生产中的结构化流式处理
可以方便地将笔记本附加到群集并以交互方式运行流式处理查询。 但是,在生产环境中运行它们时,可能需要更高的可靠性和正常运行时间保证。 本文介绍了如何使用 Azure Databricks 作业使流式处理应用程序更具容错能力。
定义流式数据处理的计时
使用触发器定义流式数据处理的计时。 如果指定的 trigger 间隔太小(小于数十秒),则系统可能会执行不必要的检查来查看新数据是否已到达。 建议指定一个定制的 trigger 以最大程度地降低成本,这是最佳做法。
在发生查询失败后进行恢复
生产级流式处理应用程序必须有可靠的故障处理能力。 在结构化流式处理中,如果为流式处理查询启用检查点,则可以在失败后重启查询,重启的查询将从失败查询停止的位置继续,同时确保容错并保证数据一致性。 因此,弱要使查询具有容错性,你必须启用查询检查点并将 Databricks 作业配置为在失败后自动重启查询。
启用检查点
若要启用检查点,请在启动查询之前将选项 checkpointLocation 设置为 DBFS 或云存储路径。 例如: 。
streamingDataFrame.writeStream
.format("parquet")
.option("path", "dbfs://outputPath/")
.option("checkpointLocation", "dbfs://checkpointPath")
.start()
此检查点位置保留可用于唯一标识查询的所有基本信息。 因此,每个查询都必须有不同的检查点位置,并且多个查询不应有相同的位置。 有关更多详细信息,请参阅结构化流式处理编程指南。
注意
尽管 checkpointLocation 是大多数类型的输出接收器的必需选项,但当你未提供 checkpointLocation 时,某些接收器(例如内存接收器)可能会在 DBFS 上自动生成一个临时检查点位置。 临时检查点位置不能确保任何容错,也不能保证数据一致性,并且可能无法进行正常的清理。
建议始终指定 选项,这是最佳做法。
将作业配置为在失败时重启流式处理查询
你可以使用包含流式处理查询的笔记本或 JAR 创建 Azure Databricks 作业,并将其配置为:
- 始终使用新群集。
- 始终在失败时重试。
作业与结构化流式处理 API 紧密集成,并且可以监视运行中处于活动状态的所有流式处理查询。 此配置可确保如果查询的任何部分失败,作业会自动终止此运行(以及所有其他查询),并在新群集中启动新的运行。 新运行会重新执行笔记本或 JAR 代码,并再次重启所有查询。 这是确保返回到良好状态的最安全的方法。
警告
长时间运行的作业不支持笔记本工作流。 因此,我们不建议在流式处理作业中使用笔记本工作流。
注意
- 任何活动的流式处理查询中的失败都会导致活动的运行失败,并终止所有其他流式处理查询。
- 你无需在笔记本的末尾使用
streamingQuery.awaitTermination()或spark.streams.awaitAnyTermination()。 当流式处理查询处于活动状态时,作业会自动防止运行完成。
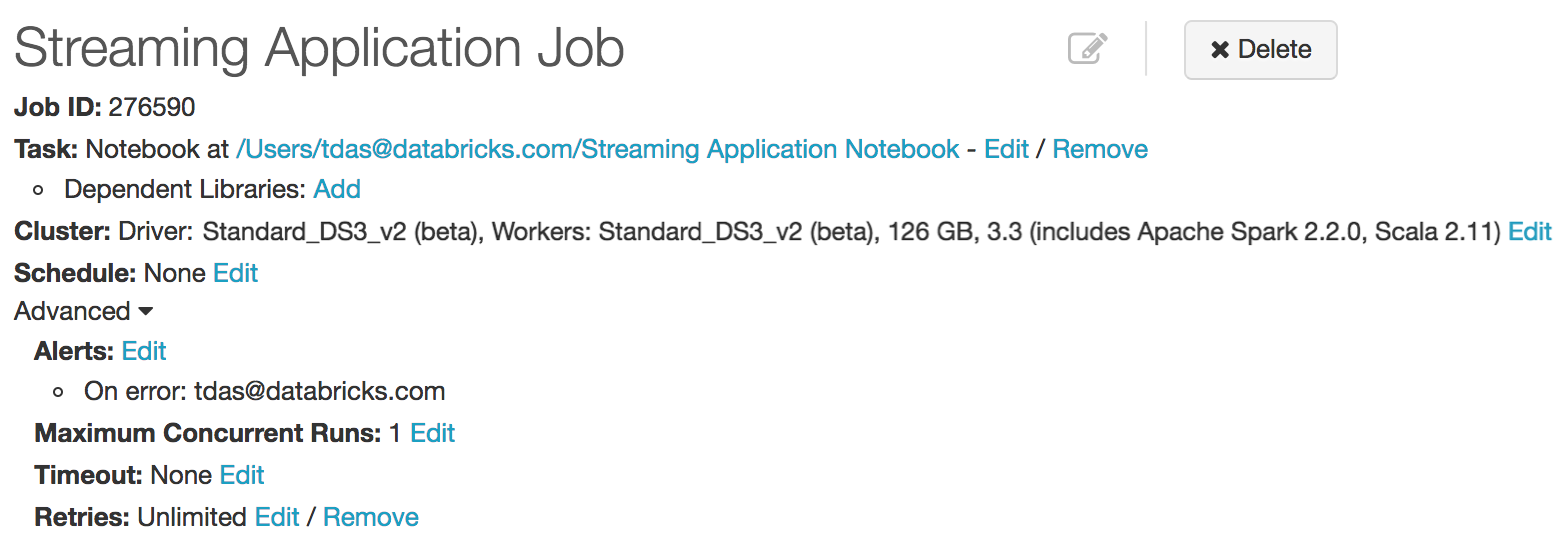
下面是建议的作业配置的详细信息。
- 群集:将此项始终设置为使用新群集并使用最新的 Spark 版本(或至少使用版本 2.1)。 在查询和 Spark 版本升级之后,在 Spark 2.1 及更高版本中启动的查询是可恢复的查询。
- 警报:如果希望在失败时收到电子邮件通知,请设置此项。
- 计划:不设置计划。
- 超时:请勿设置超时。流式处理查询会运行无限长的时间。
- 最大并发运行数:设置为 1。 每个查询只能有一个并发的活动实例。
- 重试:设置为“不受限制”。
请参阅作业来了解这些配置。 下面是良好作业配置的屏幕截图。
在流式处理查询发生更改后恢复
在从同一检查点位置进行的各次重启之间,对于流式处理查询中允许哪些更改存在限制。 下面的几种类型的更改是不允许的,或者是更改效果未明确的。 对于它们:
- “允许”一词意味着你可以执行指定的更改,但其效果的语义是否明确取决于查询和更改。
- “不允许”一词意味着不应执行指定的更改,因为重启的查询可能会失败并出现不可预知的错误。
sdf表示通过sparkSession.readStream生成的流式处理数据帧/数据集。
更改的类型
- 输入源的数量或类型(即不同源)的更改:这是不允许的。
- 输入源的参数中的更改:是否允许这样做,以及更改的语义是否明确取决于源和查询。 以下是一些示例。
允许添加、删除和修改速率限制:
spark.readStream.format("kafka").option("subscribe", "article")to
spark.readStream.format("kafka").option("subscribe", "article").option("maxOffsetsPerTrigger", ...)通常不允许更改已订阅的文章和文件,因为结果不可预知:不允许将
spark.readStream.format("kafka").option("subscribe", "article")更改为spark.readStream.format("kafka").option("subscribe", "newarticle")
