本教程介绍如何从 csv 文件创建数据帧,以及如何针对 Azure HDInsight 中的 Apache Spark 群集运行交互式 Spark SQL 查询。 在 Spark 中,数据帧是已组织成命名列的分布式数据集合。 数据帧在概念上相当于关系型数据库中的表,或 R/Python 中的数据帧。
在本教程中,你将了解如何执行以下操作:
- 从 csv 文件创建数据帧
- 对数据帧运行查询
先决条件
HDInsight 上的 Apache Spark 群集。 请参阅创建 Apache Spark 群集。
创建 Jupyter Notebook
Jupyter Notebook 是支持各种编程语言的交互式笔记本环境。 通过此笔记本可以与数据进行交互、结合代码和 markdown 文本以及执行简单的可视化效果。
通过将
SPARKCLUSTER替换为 Spark 群集的名称来编辑 URLhttps://SPARKCLUSTER.azurehdinsight.cn/jupyter。 然后在 Web 浏览器中输入已编辑的 URL。 出现提示时,请输入群集的群集登录凭据。在 Jupyter 网页中,对于 Spark 2.4 群集,选择“新建”>“PySpark”,以创建笔记本。 对于 Spark 3.1 版本,请选择“新建”>“PySpark3”来创建笔记本,因为 Spark 3.1 中不再提供 PySpark 内核。
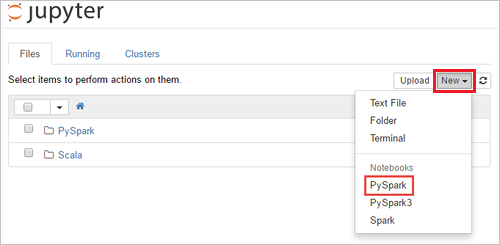
新笔记本随即创建,并以名称 Untitled(
Untitled.ipynb) 打开。注意
如果使用 PySpark 或 PySpark3 内核创建笔记本,在运行第一个代码单元时,系统会自动创建
spark会话。 不需要显式创建会话。
从 csv 文件创建数据帧
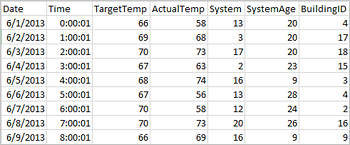
应用程序可以直接从远程存储(例如 Azure 存储或 Azure Data Lake Storage)上的文件或文件夹创建数据帧;从 Hive 表或从 Spark 支持的其他数据源(例如 Azure Cosmos DB、Azure SQL DB、DW 等)创建数据帧。 以下屏幕截图显示本教程中所用 HVAC.csv 文件的快照。 所有 HDInsight Spark 群集都随附了该 csv 文件。 该数据捕获了一些建筑物的温度变化。
在 Jupyter Notebook 的空单元格中粘贴以下代码,然后按 Shift+Enter 运行这些代码。 这些代码会导入此方案所需的类型:
from pyspark.sql import * from pyspark.sql.types import *在 Jupyter 中运行交互式查询时,Web 浏览器窗口或选项卡标题中会显示“(繁忙)”状态以及笔记本标题。 右上角“PySpark”文本的旁边还会出现一个实心圆。 作业完成后,实心圆将变成空心圆。
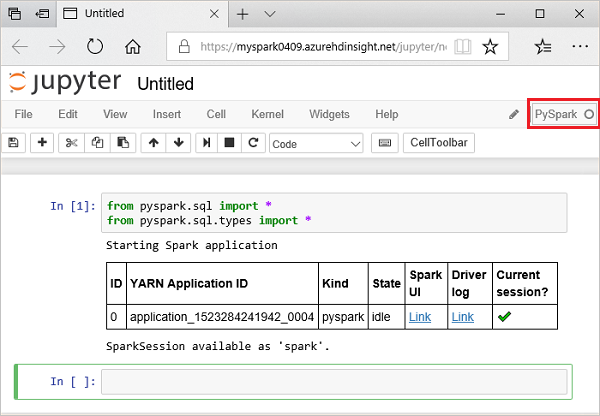
记下返回的会话 ID。 在上图中,会话 ID 为 0。 若要检索会话详细信息,可以根据需要导航到
https://CLUSTERNAME.azurehdinsight.cn/livy/sessions/ID/statements,其中的 CLUSTERNAME 是 Spark 群集的名称,ID 是会话 ID 号。运行以下代码,创建数据帧和临时表 (hvac) 。
# Create a dataframe and table from sample data csvFile = spark.read.csv('/HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv', header=True, inferSchema=True) csvFile.write.saveAsTable("hvac")
对 datanami 运行查询
创建表后,可以针对数据运行交互式查询。
在 Notebook 的空单元格中运行以下代码:
%%sql SELECT buildingID, (targettemp - actualtemp) AS temp_diff, date FROM hvac WHERE date = \"6/1/13\"以下表格输出随即显示。
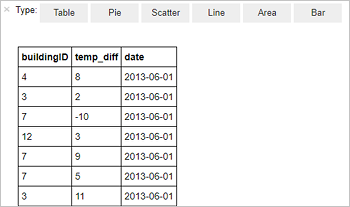
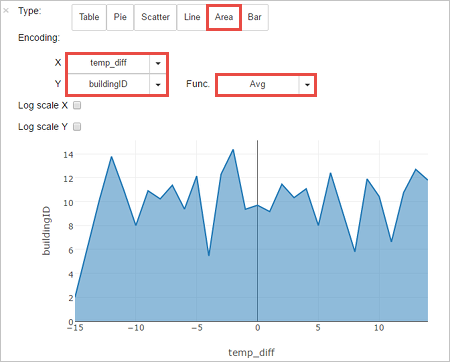
也可以在其他视觉效果中查看结果。 若要查看相同输出的面积图,请选择“面积” ,然后设置其他值,如下所示。
从笔记本菜单栏中,导航到“文件” >“保存和检查点” 。
如果现在开始下一教程,请使笔记本保持打开状态。 否则,请关闭笔记本以释放群集资源:从笔记本菜单栏,导航到“文件” >“关闭并停止” 。
清理资源
有了 HDInsight,便可以将数据和 Jupyter Notebook 存储在 Azure 存储或 Azure Data Lake Store 中,以便在不使用群集时安全地删除它。 此外,还需要为 HDInsight 群集付费,即使不用也是如此。 由于群集费用数倍于存储空间费用,因此在群集不用时删除群集可以节省费用。 如果打算立即开始学习下一教程,可能需要保留该群集。
在 Azure 门户中打开群集,然后选择“删除” 。
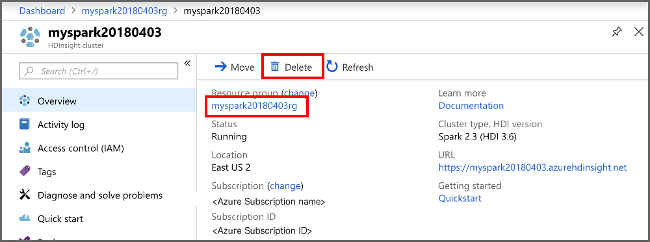
还可以选择资源组名称来打开“资源组”页,然后选择“删除资源组”。 通过删除资源组,可以删除 HDInsight Spark 群集和默认存储帐户。
后续步骤
本教程介绍如何从 csv 文件创建数据帧,以及如何针对 Azure HDInsight 中的 Apache Spark 群集运行交互式 Spark SQL 查询。 请转到下一篇文章,了解如何将在 Apache Spark 中注册的数据拉取到 Power BI 等 BI 分析工具中。