适用于: 适用于 Python 的 Azure 机器学习 SDK v1
适用于 Python 的 Azure 机器学习 SDK v1
重要
本文提供有关使用 Azure 机器学习 SDK v1 的信息。 SDK v1 自 2025 年 3 月 31 日起弃用。 对它的支持将于 2026 年 6 月 30 日结束。 可以在该日期之前安装和使用 SDK v1。 使用 SDK v1 的现有工作流将在支持结束日期后继续运行。 但是,在产品发生体系结构更改时,可能会面临安全风险或中断性变更。
建议在 2026 年 6 月 30 日之前过渡到 SDK v2。 有关 SDK v2 的详细信息,请参阅 什么是 Azure 机器学习 CLI 和 Python SDK v2? 以及 SDK v2 参考。
本文介绍在 Azure 机器学习 SDK 中使用 ParallelRunStep 出现错误时如何进行故障排除。
有关对管道进行故障排除的一般提示,请参阅对机器学习管道进行故障排除。
在本地测试脚本
ParallelRunStep 作为 ML 管道中的一个步骤运行。 你可能希望首先在本地测试脚本。
入口脚本要求
ParallelRunStep 的入口脚本必须包含run() 函数,还可以选择包含 init() 函数:
-
init():此函数适用于后续处理的任何成本高昂或常见的准备工作。 例如,使用它将模型加载到全局对象。 此函数仅在进程开始时调用一次。注意
如果
init方法创建输出目录,请指定parents=True和exist_ok=True。 每个运行该作业的节点上的每个工作进程都会调用init方法。 -
run(mini_batch):函数将针对每个mini_batch实例运行。-
mini_batch:ParallelRunStep将调用 run 方法,并将列表或 pandasDataFrame作为参数传递给该方法。 如果输入是FileDataset,则 mini_batch 中的每个条目可以是文件路径;如果输入是DataFrame,则每个条目可以是 pandasTabularDataset。 -
response:run() 方法应返回 pandasDataFrame或数组。 对于 append_row output_action,这些返回的元素将追加到公共输出文件中。 对于 summary_only,将忽略元素的内容。 对于所有的输出操作,每个返回的输出元素都指示输入微型批处理中输入元素的一次成功运行。 确保运行结果中包含足够的数据,以便将输入映射到运行输出结果。 运行输出写入到输出文件中,并且不保证按顺序写入,你应使用输出中某个键将其映射到输入。注意
一个输入元素应该对应一个输出元素。
-
%%writefile digit_identification.py
# Snippets from a sample script.
# Refer to the accompanying digit_identification.py
# (https://github.com/Azure/MachineLearningNotebooks/tree/master/how-to-use-azureml/machine-learning-pipelines/parallel-run)
# for the implementation script.
import os
import numpy as np
import tensorflow as tf
from PIL import Image
from azureml.core import Model
def init():
global g_tf_sess
# Pull down the model from the workspace
model_path = Model.get_model_path("mnist")
# Construct a graph to execute
tf.reset_default_graph()
saver = tf.train.import_meta_graph(os.path.join(model_path, 'mnist-tf.model.meta'))
g_tf_sess = tf.Session()
saver.restore(g_tf_sess, os.path.join(model_path, 'mnist-tf.model'))
def run(mini_batch):
print(f'run method start: {__file__}, run({mini_batch})')
