本文介绍如何使用不同的 Azure 存储帐户将 Azure HDInsight 上的 Apache HBase 群集迁移到新版本。
仅当需要为源群集和目标群集使用不同的存储帐户时,本文才适用。 若要为源群集和目标群集使用相同的存储帐户升级版本,请参阅将 Apache HBase 迁移到新版本。
升级时的停机时间可能超过 20 分钟。 此停机是由刷新所有内存中数据的步骤,等待所有过程完成,以及在新群集上配置和重启服务所耗时间导致的。 最终时间因节点数目、数据量和其他变数而异。
检查 Apache HBase 兼容性
在升级 Apache HBase 之前,请确保源群集和目标群集上的 HBase 版本兼容。 查看 HBase 参考指南中的 HBase 版本兼容性对照表和发行说明,以确保应用程序与新版本兼容。
下面是一个示例兼容性对照表。 Y 表示兼容,N 表示可能不兼容:
| 兼容性类型 | 主版本 | 次版本 | 修补程序 |
|---|---|---|---|
| 客户端-服务器网络兼容性 | N | Y | Y |
| 服务器-服务器兼容性 | N | Y | Y |
| 文件格式兼容性 | N | Y | Y |
| 客户端 API 兼容性 | N | Y | Y |
| 客户端二进制文件兼容性 | N | N | Y |
| 服务器端受限的 API 兼容性 | |||
| Stable | N | Y | Y |
| 不断变化 | N | N | Y |
| 不稳定 | N | N | N |
| 依赖项兼容性 | N | Y | Y |
| 操作兼容性 | N | N | Y |
HBase 版本发行说明应会阐述任何重大的不兼容性。 在运行 HDInsight 和 HBase 目标版本的群集中测试应用程序。
有关 HDInsight 版本和兼容性的详细信息,请参阅 Azure HDInsight 版本。
Apache HBase 群集迁移概述
若要升级 Azure HDInsight 上的 Apache HBase 群集并将其迁移到新的存储帐户,请完成以下基本步骤。 有关详细说明,请参阅详细步骤和命令。
准备源群集:
- 停止数据引入。
- 检查群集运行状况
- 如需要,请停止复制
- 刷新
memstore数据。 - 停止 HBase。
- 对于具有加速写入的群集,请备份“Write Ahead Log (WAL)”目录。
准备目标群集:
- 创建目标群集。
- 从 Ambari 停止 HBase。
- 清理 Zookeeper 数据。
- 将用户切换到 HBase。
完成迁移:
- 清理目标文件系统、迁移数据并删除
/hbase/hbase.id。 - 清理并迁移 WAL。
