适用于: 适用于 Python 的 Azure 机器学习 SDK v1
适用于 Python 的 Azure 机器学习 SDK v1
重要
本文提供有关使用 Azure 机器学习 SDK v1 的信息。 SDK v1 自 2025 年 3 月 31 日起弃用。 对它的支持将于 2026 年 6 月 30 日结束。 可以在该日期之前安装和使用 SDK v1。 使用 SDK v1 的现有工作流将在支持结束日期后继续运行。 但是,在产品发生体系结构更改时,可能会面临安全风险或中断性变更。
建议在 2026 年 6 月 30 日之前过渡到 SDK v2。 有关 SDK v2 的详细信息,请参阅 什么是 Azure 机器学习 CLI 和 Python SDK v2? 以及 SDK v2 参考。
本文演示如何从 Azure Kubernetes 服务 (AKS) 群集上部署的 Azure 机器学习模型中收集数据, 然后将收集的数据存储在 Azure Blob 存储中。
启用收集后,收集的数据可帮助你:
针对收集的生产数据监视数据偏移。
使用 Power BI 或 Azure Databricks 分析收集的数据
更好地决定何时重新训练或优化模型。
使用收集的数据重新训练模型。
收集哪些数据,收集的数据存储在何处
可以收集以下数据:
从部署在 AKS 群集中的 Web 服务收集模型输入数据。 不收集语音、音频、图像和视频数据。
使用生产输入数据进行模型预测。
注意
基于此数据的预先聚合与预先计算目前不是收集服务的一部分。
输出保存在 Blob 存储中。 由于数据将添加到 Blob 存储,因此你可以选择喜好的工具来运行分析。
Blob 中输出数据的路径遵循以下语法:
/modeldata/<subscriptionid>/<resourcegroup>/<workspace>/<webservice>/<model>/<version>/<designation>/<year>/<month>/<day>/data.csv
# example: /modeldata/1a2b3c4d-5e6f-7g8h-9i10-j11k12l13m14/myresourcegrp/myWorkspace/aks-w-collv9/best_model/10/inputs/2018/12/31/data.csv
注意
在低于 0.1.0a16 的适用于 Python 的 Azure 机器学习 SDK 版本中,designation 参数命名为 identifier。 如果使用早期版本开发代码,则需要相应地更新此名称。