- 输出接收器类型的更改:允许在几个特定的接收器组合之间进行更改。 这需要根据具体情况进行验证。 以下是一些示例。
- 允许从文件接收器更改为 Kafka 接收器。 Kafka 只会看到新数据。
- 不允许从 Kafka 接收器更改为文件接收器。
- 允许从 Kafka 接收器更改为 foreach,反之亦然。
- 输出接收器的参数中的更改:是否允许这样做,以及更改的语义是否明确取决于接收器和查询。 以下是一些示例。
- 不允许更改文件接收器的输出目录:不允许从
sdf.writeStream.format("parquet").option("path", "/somePath")更改为sdf.writeStream.format("parquet").option("path", "/anotherPath") - 允许更改输出项目:允许从
sdf.writeStream.format("kafka").option("article", "somearticle")更改为sdf.writeStream.format("kafka").option("path", "anotherarticle") - 允许更改用户定义的 foreach 接收器(即
ForeachWriter代码),但更改的语义取决于代码。
- 不允许更改文件接收器的输出目录:不允许从
- 投影/筛选器/映射类操作中的更改:允许某些案例。 例如:
- 允许添加/删除筛选器:允许将
sdf.selectExpr("a")修改为sdf.where(...).selectExpr("a").filter(...)。 - 允许对具有相同输出架构的投影进行更改:允许将
sdf.selectExpr("stringColumn AS json").writeStream更改为sdf.select(to_json(...).as("json")).writeStream。 - 具有不同输出架构的投影中的更改是有条件允许的:只有当输出接收器允许架构从
"a"更改为"b"时,才允许从sdf.selectExpr("a").writeStream到sdf.selectExpr("b").writeStream的更改。
- 允许添加/删除筛选器:允许将
- 有状态操作的更改:流式处理查询中的某些操作需要保留状态数据才能持续更新结果。 结构化流式处理自动为容错存储(例如,DBFS、Azure Blob 存储)的状态数据设置检查点并在重启后对其进行还原。 但是,这假设状态数据的架构在重启后保持不变。 这意味着,在两次重启之间不允许对流式处理查询的有状态操作进行任何更改(即,添加、删除或架构修改)。 下面列出了不应在两次重启之间更改其架构以确保状态恢复的有状态操作:
- 流式处理聚合:例如,。 不允许对分组键或聚合的数量或类型进行任何更改。
- 流式处理去重:例如,。 不允许对分组键或聚合的数量或类型进行任何更改。
- 流间联接:例如 (即,两个输入都是通过
sparkSession.readStream生成的)。 不允许对架构或同等联接列进行更改。 不允许对联接类型(外部或内部)进行更改。 联接条件中的其他更改被视为错误定义。 - 任意监控状态的操作:例如,
sdf.groupByKey(...).mapGroupsWithState(...)或sdf.groupByKey(...).flatMapGroupsWithState(...)。 不允许对用户定义状态的架构和超时类型进行任何更改。 允许在用户定义的状态映射函数中进行任何更改,但更改的语义效果取决于用户定义的逻辑。 如果你确实想要支持状态架构更改,则可以使用支持架构迁移的编码/解码方案,将复杂的状态数据结构显式编码/解码为字节。 例如,如果你将状态另存为 Avro 编码的字节,则可以在两次查询重启之间自由更改 Avro 状态架构,因为二进制状态始终会成功还原。
监视流式处理查询
可以通过 Spark UI 中的“流式处理”选项卡监视流式处理应用程序。使用 df.writeStream.queryName(<query_name>) 为流提供查询名称,可以轻松区分哪些指标属于 Spark UI 中的哪个流。
可以使用 Apache Spark 的“流式处理查询侦听器”界面将流式处理指标推送到外部服务,以实现警报或仪表板用例。 在 Databricks Runtime 11.0 及更高版本中,流式处理查询侦听器在 Python 和 Scala 中可用:
Scala
import org.apache.spark.sql.streaming.StreamingQueryListener
import org.apache.spark.sql.streaming.StreamingQueryListener._
val myListener = new StreamingQueryListener {
/**
* Called when a query is started.
* @note This is called synchronously with
* [[org.apache.spark.sql.streaming.DataStreamWriter `DataStreamWriter.start()`]],
* that is, `onQueryStart` will be called on all listeners before
