适用于: 适用于 Python 的 Azure 机器学习 SDK v1
适用于 Python 的 Azure 机器学习 SDK v1
重要
本文提供有关使用 Azure 机器学习 SDK v1 的信息。 SDK v1 自 2025 年 3 月 31 日起弃用。 对它的支持将于 2026 年 6 月 30 日结束。 可以在该日期之前安装和使用 SDK v1。 使用 SDK v1 的现有工作流将在支持结束日期后继续运行。 但是,在产品发生体系结构更改时,可能会面临安全风险或中断性变更。
建议在 2026 年 6 月 30 日之前过渡到 SDK v2。 有关 SDK v2 的详细信息,请参阅 什么是 Azure 机器学习 CLI 和 Python SDK v2? 以及 SDK v2 参考。
注释
已停用的包:即将停用以下 SDK v1 管道包:azureml-train-core、azureml-pipeline、azureml-pipeline-core、azureml-pipeline-internal 和 azureml-pipeline-steps。 有关 v2 管道,请参阅 使用 Azure 机器学习 CLI/SDK v2 生成和运行机器学习管道。
本文介绍如何与同事或客户共享机器学习管道。
机器学习管道是用于机器学习任务的可重用工作流。 管道的一个益处是加强了协作。 还可以使用版本管道,使客户能够在处理新版本时使用当前模型。
必备条件
创建 Azure 机器学习工作区 以包含管道资源。
通过安装 Azure 机器学习 SDK 来配置开发环境,或使用已安装 SDK 的 Azure 机器学习计算实例。
创建并运行机器学习管道。 满足此要求的一种方法是完成 教程:生成用于批量评分的 Azure 机器学习管道。 有关其他选项,请参阅 使用 Azure 机器学习 SDK 创建和运行机器学习管道。
发布管道
创建正在运行的管道后,可以发布管道,以便它使用不同的输入运行。 要使已发布管道的 REST 终结点接受参数,必须将管道配置为对参数使用 PipelineParameter 对象,这些参数将有所不同。
若要创建管道参数,请使用具有默认值的 PipelineParameter 对象:
from azureml.pipeline.core.graph import PipelineParameter pipeline_param = PipelineParameter( name="pipeline_arg", default_value=10)将
PipelineParameter对象作为参数添加到管道中的任何步骤,如下所示:compareStep = PythonScriptStep( script_name="compare.py", arguments=["--comp_data1", comp_data1, "--comp_data2", comp_data2, "--output_data", out_data3, "--param1", pipeline_param], inputs=[ comp_data1, comp_data2], outputs=[out_data3], compute_target=compute_target, source_directory=project_folder)发布此管道,该管道将在调用时接受参数:
published_pipeline1 = pipeline_run1.publish_pipeline( name="My_Published_Pipeline", description="My Published Pipeline Description", version="1.0")发布管道后,可以在 UI 中检查它。 管道 ID 是已发布管道的唯一标识符。
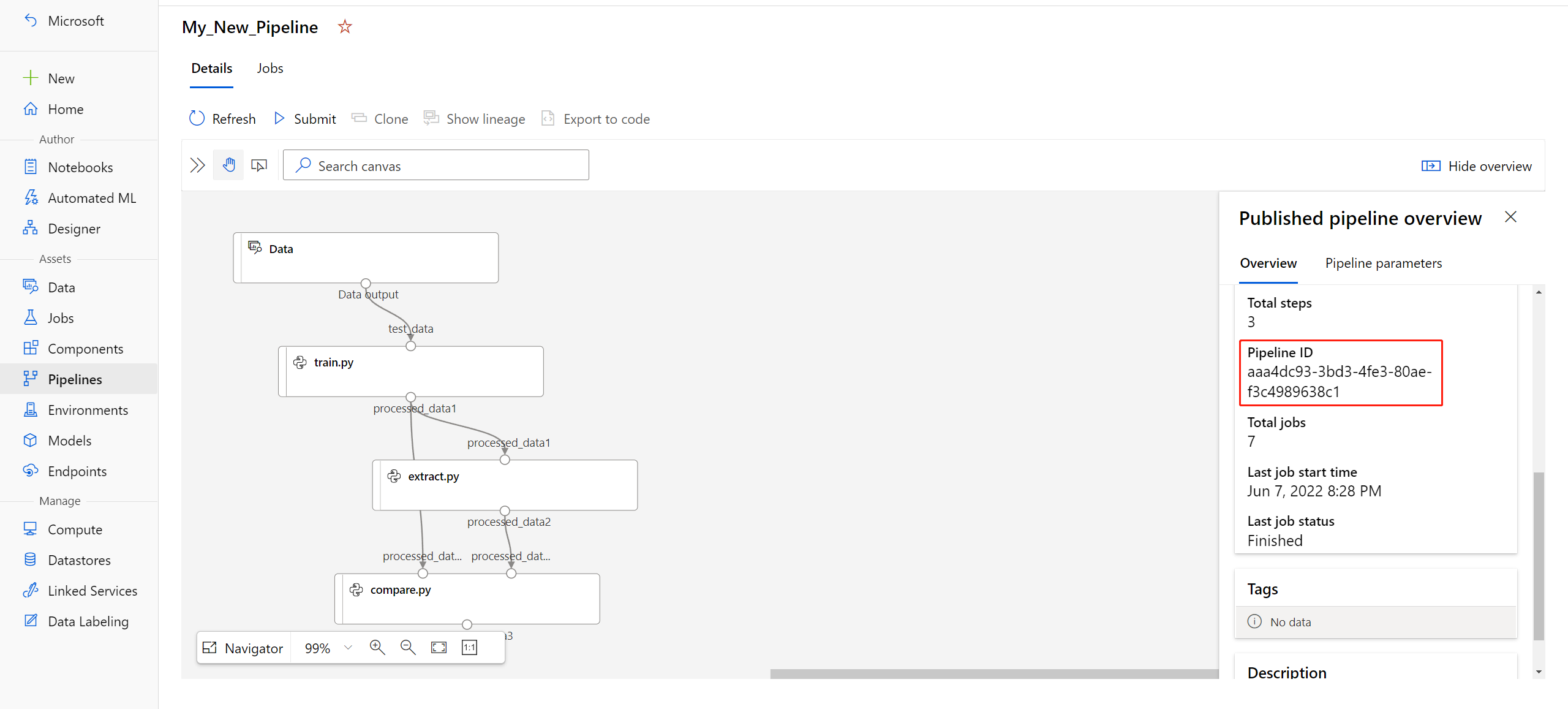

运行已发布的流水线
所有已发布的管道都具有 REST 终结点。 通过使用管道终结点,可以从外部系统(包括非 Python 客户端)触发管道的运行。 此终结点支持在批量评分和重新训练场景中管理可重复性。
重要
如果使用 Azure 基于角色的访问控制(RBAC)来管理对管道的访问, 请为管道方案(训练或评分)设置权限。
若要调用上述管道的运行,需要 Microsoft Entra 身份验证标头令牌。 AzureCliAuthentication 类参考和 Azure 机器学习中的身份验证笔记本中介绍了获取令牌的过程。
from azureml.pipeline.core import PublishedPipeline
import requests
response = requests.post(published_pipeline1.endpoint,
headers=aad_token,
json={"ExperimentName": "My_Pipeline",
"ParameterAssignments": {"pipeline_arg": 20}})
对于 json 键,POST 请求的 ParameterAssignments 参数必须包含一个具有管道参数及其值的字典。 此外,该 json 参数可以包含以下键:
| 键 | 说明 |
|---|---|
ExperimentName |
与终结点关联的试验的名称。 |
Description |
描述终结点的自由格式文本。 |
Tags |
可用于标记和批注请求的自由形式键值对。 |
DataSetDefinitionValueAssignments |
用于在不重新训练的情况下更改数据集的字典。 (请参阅本文后面的讨论。 |
DataPathAssignments |
用于在不重新训练的情况下更改数据路径的字典。 (请参阅本文后面的讨论。 |
使用 C# 运行已发布的管道
下面的代码演示如何从 C# 异步调用管道。 部分代码片段仅显示调用结构。 它不会显示完整的类或错误处理。 它不属于Microsoft示例。
[DataContract]
public class SubmitPipelineRunRequest
{
[DataMember]
public string ExperimentName { get; set; }
[DataMember]
public string Description { get; set; }
[DataMember(IsRequired = false)]
public IDictionary<string, string> ParameterAssignments { get; set; }
}
// ... in its own class and method ...