先决条件
如果没有 Azure 订阅,可在开始前创建一个试用帐户。
必须安装一个 Azure 机器学习工作区、一个包含脚本的本地目录以及适用于 Python 的 Azure 机器学习 SDK。 若要了解如何安装,请参阅如何配置开发环境。
需要一个已训练的机器学习模型,该模型将部署到 AKS。 如果没有模型,请参阅训练图像分类模型教程。
需要一个 AKS 群集。 有关如何创建此类群集并部署到其中的信息,请参阅将机器学习模型部署到 Azure。
设置环境并安装 Azure 机器学习监视 SDK。
使用基于 Ubuntu 18.04 的 docker 映像,它随
libssl 1.0.0的基本依赖项 一起提供。 可以参考预生成的映像。
启用数据收集
无论通过 Azure 机器学习或其他工具部署的模型是什么,都可以启用数据收集。
若要启用数据收集,需要:
打开评分文件。
在该文件顶部,添加以下代码:
from azureml.monitoring import ModelDataCollector在
init函数中声明数据集合变量:global inputs_dc, prediction_dc inputs_dc = ModelDataCollector("best_model", designation="inputs", feature_names=["feat1", "feat2", "feat3", "feat4", "feat5", "feat6"]) prediction_dc = ModelDataCollector("best_model", designation="predictions", feature_names=["prediction1", "prediction2"])CorrelationId 是可选参数。 如果模型不需要此参数,则无需使用它。 使用 CorrelationId 确实可以帮助你轻松映射到其他数据,例如 LoanNumber 或 CustomerId。
稍后将使用 Identifier 参数在 Blob 中生成文件夹结构。 可以使用此参数将原始数据与已处理的数据区分开来。
将以下代码行添加到
run(input_df)函数:data = np.array(data) result = model.predict(data) inputs_dc.collect(data) #this call is saving our input data into Azure Blob prediction_dc.collect(result) #this call is saving our prediction data into Azure Blob在 AKS 中部署服务时,数据收集不会自动设置为 true。 如以下示例所示更新配置文件:
aks_config = AksWebservice.deploy_configuration(collect_model_data=True)也可以通过更改以下配置来为 Application Insights 启用服务监视:
aks_config = AksWebservice.deploy_configuration(collect_model_data=True, enable_app_insights=True)若要创建新映像并部署机器学习模型,请参阅将机器学习模型部署到 Azure。
将“Azure-Monitoring”pip 包添加到 Web 服务环境的 conda 依赖项:
env = Environment('webserviceenv')
env.python.conda_dependencies = CondaDependencies.create(conda_packages=['numpy'],pip_packages=['azureml-defaults','azureml-monitoring','inference-schema[numpy-support]'])
禁用数据收集
随时可以停止收集数据。 使用 Python 代码禁用数据收集。
## replace <service_name> with the name of the web service
<service_name>.update(collect_model_data=False)
验证并分析数据
可以选择偏好的工具来分析收集到 Blob 存储中的数据。
快速访问 Blob 数据
登录到 Azure 门户。
打开你的工作区。
选择“存储”。

Blob 输出数据的路径遵循以下语法:
/modeldata/<subscriptionid>/<resourcegroup>/<workspace>/<webservice>/<model>/<version>/<designation>/<year>/<month>/<day>/data.csv # example: /modeldata/1a2b3c4d-5e6f-7g8h-9i10-j11k12l13m14/myresourcegrp/myWorkspace/aks-w-collv9/best_model/10/inputs/2018/12/31/data.csv