* `DataStreamWriter.start()` returns the corresponding [[StreamingQuery]].
* Do not block in this method as it will block your query.
*/
def onQueryStarted(event: QueryStartedEvent): Unit = {}
/**
* Called when there is some status update (ingestion rate updated, etc.)
*
* @note This method is asynchronous. The status in [[StreamingQuery]] will always be
* latest no matter when this method is called. Therefore, the status of [[StreamingQuery]]
* may be changed before/when you process the event. For example, you may find [[StreamingQuery]]
* is terminated when you are processing `QueryProgressEvent`.
*/
def onQueryProgress(event: QueryProgressEvent): Unit = {}
/**
* Called when a query is stopped, with or without error.
*/
def onQueryTerminated(event: QueryTerminatedEvent): Unit = {}
}
Python
class MyListener(StreamingQueryListener):
def onQueryStarted(self, event):
"""
Called when a query is started.
Parameters
----------
event: :class:`pyspark.sql.streaming.listener.QueryStartedEvent`
The properties are available as the same as Scala API.
Notes
-----
This is called synchronously with
meth:`pyspark.sql.streaming.DataStreamWriter.start`,
that is, ``onQueryStart`` will be called on all listeners before
``DataStreamWriter.start()`` returns the corresponding
:class:`pyspark.sql.streaming.StreamingQuery`.
Do not block in this method as it will block your query.
"""
pass
def onQueryProgress(self, event):
"""
Called when there is some status update (ingestion rate updated, etc.)
Parameters
----------
event: :class:`pyspark.sql.streaming.listener.QueryProgressEvent`
The properties are available as the same as Scala API.
Notes
-----
This method is asynchronous. The status in
:class:`pyspark.sql.streaming.StreamingQuery` will always be
latest no matter when this method is called. Therefore, the status
of :class:`pyspark.sql.streaming.StreamingQuery`.
may be changed before/when you process the event.
For example, you may find :class:`StreamingQuery`
is terminated when you are processing `QueryProgressEvent`.
"""
pass
def onQueryTerminated(self, event):
"""
Called when a query is stopped, with or without error.
Parameters
----------
event: :class:`pyspark.sql.streaming.listener.QueryTerminatedEvent`
The properties are available as the same as Scala API.
