Azure HDInsight是云中面向企业的托管、全谱开源分析服务。 借助 HDInsight,可以在Azure环境中使用开源框架,例如 Apache Spark、Apache Hive、LLAP、Apache Kafka、Hadoop 等。
什么是 HDInsight 和 Hadoop 技术堆栈?
Azure HDInsight是一个托管群集平台,可用于在 Azure 环境中轻松运行大数据框架,如 Apache Spark、Apache Hive、LLAP、Apache Kafka、Apache Hadoop 和其他框架。 此平台专为快速高效地处理大量数据而设计。
为何应使用Azure HDInsight?
| 能力 | DESCRIPTION |
|---|---|
| 云原生 | Azure HDInsight使你能够在 Azure 上为 Spark、Interactive query (LLAP)、Kafka、HBase 和 Hadoop 创建优化群集。 HDInsight 还在所有生产工作负荷上提供端到端 SLA。 |
| 低成本且可缩放 | 可以通过 HDInsight 纵向缩放工作负载。 可以通过创建按需群集来降低成本,只为自己使用的资源付费。 还可以生成数据管道来使作业自动化。 分离的计算和存储提供更好的性能和灵活性。 |
| 既安全又合规 | 借助 HDInsight,可以使用Azure Virtual Network、加密和与Microsoft Entra ID集成来保护企业数据资产。 HDInsight 还满足最常用的行业和政府符合性标准。 |
| 监测 | Azure HDInsight与Azure Monitor日志集成,以提供一个接口,可用于监视所有群集。 |
| 全球推出 | 提供 HDInsight 的区域要多于提供任何其他大数据分析产品/服务的区域。 Azure HDInsight也可在由世纪互联和德国运营的Azure中使用,这使你可以在关键主权领域满足企业需求。 |
| 生产力 | Azure HDInsight使你能够将适用于 Hadoop 和 Spark 的丰富高效工具与首选开发环境配合使用。 这些开发环境包括Visual Studio、VS Code、Eclipse 和 IntelliJ for Scala、Python、Java和.NET支持。 |
| 可扩展性 | 可以通过脚本操作、添加边缘节点或与其他大数据认证应用程序集成,使用安装的组件(如 Hue、Presto 等)来扩展 HDInsight 群集。 HDInsight 允许通过单击部署方式无缝集成最常用的大数据解决方案。 |
什么是大数据?
与以前相比,大数据的收集量在增加,收集速度在加快,收集格式在增多。 大数据可以是历史数据(即已存储的数据),也可以是实时数据(即从数据源流式传输的数据)。 请参阅使用 HDInsight 的方案,了解大数据的最常见用例。
HDInsight 中的群集类型
HDInsight 包括特定的群集类型和群集自定义功能,例如添加组件、实用程序和语言的功能。 HDInsight 提供以下群集类型:
| 群集类型 | DESCRIPTION | 开始 |
|---|---|---|
| Apache Hadoop | 一个框架,使用 HDFS、YARN 资源管理和简单的 MapReduce 编程模型并行处理和分析批处理数据。 | 创建 Apache Hadoop 群集 |
| Apache Spark | 一种开源并行处理框架,支持使用内存中处理来提升大数据分析应用程序的性能。 请参阅 HDInsight 中的 Apache Spark 是什么? | 创建 Apache Spark 群集 |
| Apache HBase | 一个基于 Hadoop 构建的 NoSQL 数据库,为大量非结构化和半结构化数据提供随机访问和强一致性——这些数据可以是数十亿行乘以数百万列。 请参阅什么是 HDInsight 上的 HBase? | 创建 Apache HBase 群集 |
| Apache Interactive Query | 用于实现更快的交互式 Hive 查询的内存中缓存。 请参阅 在 HDInsight 中使用 Interactive Query。 | 创建Interactive Query群集 |
| Apache Kafka | 开源平台用于构建流数据处理管道和应用程序。 Kafka 还提供了消息队列功能,允许用户发布和订阅数据流。 请参阅 Apache Kafka on HDInsight 简介。 | 创建 Apache Kafka 群集 |
使用 HDInsight 的方案
Azure HDInsight 可用于 大数据处理的各种场景。 大数据可以是历史数据(已收集和存储的数据),也可以是实时数据(直接从源流式传输的数据)。 处理此类数据的方案可以汇总成以下类别:
批处理 (ETL)
提取、转换和加载 (ETL) 是指将非结构化或结构化数据从异类数据源中提取出来, 然后将其转换为结构化格式,并加载到数据存储中。 可以将转换的数据用于数据科学或数据仓库。
数据仓库
可以使用 HDInsight 对任何格式的结构化或非结构化数据执行 PB 规模的交互式查询。 也可以通过生成模型将其连接到 BI 工具。
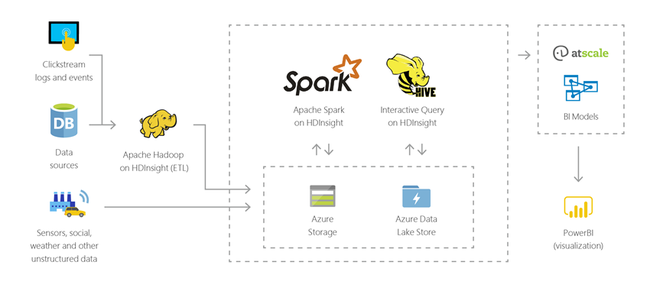
物联网 (IoT)
可以使用 HDInsight 处理从各种设备实时接收的流数据。 有关详细信息,请阅读 Azure 发布的博客文章,该文章宣布了使用 Azure 托管磁盘的 HDInsight 上 Apache Kafka 的公共预览版。
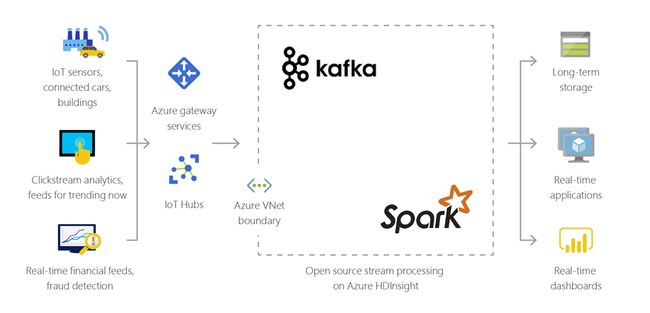
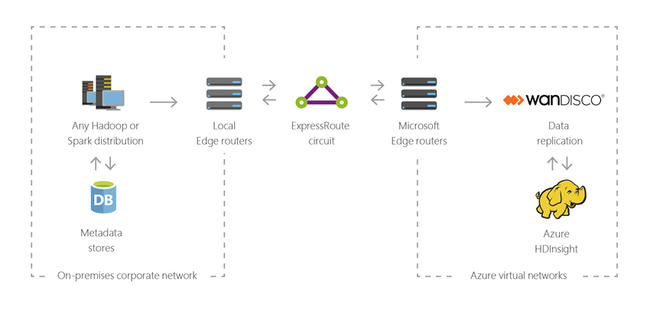
混合
可以使用 HDInsight 将现有的本地大数据基础结构扩展到 Azure,以利用云的高级分析功能。
HDInsight 中的开源组件
Azure HDInsight使你能够使用 Spark、Hive、LLAP、Kafka、Hadoop 和 HBase 等开源框架创建群集。 默认情况下,这些群集包含各种开源组件,例如 Apache Ambari、Avro、Apache Hive 3、HCatalog、Apache Hadoop MapReduce、Apache Hadoop YARN、Apache Phoenix、Apache Pig、Apache Sqoop、Apache Tez、Apache Oozie 和 Apache ZooKeeper。
HDInsight 中的编程语言
HDInsight 群集包括 Spark、HBase、Kafka、Hadoop 和其他群集,支持多种编程语言。 某些编程语言默认情况下未安装。 对于默认情况下未安装的库、模块或程序包,请使用脚本操作来安装组件。
| 程序设计语言 | 信息 |
|---|---|
| 默认编程语言支持 | 默认情况下,HDInsight 群集支持:
|
| Java虚拟机(JVM)语言 | Java以外的多种语言可以在Java虚拟机(JVM)上运行。 但是,运行这其中的部分语言时,可能必须在群集上安装其他组件。 HDInsight 群集支持以下基于 JVM 的语言:
|
| Hadoop 专用语言 | HDInsight 群集支持以下特定于 Hadoop 技术堆栈的语言:
|
适用于 HDInsight 的开发工具
可以使用 HDInsight 开发工具(包括 IntelliJ、Eclipse、Visual Studio Code 和 Visual Studio)创作和提交 HDInsight 数据查询和作业,并与Azure无缝集成。
- 用于 IntelliJ 10 的 Azure 工具包
- 用于 Eclipse 6 的 Azure 工具包
- 适用于 VS Code 13 的Azure HDInsight工具
- 适用于 Visual Studio 9 的 Azure data lake 工具
HDInsight 上的商业智能
熟悉的商业智能(BI)工具通过使用 Power Query 加载项或 Microsoft Hive ODBC 驱动程序检索、分析和报告与 HDInsight 集成的数据:
将 Apache Spark BI 与 Azure HDInsight 和数据可视化工具结合使用
使用 Power Query 将 Excel 连接到 Apache Hadoop(需要 Windows)
使用 Microsoft Hive ODBC 驱动程序将 Excel 连接到 Apache Hadoop(需要 Windows)
区域内数据驻留
Spark、Hadoop 和 LLAP 不会存储客户数据,因此这些服务会自动满足 Azure 全局基础结构站点中指定的区域数据驻留要求。
Kafka 和 HBase 确实会存储客户数据。 此数据由 Kafka 和 HBase 自动存储在单个区域中,因此此服务满足 Azure 全局基础结构站点中指定的区域内数据驻留要求。
熟悉的商业智能(BI)工具通过使用Power Query加载项或 Microsoft Hive ODBC 驱动程序检索、分析和报告与 HDInsight 集成的数据。
后续步骤
- 在 HDInsight 中创建 Apache Hadoop 群集
- 创建 Apache Spark 群集 - 门户
- Azure HDInsight 中的企业安全