HDInsight 为大规模数据处理应用程序提供 Apache Hadoop 群集。 对这些复杂的多节点群集进行管理、监视和优化可能充满挑战。 Apache Ambari 是可用于管理和监视 HDInsight Linux 群集的 Web 界面。
有关使用 Ambari Web UI 的简介,请参阅使用 Apache Ambari Web UI 管理 HDInsight 群集
使用群集凭据通过 https://CLUSTERNAME.azurehdidnsight.net 登录到 Ambari。 初始屏幕显示了概述仪表板。
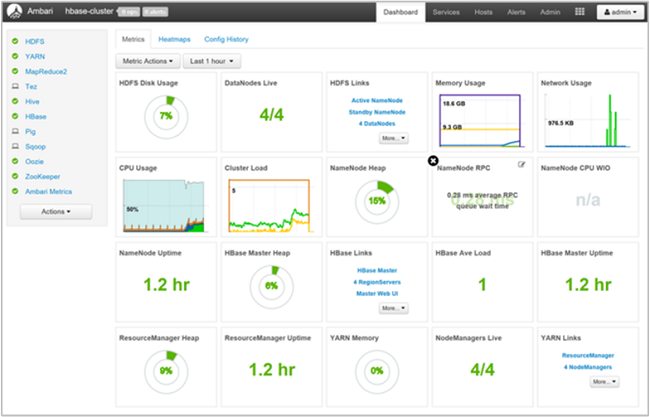
Ambari Web UI 可用于管理主机、服务、警报、配置和视图。 Ambari 不能用于创建 HDInsight 群集或升级服务。 它也无法管理堆栈和版本、停用或重新启用主机,或向群集添加服务。
管理群集的配置
配置设置可帮助优化特定服务。 若要修改某服务的配置设置,请从左侧的“服务”边栏中选择此服务。 然后,在服务详细信息页中转到“配置”选项卡。
修改 NameNode Java 堆大小
NameNode Java 堆大小取决于许多因素,例如群集上的负载。 此外,还有文件数和块数。 默认大小 1 GB 能够很好地满足大多数群集的需要,不过,某些工作负荷可能需要更多或更少的内存。
修改 NameNode Java 堆大小:
从“服务”边栏中选择“HDFS”,然后导航到“配置”选项卡。
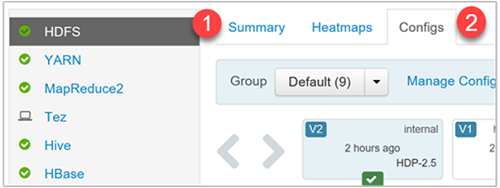
找到“NameNode Java 堆大小”设置。 也可以使用“筛选器”文本框键入和查找特定的设置。 选择设置名称旁边的笔图标。

在文本框中键入新值,然后按 Enter 保存更改。
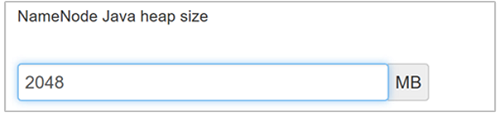
NameNode Java 堆大小已从 2 GB 更改为 1 GB。

单击配置屏幕顶部的绿色“保存”按钮保存所做的更改。
