重要
本文提供有关使用 Azure 机器学习 SDK v1 的信息。 SDK v1 自 2025 年 3 月 31 日起弃用。 对它的支持将于 2026 年 6 月 30 日结束。 可以在该日期之前安装和使用 SDK v1。 使用 SDK v1 的现有工作流将在支持结束日期后继续运行。 但是,在产品发生体系结构更改时,可能会面临安全风险或中断性变更。
建议在 2026 年 6 月 30 日之前过渡到 SDK v2。 有关 SDK v2 的详细信息,请参阅 什么是 Azure 机器学习 CLI 和 Python SDK v2? 以及 SDK v2 参考。
本文介绍如何将设计器模型部署到 Azure 机器学习工作室中的实时联机终结点。
注册或下载后,可以像使用任何其他模型一样使用由设计师训练的模型。 导出的模型可以在用例(例如物联网 (IoT) 和本地部署)中进行部署。
工作室中的部署包括以下步骤:
- 注册已训练的模型。
- 下载模型的输入脚本和 conda 依赖项文件。
- (可选)配置入口脚本。
- 将模型部署到计算目标。
还可以直接在设计器中部署模型,以跳过模型注册和文件下载步骤。 这对于快速部署非常有用。 有关详细信息,请参阅 教程:使用设计器部署机器学习模型。
在设计器中训练的模型也可以通过 SDK 或命令行接口 (CLI) 进行部署。 有关详细信息,请参阅将机器学习模型部署到 Azure。
先决条件
一个已完成的训练管道,其中包含以下组件之一:
- “训练模型”组件
- “训练异常情况检测模型”组件
- “训练聚类分析模型”组件
- 训练 PyTorch 模型组件
- “训练 SVD 推荐器”组件
- “训练 Vowpal Wabbit 模型”组件
- “训练宽度和深度模型”组件
注册模型
训练管道完成后,将训练的模型注册到 Azure 机器学习工作区,以在其他项目中访问该模型。
登录到 Azure 机器学习工作室,并选择已完成的管道。
双击 “训练模型”组件 以打开详细信息窗格。
在详细信息窗格中选择“ 输出 + 日志 ”选项卡。
选择“注册模型”。

输入模型的名称,然后选择“保存”。

在注册您的模型后,您可以在工作室的“模型”资产页面找到它。
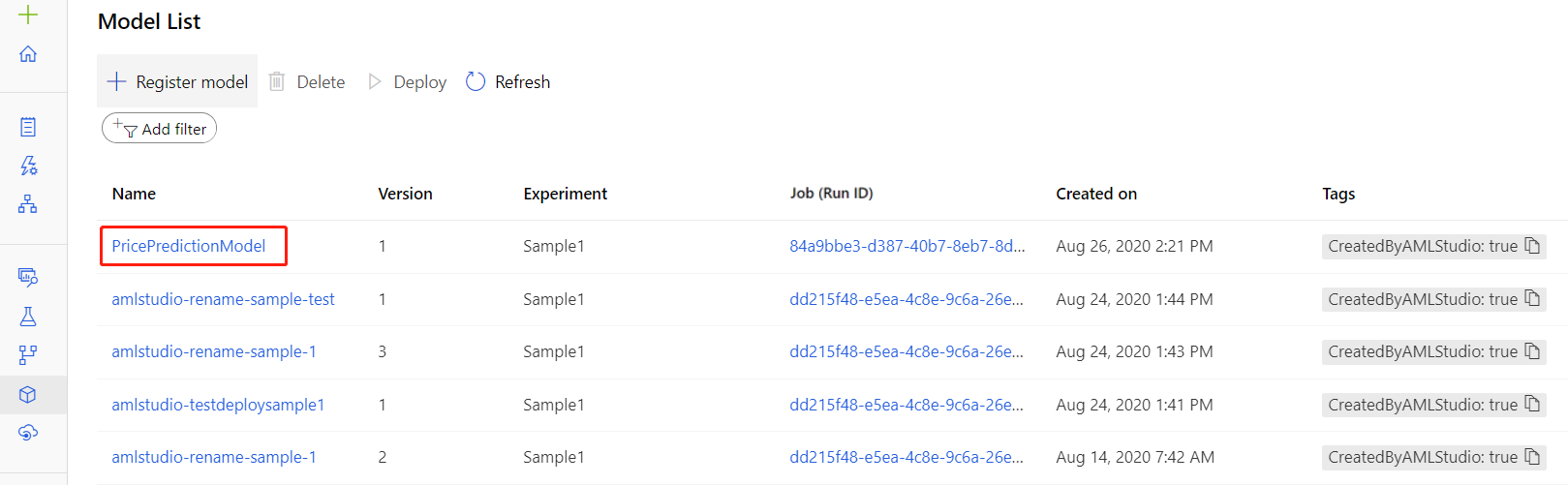
下载入口脚本文件和 conda 依赖项文件
需要以下文件才能在 Azure 机器学习工作室中部署模型:
输入脚本文件:加载训练的模型、处理来自请求的输入数据、执行实时推理并返回结果。 当“训练模型”组件完成时,设计器会自动生成一个
score.py条目脚本文件。Conda 依赖项文件:指定 Web 服务依赖的 pip 和 conda 包。 当“训练模型”组件完成时,设计器会自动创建一个
conda_env.yaml文件。
可以在“训练模型”组件的右窗格中下载这两个文件:
创建“训练模型”组件。
在“输出 + 日志”选项卡中,选择文件夹 。
下载