"""
pass
my_listener = MyListener()
观察方法
可观察指标是可以在查询(数据帧)中定义的命名任意聚合函数。 在数据帧的执行达到完成点(即,完成批处理查询或达到流式处理循环)后,会发出一个命名事件,其中包含自上一个完成点以来处理的数据的指标。
可以通过将侦听器附加到 Spark 会话来观察这些指标。 侦听器取决于执行模式:
批处理模式:使用
QueryExecutionListener。查询完成时调用
QueryExecutionListener。 使用QueryExecution.observedMetrics映射访问指标。流式处理或微批处理:使用
StreamingQueryListener。流式处理查询完成某个循环时调用
StreamingQueryListener。 使用StreamingQueryProgress.observedMetrics映射访问指标。 Azure Databricks 不支持连续执行流式处理。
例如:
Scala
// Observe row count (rc) and error row count (erc) in the streaming Dataset
val observed_ds = ds.observe("my_event", count(lit(1)).as("rc"), count($"error").as("erc"))
observed_ds.writeStream.format("...").start()
// Monitor the metrics using a listener
spark.streams.addListener(new StreamingQueryListener() {
override def onQueryProgress(event: QueryProgressEvent): Unit = {
event.progress.observedMetrics.get("my_event").foreach { row =>
// Trigger if the number of errors exceeds 5 percent
val num_rows = row.getAs[Long]("rc")
val num_error_rows = row.getAs[Long]("erc")
val ratio = num_error_rows.toDouble / num_rows
if (ratio > 0.05) {
// Trigger alert
}
}
}
})
Python
# Observe metric
observed_df = df.observe("metric", count(lit(1)).as("cnt"), count(col("error")).as("malformed"))
observed_df.writeStream.format("...").start()
# Define my listener.
class MyListener(StreamingQueryListener):
def onQueryStarted(self, event):
print(f"'{event.name}' [{event.id}] got started!")
def onQueryProgress(self, event):
row = event.progress.observedMetrics.get("metric")
if row is not None:
if row.malformed / row.cnt > 0.5:
print("ALERT! Ouch! there are too many malformed "
f"records {row.malformed} out of {row.cnt}!")
else:
print(f"{row.cnt} rows processed!")
def onQueryTerminated(self, event):
print(f"{event.id} got terminated!")
# Add my listener.
spark.streams.addListener(MyListener())
配置 Apache Spark 计划程序池以提高效率
默认情况下,笔记本中启动的所有查询都在同一公平计划池中运行。 因此,由触发器根据笔记本中的所有流式处理查询生成的作业将按照先入先出 (FIFO) 的顺序逐一运行。 这可能会导致查询中产生不必要的延迟,因为它们不能有效地共享群集资源。
若要允许所有流式处理查询并发执行作业并有效地共享群集,可以将查询设置为在单独的计划程序池中执行。 例如:
// Run streaming query1 in scheduler pool1
spark.sparkContext.setLocalProperty("spark.scheduler.pool", "pool1")
df.writeStream.queryName("query1").format("parquet").start(path1)
// Run streaming query2 in scheduler pool2
spark.sparkContext.setLocalProperty("spark.scheduler.pool", "pool2")
df.writeStream.queryName("query2").format("orc").start(path2)
注意
本地属性配置必须位于你启动流式处理查询时所在的笔记本单元中。
有关更多详细信息,请参阅 Apache 公平计划程序文档。
优化有状态流查询的性能