const string RestEndpoint = "your-pipeline-endpoint";
using (HttpClient client = new HttpClient())
{
var submitPipelineRunRequest = new SubmitPipelineRunRequest()
{
ExperimentName = "YourExperimentName",
Description = "Asynchronous C# REST api call",
ParameterAssignments = new Dictionary<string, string>
{
{
// Replace with your pipeline parameter keys and values
"your-pipeline-parameter", "default-value"
}
}
};
string auth_key = "your-auth-key";
client.DefaultRequestHeaders.Authorization = new AuthenticationHeaderValue("Bearer", auth_key);
// Submit the job
var requestPayload = JsonConvert.SerializeObject(submitPipelineRunRequest);
var httpContent = new StringContent(requestPayload, Encoding.UTF8, "application/json");
var submitResponse = await client.PostAsync(RestEndpoint, httpContent).ConfigureAwait(false);
if (!submitResponse.IsSuccessStatusCode)
{
await WriteFailedResponse(submitResponse); // ... method not shown ...
return;
}
var result = await submitResponse.Content.ReadAsStringAsync().ConfigureAwait(false);
var obj = JObject.Parse(result);
// ... use `obj` dictionary to access results
}
使用 Java 运行已发布的管道
以下代码显示了对需要身份验证的管道的调用。 (请参阅 为 Azure 机器学习资源和工作流设置身份验证。如果管道是公开部署的,则不需要生成 authKey调用。 部分代码片段不显示 Java 类和异常处理样板。 代码使用 Optional.flatMap 将可能返回空 Optional 的函数链接在一起。 使用 flatMap 可以缩短和阐明代码,但请注意,getRequestBody() 会吞并异常。
import java.net.URI;
import java.net.http.HttpClient;
import java.net.http.HttpRequest;
import java.net.http.HttpResponse;
import java.util.Optional;
// JSON library
import com.google.gson.Gson;
String scoringUri = "scoring-endpoint";
String tenantId = "your-tenant-id";
String clientId = "your-client-id";
String clientSecret = "your-client-secret";
String resourceManagerUrl = "https://management.chinacloudapi.cn";
String dataToBeScored = "{ \"ExperimentName\" : \"My_Pipeline\", \"ParameterAssignments\" : { \"pipeline_arg\" : \"20\" }}";
HttpClient client = HttpClient.newBuilder().build();
Gson gson = new Gson();
HttpRequest tokenAuthenticationRequest = tokenAuthenticationRequest(tenantId, clientId, clientSecret, resourceManagerUrl);
Optional<String> authBody = getRequestBody(client, tokenAuthenticationRequest);
Optional<String> authKey = authBody.flatMap(body -> Optional.of(gson.fromJson(body, AuthenticationBody.class).access_token));
Optional<HttpRequest> scoringRequest = authKey.flatMap(key -> Optional.of(scoringRequest(key, scoringUri, dataToBeScored)));
Optional<String> scoringResult = scoringRequest.flatMap(req -> getRequestBody(client, req));
// ... etc. (`scoringResult.orElse()`) ...
