将模型部署到 Azure Kubernetes 服务群集
了解如何使用 Azure 机器学习将模型部署为 Azure Kubernetes 服务 (AKS) 中的 Web 服务。 Azure Kubernetes 服务适用于大规模的生产部署。 如果需要以下一项或多项功能,请使用 Azure Kubernetes 服务:
- 快速响应时间
- 自动缩放已部署的服务
- Logging
- 模型数据集合
- 身份验证
- TLS 终止
- 硬件加速选项,例如 GPU 和现场可编程门阵列 (FPGA)
部署到 Azure Kubernetes 服务时,将部署到连接到工作区的 AKS 群集。 有关将 AKS 群集连接到工作区的信息,请参阅创建并附加 Azure Kubernetes 服务群集。
注意
Azure 机器学习终结点 (v2) 提供了经过改进的简化部署体验。 终结点同时支持实时和批量推理场景。 终结点提供了一个统一的接口,以用于跨计算类型调用和管理模型部署。 请参阅什么是 Azure 机器学习终结点?。
先决条件
Azure 机器学习工作区。 有关详细信息,请参阅创建 Azure 机器学习工作区。
工作区中注册的机器学习模型。 如果尚未注册模型,请参阅部署模型的方式和位置。
机器学习服务的 Azure CLI 扩展 (v1)、Azure 机器学习 Python SDK 或 Azure 机器学习 Visual Studio Code 扩展。
本文中的 Python 代码片段假设设置了以下变量:
ws- 设置为工作区。model- 设置为注册的模型。inference_config- 设置为模型的推理配置。
有关如何设置这些变量的详细信息,请参阅部署模型的方式和位置。
本文中的 CLI 片段假设已创建
inferenceconfig.json文档。 有关如何创建此文档的详细信息,请参阅部署模型的方式和位置。连接到你的工作区的 Azure Kubernetes 服务群集。 有关详细信息,请参阅创建并附加 Azure Kubernetes 服务群集。
- 如果要将模型部署到 GPU 节点或 FPGA 节点(或任何特定 SKU),则必须使用该特定 SKU 创建群集。 不支持在现有群集中创建辅助节点池以及在辅助节点池中部署模型。
了解部署过程
在 Kubernetes 和 Azure 机器学习中都会用到“部署”一词。 “部署”在这两种上下文中有不同的含义。 在 Kubernetes 中,Deployment 是使用声明性 YAML 文件指定的具体实体。 Kubernetes Deployment 具有明确的生命周期,并与其他 Kubernetes 实体(如 Pods 和 ReplicaSets)有具体的关系。 可以从什么是 Kubernetes?中的文档和视频了解 Kubernetes。
在 Azure 机器学习中,“部署”在更普遍的意义上用于提供和清理项目资源。 Azure 机器学习认为属于部署的步骤包括:
- 将项目文件夹中的文件压缩,忽略那些在 .amlignore 或 .gitignore 中指定的文件
- 纵向扩展计算群集(与 Kubernetes 相关)
- 构建 dockerfile 或将其下载到计算节点(与 Kubernetes 相关)
- 系统会计算以下各项的哈希:
- 基础映像
- 自定义 Docker 步骤(请参阅使用自定义 Docker 基础映像部署模型)
- Conda 定义 YAML(请参阅在 Azure 机器学习中创建和使用软件环境)
- 在工作区 Azure 容器注册表 (ACR) 中查找时,系统使用此哈希作为键
- 如果找不到,它会在全局 ACR 中寻找匹配项
- 如果找不到匹配项,系统会生成一个新映像(该映像会被缓存并推送到工作区 ACR 中)
- 系统会计算以下各项的哈希:
- 将压缩的项目文件下载到计算节点上的临时存储
- 解压缩项目文件
- 执行
python <entry script> <arguments>的计算节点 - 将写入
./outputs的日志、模型文件和其他文件保存到与工作区关联的存储帐户 - 纵向缩减计算,包括删除临时存储(与 Kubernetes 相关)
Azure ML 路由器
将传入的推理请求路由到已部署服务的前端组件 (azureml-fe) 可根据需要自动缩放。 azureml-fe 的缩放基于 AKS 群集用途和大小(节点数)。 群集用途和节点数是在创建或附加 AKS 群集时配置的。 每个群集都有一个 azureml-fe 服务,该服务可能在多个 Pod 上运行。
重要
当使用配置为“开发测试”的群集时,self-scaler 会被禁用。 即使对于 FastProd/DenseProd 集群,Self-Scaler 也仅在遥测显示需要时才启用。
Azureml-fe 会纵向(垂直)扩展以使用更多的核心,并会横向(水平)扩展以使用更多的 Pod。 决定进行纵向扩展时,将使用对传入的推理请求进行路由所花费的时间。 如果此时间超过阈值,则会进行纵向扩展。 如果对传入的请求进行路由的时间仍超出阈值,则会进行横向扩展。
在纵向和横向缩减时,将使用 CPU 使用率。 如果满足 CPU 使用率阈值,则前端会首先纵向缩减。 如果 CPU 使用率下降到了横向缩减阈值,则会进行横向缩减操作。 仅当有足够的群集资源可用时,才会进行纵向扩展和横向扩展。
纵向扩展或纵向缩减时,azureml-fe pod 将重新启动以应用 cpu/内存更改。 推理请求不受重新启动的影响。
了解 AKS 推理集群的连接要求
当 Azure 机器学习创建或附加 AKS 群集时,将使用以下两种网络模型之一部署 AKS 群集:
- Kubenet 网络 - 通常在部署 AKS 群集时创建和配置网络资源。
- Azure 容器网络接口 (CNI) 网络 - AKS 群集连接到现有的虚拟网络资源和配置。
对于 Kubenet 网络,已为 Azure 机器学习服务适当创建和配置了网络。 对于 CNI 网络,需要了解连接要求,并确保用于 AKS 推理的 DNS 解析和出站连接。 例如,可能正在使用防火墙来阻止网络流量。
下图显示了 AKS 推理的连接要求。 黑色箭头代表实际的通信,蓝色箭头代表域名。 可能需要将这些主机的条目添加到防火墙或自定义 DNS 服务器。
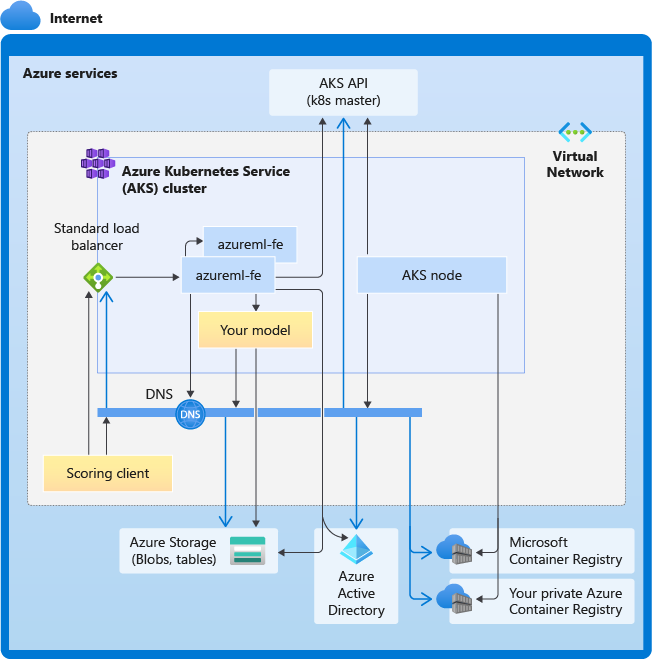
要查看常规的 AKS 连接要求,请参阅控制 Azure Kubernetes 服务中群集节点的出口流量。
要在防火墙后访问 Azure ML 服务,请参阅如何在防火墙后访问 azureml。
总体 DNS 解析要求
现有 VNet 中的 DNS 解析由用户控制。 例如,防火墙或自定义 DNS 服务器。 以下主机必须是可访问的:
| 主机名 | 使用者 |
|---|---|
<cluster>.hcp.<region>.cx.prod.service.azk8s.cn |
AKS API 服务器 |
mcr.microsoft.com |
Microsoft Container Registry (MCR) |
<ACR name>.azurecr.cn |
Azure 容器注册表 (ACR) |
<account>.table.core.chinacloudapi.cn |
Azure 存储帐户(表存储) |
<account>.blob.core.chinacloudapi.cn |
Azure 存储帐户(Blob 存储) |
api.ml.azure.cn |
Azure Active Directory (Azure AD) 身份验证 |
ingest-vienna<region>.kusto.chinacloudapi.cn |
Kusto 终结点用于上传遥测数据 |
<leaf-domain-label + auto-generated suffix>.<region>.cloudapp.chinacloudapi.cn |
终结点域名(如果由 Azure 机器学习自动生成)。 如果使用自定义域名,则不需要此项。 |
按时间顺序排列的连接性要求:从群集创建到模型部署
在 AKS 创建或附加过程中,将 Azure ML 路由器 (azureml-fe) 部署到 AKS 群集中。 为了部署 Azure ML 路由器, AKS 节点应该能够:
- 解析 AKS API 服务器的 DNS
- 解析 MCR 的 DNS,以便为 Azure ML 路由器下载 docker 映像
- 从需要出站连接的 MCR 下载映像
在部署 azureml-fe 之后,它将立即尝试启动,这需要:
- 解析 AKS API 服务器的 DNS
- 查询 AKS API 服务器以发现自身的其他实例(这是一个多 Pod 服务)
- 连接到其自身的其他实例
启动 azureml-fe 后,需要使用以下连接才能正常工作:
- 连接到 Azure 存储以下载动态配置
- 为 AAD 身份验证服务器 api.ml.azure.cn 解析 DNS,并在部署的服务使用 Azure AD 身份验证时与其通信。
- 查询 AKS API 服务器以发现已部署的模型
- 与已部署的模型 Pod 进行通信
在模型部署时,要成功进行模型部署,AKS 节点应能够:
- 为客户的 ACR 解析 DNS
- 从客户的 ACR 下载映像
- 为存储模型的 Azure BLOB 解析 DNS
- 从 Azure Blob 下载模型
部署模型并启动服务后,azureml-fe 将使用 AKS API 自动发现它,并准备将请求路由到该模型。 它必须能够与模型 Pod 通信。
注意
如果部署的模型需要任何连接(例如查询外部数据库或其他 REST 服务,下载 BLOB 等),则应启用这些服务的 DNS 解析和出站通信。
部署到 AKS
要将模型部署到 Azure Kubernetes 服务,请创建一个描述所需计算资源的部署配置。 例如,核心和内存的数量。 此外,还需要一个推理配置,描述托管模型和 Web 服务所需的环境。 有关如何创建推理配置的详细信息,请参阅部署模型的方式和位置。
注意
待部署模型的数量限制为每个部署(每个容器)1,000 个模型。
from azureml.core.webservice import AksWebservice, Webservice
from azureml.core.model import Model
from azureml.core.compute import AksCompute
aks_target = AksCompute(ws,"myaks")
# If deploying to a cluster configured for dev/test, ensure that it was created with enough
# cores and memory to handle this deployment configuration. Note that memory is also used by
# things such as dependencies and AML components.
deployment_config = AksWebservice.deploy_configuration(cpu_cores = 1, memory_gb = 1)
service = Model.deploy(ws, "myservice", [model], inference_config, deployment_config, aks_target)
service.wait_for_deployment(show_output = True)
print(service.state)
print(service.get_logs())
有关此示例中使用的类、方法和参数的详细信息,请参阅以下参考文档:

自动缩放
处理 Azure ML 模型部署的自动缩放的组件是 azureml-fe,这是一个智能请求路由器。 由于所有推理请求都通过它进行,因此它具有自动缩放已部署模型所需的数据。
重要
不要为模型部署启用 Kubernetes 水平 Pod 自动缩放程序 (HPA) 。 这样做会导致两个自动缩放组件相互竞争。 Azureml-fe 设计用于自动缩放由 Azure ML 部署的模型,其中,HPA 必须根据 CPU 使用率或自定义指标配置等一般指标推测或估算模型利用率。
Azureml-fe 不会缩放 AKS 群集中的节点数,因为这可能会导致成本意外增加。 相反,它会在物理群集边界内缩放模型的副本数。 如果你需要缩放群集中的节点数,则可以手动缩放群集,或配置 AKS 群集自动缩放程序。
可以通过为 AKS Web 服务设置 autoscale_target_utilization、autoscale_min_replicas 和 autoscale_max_replicas 来控制自动缩放。 以下示例演示了如何启用自动缩放:
aks_config = AksWebservice.deploy_configuration(autoscale_enabled=True,
autoscale_target_utilization=30,
autoscale_min_replicas=1,
autoscale_max_replicas=4)
纵向扩展/缩减决策取决于当前容器副本的利用率。 处于繁忙状态(正在处理请求)的副本数除以当前副本的总数为当前利用率。 如果此数字超出 autoscale_target_utilization,则会创建更多的副本。 如果它较低,则会减少副本。 默认情况下,目标利用率为 70%。
添加副本的决策是迫切而迅速的(大约 1 秒)。 删除副本的决策是保守的(大约 1 分钟)。
可以使用以下代码计算所需的副本:
from math import ceil
# target requests per second
targetRps = 20
# time to process the request (in seconds)
reqTime = 10
# Maximum requests per container
maxReqPerContainer = 1
# target_utilization. 70% in this example
targetUtilization = .7
concurrentRequests = targetRps * reqTime / targetUtilization
# Number of container replicas
replicas = ceil(concurrentRequests / maxReqPerContainer)
有关设置 autoscale_target_utilization、autoscale_max_replicas 和 autoscale_min_replicas 的详细信息,请参阅 AksWebservice 模块参考。
Web 服务身份验证
部署到 Azure Kubernetes 服务时,默认会启用基于密钥的身份验证。 此外,还可以启用基于令牌的身份验证。 基于令牌的身份验证要求客户端使用 Azure Active Directory 帐户来请求身份验证令牌,该令牌用于向已部署的服务发出请求。
要禁用身份验证,请在创建部署配置时设置 auth_enabled=False 参数。 下面的示例使用 SDK 来禁用身份验证:
deployment_config = AksWebservice.deploy_configuration(cpu_cores=1, memory_gb=1, auth_enabled=False)
有关如何从客户端应用程序进行身份验证的信息,请参阅使用部署为 Web 服务的 Azure 机器学习模型。
使用密钥进行身份验证
如果已启用密钥身份验证,可以使用 get_keys 方法来检索主要和辅助身份验证密钥:
primary, secondary = service.get_keys()
print(primary)
重要
如需重新生成密钥,请使用 service.regen_key
使用令牌进行身份验证
要启用令牌身份验证,请在创建或更新部署时设置 token_auth_enabled=True 参数。 下面的示例使用 SDK 来启用令牌身份验证:
deployment_config = AksWebservice.deploy_configuration(cpu_cores=1, memory_gb=1, token_auth_enabled=True)
如果启用了令牌身份验证,可以使用 get_token 方法来检索 JWT 令牌以及该令牌的到期时间:
token, refresh_by = service.get_token()
print(token)
重要
需要在令牌的 refresh_by 时间后请求一个新令牌。
Azure 强烈建议在 Azure Kubernetes 服务群集所在的相同区域中创建 Azure 机器学习工作区。 要使用令牌进行身份验证,Web 服务将调用创建 Azure 机器学习工作区的区域。 如果工作区区域不可用,即使群集和工作区不在同一区域,也将无法获取 Web 服务的令牌。 这实际上会导致在工作区的区域再次可用之前,基于令牌的身份验证不可用。 此外,群集区域和工作区区域的距离越远,获取令牌所需的时间就越长。
若要检索令牌,必须使用 Azure 机器学习 SDK 或 az ml service get-access-token 命令。
漏洞扫描
Microsoft Defender for Cloud 跨混合云工作负载提供统一的安全管理和高级威胁防护。 应允许 Microsoft Defender for Cloud 扫描资源并遵循其建议。 有关详细信息,请参阅 Azure Kubernetes 服务与 Defender for Cloud 集成。