resultList = []
in_tensor = g_tf_sess.graph.get_tensor_by_name("network/X:0")
output = g_tf_sess.graph.get_tensor_by_name("network/output/MatMul:0")
for image in mini_batch:
# Prepare each image
data = Image.open(image)
np_im = np.array(data).reshape((1, 784))
# Perform inference
inference_result = output.eval(feed_dict={in_tensor: np_im}, session=g_tf_sess)
# Find the best probability, and add it to the result list
best_result = np.argmax(inference_result)
resultList.append("{}: {}".format(os.path.basename(image), best_result))
return resultList
如果推理脚本所在的同一目录中包含另一个文件或文件夹,可以通过查找当前工作目录来引用此文件或文件夹。 如果要导入包,还可以将包文件夹追加到 sys.path。
script_dir = os.path.realpath(os.path.join(__file__, '..',))
file_path = os.path.join(script_dir, "<file_name>")
packages_dir = os.path.join(file_path, '<your_package_folder>')
if packages_dir not in sys.path:
sys.path.append(packages_dir)
from <your_package> import <your_class>
ParallelRunConfig 的参数
ParallelRunConfig 是 ParallelRunStep 实例在 Azure 机器学习管道中的主要配置。 使用它来包装脚本并配置所需的参数,包括所有以下条目:
entry_script:一个用户脚本,以本地文件路径形式存在,并将在多个节点上并行运行。 如果source_directory存在,则应使用相对路径。 否则,请使用计算机上可访问的任何路径。mini_batch_size:传递给单个run()调用的微型批处理的大小。 (可选;默认值对于10是FileDataset个文件,对应1MB是TabularDataset。)- 对于
FileDataset,它是最小值为1的文件数。 可以将多个文件合并成一个微型批处理。 - 对于
TabularDataset,它是数据的大小。 示例值为1024、1024KB、10MB和1GB。 建议值为1MB。TabularDataset中的微批永远不会跨越文件边界。 例如,如果有多个具有各种大小的 .csv 文件,则最小的文件为 100 KB,最大为 10 MB。 如果mini_batch_size = 1MB已设置,则小于 1 MB 的文件将被视为一个小型批处理,大于 1 MB 的文件将拆分为多个小型批处理。注意
不能对 SQL 支持的 TabularDataset 进行分区。 无法对单个 parquet 文件和单个行组中的 TabularDataset 进行分区。
- 对于
error_threshold:在处理过程中应忽略的TabularDataset记录失败数和FileDataset文件失败数。 整个输入的错误计数超出此值时,作业将中止。 错误阈值适用于整个输入,而不适用于发送给run()方法的单个微型批处理。 范围为[-1, int.max]。-1指示在处理过程中忽略所有失败。output_action:以下值之一指示输出的组织方式:-
summary_only:用户脚本需要存储输出文件。run()的输出仅用于错误阈值计算。 -
append_row:对于所有输入,ParallelRunStep会在输出文件夹中创建一个文件来追加所有按行分隔的输出。
-
append_row_file_name:用于自定义 append_row output_action 的输出文件名(可选;默认值为parallel_run_step.txt)。source_directory:文件夹的路径,这些文件夹包含要在计算目标上执行的所有文件(可选)。compute_target:仅支持AmlCompute。node_count:用于运行用户脚本的计算节点数。process_count_per_node:每个节点并行运行入口脚本的工作进程数。 对于 GPU 计算机,默认值为 1。 对于 CPU 计算机,默认值是每个节点的核心数。 工作进程通过传递作为参数获取的微型批处理来反复调用run()。 作业中的工作进程总数为process_count_per_node * node_count,这个数字决定了要并行执行的run()的最大数目。environment:Python 环境定义。 可以将其配置为使用现有的 Python 环境或设置临时环境。 定义还负责设置所需的应用程序依赖项(可选)。logging_level:日志详细程度。 递增详细程度的值为:WARNING、INFO和DEBUG。 (可选;默认值为INFO)run_invocation_timeout:run()方法调用超时(以秒为单位)。 (可选;默认值为60)run_max_try:微型批处理的run()的最大尝试次数。 如果引发异常,则run()失败;如果达到run_invocation_timeout,则不返回任何内容(可选;默认值为3)。
可以指定 mini_batch_size、node_count、process_count_per_node、logging_level、run_invocation_timeout 和 run_max_try 作为 PipelineParameter 以便在重新提交管道运行时,可以微调参数值。
CUDA 设备可见性
对于配备 GPU 的计算目标,会在工作进程中设置环境变量 CUDA_VISIBLE_DEVICES。 在 AmlCompute 中,可以在环境变量 AZ_BATCHAI_GPU_COUNT_FOUND 中查找 GPU设备的总数,它是自动设置的。 如果希望每个工作进程都有专用 GPU,请将 process_count_per_node 设置为等于计算机上 GPU 设备的数量。 然后,每个工作进程都会被分配一个唯一的 CUDA_VISIBLE_DEVICES 索引。 当工作进程因任何原因停止,下一个启动的工作进程会采用已发布的 GPU 索引。
当 GPU 设备总数小于 process_count_per_node 时,可以向具有较小索引的工作进程分配 GPU 索引,直到所有 GPU 被占用。
假设 GPU 设备总数为 2,并以 process_count_per_node = 4 为例,进程 0 和进程 1 会接收索引 0 和 1。 进程 2 和 3 没有环境变量。 对于使用此环境变量进行 GPU 分配的库,进程 2 和 3 将不会有 GPU,也不会尝试获取 GPU 设备。 进程 0 在停止时释放 GPU 索引 0。 下一个进程(如果适用),即进程 4,将会被分配 GPU 索引 0。
有关详细信息,请参阅 CUDA Pro 提示:使用CUDA_VISIBLE_DEVICES 控制 GPU 可见性。
用于创建 ParallelRunStep 的参数
使用脚本、环境配置和参数创建 ParallelRunStep。 将已附加到工作区的计算目标指定为推理脚本的执行目标。 使用 ParallelRunStep 创建批处理推理管道步骤,该步骤采用以下所有参数:
-
name:步骤的名称,但具有以下命名限制:唯一、3-32 个字符和正则表达式 ^[a-z]([-a-z0-9]*[a-z0-9])?$。 -
parallel_run_config:ParallelRunConfig对象,如前文所述。 -
inputs:要分区以进行并行处理的一个或多个单类型 Azure 机器学习数据集。 -
side_inputs:无需分区就可以用作辅助输入的一个或多个参考数据或数据集。 -
output:一个OutputFileDatasetConfig对象,代表应存储输出数据的目录路径。 -
arguments:传递给用户脚本的参数列表。 使用 unknown_args 在入口脚本中检索它们(可选)。 -
allow_reuse:当使用相同的设置/输入运行时,该步骤是否应重用以前的结果。 如果此参数为False,则在管道执行过程中将始终为此步骤生成新的运行。 (可选;默认值为True。)
from azureml.pipeline.steps import ParallelRunStep
parallelrun_step = ParallelRunStep(
name="predict-digits-mnist",
parallel_run_config=parallel_run_config,
inputs=[input_mnist_ds_consumption],
output=output_dir,
allow_reuse=True
)
从远程上下文调试脚本
要实现从在本地调试评分脚本到在实际管道中调试评分脚本这一飞跃可能很困难。 若要了解如何在门户中查找日志,请参阅有关从远程上下文调试脚本的机器学习管道部分。 该部分中的信息也适用于 ParallelRunStep。
由于 ParallelRunStep 作业具有分布式特性,因此存在来自多个不同源的日志。 但是,会创建两个合并文件来提供高级信息:
~/logs/job_progress_overview.txt:此文件提供了有关到目前为止已创建的微型批处理数(也称为任务数)以及已处理的微型批处理数的高级信息。 最后,它会显示作业的结果。 如果作业失败,它会显示错误消息以及开始进行故障排除的位置。~/logs/job_result.txt:它显示作业的结果。 如果作业失败,它会显示错误消息以及开始进行故障排除的位置。~/logs/job_error.txt:此文件汇总了脚本中的错误。~/logs/sys/master_role.txt:此文件提供运行中作业的主节点(也称为业务流程协调程序)视图。 包括任务创建、进度监视和运行结果。~/logs/sys/job_report/processed_mini-batches.csv:一个包含所有已处理完毕的小批次数据的表格。 显示每次运行的小批处理结果、其执行代理节点 ID 和进程名称。 此外,还包括已用时间和错误消息。 可以通过节点 ID 和进程名称找到每次小批量数据处理的运行日志。
使用 EntryScript 帮助程序和 print 语句,通过入口脚本生成的日志显示在以下文件中:
~/logs/user/entry_script_log/<node_id>/<process_name>.log.txt:这些文件是使用 EntryScript 帮助程序从 entry_script 写入的日志。~/logs/user/stdout/<node_id>/<process_name>.stdout.txt:这些文件是 entry_script 的 stdout(例如,print 语句)的日志。~/logs/user/stderr/<node_id>/<process_name>.stderr.txt:这些文件是 entry_script 的 stderr 的日志。
例如,屏幕截图显示节点 0 process001 上的微型批处理 0 失败。 可以在 ~/logs/user/entry_script_log/0/process001.log.txt、~/logs/user/stdout/0/process001.log.txt 和 ~/logs/user/stderr/0/process001.log.txt 中找到输入脚本的相应日志
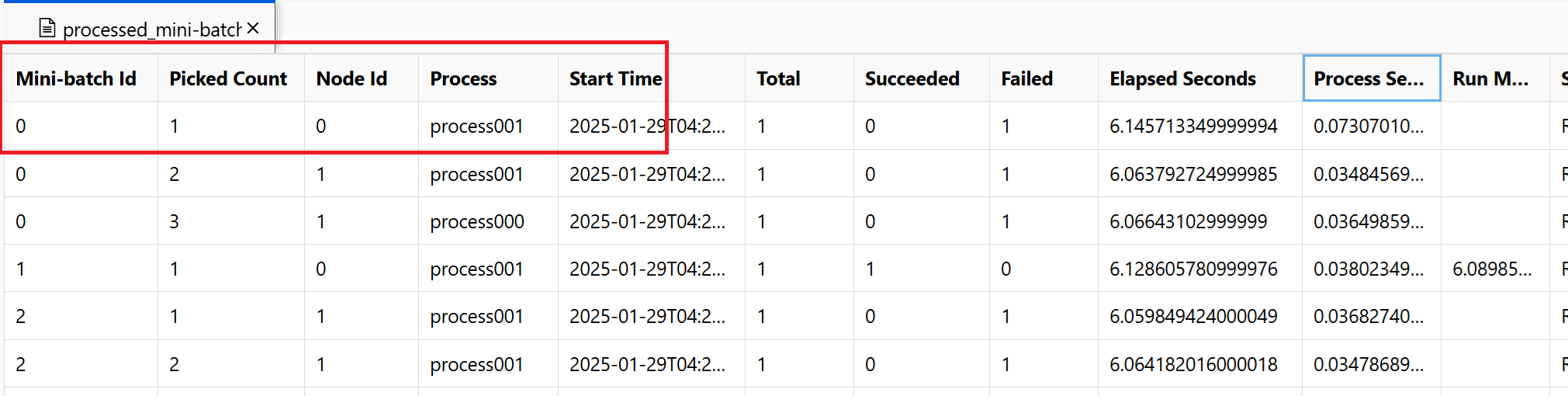
如需全面了解每个节点如何执行评分脚本,请查看每个节点单独的进程日志。 进程日志位于 ~/logs/sys/node 文件夹中,按工作器节点分组:
~/logs/sys/node/<node_id>/<process_name>.txt:此文件提供了有关每个由工人选取或完成的小批次的详细信息。 对于每个微型批处理,此文件包括以下内容:- 工作进程的 IP 地址和 PID。
- 总项数、成功处理的项计数和失败的项计数。
- 开始时间、持续时间、处理时间和运行方法时间。
你还可以查看每个节点的资源使用情况的定期检查结果。 日志文件和安装程序文件位于以下文件夹中:
~/logs/perf:设置--resource_monitor_interval以更改检查时间间隔(以秒为单位)。 默认时间间隔为600,约为 10 分钟。 若要停止监视,请将值设置为0。 每个<node_id>文件夹包括:-
os/:节点中所有正在运行的进程的相关信息。 一项检查将运行一个操作系统命令,并将结果保存到文件。 在 Linux 上,该命令为ps。 在 Windows 上,请使用tasklist。-
%Y%m%d%H:子文件夹名称是到精确到小时的时间。-
processes_%M:文件名以检查时间的分钟结束。
-
-
-
node_disk_usage.csv:节点的详细磁盘使用情况。 -
node_resource_usage.csv:节点的资源使用情况概述。 -
processes_resource_usage.csv:每个进程的资源使用情况概述。
-
常见作业失败原因
SystemExit:42
退出码 41 和 42 是 PRS 设计的退出代码。 工作器节点以代码 41 退出,通知计算管理器其已独立终止。 这符合预期。 领导节点可能以表示作业结果的代码 0 或 42 退出。 退出码 42 表示作业失败。 失败原因可在 ~/logs/job_result.txt 中找到。 你可以根据上一节内容来调试作业。
数据权限
作业错误表示计算无法访问输入数据。 如果您的计算群集和存储使用基于标识的身份验证,请参考《基于标识的数据身份验证》。
进程意外终止
由于意外或未经处理的异常,进程可能会崩溃,系统会因“内存不足”异常而终止进程。 在 PRS 系统日志 ~/logs/sys/node/<node-id>/_main.txt 中,可以找到如下所示的错误。
<process-name> exits with returncode -9.
内存不足
~/logs/perf 记录进程的计算资源消耗。 可以找到每个任务处理器的内存使用情况。 你可以估计节点上的总内存使用量。
“内存不足”错误可在 ~/system_logs/lifecycler/<node-id>/execution-wrapper.txt 中找到。
如果计算资源接近限制,则建议减少每个节点的进程数或升级 VM 大小。
未经处理的异常
在某些情况下,Python 进程无法捕获失败的堆栈。 你可以添加环境变量 env["PYTHONFAULTHANDLER"]="true" 以启用 Python 的内置故障处理程序。
微型批处理超时
你可以根据小批数据任务调整 run_invocation_timeout 参数。 如果 run() 函数花费的时间比预期多时,请参考下文的提示。
检查微型批处理的已用时间和处理时间。 进程时间测量进程的 CPU 时间。 当进程时间明显少于经过的时间时,你可以检查任务中是否存在一些繁重的 IO 操作或网络请求。 这些作业的长时间延迟是小批数据处理超时的常见原因。
一些特定的小批量所需时间比其他的更长。 你可以更新配置,或尝试使用输入数据来平衡小批数据的处理时间。
如何从远程上下文中的用户脚本记录?
ParallelRunStep 可以基于 process_count_per_node 在一个节点上运行多个进程。 为了组织节点上每个进程的日志并结合 print 和 log 语句,建议使用 ParallelRunStep 记录器,如下所示。 从 EntryScript 获取记录器,使日志显示在门户的 logs/user 文件夹中。
使用记录器的示例入口脚本:
from azureml_user.parallel_run import EntryScript
def init():
"""Init once in a worker process."""
entry_script = EntryScript()
logger = entry_script.logger
logger.info("This will show up in files under logs/user on the Azure portal.")
def run(mini_batch):
"""Call once for a mini batch. Accept and return the list back."""
# This class is in singleton pattern. It returns the same instance as the one in init()
entry_script = EntryScript()
logger = entry_script.logger
logger.info(f"{__file__}: {mini_batch}.")
...
return mini_batch
消息从 Python logging 发送到何处?
ParallelRunStep 会在根记录器上设置一个处理程序,该程序可将消息发送到 logs/user/stdout/<node_id>/processNNN.stdout.txt。
logging 默认为 INFO 级别。 默认情况下,以下级别 INFO 不会显示,例如 DEBUG。
如何写入到文件,以便在门户中显示?
写入 /logs 文件夹的文件将被上传并显示在门户中。
你可以获得如下所示的文件夹 logs/user/entry_script_log/<node_id> 并编写要写入的文件路径:
from pathlib import Path
from azureml_user.parallel_run import EntryScript
def init():
"""Init once in a worker process."""
entry_script = EntryScript()
log_dir = entry_script.log_dir
log_dir = Path(entry_script.log_dir) # logs/user/entry_script_log/<node_id>/.
log_dir.mkdir(parents=True, exist_ok=True) # Create the folder if not existing.
proc_name = entry_script.agent_name # The process name in pattern "processNNN".
fil_path = log_dir / f"{proc_name}_<file_name>" # Avoid conflicting among worker processes with proc_name.
如何处理新进程中的日志?
可以通过 subprocess 模块在入口脚本中生成新进程,连接到其输入/输出/错误管道并获取其返回代码。
建议的方法是在 run() 中使用 capture_output=True 函数。 错误显示在 logs/user/error/<node_id>/<process_name>.txt 中。
如果要使用 Popen(),stdout/stderr 应重定向到文件,例如:
from pathlib import Path
from subprocess import Popen
from azureml_user.parallel_run import EntryScript
def init():
"""Show how to redirect stdout/stderr to files in logs/user/entry_script_log/<node_id>/."""
entry_script = EntryScript()
proc_name = entry_script.agent_name # The process name in pattern "processNNN".
log_dir = Path(entry_script.log_dir) # logs/user/entry_script_log/<node_id>/.
log_dir.mkdir(parents=True, exist_ok=True) # Create the folder if not existing.
stdout_file = str(log_dir / f"{proc_name}_demo_stdout.txt")
stderr_file = str(log_dir / f"{proc_name}_demo_stderr.txt")
proc = Popen(
["...")],
stdout=open(stdout_file, "w"),
stderr=open(stderr_file, "w"),
# ...
)
注意
一个工作进程在同一进程中运行“系统”代码和条目脚本代码。
如果 stdout 或 stderr 未指定,则工作进程设置将由在入口脚本中使用 Popen() 创建的子进程继承。
stdout 写入到 ~/logs/sys/node/<node_id>/processNNN.stdout.txt,stderr 写入到 ~/logs/sys/node/<node_id>/processNNN.stderr.txt。
如何将文件写入到输出目录,然后在门户中查看它?
可以从 EntryScript 类获取输出目录并写入到该目录。 若要查看写入的文件,请在 Azure 机器学习门户中的“单步运行”视图中,选择“输出 + 日志”选项卡。选择“数据输出”链接,然后完成对话框中所述的步骤 。
在入口脚本中使用 EntryScript,如以下示例所示:
from pathlib import Path
from azureml_user.parallel_run import EntryScript
def run(mini_batch):
output_dir = Path(entry_script.output_dir)
(Path(output_dir) / res1).write...
(Path(output_dir) / res2).write...
如何将端输入(如包含查找表的一个或多个文件)传递到所有工作器?
用户可以使用 ParalleRunStep 的 side_inputs 参数将引用数据传递给脚本。 作为侧输入提供的所有数据集会装载到每个工作节点上。 用户可以通过传递参数获取装载的位置。
构造一个包含参考数据的数据集,指定本地装载路径并将其注册到工作区。 将其传递到 side_inputs 的 ParallelRunStep 参数。 此外,还可以在 arguments 部分中添加其路径,以便轻松访问其已装载的路径。
注意
FileDataset 只用于 side_inputs。
local_path = "/tmp/{}".format(str(uuid.uuid4()))
label_config = label_ds.as_named_input("labels_input").as_mount(local_path)
batch_score_step = ParallelRunStep(
name=parallel_step_name,
inputs=[input_images.as_named_input("input_images")],
output=output_dir,
arguments=["--labels_dir", label_config],
side_inputs=[label_config],
parallel_run_config=parallel_run_config,
)
之后,可以在脚本中访问它(例如在 init() 方法中),如下所示:
parser = argparse.ArgumentParser()
parser.add_argument('--labels_dir', dest="labels_dir", required=True)
args, _ = parser.parse_known_args()
labels_path = args.labels_dir
如何通过服务主体身份验证使用输入数据集?
用户可以通过工作区中使用的服务主体身份验证传递输入数据集。 若要在 ParallelRunStep 中使用此类数据集,需要为其注册该数据集以构造 ParallelRunStep 配置。
service_principal = ServicePrincipalAuthentication(
tenant_id="***",
service_principal_id="***",
service_principal_password="***")
ws = Workspace(
subscription_id="***",
resource_group="***",
workspace_name="***",
auth=service_principal
)
default_blob_store = ws.get_default_datastore() # or Datastore(ws, '***datastore-name***')
ds = Dataset.File.from_files(default_blob_store, '**path***')
registered_ds = ds.register(ws, '***dataset-name***', create_new_version=True)
如何检查进度和分析进度
本部分介绍如何检查 ParallelRunStep 作业的进度并检查意外行为的原因。
如何检查作业进度?
在 ~/logs/job_progress_overview.<timestamp>.txt 中,除了可以查看 StepRun 的总体状态外,还可以查看已计划的/已处理的微型批的计数以及生成输出的进度。 该文件每天轮换。 你可以检查时间戳最大的文件,以了解最新信息。
如果一段时间没有进度,应该检查什么?
可以转到 ~/logs/sys/error 查看是否有异常。 如果没有,则有可能是因为输入脚本耗时较长,你可以在代码中输出进度信息,以查找耗时部分,或将 "--profiling_module", "cProfile" 添加到 arguments 的 ParallelRunStep,以便在 <process_name>.profile 文件夹下生成名为 ~/logs/sys/node/<node_id> 的配置文件。
作业将何时运行?
如果未取消,则该作业可能会停止,状态为:
- 已完成。 所有微型批处理都已成功处理,并生成
append_row模式的输出。 - 已失败。 如果已超出
error_threshold中的Parameters for ParallelRunConfig,或在作业期间发生了系统错误。
在哪里查找到失败的根本原因?
可以按照 ~/logs/job_result.txt 中的线索来查找原因和详细的错误日志。
节点故障是否会影响作业结果?
如果在指定的计算群集中有其他可用节点,则不会影响。 ParallelRunStep 可以在每个节点上独立运行。 单节点故障不会使整个作业失败。
如果入口脚本中的 init 函数失败,会发生什么情况?
ParallelRunStep 具有一个重试机制,在限定时间内重试多次,以便在不延迟作业失败时间的前提下保证从暂时性问题中恢复。 机制如下:
- 如果在节点启动后,所有代理上的
init仍然失败,我们将会在发生3 * process_count_per_node次故障后停止尝试。 - 如果在作业启动后,所有节点的所有代理上的
init都继续失败,我们将在作业运行时间超过 2 分钟并且出现2 * node_count * process_count_per_node次故障后停止尝试。 - 如果所有代理都在
init上停滞超过3 * run_invocation_timeout + 30秒,则该作业会由于长时间没有进度而失败。
OutOfMemory 会发生什么情况? 如何检查原因?
进程可能由系统终止。 ParallelRunStep 会将当前用于处理微型批的尝试设置为失败状态,并尝试重启失败的进程。 可以检查 ~logs/perf/<node_id> 以查找消耗内存的进程。
为什么有多个 processNNN 文件?
ParallelRunStep 启动新的工作进程,以替换异常退出的进程。 每个进程都会生成一组 processNNN 文件作为日志。 但是,如果该进程由于用户脚本的 init 函数期间出现异常而失败,并且该错误持续重复 3 * process_count_per_node 次,则不会启动新工作进程。
后续步骤
请查看 SDK 参考,获取有关 azureml-pipeline-steps 包的帮助。
按照高级教程操作,将管道与 ParallelRunStep 配合使用。 本教程演示如何将另一个文件作为旁路输入。