static HttpRequest tokenAuthenticationRequest(String tenantId, String clientId, String clientSecret, String resourceManagerUrl)
{
String authUrl = String.format("https://login.partner.microsoftonline.cn/%s/oauth2/token", tenantId);
String clientIdParam = String.format("client_id=%s", clientId);
String resourceParam = String.format("resource=%s", resourceManagerUrl);
String clientSecretParam = String.format("client_secret=%s", clientSecret);
String bodyString = String.format("grant_type=client_credentials&%s&%s&%s", clientIdParam, resourceParam, clientSecretParam);
HttpRequest request = HttpRequest.newBuilder()
.uri(URI.create(authUrl))
.POST(HttpRequest.BodyPublishers.ofString(bodyString))
.build();
return request;
}
static HttpRequest scoringRequest(String authKey, String scoringUri, String dataToBeScored)
{
HttpRequest request = HttpRequest.newBuilder()
.uri(URI.create(scoringUri))
.header("Authorization", String.format("Token %s", authKey))
.POST(HttpRequest.BodyPublishers.ofString(dataToBeScored))
.build();
return request;
}
static Optional<String> getRequestBody(HttpClient client, HttpRequest request) {
try {
HttpResponse<String> response = client.send(request, HttpResponse.BodyHandlers.ofString());
if (response.statusCode() != 200) {
System.out.println(String.format("Unexpected server response %d", response.statusCode()));
return Optional.empty();
}
return Optional.of(response.body());
}catch(Exception x)
{
System.out.println(x.toString());
return Optional.empty();
}
}
class AuthenticationBody {
String access_token;
String token_type;
int expires_in;
String scope;
String refresh_token;
String id_token;
AuthenticationBody() {}
}
在不重新训练的情况下更改数据集和数据路径
你可能想要对其他数据集和数据路径进行训练和推理。 例如,你可能想要对较小的数据集进行训练,但要对完整数据集进行推理。 可以使用请求参数DataSetDefinitionValueAssignments中的json键来切换数据集。 可以通过使用DataPathAssignments切换数据路径。 这两种方法都类似:
在管道定义脚本中,为数据集创建
PipelineParameter。 从PipelineParameter创建DatasetConsumptionConfig或DataPath:tabular_dataset = Dataset.Tabular.from_delimited_files('https://dprepdata.blob.core.chinacloudapi.cn/demo/Titanic.csv') tabular_pipeline_param = PipelineParameter(name="tabular_ds_param", default_value=tabular_dataset) tabular_ds_consumption = DatasetConsumptionConfig("tabular_dataset", tabular_pipeline_param)在机器学习脚本中,使用
Run.get_context().input_datasets以下命令访问动态指定的数据集:from azureml.core import Run input_tabular_ds = Run.get_context().input_datasets['tabular_dataset'] dataframe = input_tabular_ds.to_pandas_dataframe() # ... etc. ...请注意,机器学习脚本访问的是为
DatasetConsumptionConfig(tabular_dataset) 指定的值,而不是PipelineParameter(tabular_ds_param) 的值。在管道定义脚本中,将参数设置为
DatasetConsumptionConfigPipelineScriptStep:train_step = PythonScriptStep( name="train_step", script_name="train_with_dataset.py", arguments=["--param1", tabular_ds_consumption], inputs=[tabular_ds_consumption], compute_target=compute_target, source_directory=source_directory) pipeline = Pipeline(workspace=ws, steps=[train_step])若要在推理 REST 调用中动态切换数据集,请使用
DataSetDefinitionValueAssignments:tabular_ds1 = Dataset.Tabular.from_delimited_files('path_to_training_dataset') tabular_ds2 = Dataset.Tabular.from_delimited_files('path_to_inference_dataset') ds1_id = tabular_ds1.id d22_id = tabular_ds2.id response = requests.post(rest_endpoint, headers=aad_token, json={ "ExperimentName": "MyRestPipeline", "DataSetDefinitionValueAssignments": { "tabular_ds_param": { "SavedDataSetReference": {"Id": ds1_id #or ds2_id }}}})
展示 Dataset 和 PipelineParameter 和展示 DataPath 和 PipelineParameter 这两个笔记本包含此方法的完整示例。
创建版本化的管道终结点
可以创建一个其后有多个已发布管道的管道终结点。 在循环访问和更新机器学习管道时,此方法提供固定的 REST 终结点。
from azureml.pipeline.core import PipelineEndpoint
published_pipeline = PublishedPipeline.get(workspace=ws, id="My_Published_Pipeline_id")
pipeline_endpoint = PipelineEndpoint.publish(workspace=ws, name="PipelineEndpointTest",
pipeline=published_pipeline, description="Test description Notebook")
将任务提交给流水线端点
可将作业提交到管道终结点的默认版本:
pipeline_endpoint_by_name = PipelineEndpoint.get(workspace=ws, name="PipelineEndpointTest")
run_id = pipeline_endpoint_by_name.submit("PipelineEndpointExperiment")
print(run_id)
还可以将任务提交给特定的版本:
run_id = pipeline_endpoint_by_name.submit("PipelineEndpointExperiment", pipeline_version="0")
print(run_id)
可以使用 REST API 完成相同的作:
rest_endpoint = pipeline_endpoint_by_name.endpoint
response = requests.post(rest_endpoint,
headers=aad_token,
json={"ExperimentName": "PipelineEndpointExperiment",
"RunSource": "API",
"ParameterAssignments": {"1": "united", "2":"city"}})
在工作室中使用已发布的管道
也可以从工作室运行已发布的管道:
登录到 Azure 机器学习工作室。
在左侧菜单中,选择 “终结点”。
选择 管道终结点:
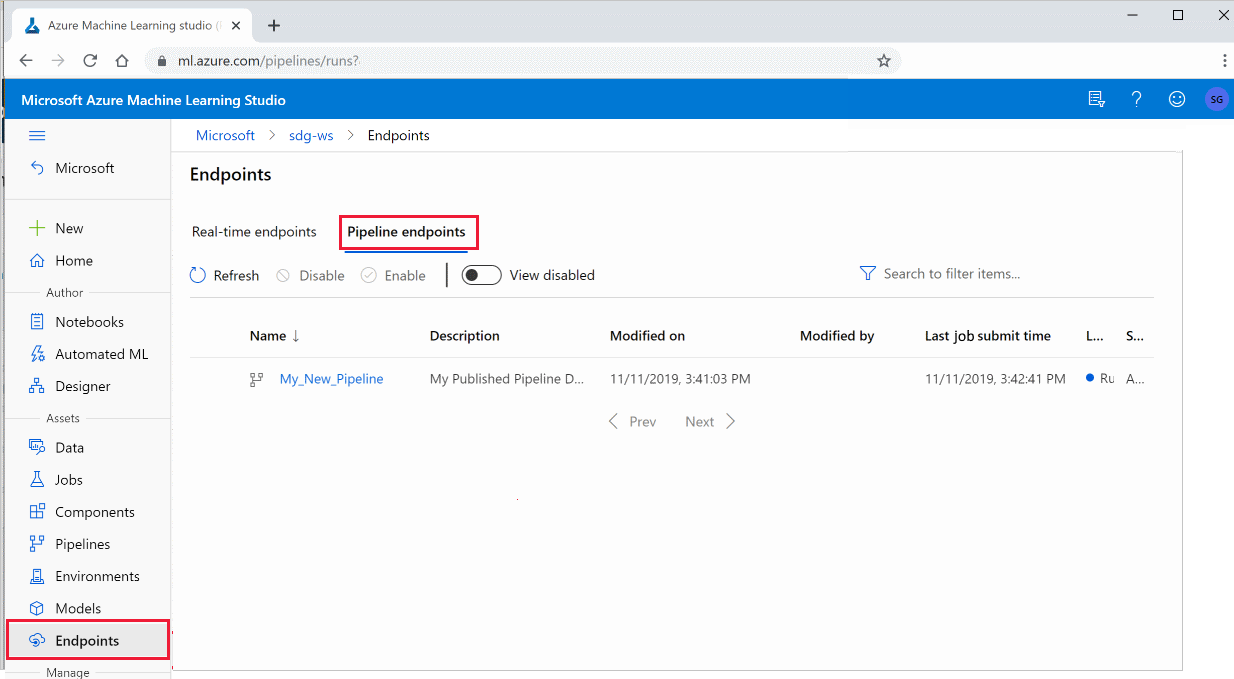
选择要运行的特定管道,查看或使用管道端点以前运行的结果。

禁用已发布的管道
若要在已发布管道列表中隐藏管道,请在工作室中或通过 SDK 禁用该管道:
# Get the pipeline by using its ID from Azure Machine Learning studio
p = PublishedPipeline.get(ws, id="068f4885-7088-424b-8ce2-eeb9ba5381a6")
p.disable()
可以通过 p.enable() 再次启用它。 有关详细信息,请参阅 PublishedPipeline 类 的参考。
后续步骤
注释
这些是 SDK v1 包;请参阅本文顶部的弃用通知。
- 使用这些 GitHub 上的 Jupyter 笔记本 进一步探索机器学习管道。
- 请参阅有关 azureml-pipelines-core 包和 azureml-pipelines-steps 包的 SDK 参考。
- 有关调试和故障排除管道的提示,请参阅 如何调试管道。