使用 Power BI 分析模型数据
下载并打开 Power BI Desktop。
-
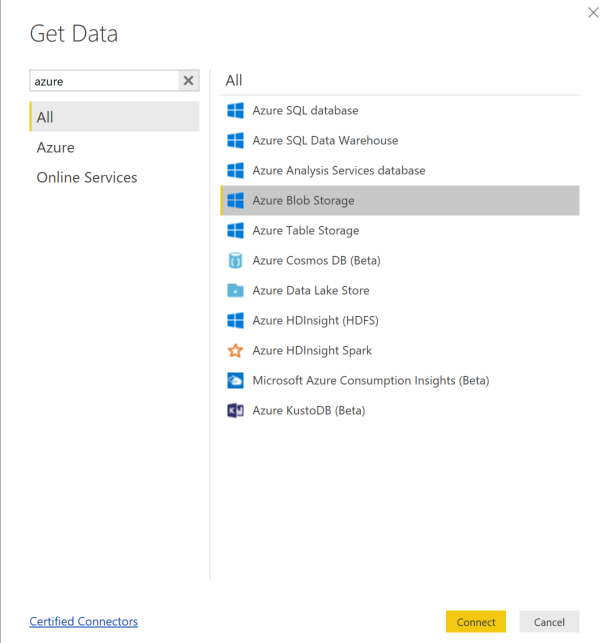
添加存储帐户名称并输入存储密钥。 可以通过在 Blob 中选择“设置”“访问密钥”找到此信息。>
选择“模型数据”容器,然后选择“编辑”。
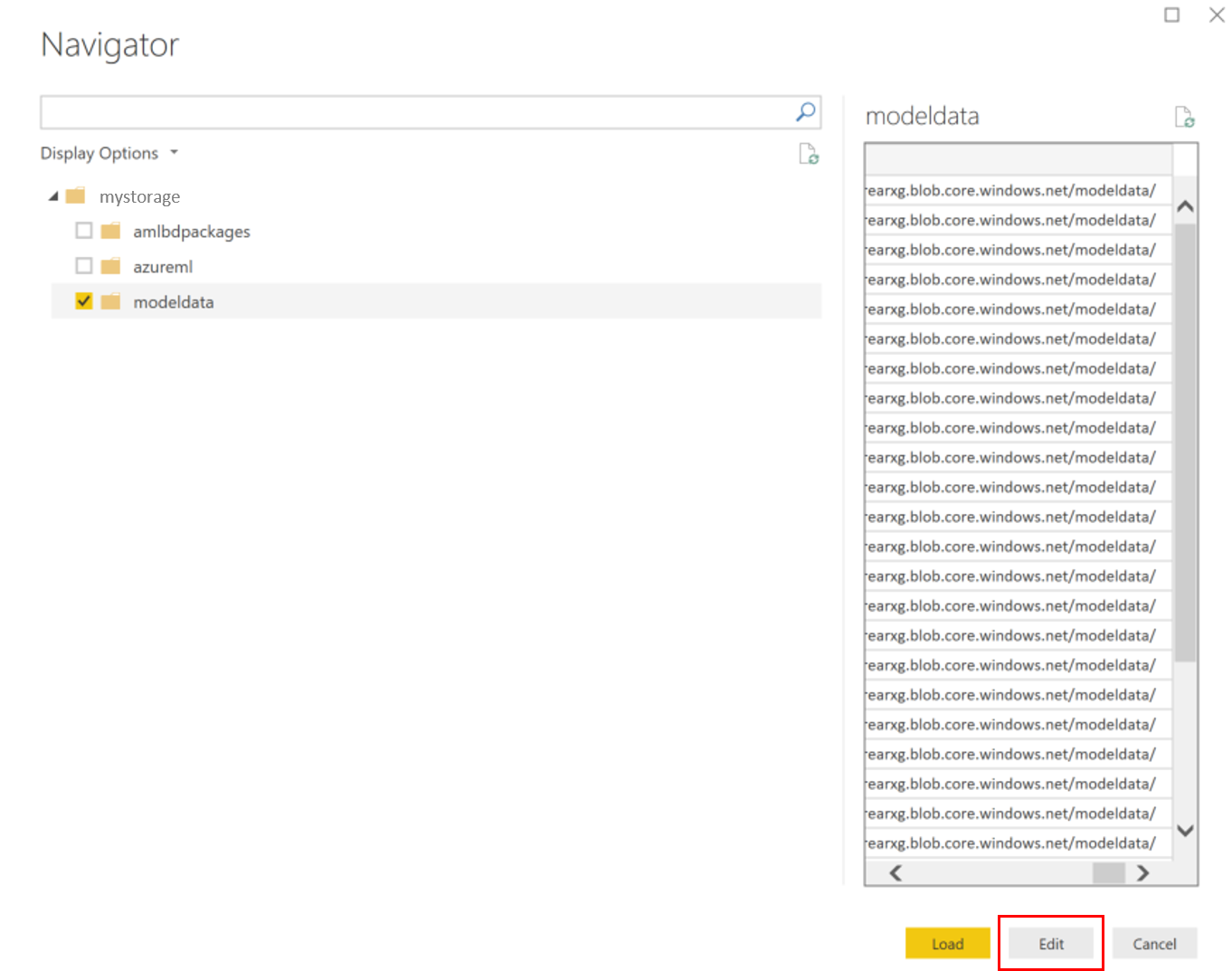
在查询编辑器中,单击“名称”列的下面,并添加存储帐户。
在筛选器中输入模型路径。 如果只想查看特定年份或月份的文件,则只需展开筛选器路径即可。 例如,如果只想查看三月份的数据,请使用以下筛选路径:
/modeldata/<subscriptionid>/<resourcegroupname>/<workspacename>/<webservicename>/<modelname>/<modelversion>/<designation>/<year>/3
基于“名称”值筛选相关的数据。 如果存储了预测和输入,则需要针对每个预测和输入创建一个查询。
选择“内容”列标题旁边的向下双箭头,将文件合并在一起。
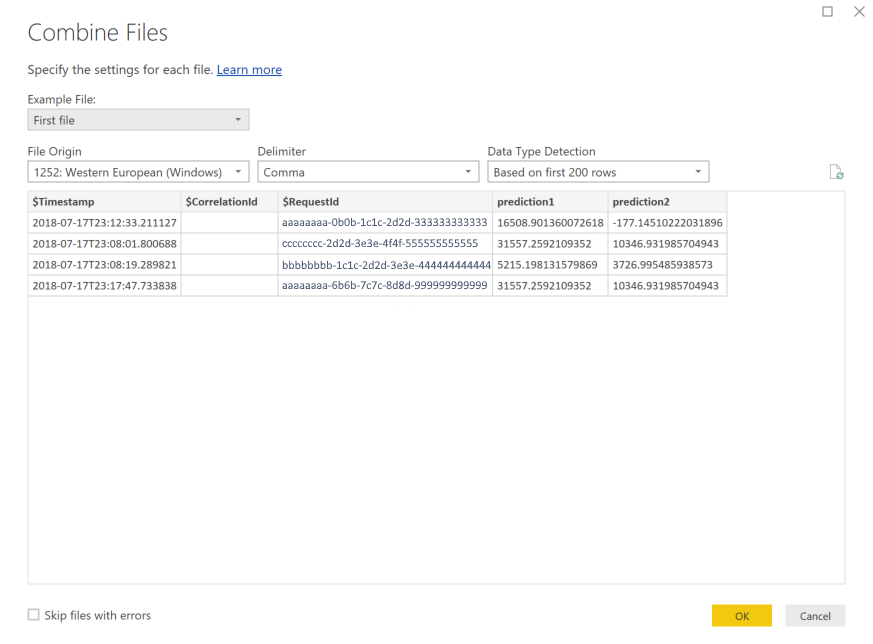
选择“确定”。 数据将预先加载。
选择“关闭并应用”。
如果添加了输入和预测,则表会自动按 RequestId 值排序。
开始基于模型数据生成自定义报表。




使用 Azure Databricks 分析模型数据
创建一个 Azure Databricks 工作区。
转到该 Databricks 工作区。
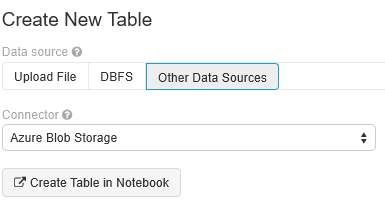
在 Databricks 工作区中,选择“上传数据”。

选择“创建新表”,然后选择“其他数据源”“Azure Blob 存储”“在笔记本中创建表”。>>
更新数据的位置。 下面是一个示例:
file_location = "wasbs://mycontainer@storageaccountname.blob.core.chinacloudapi.cn/*/*/data.csv" file_type = "csv"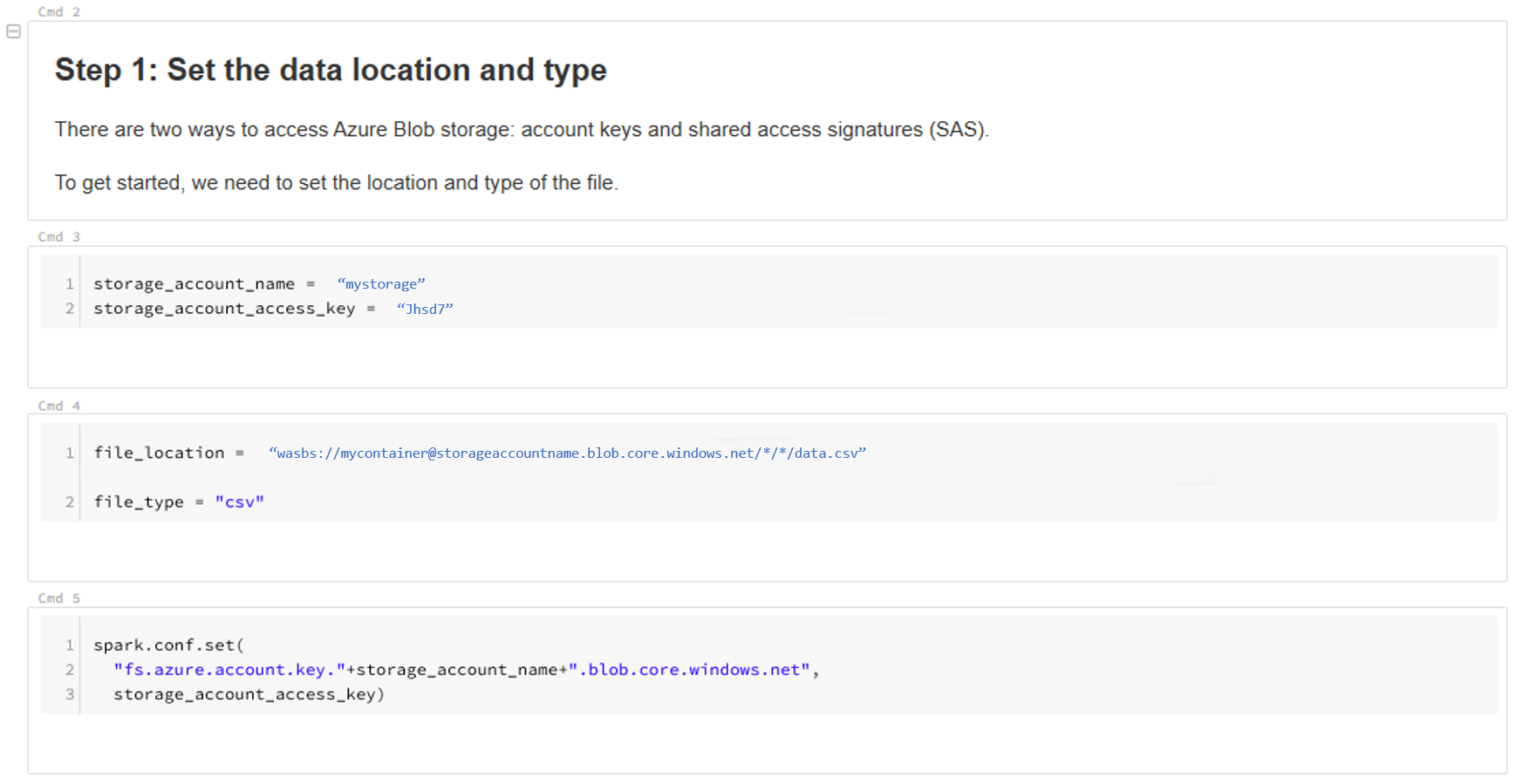
遵循模板中的步骤查看和分析数据。



后续步骤
针对已收集的数据检测数据偏移。