如果流式处理查询中存在有状态操作(例如,流式处理聚合、流式处理 dropDuplicates、流间联接、mapGroupsWithState 或 flatMapGroupsWithState),并且你希望维护数百万个处于该状态的键,则你可能会遇到与大量 JVM 垃圾回收 (GC) 暂停相关的问题,这些问题会导致微批处理时间差异过大。 出现这种情况的原因是,默认情况下,状态数据是在执行程序的 JVM 内存中维护的,大量状态对象将给 JVM 带来内存压力,导致大量的 GC 暂停。
在这种情况下,可以选择根据 RocksDB 使用更优化的状态管理解决方案。 此解决方案在 Databricks Runtime 中提供。 此解决方案不是在 JVM 内存中保留状态,而是使用 RocksDB 来有效地管理本机内存和本地 SSD 中的状态。 此外,对此状态所做的任何更改都会通过结构化流式处理自动保存到你提供的检查点位置,从而提供完全容错保证(与默认状态管理相同)。 有关将 RocksDB 配置为状态存储的说明,请参阅配置 RocksDB 状态存储。
其他用于实现最佳性能的建议配置:
- 使用计算优化的实例作为工作器。 例如,Azure Standard_F16s 实例。
- 将无序分区的数量设置为群集中的核心数的 1-2 倍。
- 在 SparkSession 中,将
spark.sql.streaming.noDataMicroBatches.enabled配置设置为false。 这可阻止流式微批处理引擎处理不包含数据的微批处理。 另请注意,将此配置设置为false可能会导致有状态操作,该操作利用水印或处理时间超时,直到新数据到达时才获取数据输出,而不是立即获取数据输出。
关于性能优势,基于 RocksDB 的状态管理可以维护的状态键是默认的 100 倍。 例如,在使用 Azure Standard_F16s 实例作为工作器的 Spark 群集中,默认状态管理可以为每个执行程序维护最多 1-2 百万个状态键,超过此数量后,JVM GC 将开始显著影响性能。 与之相对,基于 RocksDB 的状态管理可以轻松地为每个执行程序维护 1 亿个状态键,不会出现任何 GC 问题。
注意
无法在两次查询重启之间更改状态管理方案。 也就是说,如果使用默认管理启动了某个查询,但不使用新的检查点位置从头启动查询,则无法更改该查询。
配置 RocksDB 状态存储
可以在启动流式处理查询之前,通过在 SparkSession 中设置以下配置来启用基于 RockDB 的状态管理。
spark.conf.set(
"spark.sql.streaming.stateStore.providerClass",
"com.databricks.sql.streaming.state.RocksDBStateStoreProvider")
RocksDB 状态存储指标
每个状态运算符收集有关在其 RocksDB 实例上执行的状态管理操作的指标,这些指标可用于观测状态存储,并可能有助于调试作业速度缓慢问题。 这些指标将会根据运行状态运算符的所有任务中的每个作业中状态运算符进行聚合(加总)。 这些指标是 StreamingQueryProgress 中 stateOperators 字段内的 customMetrics 映射的一部分。 下面是采用 JSON 格式的 StreamingQueryProgress 的示例(使用 StreamingQueryProgress.json() 获取)。
{
"id" : "6774075e-8869-454b-ad51-513be86cfd43",
"runId" : "3d08104d-d1d4-4d1a-b21e-0b2e1fb871c5",
"batchId" : 7,
"stateOperators" : [ {
"numRowsTotal" : 20000000,
"numRowsUpdated" : 20000000,
"memoryUsedBytes" : 31005397,
"numRowsDroppedByWatermark" : 0,
"customMetrics" : {
"rocksdbBytesCopied" : 141037747,
"rocksdbCommitCheckpointLatency" : 2,
"rocksdbCommitCompactLatency" : 22061,
"rocksdbCommitFileSyncLatencyMs" : 1710,
"rocksdbCommitFlushLatency" : 19032,
"rocksdbCommitPauseLatency" : 0,
"rocksdbCommitWriteBatchLatency" : 56155,
"rocksdbFilesCopied" : 2,
"rocksdbFilesReused" : 0,
"rocksdbGetCount" : 40000000,
"rocksdbGetLatency" : 21834,
"rocksdbPutCount" : 1,
"rocksdbPutLatency" : 56155599000,
"rocksdbReadBlockCacheHitCount" : 1988,
"rocksdbReadBlockCacheMissCount" : 40341617,
"rocksdbSstFileSize" : 141037747,
"rocksdbTotalBytesReadByCompaction" : 336853375,
"rocksdbTotalBytesReadByGet" : 680000000,
"rocksdbTotalBytesReadThroughIterator" : 0,
"rocksdbTotalBytesWrittenByCompaction" : 141037747,
"rocksdbTotalBytesWrittenByPut" : 740000012,
"rocksdbTotalCompactionLatencyMs" : 21949695000,
