domain.example.com", "internet_destination_type": "DNS_NAME" } ] } } }使用以下命令,将更新后的策略连同
PUT请求提交到同一端点。PUT正文必须包含完整的网络策略。 任何未填写的字段都将被清除。curl --location --request PUT \ 'https://<ACCOUNT_HOST>/api/2.0/accounts/<ACCOUNT_ID>/network-policies/<NETWORK_POLICY_ID>' \ --header 'Content-Type: application/json' \ --header 'Authorization: Bearer <OAUTH_TOKEN>' \ --data @network-policy.json
还可以使用 databricks account network-policies update-network-policy-rpc Databricks CLI 管理网络策略,或者使用 Terraform 的 databricks_account_network_policy 资源进行管理。 请参阅 account network-policies 命令组。
更新默认策略
每个Azure Databricks帐户都包含一个 default 策略。 默认策略 与没有显式网络策略分配的所有工作区(包括新创建的工作区)相关联。 可以修改此策略,但无法将其删除。
默认策略仅适用于至少具有高级层的工作区。
将网络策略关联到工作区
如果已使用其他配置更新了默认策略,那么系统会将这些策略自动应用于没有现有网络策略的工作区。
你的工作区必须位于高级层中。
要将工作区与其他策略相关联,请执行以下操作:
选择工作区。
在 网络策略中,单击 更新网络策略。
从列表中选择所需的网络策略。
单击 “应用策略”。
应用网络策略更改
大多数网络配置更新会在 10 分钟内自动传播到无服务器计算服务。 这包括:
添加新的 Unity 目录外部位置或连接。
将工作区附加到不同的元存储。
更改允许的存储或互联网目标。
注释
如果修改 Internet access或干运行模式设置,则必须重启计算。
重启或重新部署无服务器工作负荷
只有在切换互联网接入模式或更新试运行模式时才需要更新。
若要确定适当的重启过程,请参阅以下按产品列出的列表:
Databricks ML 服务:重新部署 ML 服务终结点。
Pipelines:停止并重启正在运行的 Lakeflow Spark 声明性数据管道。 请参阅 运行管道更新。
无服务器 SQL 仓库:停止并重启 SQL 仓库。 请参阅管理 SQL 仓库。
Lakeflow 作业:触发新作业运行或重启现有作业运行时,将自动应用网络策略更改。
Notebooks:
- 如果笔记本不与 Spark 交互,可以终止,然后重新附加无服务器计算以刷新网络策略。
- 如果笔记本与 Spark 交互,则无服务器资源会刷新并自动检测更改。 大多数更改将在 10 分钟内刷新,但切换互联网接入模式、更新模拟运算模式或更改具有不同强制类型的附加的策略之间可能需要长达 24 小时。 若要加快对这些特定类型的更改进行刷新,请关闭所有关联的笔记本和作业。
声明性自动化捆绑 UI 依赖项
在使用受限访问模式和无服务器网络流量控制时,声明式自动化包中的UI功能需要访问特定的外部域。 如果出站访问受到严格限制,在使用声明式自动化捆绑包时,用户可能会在工作区界面中看到错误。
为了使声明性自动化捆绑的 UI 功能能在受限网络策略下正常运作,请将这些域添加到策略中的允许域:
- github.com
- objects.githubusercontent.com
- release-assets.githubusercontent.com
- checkpoint-api.hashicorp.com
- releases.hashicorp.com
- registry.terraform.io
验证网络策略强制实施
可以通过尝试从不同的无服务器工作负载访问受限资源来验证网络策略是否得到正确应用。 验证过程因无服务器产品而异。
Lakeflow Spark 声明性流水线
- 创建Python笔记本。 可以使用 Lakeflow Spark 声明性Pipelines维基百科 python 教程中提供的示例笔记本。
- 创建管道:
- 在您的工作区中,单击
 ,在侧栏中选择作业和管道。
,在侧栏中选择作业和管道。 - 单击 创建,然后 ETL 管道。
- 使用以下设置配置管道:
- 管道模式:无服务器
- 源代码:选择创建的笔记本。
- 存储选项:Unity Catalog. 选择所需的目录和架构。
- 单击 “创建” 。
- 在您的工作区中,单击
- 运行管道。
- 在管道页中,单击开始。
- 等待管道完成。
- 验证结果
- 受信任的目标:管道成功运行,并将数据写入目标。
- 不受信任的目标:管道失败并出现错误,指示网络访问被阻止。
Databricks SQL
使用 Databricks SQL 进行验证
创建 SQL 仓库。
在 SQL 编辑器中运行测试查询,该查询尝试access由网络策略控制的资源。
验证结果:
- 受信任的目标:查询成功。
- 不受信任的目标:查询因网络访问错误而失败。
若要使用标准Python库从 UDF 连接到网络,请运行以下 UDF 定义:
CREATE OR REPLACE TEMPORARY FUNCTION ping_qq(value DOUBLE) RETURNS STRING LANGUAGE python AS $$ import requests url = "https://www.qq.com" response = requests.get(url, timeout=5) if response.status_code == 200: return "UDF has network!" else: return "UDF has no network!" $$;
模型服务
使用模型服务进行验证
在您开始之前
当创建模型服务端点时,会生成容器映像用于提供模型服务。 在此构建阶段执行网络策略。 将模型服务用于网络策略时,请考虑以下事项:
-
Dependency access:任何外部构建依赖项,例如来自 PyPI 和 conda-forge 的 Python 包、基础容器镜像,或在模型环境或 Docker 上下文中指定的外部 URL 的文件,都必须符合网络策略的许可。
- 例如,如果模型需要特定版本的 scikit-learn,并且需要在构建期间下载,网络策略必须允许访问托管该包的存储库。
- 生成失败: 如果网络策略阻止访问必要的依赖项,则提供容器生成的模型将失败。 这可以防止服务终结点成功部署,并可能导致它无法正确存储或正常运行。 请参阅 检查拒绝日志。
-
故障排除拒绝:生成阶段的网络访问拒绝都被记录。 这些日志的
network_source_type字段具有值ML Build。 此信息对于确定必须添加到网络策略中的具体阻止资源以便让构建成功完成至关重要。
验证运行时网络访问
以下步骤演示如何在运行时验证已部署模型的网络策略,尤其是模型在推理期间尝试访问外部资源时的策略。 这假定已成功生成提供容器的模型,这意味着网络策略中允许任何生成时依赖项。
创建测试模型
在Python笔记本中,创建一个模型,该模型尝试在推理时访问公共 Internet 资源,例如下载文件或发出 API 请求。
运行此笔记本以在测试工作区中生成模型。 例如:
import mlflow import mlflow.pyfunc import mlflow.sklearn import requests class DummyModel(mlflow.pyfunc.PythonModel): def load_context(self, context): # This method is called when the model is loaded by the serving environment. # No network access here in this example, but could be a place for it. pass def predict(self, _, model_input): # This method is called at inference time. first_row = model_input.iloc[0] try: # Attempting network access during prediction response = requests.get(first_row['host']) except requests.exceptions.RequestException as e: # Return the error details as text return f"Error: An error occurred - {e}" return [response.status_code] with mlflow.start_run(run_name='internet-access-model'): wrappedModel = DummyModel() # When this model is deployed to a serving endpoint, # the environment will be built. If this environment # itself (e.g., specified conda_env or python_env) # requires packages from the internet, the build-time serverless network policy applies. mlflow.pyfunc.log_model( artifact_path="internet_access_ml_model", python_model=wrappedModel, registered_model_name="internet-http-access" )
创建服务终结点
- 在工作区导航中,选择 “AI/ML”。
- 单击服务选项卡。
- 单击创建服务终结点。
- 使用以下设置配置终结点:
- 服务终结点名称:提供描述性名称。
- 实体详细信息:选择模型注册表模型。
-
Model:选择在上一步中创建的模型(
internet-http-access)。
- 单击“确认”。
在此阶段,模型服务容器的构建过程开始。
ML Build的网络策略将被强制实施。 如果生成因依赖项的网络访问被阻止而失败,则端点将无法就绪。 - 等待服务终结点达到就绪状态。 如果它无法准备就绪,请检查拒绝日志中是否有
network_source_type: ML Build条目。 请参阅 检查拒绝日志。
查询终结点。
使用服务终结点页中的 “查询终结点 ”选项发送测试请求。
{ "dataframe_records": [{ "host": "[https://www.qq.com](https://www.qq.com)" }] }
验证运行时访问结果:
- 在运行时启用的 Internet access:查询成功并返回状态代码,如
200。 -
运行时互联网访问受到限制:查询因网络访问错误而失败,例如模型代码中来自
try-except块的错误消息,指示连接超时或主机解析失败。
- 在运行时启用的 Internet access:查询成功并返回状态代码,如
更新网络策略
可以在创建网络策略后随时更新它。 要更新网络策略,请执行以下操作:
- 在帐户控制台中网络策略的详细信息页上,修改策略:
- 更改网络访问模式。
- 为特定服务启用或禁用干运行模式。
- 添加或删除 FQDN 或存储位置。
- 单击“更新” 。
- 请参阅 应用网络策略更改,以验证更新是否应用于现有工作负荷。
检查拒绝日志
拒绝日志存储在 Unity 目录中的 system.access.outbound_network 表中。 这些日志跟踪出站网络请求被拒绝的时间。 若要访问拒绝日志,请验证是否已在 Unity Catalog 元存储上启用了访问模式。 请参阅启用系统表。
使用如下所示的 SQL 查询来查看拒绝事件。 如果启用了干运行日志,查询将返回拒绝日志和干运行日志,可以使用 access_type 列进行区分。 拒绝日志显示 DROP 值,而试运行日志显示 DRY_RUN_DENIAL。
以下示例检索过去 2 小时中的日志:
SELECT *
FROM system.access.outbound_network
WHERE event_time >= CURRENT_TIMESTAMP() - INTERVAL 2 HOUR
ORDER BY event_time DESC;
对于试运行模式和外部生成式 AI 模型,以下情况属实:
- 如果网络策略已阻止access必要的依赖项,请先检查
system.access.outbound_network中的拒绝日志。 此外,为容器提供服务的模型生成日志可能会提供有关哪些域被阻止的有用信息。 - 如果提供容器生成的模型失败,请检查
system.access.outbound_network中的拒绝日志以确定哪些域被阻止。 - 通过模型服务对外部模型访问的强制实施即使在干运行模式下也是如此。
注释
access时间与出现拒绝日志的时间之间可能存在可感知的延迟。
局限性
Artifact 上传大小:将 MLflow 的内部 Databricks 文件系统与
dbfs:/databricks/mlflow-tracking/<experiment_id>/<run_id>/artifacts/<artifactPath>格式配合使用时,项目上传限制为 5GB,适用于log_artifact、log_artifacts和log_modelAPI。短生存期垃圾回收(GC)工作负载的拒绝日志传送:对于持续时间小于 120 秒的短生存期 GC 工作负载,由于日志记录的延迟,拒绝日志可能无法在节点终止之前被传送。 尽管仍强制执行访问,但可能缺少相应的日志条目。
Databricks SQL 用户定义函数(UDF) 的网络连接:若要在 Databricks SQL 中启用网络访问,请联系 Databricks 帐户团队。
Pipeline eventhook 日志记录:不会记录面向其他工作区的 Lakeflow Spark 声明性Pipelines事件hook。 这适用于为跨区域工作区及同一区域内工作区配置的 Eventhook。
Unity 目录工作区绑定更改:对 Unity 目录工作区绑定的更改可能需要长达 24 小时才能生效。 若要加快此过程,请将存储桶添加到网络策略。 请参阅 工作区目录绑定。
跨云的网络访问:目前基于无服务器的网络策略不允许 Azure 工作区使用作为 Unity Catalog 外部存储位置的 S3 存储桶。
后续步骤
- 配置基于上下文的入口控制:根据身份、请求类型和网络来源定义入站访问策略,以保护工作区的安全访问。 请参阅 基于上下文的入口控件。
- 管理专用终结点规则:通过定义允许或拒绝连接以增强安全性的特定规则来控制传入和传出专用终结点的网络流量。 请参阅管理专用终结点规则。
- 为无服务器计算访问配置防火墙:实现防火墙,以限制和保护无服务器计算环境的入站和出站网络连接。 请参阅为 Azure 资源配置 Azure 网络安全边界 (NSP)。
- 了解数据传输和连接成本:了解实现无服务器工作负荷的网络安全控制和专用连接时产生的成本影响。 请参阅 了解 Databricks 网络成本。