conda_env.yaml文件和score.py文件。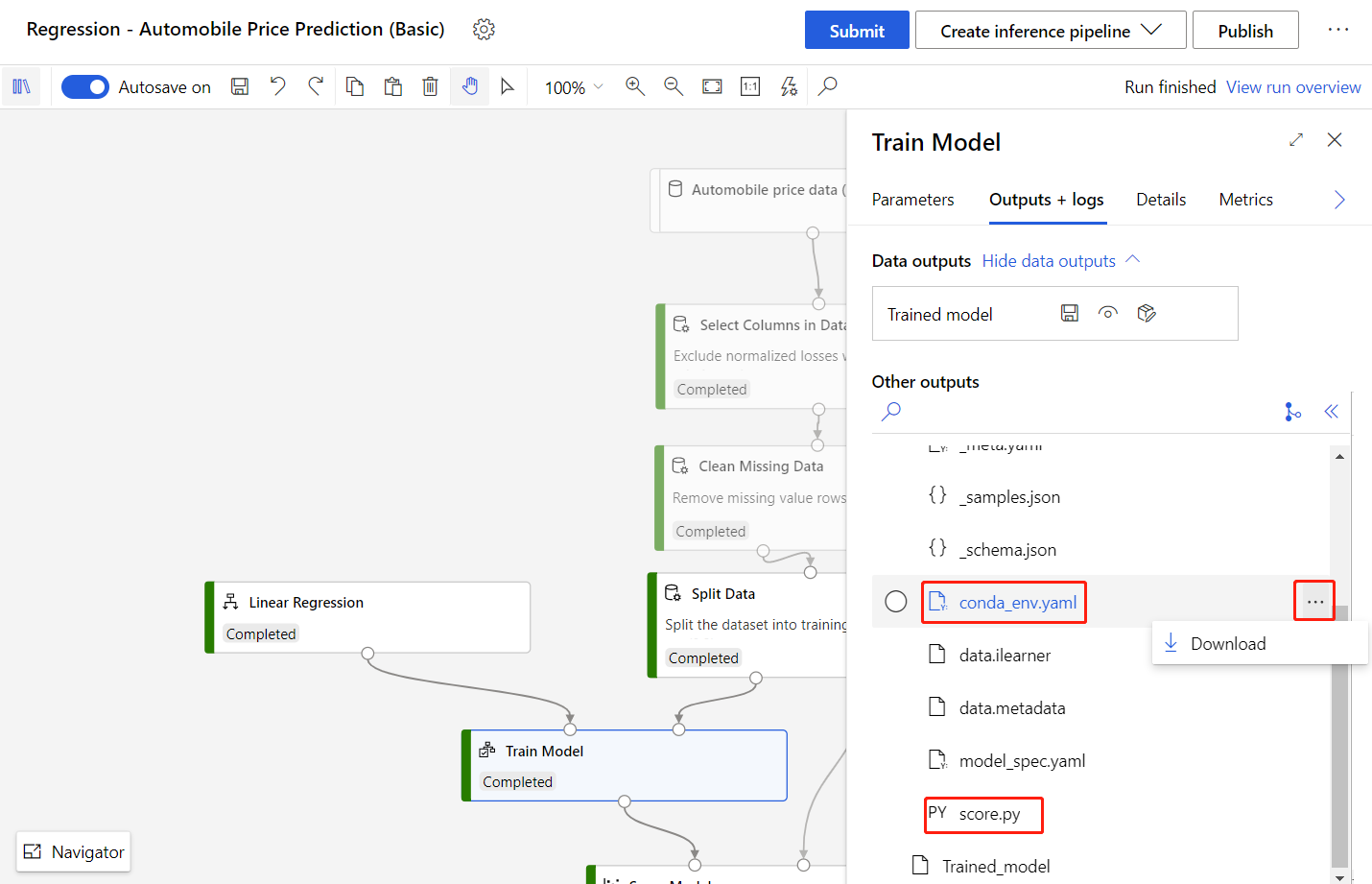

或者,可以在注册模型后,从“模型”资产页中下载这些文件:
导航到“模型”资产页。
选择要部署的模型。
选择工件选项卡。
选择
trained_model_outputs文件夹。下载
conda_env.yaml文件和score.py文件。

注释
score.py 文件提供与“评分模型”组件几乎相同的功能。 不过,某些组件(例如为 SVD 推荐器评分、为 Wide and Deep 推荐器评分和为 Vowpal Wabbit 模型评分)有用于不同评分模式的参数。 你还可以在入口脚本中更改这些参数。
有关在 score.py 文件中设置参数的详细信息,请参阅配置入口脚本。
部署模型
下载所需的文件后,就可以部署该模型了。
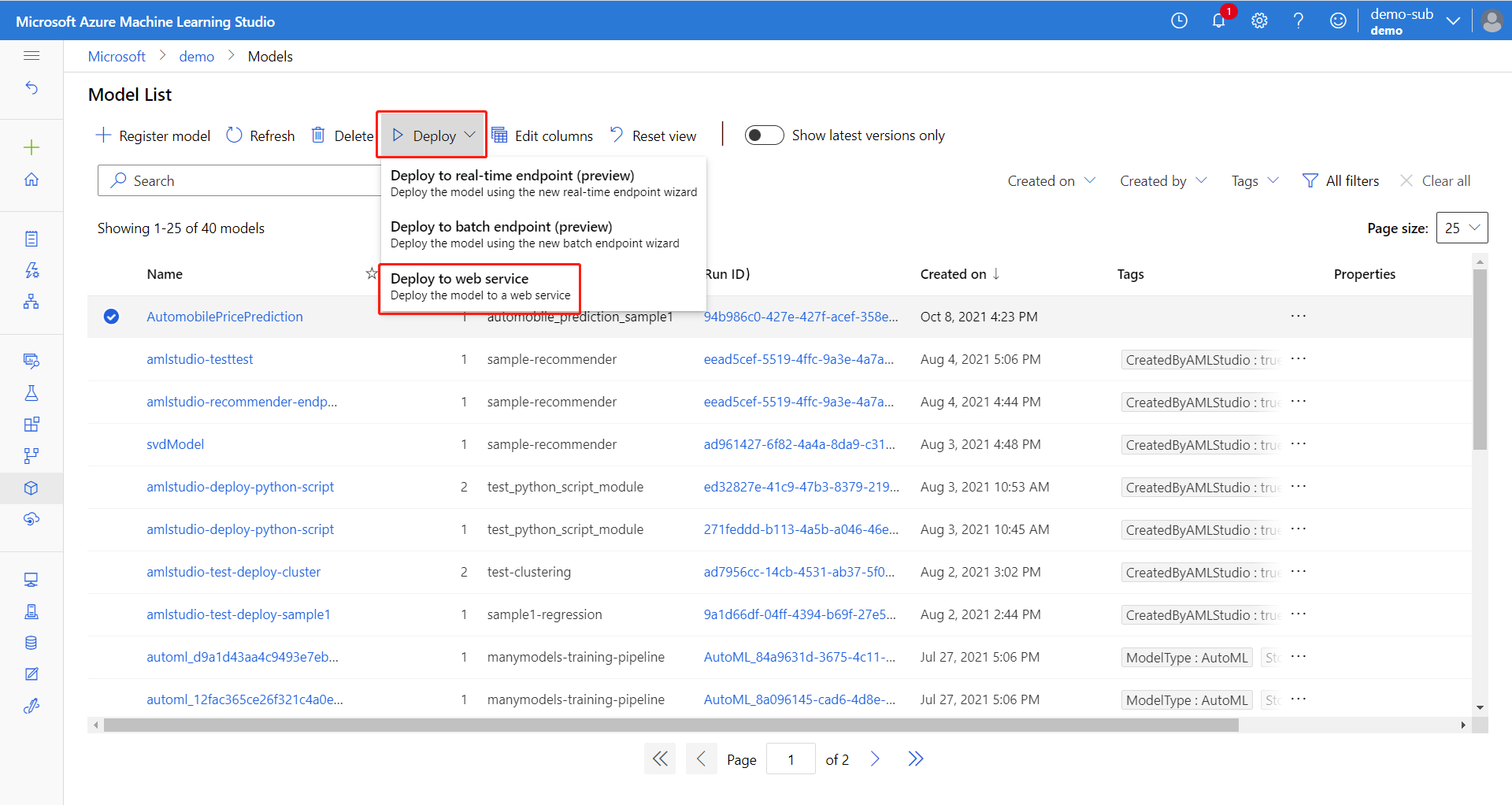
在“模型”资产页,选择已注册的模型。
选择“ 使用此模型”,然后从下拉菜单中选择 “Web 服务 ”。
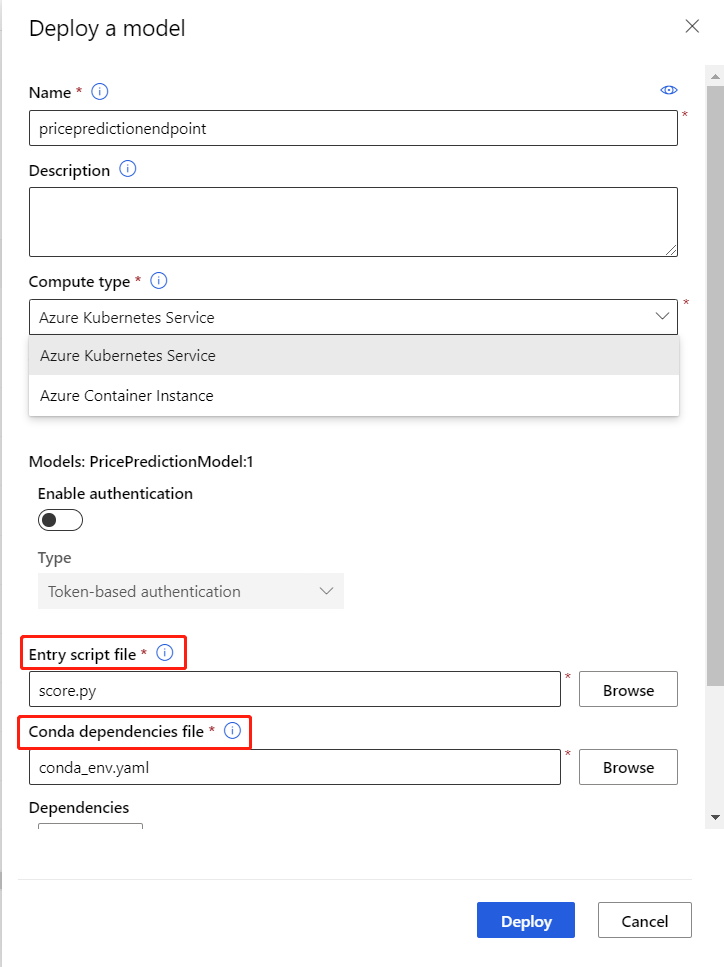
在“配置”菜单中,输入以下信息:
- 输入终结点的名称。
- 选择 AksCompute 或 Azure 容器实例 计算类型。
- 选择计算名称。
- 为入口脚本文件上传
score.py。 - 为 Conda 依赖项文件上传
conda_env.yml。
小窍门
在 “高级 ”设置中,可以设置 CPU/内存容量和其他用于部署的参数。 这些设置对于某些模型(如 PyTorch 模型)非常重要,这些模型消耗了大量内存(约 4 GB)。
选择 部署 部署您的模型为联机终结点。

使用联机终结点
部署成功后,可以在资产页面找到“终结点”所在的位置。 找到 REST 终结点之后,客户端可以使用该终结点将请求提交到终结点。
注释
设计器还会生成用于测试的示例数据 json 文件,你可以在 trained_model_outputs 文件夹中下载 _samples.json。
请使用以下代码示例来调用在线终结点。
import json
from pathlib import Path
from azureml.core.workspace import Workspace, Webservice
service_name = 'YOUR_SERVICE_NAME'
ws = Workspace.get(
name='WORKSPACE_NAME',
subscription_id='SUBSCRIPTION_ID',
resource_group='RESOURCEGROUP_NAME'
)
service = Webservice(ws, service_name)
sample_file_path = '_samples.json'
with open(sample_file_path, 'r') as f:
sample_data = json.load(f)
score_result = service.run(json.dumps(sample_data))
print(f'Inference result = {score_result}')
使用与计算机视觉相关的联机终结点
使用与计算机视觉相关的联机终结点时,需要将图像转换为字节,因为 Web 服务仅接受字符串作为输入。 以下是示例代码:
import base64
import json
from copy import deepcopy
from pathlib import Path
from azureml.studio.core.io.image_directory import (IMG_EXTS, image_from_file, image_to_bytes)
from azureml.studio.core.io.transformation_directory import ImageTransformationDirectory
# image path
image_path = Path('YOUR_IMAGE_FILE_PATH')
# provide the same parameter setting as in the training pipeline. Just an example here.
image_transform = [
# format: (op, args). {} means using default parameter values of torchvision.transforms.
# See https://pytorch.org/docs/stable/torchvision/transforms.html
('Resize', 256),
('CenterCrop', 224),
# ('Pad', 0),
# ('ColorJitter', {}),
# ('Grayscale', {}),
# ('RandomResizedCrop', 256),
# ('RandomCrop', 224),
# ('RandomHorizontalFlip', {}),
# ('RandomVerticalFlip', {}),
# ('RandomRotation', 0),
# ('RandomAffine', 0),
# ('RandomGrayscale', {}),
# ('RandomPerspective', {}),
]
transform = ImageTransformationDirectory.create(transforms=image_transform).torch_transform
# download _samples.json file under Outputs+logs tab in the right pane of Train PyTorch Model component
sample_file_path = '_samples.json'
