 Azure CLI ml 扩展 v2(当前)
Azure CLI ml 扩展 v2(当前)本文介绍如何使用 Azure 机器学习工作室和组件创建和运行机器学习管道。 无需使用组件即可创建管道,但组件可提供更好的灵活性和重用性。 可以在 YAML 中定义 Azure 机器学习管道,然后 从 Azure CLI 运行、 使用 Python 创作,或使用拖放 UI 在 Azure 机器学习工作室设计器中编写。 本文重点介绍 Azure 机器学习工作室设计器 UI。
先决条件
如果没有 Azure 订阅,请在开始前创建一个试用版订阅。 尝试试用版订阅。
一个 Azure 机器学习工作区。 创建工作区资源。
克隆示例存储库:
git clone https://github.com/Azure/azureml-examples --depth 1 cd azureml-examples/cli/jobs/pipelines-with-components/
注意
设计器支持两种类型的组件:经典预生成组件(v1)和自定义组件(v2)。 这两种类型的组件不兼容。
经典预生成组件主要为数据处理和传统的机器学习任务(如回归和分类)提供预生成组件。 经典预生成组件将继续受支持,但不会再添加任何新组件。 此外,经典预生成 (v1) 组件的部署不支持托管联机终结点 (v2)。
自定义组件允许以组件的形式包装自己的代码。 它支持跨工作区共享组件,并跨工作室、CLI v2 和 SDK v2 接口进行无缝创作。
对于新项目,强烈建议使用与 Azure 机器学习 V2 兼容的自定义组件,并接收新的更新。
本文适用于自定义组件。
在工作区中注册组件
若要使用设计器 UI 中的组件生成管道,需要先将组件注册到工作区。 可以使用 UI、Azure CLI 或 SDK 将组件注册到工作区,以便可以在工作区中共享和重用组件。 已注册的组件支持自动版本控制,以便可以更新组件,但确保需要较旧版本的管道可以继续工作。
以下示例使用 UI 注册组件。
组件源文件位于cli/jobs/pipelines-with-components/basics/1b_e2e_registered_components存储库的azureml-examples目录中。 需要克隆存储库。
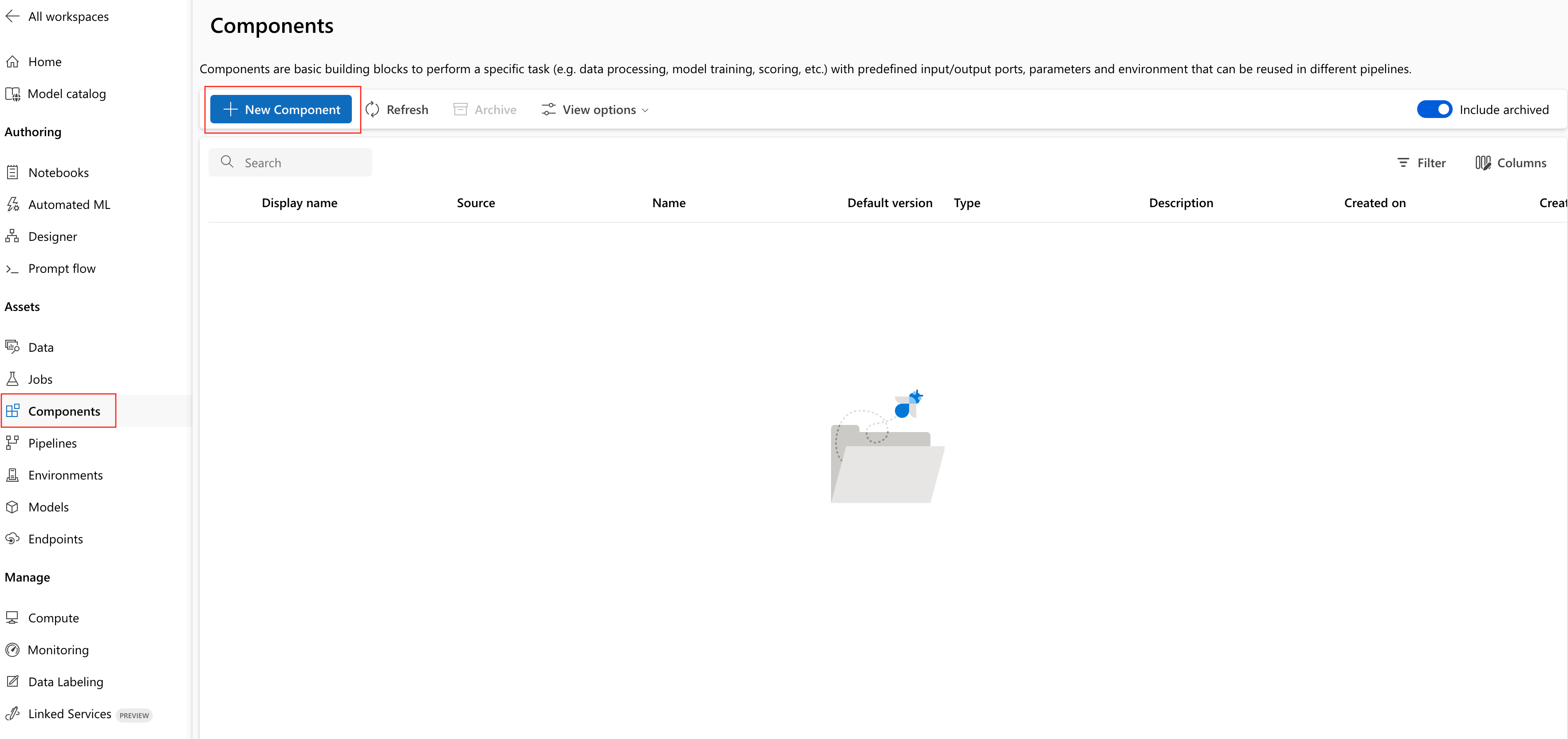
在 Azure 机器学习工作区中,导航到“组件”页面,然后选择“新建组件”。 组件页面的外观会因是否已创建组件而有所不同。
本示例使用
train.yml的 。 YAML 文件定义名称、类型、接口,包括此组件的输入和输出、代码、环境和命令。 此组件(train.py)的代码位于./train_src文件夹中。 该代码描述此组件的执行逻辑。 若要详细了解组件架构,请参阅命令组件 YAML 架构参考。注意
对于 UI 中的注册组件,组件 YAML 文件中定义的
code只能指向该 YAML 文件所在的当前文件夹或其子文件夹。 由于 UI 无法识别父目录,因此无法指定../。additional_includes只能指向当前文件夹或子文件夹。目前,UI 仅支持注册为
command类型的组件。选择 “文件夹”,然后浏览到
1b_e2e_registered_components要上传的文件夹。从
train.yml中选择 。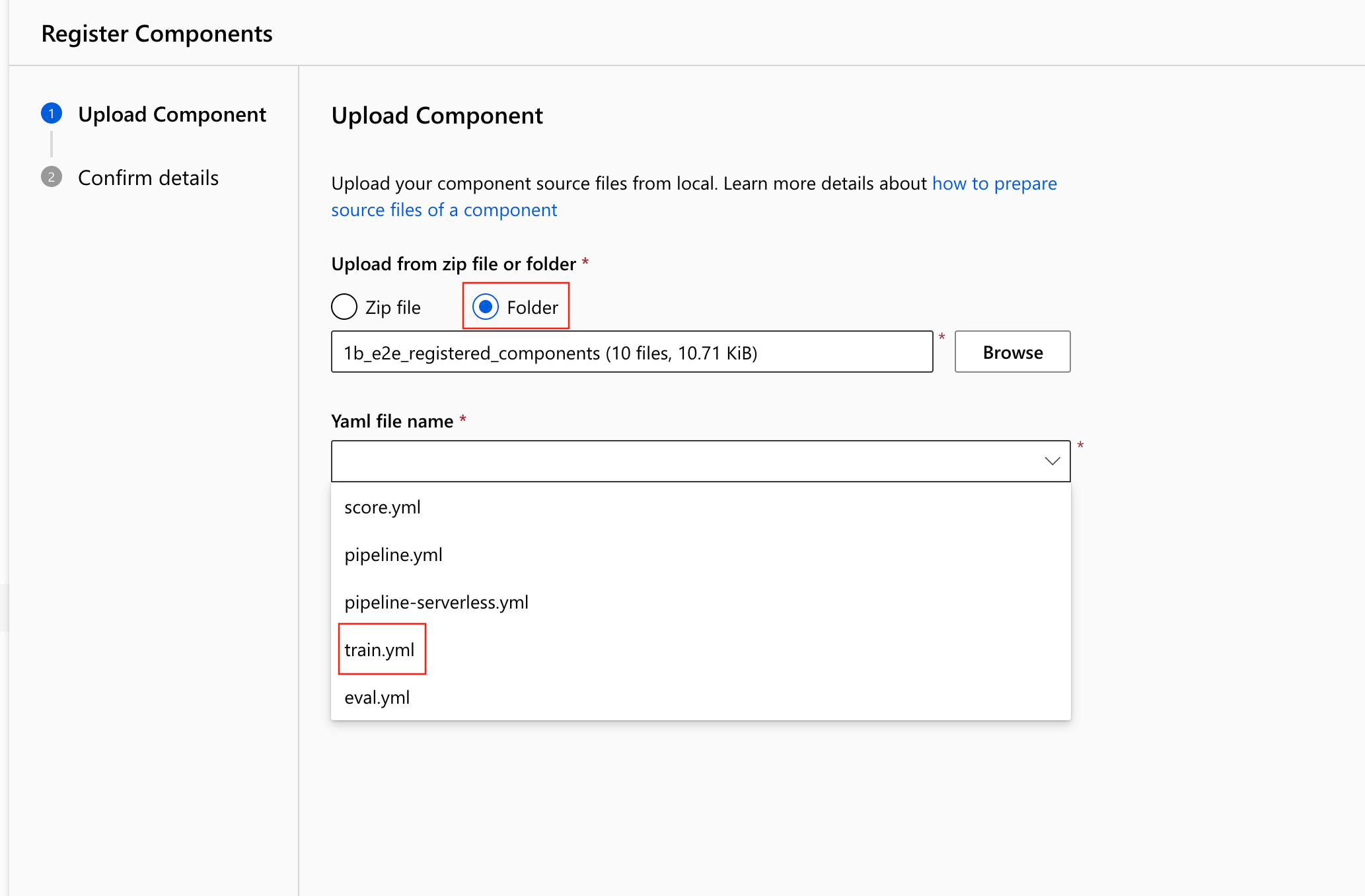
选择 “下一步”,然后确认此组件的详细信息。 确认后,选择“ 创建 ”以完成注册过程。
重复前面的步骤,使用
score.yml和eval.yml注册 Score 和 Eval 组件。成功注册这三个组件后,就可以在工作室 UI 中看到你的组件。




使用已注册组件创建管道
在设计器中创建新管道。 选择 “自定义 ”选项。
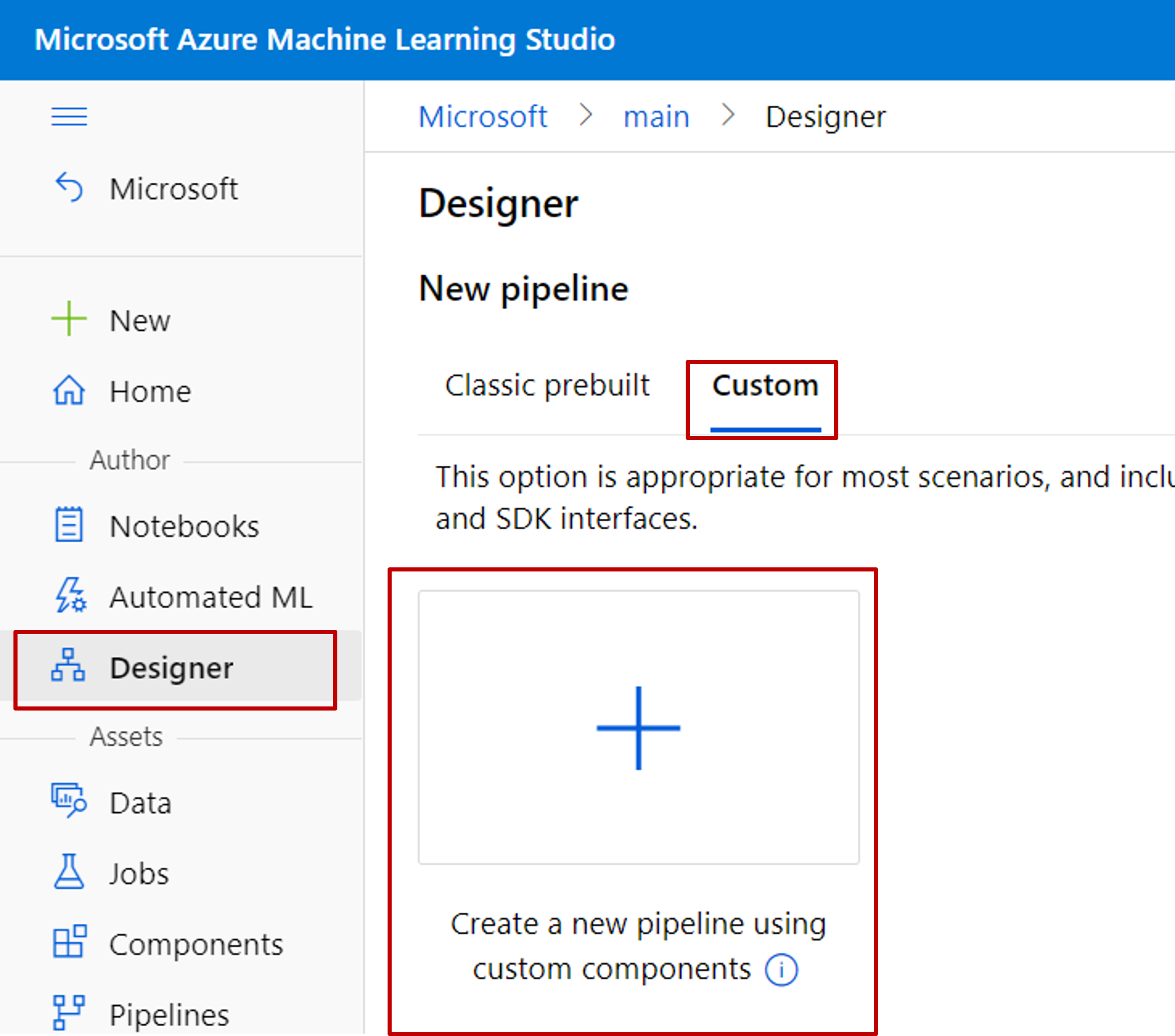
选择铅笔图标,为管道指定有意义的名称。
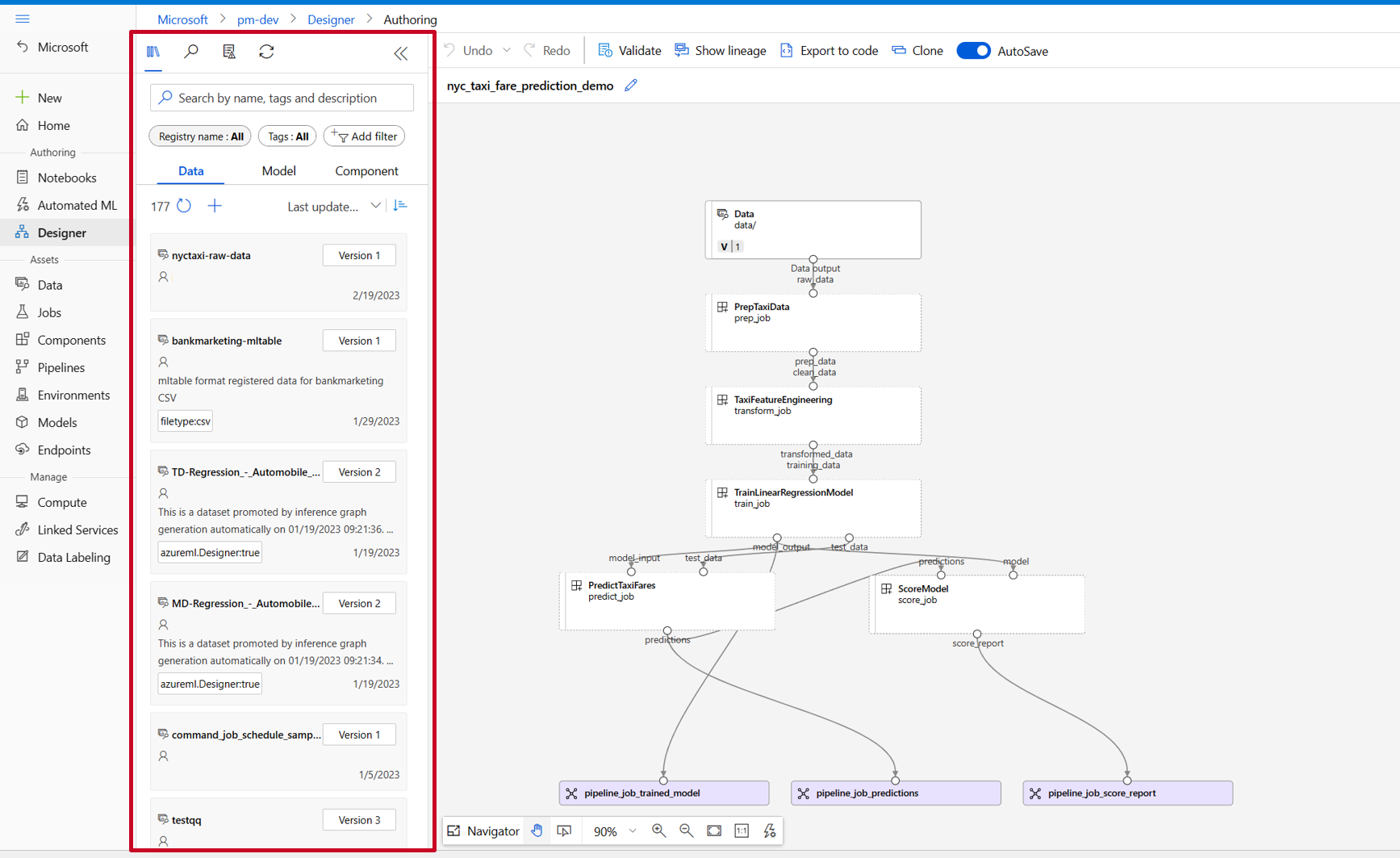
在设计器资产库中,可以看到 “数据”、“ 模型”和“ 组件 ”选项卡。 选择 “组件”。 可以看到从上一个章节注册的组件。 如果组件太多,可以使用组件名称进行搜索。
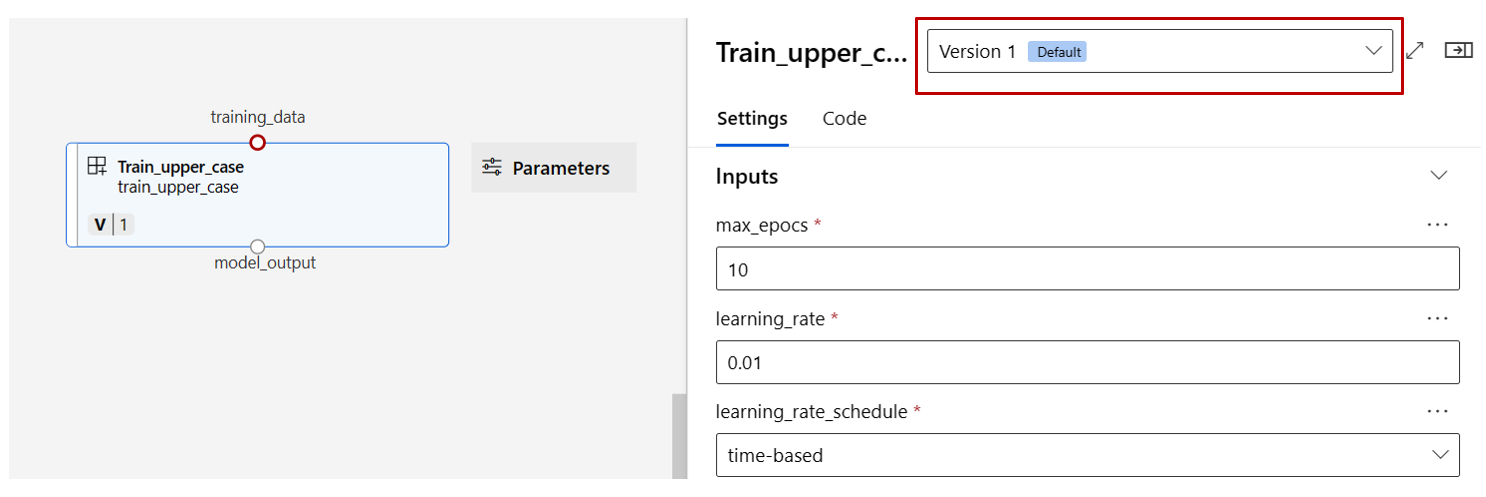
找到上一部分中注册的 训练、 评分和 评估 组件,然后将其拖到画布上。 默认情况下,设计器使用组件的默认版本。 若要更改为特定版本,请双击该组件以打开组件窗格。
在此示例中,使用 数据文件夹中的示例数据。 若要将数据注册到工作区,请选择资产库中的添加图标,然后按照向导注册数据。 数据类型需要是
uri_folder以与 训练组件定义 保持一致。
将数据拖动到画布中。 管道应如以下屏幕截图所示。
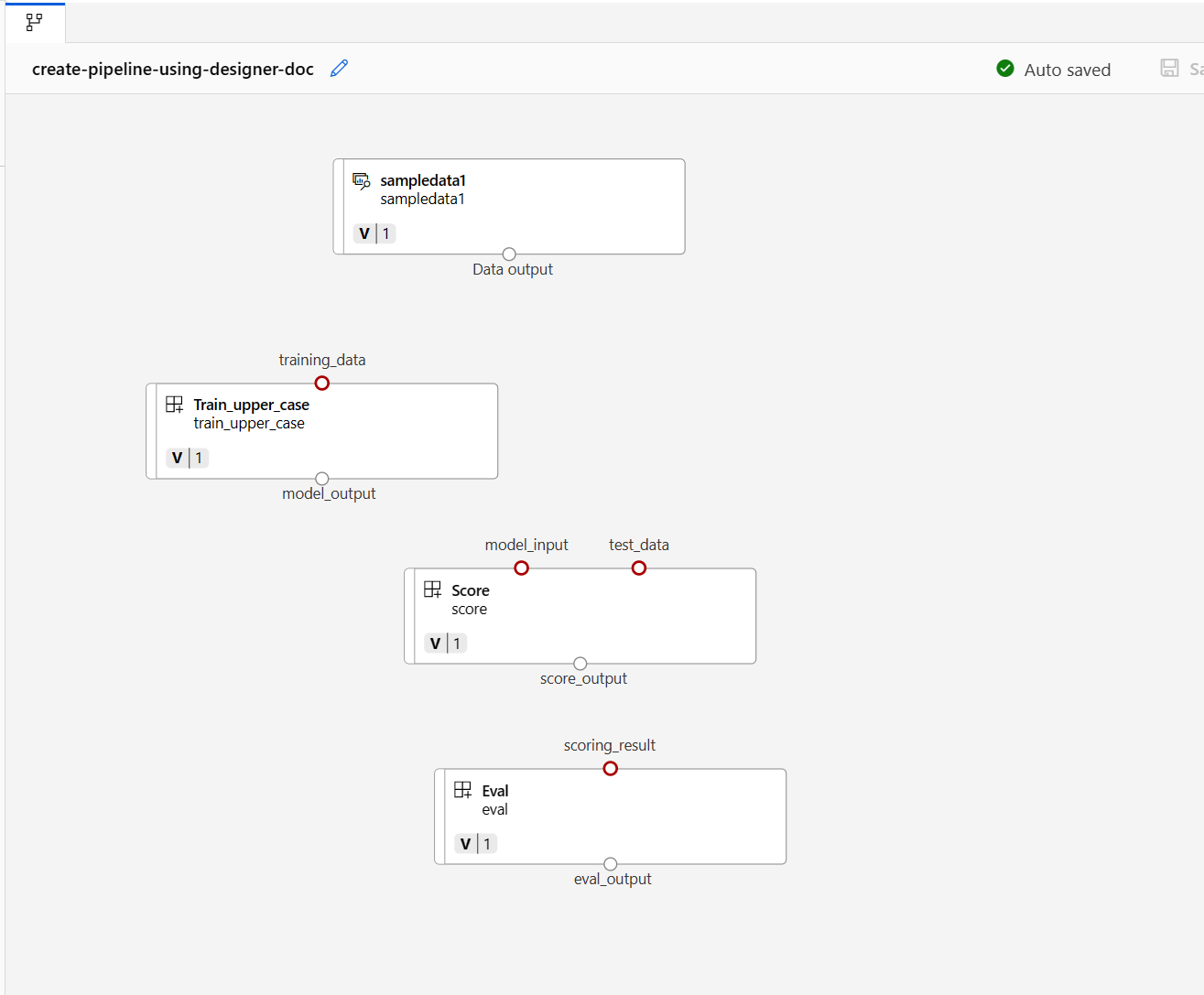
通过在画布面板中拖动连接来连接数据和组件。
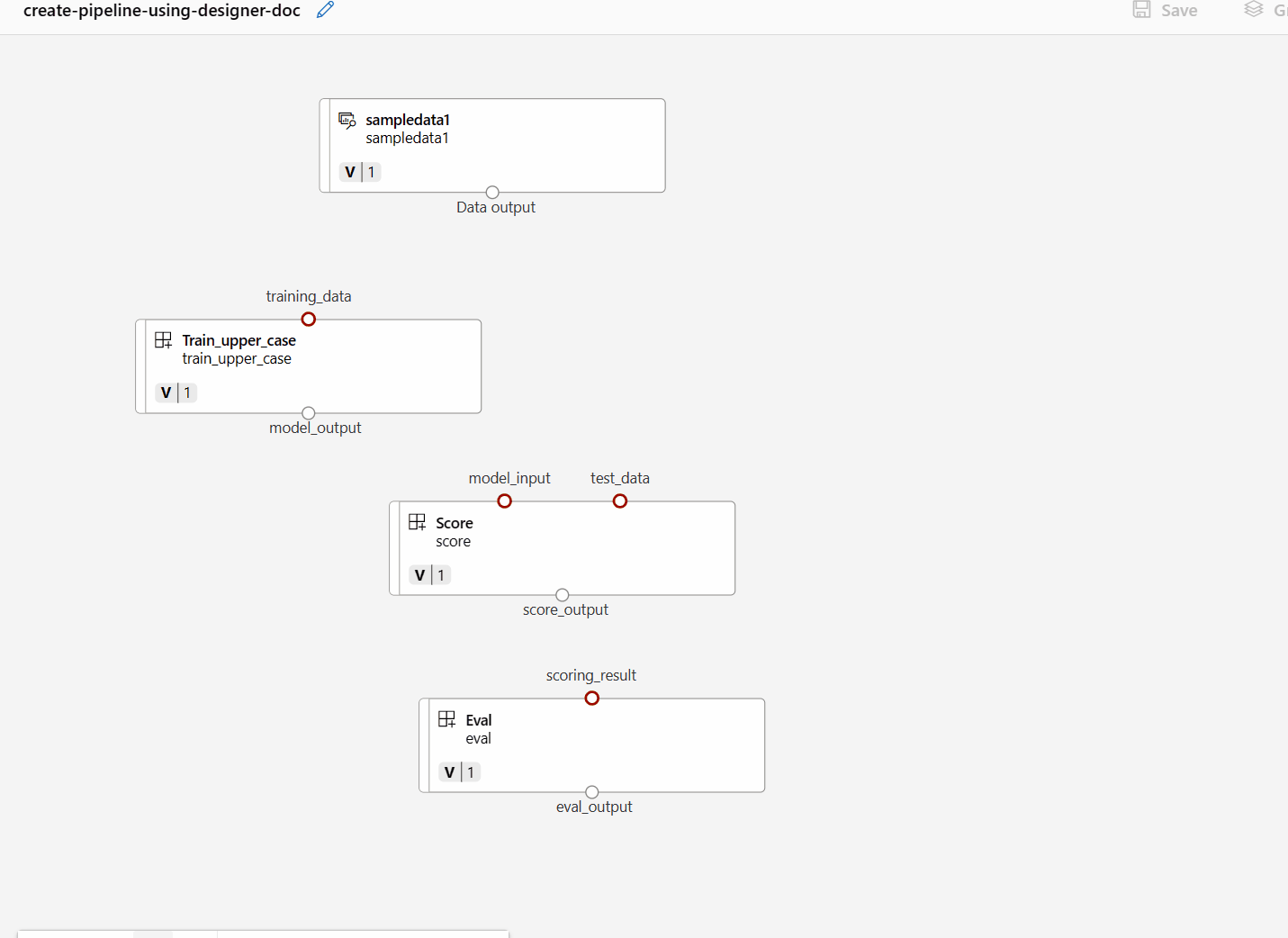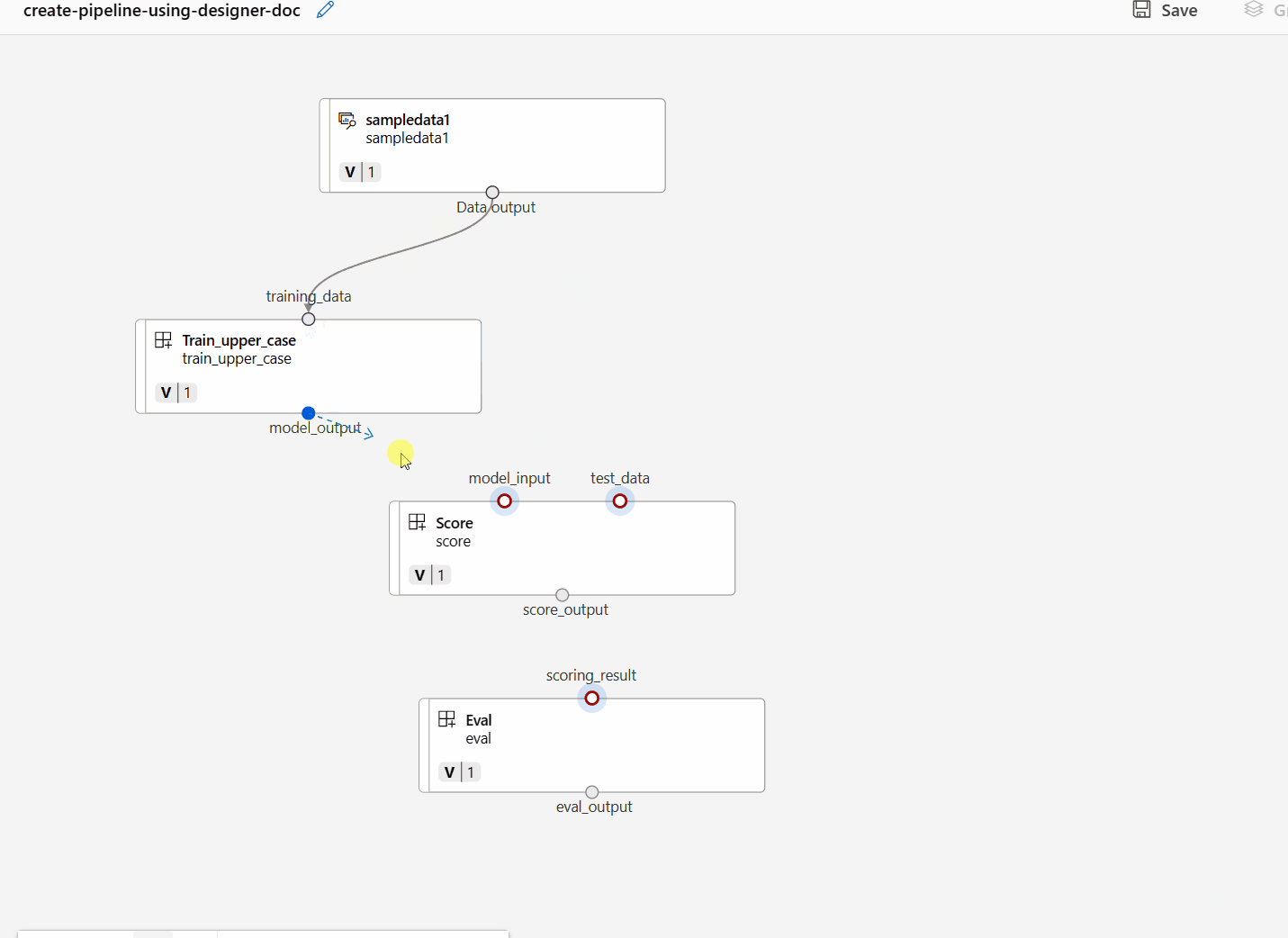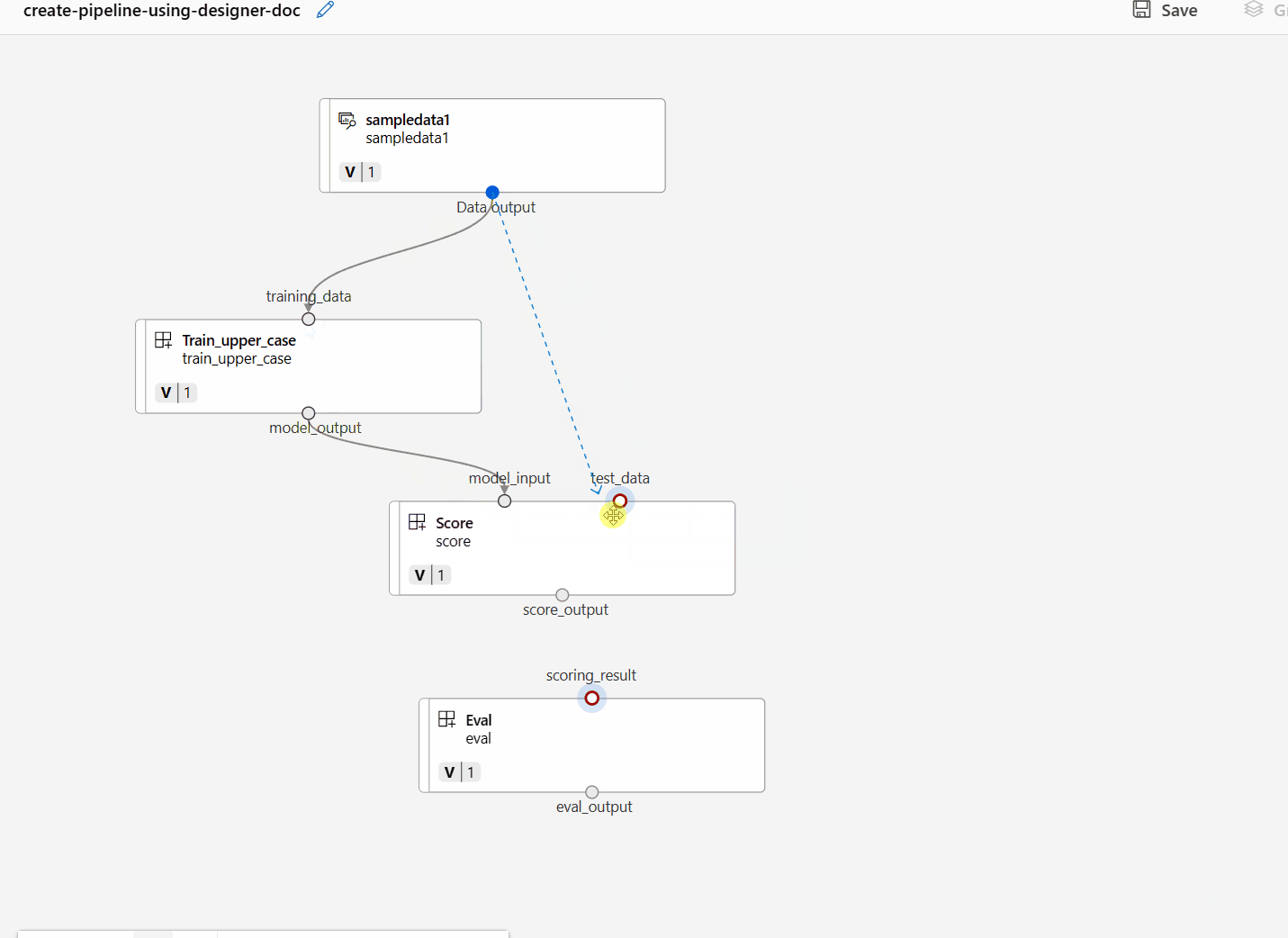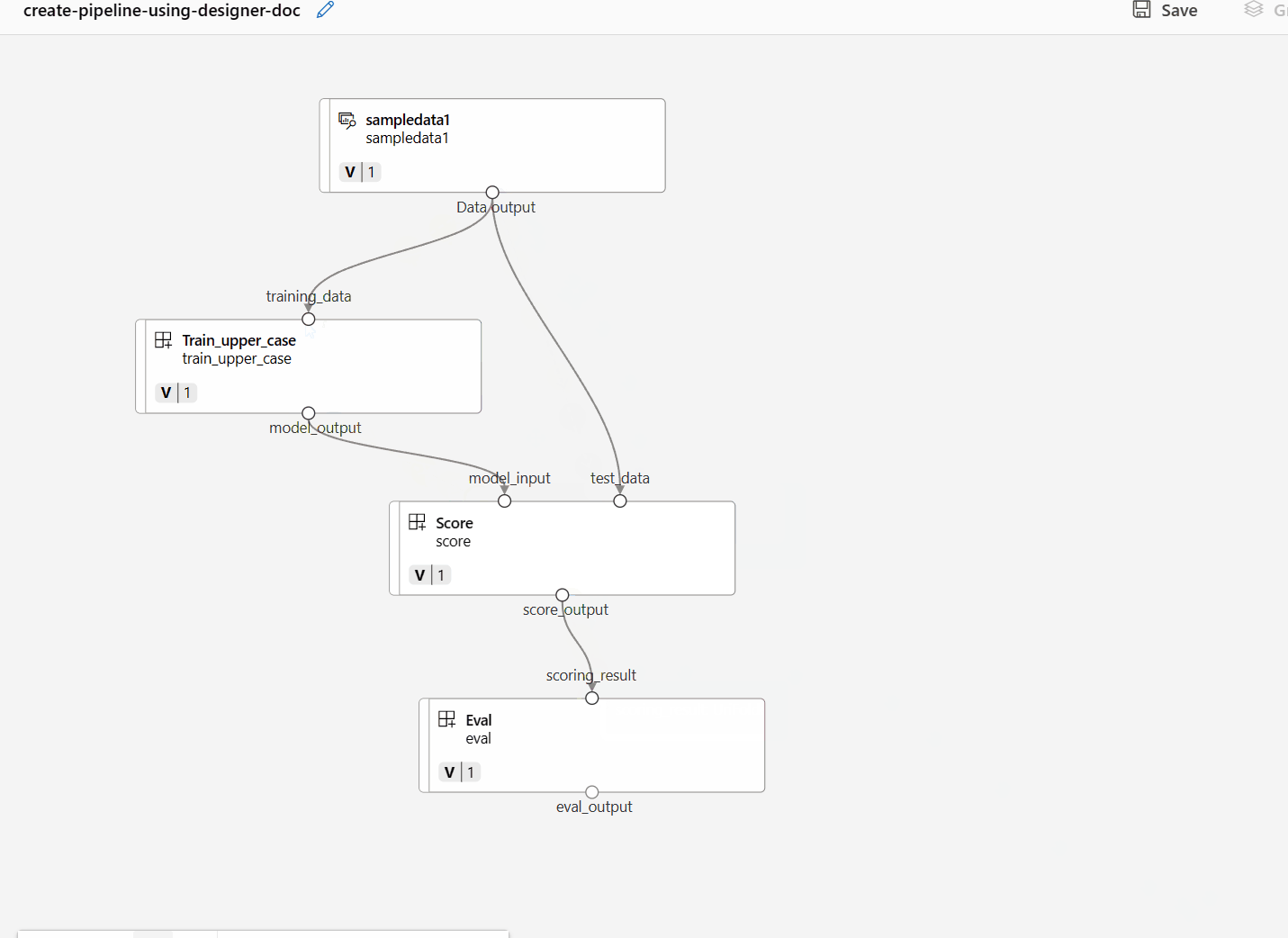
双击一个组件,你将看到一个右窗格,你可以在其中配置该组件。
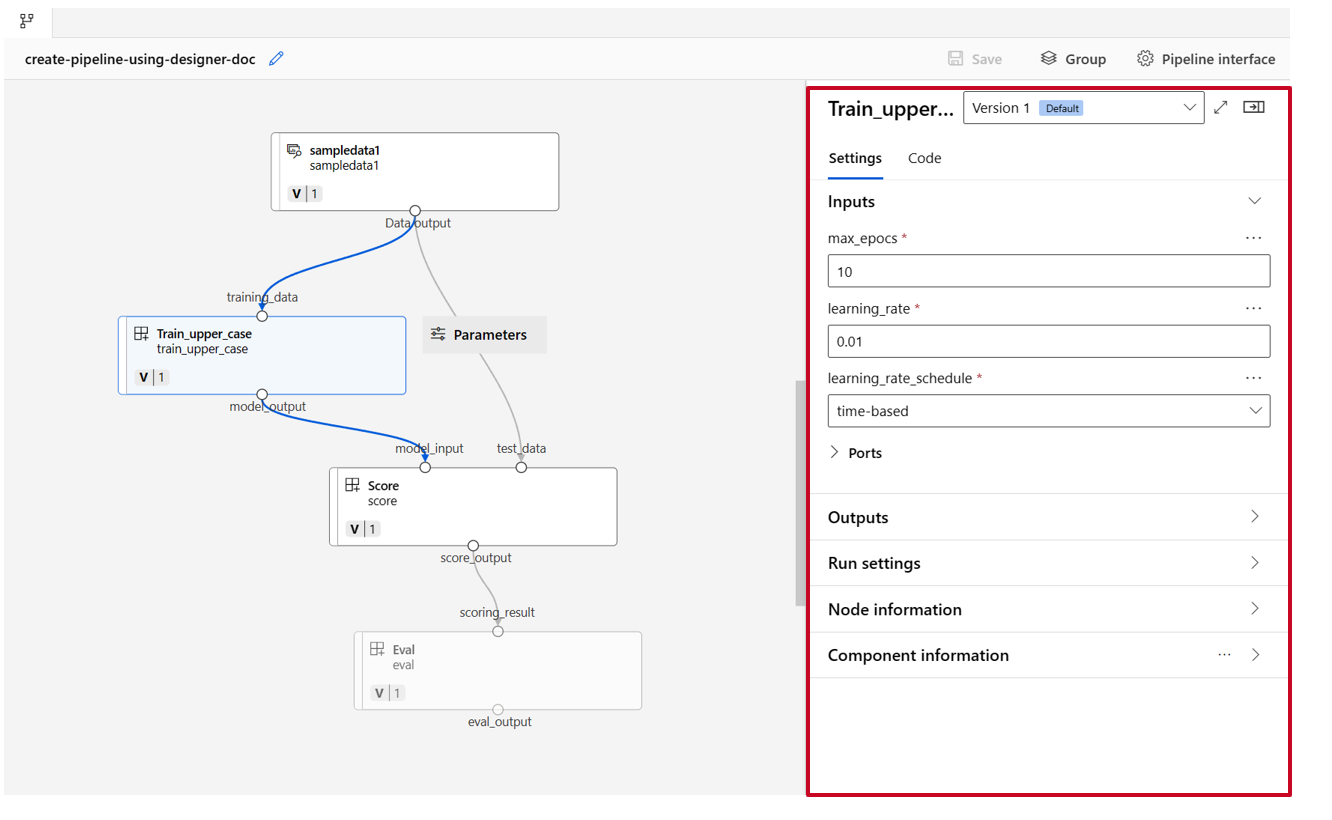
对于具有数字、整数、字符串和布尔值等基元类型输入的组件,你可以在“输入”部分的组件详细信息窗格中更改这些输入的值。
还可以在右窗格中更改输出设置(存储组件输出的位置),和运行设置(用于运行此组件的计算目标)。
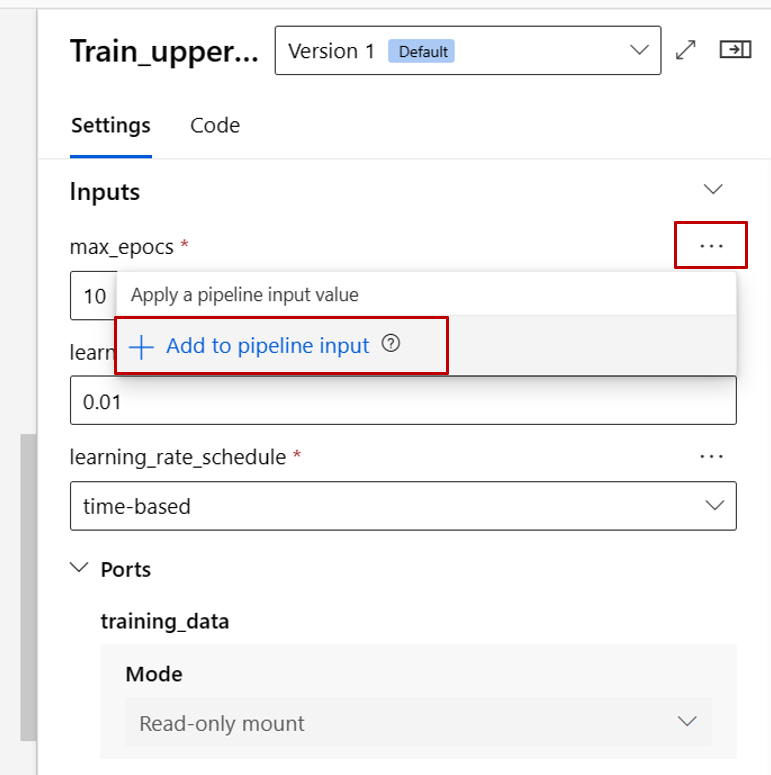
将训练组件的max_epocs输入升级为管道级输入。 这样做后,每次提交管道之前,都可以为此输入分配不同的值。









注意
自定义组件和设计器经典预生成组件不能一起使用。
提交管道
若要提交管道,请选择“ 配置和提交”。

然后你会看到一个分步向导。 按照向导提交管道作业。

在“基本信息”步骤中,可以配置试验、作业显示名称、作业说明等。
在“输入和输出”步骤中,可以配置提升到管道级别的输入/输出。 在上一步中,我们已将训练组件的 max_epocs 提升为管道输入,因此在此处应该能看到 max_epocs 并为其赋值。
在运行时设置中,可以配置管道的默认数据存储和默认计算。 它是管道中所有组件的默认数据存储/计算。 但请注意,如果显式为组件设置不同的计算或数据存储,系统将遵循组件级别设置。 否则,它使用管道默认值。
审阅 + 提交步骤是在提交之前审阅所有配置的最后一步。 如果曾经提交过管道,向导会记住你上次的配置。
提交管道作业后,顶部会显示一条消息,其中包含指向作业详细信息的链接。 你可以选择此链接来查看作业详细信息。

在管道作业中指定标识
提交管道作业时,可以指定用于访问Run settings数据的标识。 默认标识是AMLToken,它不使用任何标识。 管道也可以支持 UserIdentity 和 Managed。 对于 UserIdentity,将会使用作业提交者的标识来访问输入数据并将结果写入输出文件夹。 如果指定 Managed,系统将使用托管标识访问输入数据并将结果写入输出文件夹。

相关内容
- 使用这些 GitHub 上的 Jupyter 笔记本 进一步探索机器学习管道。
- 了解如何通过组件使用 CLI v2 创建管道。
- 了解如何使用 SDK v2 通过组件创建管道。