- 从 Ambari 目标群集启动所有服务。
- 验证 HBase。
- 删除源群集。
详细的迁移步骤和命令
使用这些详细步骤和命令通过新的存储帐户迁移 Apache HBase 群集。
准备源群集
停止引入到源 HBase 群集。
检查 Hbase hbck 以验证群集运行状况
验证 HBase UI 上的 HBCK 报告页。 正常的群集不会出现任何的不一致
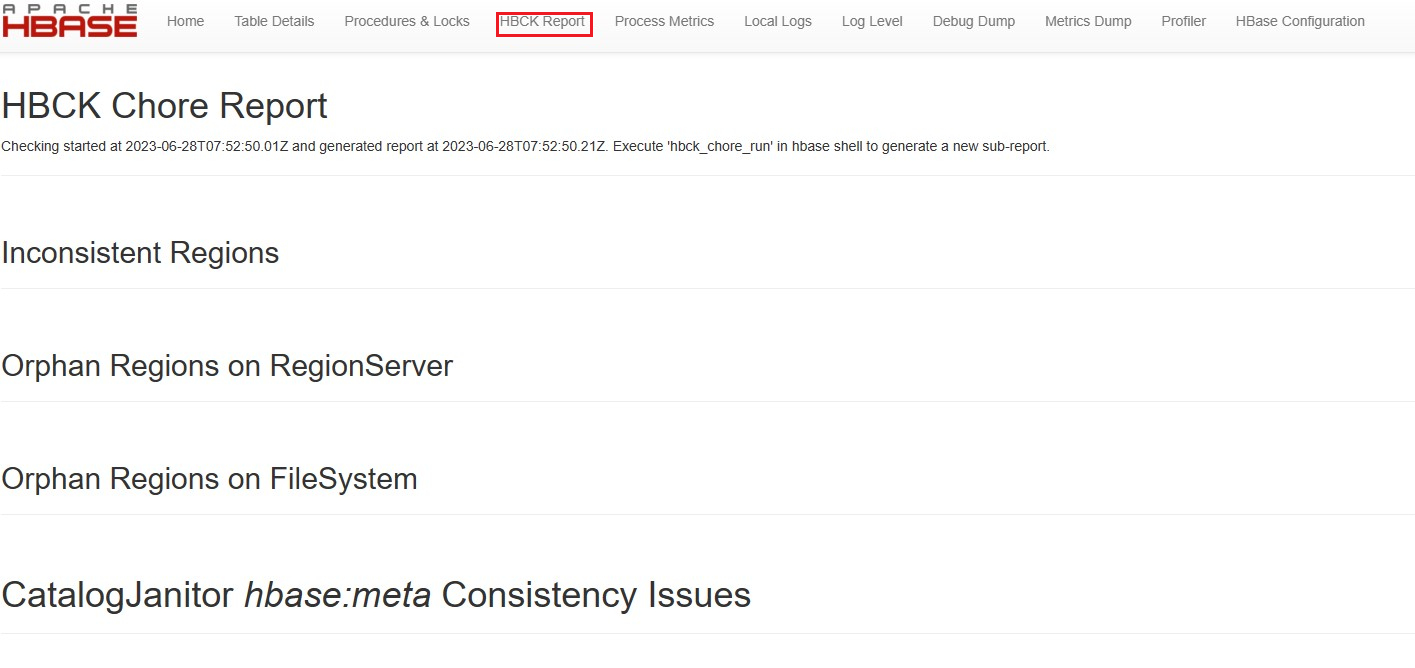
如果存在任何不一致,请使用 hbase hbck2 修复不一致问题
记下源群集联机区域中的区域数,以便在迁移后可以在目标群集中引用该数字。
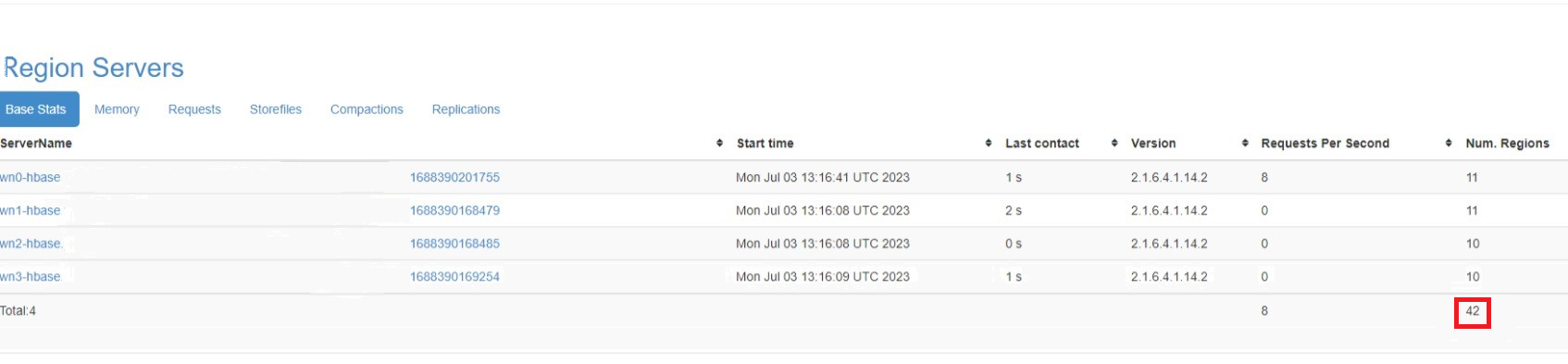
如果群集上启用了复制,请在迁移后停止复制并重新启用目标群集上的复制。 请参阅 HBase 复制指南
刷新要升级的源 HBase 群集。
HBase 将传入的数据写入名为“
memstore”的内存中存储。memstore达到特定的大小后,HBase 会将其刷新到群集存储帐户中用作长期存储的磁盘中。 如果在升级后删除源群集,则还会删除memstore中的所有数据。 若要保留数据,请在升级前将每个表的memstore手动刷新到磁盘。可通过从 hbase-utils GitHub 存储库运行 flush_all_tables.sh 脚本来刷新
memstore数据。还可通过从 HDInsight 群集内部运行以下 HBase shell 命令来刷新
memstore数据:hbase shell flush "<table-name>"等待 15 分钟并验证所有过程是否已完成,masterProcWal 文件没有任何待处理的过程。
验证“过程”页以确认没有待处理的过程。
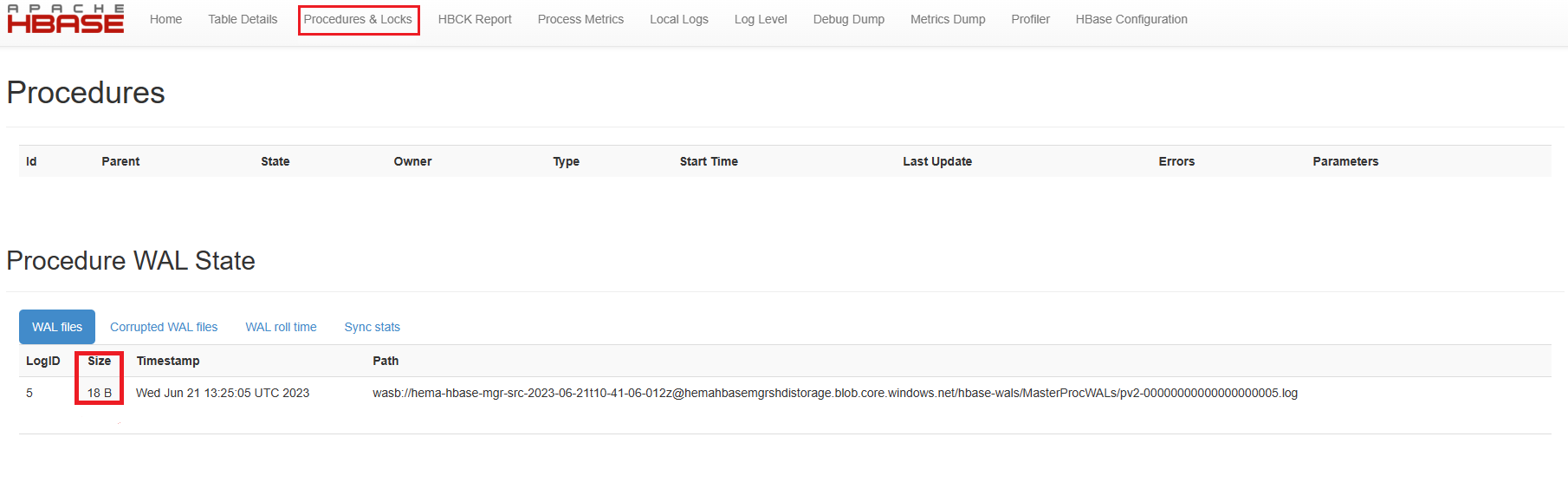
停止 HBase
使用
https://<OLDCLUSTERNAME>.azurehdinsight.cn在源群集上登录到 Apache Ambari为 HBase 打开维护模式。
仅先停止 HBase Master。 首先停止备用主节点,最后停止活动的 HBase 主节点。
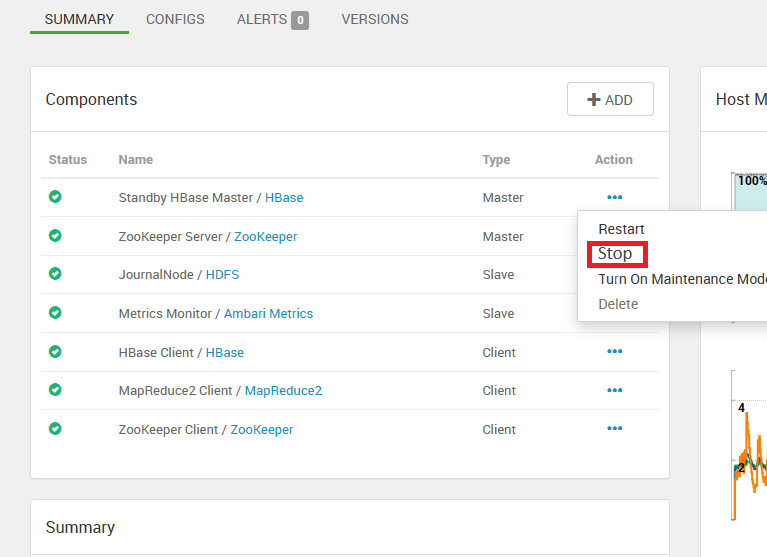
停止 HBase 服务,它会停止剩余的服务器。
注意
HBase 2.4.11 不支持某些旧过程。
有关连接和使用 Ambari 的详细信息,请参阅使用 Ambari Web UI 管理 HDInsight 群集。
在前面的步骤中停止 HBase 时提到 Hbase 如何避免创建新的主 proc WAL。