with open(sample_file_path, 'r') as f:
sample_data = json.load(f)
# use first sample item as the default value
default_data = sample_data[0]
data_list = []
for p in image_path.iterdir():
if p.suffix.lower() in IMG_EXTS:
data = deepcopy(default_data)
# convert image to bytes
data['image'] = base64.b64encode(image_to_bytes(transform(image_from_file(p)))).decode()
data_list.append(data)
# use data.json as input of consuming the endpoint
data_file_path = 'data.json'
with open(data_file_path, 'w') as f:
json.dump(data_list, f)
配置入口脚本
设计器中的某些组件(例如为 SVD 推荐器评分、为 Wide and Deep 推荐器评分和为 Vowpal Wabbit 模型评分)有用于不同评分模式的参数。
本部分介绍如何在条目脚本文件中更新这些参数。
以下示例更新训练的Wide 和 Deep 推荐器模型的默认行为。 默认情况下,score.py 文件指示 Web 服务预测用户和项目之间的评级。
可以通过更改 recommender_prediction_kind 参数来修改条目脚本文件以提出项建议,并返回建议的项。
import os
import json
from pathlib import Path
from collections import defaultdict
from azureml.studio.core.io.model_directory import ModelDirectory
from azureml.designer.modules.recommendation.dnn.wide_and_deep.score. \
score_wide_and_deep_recommender import ScoreWideAndDeepRecommenderModule
from azureml.designer.serving.dagengine.utils import decode_nan
from azureml.designer.serving.dagengine.converter import create_dfd_from_dict
model_path = os.path.join(os.getenv('AZUREML_MODEL_DIR'), 'trained_model_outputs')
schema_file_path = Path(model_path) / '_schema.json'
with open(schema_file_path) as fp:
schema_data = json.load(fp)
def init():
global model
model = ModelDirectory.load(load_from_dir=model_path)
def run(data):
data = json.loads(data)
input_entry = defaultdict(list)
for row in data:
for key, val in row.items():
input_entry[key].append(decode_nan(val))
data_frame_directory = create_dfd_from_dict(input_entry, schema_data)
# The parameter names can be inferred from Score Wide and Deep Recommender component parameters:
# convert the letters to lower cases and replace whitespaces to underscores.
score_params = dict(
trained_wide_and_deep_recommendation_model=model,
dataset_to_score=data_frame_directory,
training_data=None,
user_features=None,
item_features=None,
################### Note #################
# Set 'Recommender prediction kind' parameter to enable item recommendation model
recommender_prediction_kind='Item Recommendation',
recommended_item_selection='From All Items',
maximum_number_of_items_to_recommend_to_a_user=5,
whether_to_return_the_predicted_ratings_of_the_items_along_with_the_labels='True')
result_dfd, = ScoreWideAndDeepRecommenderModule().run(**score_params)
result_df = result_dfd.data
return json.dumps(result_df.to_dict("list"))
对于 Wide 和 Deep Recommender 和 Vowpal Wabbit 模型,可以使用以下方法配置评分模式参数:
- 参数名称是 Score Vowpal Wabbit Model 和 Score Wide 和 Deep Recommender 的参数名称的小写和下划线组合。
- 模式类型参数值是相应选项名称的字符串。 以上述代码中的 推荐器预测类型 为例,该值可以是
'Rating Prediction'或'Item Recommendation'。 不允许其他值。
对于 SVD 推荐器 训练的模型,参数名称和值可能不太明显,可以查找下表来决定如何设置参数。
| Score SVD 推荐器中的参数名称 | 入口脚本文件中的参数名称 |
|---|---|
| 推荐器预测类型 | 预测类型 |
| 推荐的项目选择 | 推荐项目选择 |
| 每个用户的建议池的最小大小 | min_recommendation_pool_size(最低推荐池大小) |
| 要推荐给用户的最大项目数 | 最大建议物品数量 |
| 是否返回项目的预测评级以及标签 | 返回评分 |
以下代码演示如何设置 SVD 推荐器的参数,该推荐器使用所有六个参数来推荐附加了预测分级的项目。
score_params = dict(
learner=model,
test_data=DataTable.from_dfd(data_frame_directory),
training_data=None,
# RecommenderPredictionKind has 2 members, 'RatingPrediction' and 'ItemRecommendation'. You
# can specify prediction_kind parameter with one of them.
prediction_kind=RecommenderPredictionKind.ItemRecommendation,
# RecommendedItemSelection has 3 members, 'FromAllItems', 'FromRatedItems', 'FromUndatedItems'.
# You can specify recommended_item_selection parameter with one of them.
recommended_item_selection=RecommendedItemSelection.FromRatedItems,
min_recommendation_pool_size=1,
max_recommended_item_count=3,
return_ratings=True,
)