"rocksdbWriterStallLatencyMs" : 0,
"rocksdbZipFileBytesUncompressed" : 7038
}
} ],
"sources" : [ {
} ],
"sink" : {
}
}
指标的详细说明如下:
| 指标名称 | 说明 |
|---|---|
| rocksdbCommitWriteBatchLatency | 将内存中结构中的分阶段写入 (WriteBatch) 应用于本机 RocksDB 所花费的时间(以毫秒为单位)。 |
| rocksdbCommitFlushLatency | 将 RocksDB 内存中更改刷新到本地磁盘所花费的时间(以毫秒为单位)。 |
| rocksdbCommitCompactLatency | 在检查点提交期间进行压缩(可选)所花费的时间(以毫秒为单位)。 |
| rocksdbCommitPauseLatency | 在检查点提交过程中停止后台工作线程(以实现压缩等目的)所花费的时间(以毫秒为单位)。 |
| rocksdbCommitCheckpointLatency | 创建本机 RocksDB 快照并将其写入本地目录所花费的时间(以毫秒为单位)。 |
| rocksdbCommitFileSyncLatencyMs | 将本机 RocksDB 快照相关的文件同步到外部存储(检查点位置)所花费的时间(以毫秒为单位)。 |
| rocksdbGetLatency | 每个基础本机 RocksDB::Get 调用平均花费的时间(以纳秒为单位)。 |
| rocksdbPutCount | 每个基础本机 RocksDB::Put 调用平均花费的时间(以纳秒为单位)。 |
| rocksdbGetCount | 本机 RocksDB::Get 调用的数量(不包括从 WriteBatch 执行的 Gets - 用于暂存写入的内存中批处理)。 |
| rocksdbPutCount | 本机 RocksDB::Put 调用数量(不包括对 WriteBatch 执行的 Puts - 用于暂存写入的内存中批处理)。 |
| rocksdbTotalBytesReadByGet | 通过本机 RocksDB::Get 调用读取的未压缩字节数。 |
| rocksdbTotalBytesWrittenByPut | 通过本机 RocksDB::Put 调用写入的未压缩字节数。 |
| rocksdbReadBlockCacheHitCount | 使用本机 RocksDB 块缓存避免从本地磁盘读取数据的次数。 |
| rocksdbReadBlockCacheMissCount | 从本地磁盘读取数据所需的未命中本机 RocksDB 块缓存次数。 |
| rocksdbTotalBytesReadByCompaction | 本机 RocksDB 压缩进程从本地磁盘读取的字节数。 |
| rocksdbTotalBytesWrittenByCompaction | 本机 RocksDB 压缩进程写入本地磁盘的字节数。 |
| rocksdbTotalCompactionLatencyMs | RocksDB 压缩(后台压缩以及在提交期间启动的可选压缩)所花费的时间(以毫秒为单位)。 |
| rocksdbWriterStallLatencyMs | 由于后台压缩或将内存表刷新到磁盘而导致写入器停滞的时间(以毫秒为单位)。 |
| rocksdbTotalBytesReadThroughIterator | 某些有状态操作(例如 flatMapGroupsWithState 中的超时处理或窗口聚合中的水印处理)需要通过迭代器读取 DB 中的整个数据。 使用迭代器读取的未压缩数据的总大小。 |
异步状态检查点
注意
在 Databricks Runtime 10.3 及更高版本中可用。
在具有较大状态更新的有状态流式处理查询中启用异步状态检查点,可能可以减少端到端的微批处理延迟。
结构化流式处理当前使用同步检查点,这意味着,每个微批处理都将确保会在开始下一个批处理之前,先将批处理中所做的所有状态更新都备份到云存储中(称为“检查点位置”)。 如果有状态流式处理查询失败,可保证所有微批处理都已使用检查点(最后一个微批处理除外)。 因此,重启时,可能只需要重新执行最后一个批处理。 但是,这种通过同步检查点进行快速恢复所造成的影响是,每个微批处理的延迟较高。
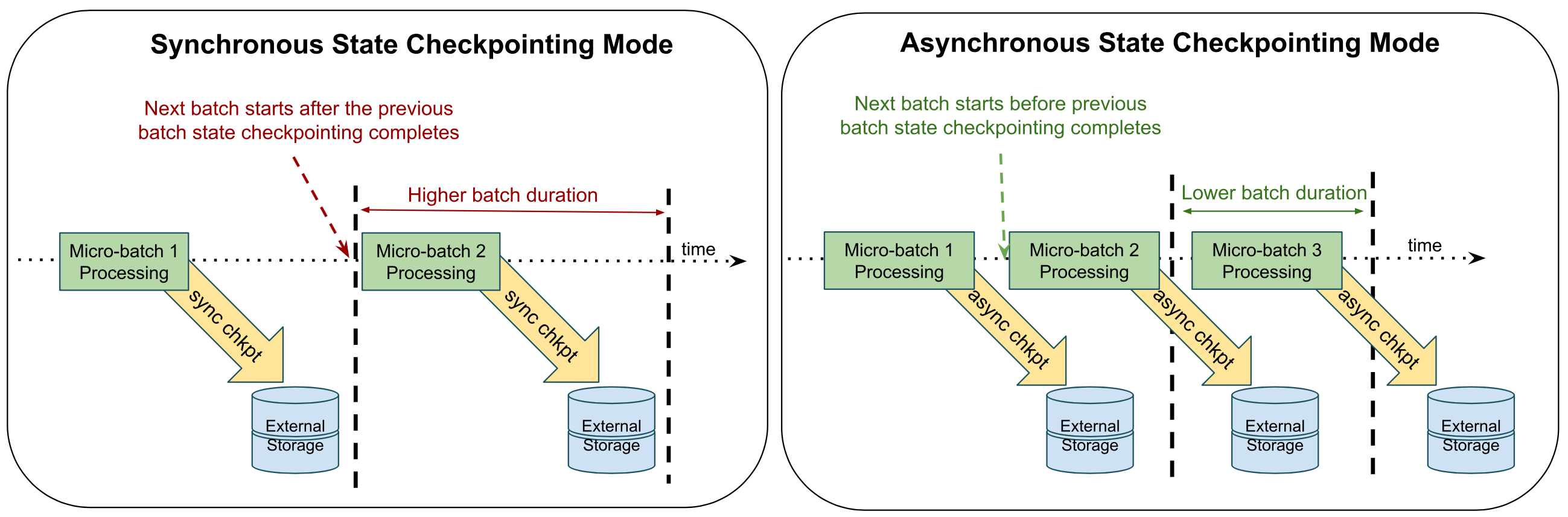
异步状态检查点尝试以异步方式执行检查点操作,以便执行微批处理时无需等待检查点完成。 换言之,只要前一个微批处理的计算完成,就可以开始下一个微批处理。 不过,偏移元数据(也保存在检查点位置)会在内部跟踪微批处理的状态检查点是否已完成。 在查询重启时,可能需要重新执行多个微批处理,即计算未完成的最后一个微批处理,以及它之前的一个状态检查点未完成的微批处理。 此外,你将获得与同步检查点相同的容错保证(即,使用幂等接收器进行恰好一次保证)。
总而言之,对于在状态更新上遇到瓶颈的有状态流式处理查询,启用异步状态检查点可以在不牺牲任何容错保证的情况下减少端到端延迟,但要付出的些许代价是会产生较高的重启延迟。
确定目标工作负载
以下是可能从异步状态检查点中受益的流式处理作业的特征。
- 作业有一个或多个有状态操作(例如聚合、[flat]MapGroupsWithState、流之间的联接)
- 状态检查点延迟是导致整体批处理执行延迟的主要因素之一。 此信息可以在 StreamingQueryProgress 事件中找到。 这些事件也可在 Spark 驱动程序上的 log4j 日志中找到。 下面是流式处理查询进度的示例,以及如何查找状态检查点对总体批处理执行延迟的影响。
-