如果源 HBase 群集没有加速写入功能,请跳过此步骤。 对于具有加速写入的源 HBase 群集,从任何源群集 Zookeeper 节点或工作器节点上的 SSH 会话运行以下命令,从而备份 HDFS 下的 WAL 目录。
hdfs dfs -mkdir /hbase-wal-backup hdfs dfs -cp hdfs://mycluster/hbasewal /hbase-wal-backup




准备目标群集
在 Azure 门户中,设置新的目标 HDInsight 群集,它使用与源群集不同的存储帐户。
在新群集 (
https://<NEWCLUSTERNAME>.azurehdinsight.cn) 上登录 Apache Ambari,然后停止 HBase 服务。在任何 Zookeeper 节点或工作器节点中运行以下命令,从而清除目标群集上的 Zookeeper 数据:
hbase zkcli rmr /hbase-unsecure quit通过运行
sudo su hbase将用户切换到 HBase。
清理并迁移文件系统和 WAL
根据源 HDInsight 版本以及源和目标群集是否具有加速写入,运行以下命令。 目标群集始终为 HDInsight 版本 4.0,因为 HDInsight 3.6 采用的是基本支持,不建议用于新群集。
- 源群集是具有加速写入的 HDInsight 4.0,目标群集具有加速写入。
- 源群集是不具有加速写入的 HDInsight 4.0,目标群集具有加速写入。
- 源群集是不具有加速写入的 HDInsight 4.0,目标群集不具有加速写入。
存储帐户的 <container-endpoint-url> 为 https://<storageaccount>.blob.core.chinacloudapi.cn/<container-name>。 在 URL 的末尾传递存储帐户的 SAS 令牌。
- 存储类型 WASB 的
<container-fullpath>为wasbs://<container-name>@<storageaccount>.blob.core.chinacloudapi.cn - 存储类型 Azure Data Lake Storage Gen2 的
<container-fullpath>为abfs://<container-name>@<storageaccount>.dfs.core.chinacloudapi.cn。
复制命令
HDFS 复制命令为 hdfs dfs <copy properties starting with -D> -cp
