Azure 事件中心 - 支持本机 Apache Kafka 的实时数据流式处理平台
Azure 事件中心是一种云原生数据流式处理服务,它每秒可以较低的延迟从任何源流式传输数百万个事件到任何目标。 事件中心与 Apache Kafka 兼容,让你无需进行任何代码更改即可运行现有的 Kafka 工作负载。
使用事件中心引入和存储流数据,企业可以利用流数据的强大功能来获取有价值的见解、推动实时分析,并在事件发生时响应事件,从而提高整体效率和客户体验。

Azure 事件中心是基于 Azure 构建的任何事件流式处理解决方案的首选事件引入层。 它与 Azure 内外的数据和分析服务无缝集成,生成完整的数据流式处理管道来处理以下用例。
- 使用 Azure 流分析进行实时分析,以便从流数据生成实时见解。
- 使用 Azure 数据资源管理器分析和探索流数据。
- 创建自己的云原生应用程序、函数或微服务,它们在来自事件中心的流数据上运行。
关键功能
Azure 事件中心上的 Apache Kafka
Azure 事件中心是一个多协议事件流式处理引擎,它本机支持 AMQP、Apache Kafka 和 HTTP 协议。 由于它支持 Apache Kafka,因此无需进行任何代码更改,即可将 Kafka 工作负载引入 Azure 事件中心。 无需设置、配置或管理你自己的 Kafka 群集,也不需要使用并非 Azure 原生的 Kafka 即服务产品。
事件中心从头开始构建为云原生代理引擎。 因此,你可以更好的性能、更好的成本效率运行 Kafka 工作负载,而且没有操作开销。
有关详细信息,请参阅适用于 Apache Kafka 的 Azure 事件中心。
使用 Azure 流分析实时处理流事件
事件中心与 Azure 流分析无缝集成,以实现实时流处理。 借助内置的无代码编辑器,无需编写任何代码即可使用拖放功能轻松开发流分析作业。

或者,开发人员可以使用基于 SQL 的流分析查询语言来执行实时流处理,并利用各种函数来分析流数据。
使用 Azure 数据资源管理器探索流数据
Azure 数据资源管理器是一个用于大数据分析的完全托管的平台,它可提供高性能,并支持近乎实时地分析大量数据。 通过将事件中心与 Azure 数据资源管理器集成,可以轻松地对流数据执行准实时分析和探索。
有关详细信息,请参阅将数据从事件中心引入 Azure 数据资源管理器及相同部分中的文章。
丰富的生态系统 - Azure 函数、SDK 和 Kafka 生态系统
实时引入、缓冲、存储和处理流,以获取可行的见解。 事件中心使用分区的使用者模型,可让多个应用程序同时处理流,并允许控制处理速度。 Azure 事件中心还与 Azure Functions 集成,以实现无服务器体系结构。