{ "id" : "2e3495a2-de2c-4a6a-9a8e-f6d4c4796f19", "runId" : "e36e9d7e-d2b1-4a43-b0b3-e875e767e1fe", "...", "batchId" : 0, "durationMs" : { "...", "triggerExecution" : 547730, "..." }, "stateOperators" : [ { "...", "commitTimeMs" : 3186626, "numShufflePartitions" : 64, "..." }] } 上述查询进度事件的状态检查点延迟分析
- 批处理持续时间 (
durationMs.triggerDuration) 约为 547 秒。 - 状态存储提交延迟时间 (
stateOperations[0].commitTimeMs) 大约为 3186 秒。 提交延迟时间是所有包含状态存储的任务的总和。 在此例中共有 64 个这样的任务 (stateOperators[0].numShufflePartitions)。 - 每个包含状态运算符的任务平均花费 50 秒(3186/64)用于检查点。 这导致了批处理持续时间的额外延迟。 假设所有 64 个任务并发运行,则检查点步骤占据了大约 9%(50 秒/547 秒)的批处理持续时间。 当并发运行的最大任务数小于 64 时,这一百分比会更高。
- 批处理持续时间 (
-
启用异步状态检查点
在流式处理作业中设置以下配置。 异步检查点需要支持异步提交的状态存储实现。 目前只有基于 RocksDB 的状态存储实现支持异步提交。
spark.conf.set(
"spark.databricks.streaming.statefulOperator.asyncCheckpoint.enabled",
"true"
)
spark.conf.set(
"spark.sql.streaming.stateStore.providerClass",
"com.databricks.sql.streaming.state.RocksDBStateStoreProvider"
)
限制
- 在任何一个或多个存储内,异步检查点中的任何故障都会导致查询失败。 在同步检查点模式下,检查点作为任务的一部分执行,Spark 在查询失败之前会多次重试任务。 异步状态检查点不提供此机制。 但是,使用 Databricks 作业重试,可以自动重试此类失败。
- 与异步状态检查点结合使用时,自动缩放可能会无法正常工作:如果微批处理执行之间的态存储位置未更改,异步检查点可获得最佳效果。 启用自动缩放后,在自动缩放过程中添加或删除节点时,可以重新分布状态存储实例。
- 仅在 RocksDB 状态存储提供程序实现中支持异步状态检查点。 默认的内存中状态存储实现不支持异步状态检查点。
多水印策略
流式处理查询可以有多个联合或联接在一起的输入流。
对于有状态操作,每个输入流可以有不同的需要容忍的延迟数据阈值。 可以使用 withWatermarks("eventTime", delay) 在每个输入流上指定这些阈值。 例如,请考虑一个包含流间联接的查询
val inputStream1 = ... // delays up to 1 hour
val inputStream2 = ... // delays up to 2 hours
inputStream1.withWatermark("eventTime1", "1 hour")
.join(
inputStream2.withWatermark("eventTime2", "2 hours"),
joinCondition)
当执行查询时,结构化流式处理会单独跟踪每个输入流中显示的最大事件时间,根据相应的延迟计算水印,并选择一个与它们一起用于有状态操作的全局水印。 默认情况下,最小值将被选为全局水印,因为它可确保在其中一个流落后于其他流的情况下(例如,其中一个流由于上游故障而停止接收数据),数据不会因为太迟而被意外丢弃。 换句话说,全局水印将以最慢流的速度安全地移动,并且查询输出将相应地延迟。
在某些情况下,你可能希望获得更快的结果,即使这意味着要从最慢的流中丢弃数据。 可以通过将 SQL 配置 spark.sql.streaming.multipleWatermarkPolicy 设置为 max(默认值为 min)来设置多水印策略,以选择最大值作为全局水印。
这允许全局水印以最快流的速度移动。
但副作用是较慢流中的数据会被主动丢弃。 因此,Databricks 建议慎用此配置。
将结构化流式处理数据帧可视化
你可以使用 display 函数实时可视化结构化流式处理数据帧。 虽然 trigger 和 checkpointLocation 参数是可选的,但 Databricks 建议在生产中始终指定它们,这是最佳做法。
Scala
import org.apache.spark.sql.streaming.Trigger
val streaming_df = spark.readStream.format("rate").load()
display(streaming_df.groupBy().count(), trigger = Trigger.ProcessingTime("5 seconds"), checkpointLocation = "dbfs:/<checkpoint-path>")
Python
streaming_df = spark.readStream.format("rate").load()
display(streaming_df.groupBy().count(), processingTime = "5 seconds", checkpointLocation = "dbfs:/<checkpoint-path>")
有关详细信息,请参阅结构化流式处理数据帧。
状态运算符 flatMapGroupsWithState 改进
指定初始状态
可以使用 [flat]MapGroupsWithState 运算符为结构化流式处理有状态处理指定用户定义的初始状态。 这样可以避免重新执行整个处理流程。
def mapGroupsWithState[S: Encoder, U: Encoder](
timeoutConf: GroupStateTimeout,
initialState: KeyValueGroupedDataset[K, S])(
func: (K, Iterator[V], GroupState[S]) => U): Dataset[U]
def flatMapGroupsWithState[S: Encoder, U: Encoder](
outputMode: OutputMode,
timeoutConf: GroupStateTimeout,
initialState: KeyValueGroupedDataset[K, S])(
func: (K, Iterator[V], GroupState[S]) => Iterator[U])
以下示例用例指定 flatMapGroupsWithState 运算符的初始状态:
val fruitCountFunc =(key: String, values: Iterator[String], state: GroupState[RunningCount]) => {
val count = state.getOption.map(_.count).getOrElse(0L) + valList.size
state.update(new RunningCount(count))
Iterator((key, count.toString))
}
val fruitCountInitialDS: Dataset[(String, RunningCount)] = Seq(
("apple", new RunningCount(1)),
("orange", new RunningCount(2)),
("mango", new RunningCount(5)),
).toDS()
val fruitCountInitial = initialState.groupByKey(x => x._1).mapValues(_._2)
fruitStream
.groupByKey(x => x)
.flatMapGroupsWithState(Update, GroupStateTimeout.NoTimeout, fruitCountInitial)(fruitCountFunc)
以下示例用例指定 mapGroupsWithState 运算符的初始状态:
val fruitCountFunc =(key: String, values: Iterator[String], state: GroupState[RunningCount]) => {
val count = state.getOption.map(_.count).getOrElse(0L) + valList.size
state.update(new RunningCount(count))
(key, count.toString)
}
val fruitCountInitialDS: Dataset[(String, RunningCount)] = Seq(
("apple", new RunningCount(1)),
("orange", new RunningCount(2)),
("mango", new RunningCount(5)),
).toDS()
val fruitCountInitial = initialState.groupByKey(x => x._1).mapValues(_._2)
fruitStream
.groupByKey(x => x)
.mapGroupsWithState(GroupStateTimeout.NoTimeout, fruitCountInitial)(fruitCountFunc)
测试状态更新函数
利用 TestGroupState API,你可以测试用于 Dataset.groupByKey(...).mapGroupsWithState(...) 和 Dataset.groupByKey(...).flatMapGroupsWithState(...) 的状态更新函数。
状态更新函数使用 GroupState 类型的对象获取先前的状态作为输入。 请参阅 Apache Spark GroupState 参考文档。 例如:
import org.apache.spark.sql.streaming._
import org.apache.spark.api.java.Optional
test("flatMapGroupsWithState's state update function") {
var prevState = TestGroupState.create[UserStatus](
optionalState = Optional.empty[UserStatus],
timeoutConf = GroupStateTimeout.EventTimeTimeout,
batchProcessingTimeMs = 1L,
eventTimeWatermarkMs = Optional.of(1L),
hasTimedOut = false)
val userId: String = ...
val actions: Iterator[UserAction] = ...
assert(!prevState.hasUpdated)
updateState(userId, actions, prevState)
assert(prevState.hasUpdated)
}