复制不在页 blob 中的文件时,使用 hadoop distcp 以获得更好的性能:hadoop distcp <copy properties starting with -D>
若要传递存储帐户的密钥,请使用:
-Dfs.azure.account.key.<storageaccount>.blob.core.chinacloudapi.cn='<storage account key>'-Dfs.azure.account.keyprovider.<storageaccount>.blob.core.chinacloudapi.cn=org.apache.hadoop.fs.azure.SimpleKeyProvider
还可以使用 AzCopy 以在复制 HBase 数据文件时获得更好的性能。
运行 AzCopy 命令:
azcopy cp "<source-container-endpoint-url>/hbase" "<target-container-endpoint-url>" --recursive如果目标存储帐户是 Azure Blob 存储,请在复制后执行此步骤。 如果目标存储帐户是 Data Lake Storage Gen2,请跳过此步骤。
Hadoop WASB 驱动程序使用对应于每个目录的大小为零的特殊 Blob。 AzCopy 在执行复制时将跳过这些文件。 某些 WASB 操作使用这些 blob,因此你必须在目标群集中创建它们。 若要创建 blob,请从目标群集中的任何节点运行以下 Hadoop 命令:
sudo -u hbase hadoop fs -chmod -R 0755 /hbase
可以从 AzCopy 入门下载 AzCopy。 有关使用 AzCopy 的详细信息,请参阅 azcopy copy。
源群集是不具有加速写入的 HDInsight 4.0,目标群集具有加速写入
若要清理文件系统并迁移数据,请运行以下命令:
hdfs dfs -rm -r /hbase hadoop distcp <source-container-fullpath>/hbase /通过运行
hdfs dfs -rm /hbase/hbase.id来删除hbase.id若要清理和迁移 WAL,请运行以下命令:
hdfs dfs -rm -r hdfs://<destination-cluster>/hbasewal hdfs dfs -Dfs.azure.page.blob.dir="/hbase-wals" -cp <source-container-fullpath>/hbase-wals hdfs://<destination-cluster>/hbasewal