借助适用于行业标准 AMQP 1.0 协议的广泛生态系统以及各种语言(.NET、Java、Python、JavaScript)的 SDK,你可以轻松地从事件中心开始处理流。 所有支持的客户端语言提供低级别集成。
生态系统还提供 Azure Functions、Azure Spring Apps、Kafka 连接器和其他数据分析平台和技术(如 Apache Spark 和 Apache Flink)的无缝集成。
事件流式处理灵活且经济高效
可以通过事件中心的各种层(包括标准层、高级层和专用层)体验灵活且经济高效的事件流式处理。 这些选项满足从几 MB/秒到几 GB/秒的数据流式处理需求,让你能够根据需求选择完美的匹配项。
可缩放
使用事件中心可以从 MB 量级的数据流着手,然后逐步扩展到 GB 甚至 TB 量级的处理。 有很多选项根据用量需求扩展吞吐量单位数或处理单位数,而自动扩充功能是其中之一。
捕获流数据以供长期保留和批处理分析
在 Azure Blob 存储或 Azure Data Lake Storage 中近乎实时地捕获数据,以进行长期保留或微批处理。 可以基于用于派生实时分析的同一个流实现此行为。 设置捕获极其简单。
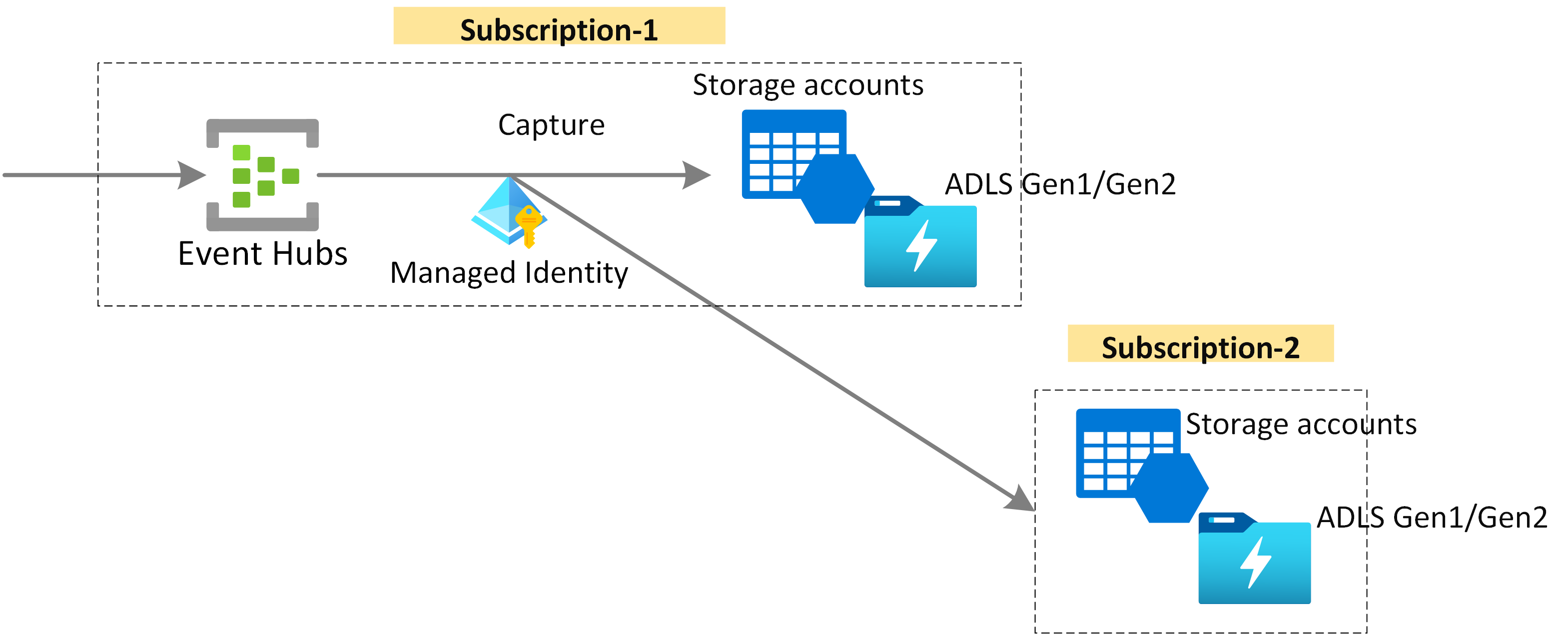
工作原理
事件中心提供统一的事件流式处理平台和时间保留缓冲区,将事件生成者与事件使用者分离开来。 生成者和使用者应用程序可以通过多个协议执行大规模数据引入。
下图显示了事件中心体系结构的关键组件:
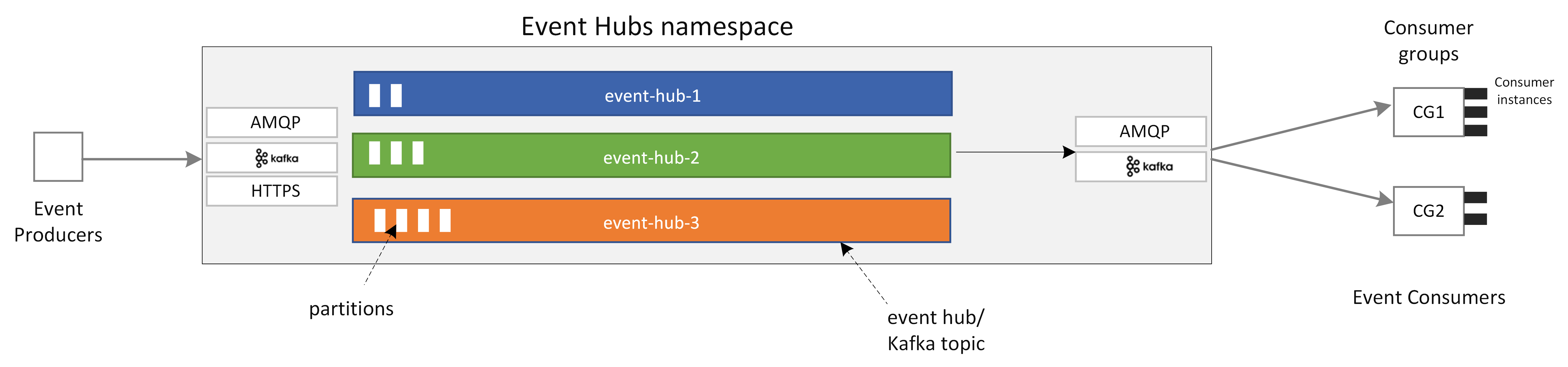
事件中心的主要功能组件包括:
- 生成者应用程序可以使用事件中心 SDK 或任何 Kafka 生成者客户端将数据引入事件中心。
- 命名空间是一个或多个事件中心或 Kafka 主题的管理容器。 在命名空间级别处理分配流式处理容量、配置网络安全、启用异地灾难恢复等管理任务。
- 事件中心/Kafka 主题:在事件中心,可以将事件整理到事件中心或 Kafka 主题中。 它是仅追加的分布式日志,可以包含一个或多个分区。
- 分区用于缩放事件中心。 他们就像高速公路里的车道。 如果需要更多流式处理吞吐量,需要添加更多分区。
- 使用者应用程序通过事件日志查找并维护使用者偏移量来使用数据。 使用者可以是 Kafka 使用者客户端,也可以是事件中心 SDK 客户端。
- 使用者组是从事件中心/Kafka 主题读取数据的使用者实例的逻辑分组。 它使多个使用者能够按照自己的节奏及其偏移量独立读取事件中心中的相同流数据。
后续步骤
若要开始使用事件中心,请参阅以下快速入门指南。
使用事件中心 SDK (AMQP) 对数据进行流式传输
可使用以下示例之一通过 SDK 将数据流式传输到事件中心。
使用 Apache Kafka 流式传输数据
可使用以下示例将数据从 Kafka 应用程序流式传输到事件中心。