源群集是不具有加速写入的 HDInsight 4.0,目标群集不具有加速写入
若要清理文件系统并迁移数据,请运行以下命令:
hdfs dfs -rm -r /hbase hadoop distcp <source-container-fullpath>/hbase /通过运行
hdfs dfs -rm /hbase/hbase.id来删除hbase.id若要清理和迁移 WAL,请运行以下命令:
hdfs dfs -rm -r /hbase-wals/* hdfs dfs -Dfs.azure.page.blob.dir="/hbase-wals" -cp <source-container-fullpath>/hbase-wals /
完成迁移
在目标群集上保存更改,然后重启 Ambari 指示的所有所需服务。
将应用程序指向目标群集。
注意
升级时,应用程序的静态 DNS 名称会更改。 请勿硬编码此 DNS 名称,可以在域名的 DNS 设置中配置一个指向群集名称的 CNAME。 另一种做法是使用应用程序的、无需重新部署即可更新的配置文件。
开始引入。
验证 HBase 一致性以及简单数据定义语言 (DDL) 和数据操作语言 (DML) 操作。
如果目标群集没有问题,请删除源群集。
疑难解答
用例 1:
如果 Hbase 主服务器和区域服务器停滞在转换中,或者只分配了一个区域,即 hbase:meta 区域,并且在等待其他区域分配。
解决方案;
通过 ssh 连接到原始群集的任何 ZooKeeper 节点,如果这是 ESP 群集,请运行
kinit -k -t /etc/security/keytabs/hbase.service.keytab hbase/<zk FQDN>运行
echo scan hbase:meta| hbase shell > meta.out将hbase:meta读取到文件中运行
grep "info:sn" meta.out | awk '{print $4}' | sort | uniq获取旧群集中存在区域的所有 RS 实例名称。 输出应该类似于value=<wn FQDN>,16020,........创建具有该
wn值的虚拟 WAL dir如果群集为加速写入的群集
hdfs dfs -mkdir hdfs://mycluster/hbasewal/WALs/<wn FQDN>,16020,.........如果群集为非加速写入的群集
hdfs dfs -mkdir /hbase-wals/WALs/<wn FQDN>,16020,.........重启活动
Hmaster
后续步骤
若要详细了解 Apache HBase 以及如何升级 HDInsight 群集,请参阅以下文章: