检测数据集中的数据偏移(预览版)

了解如何监视数据偏移并设置偏移幅度很大时的警报。
Azure 机器学习数据集监视器(预览版)具有以下功能:
- 分析数据的偏移,以了解数据在一段时间内的变化。
- 监视模型数据,以了解训练数据集与服务数据集之间的差异。 首先从部署的模型收集模型数据。
- 监视新数据,以了解任何基线与目标数据集之间的差异。
- 分析数据中的特征,以跟踪统计属性在一段时间内的变化。
- 针对数据偏移设置警报,以便针对潜在问题提前发出警告。
- 如果已确定数据偏移太大,请 创建新的数据集版本 。
使用 Azure 机器学习数据集来创建监视器。 此数据集必须包含一个时间戳列。
可以在 Python SDK 或 Azure 机器学习工作室中查看数据偏移指标。 可以通过与 Azure 机器学习工作区关联的 Azure Application Insights 资源获取其他指标和见解。
重要
数据集的数据偏移检测目前为公共预览版。 该预览版在提供时没有附带服务级别协议,建议不要将其用于生产工作负载。 某些功能可能不受支持或者受限。 有关详细信息,请参阅适用于 Azure 预览版的补充使用条款。
先决条件
若要创建和使用数据集监视器,需要:
- Azure 订阅。 如果没有 Azure 订阅,请在开始前创建一个试用帐户。 立即试用 Azure 机器学习的试用版。
- 一个 Azure 机器学习工作区。
- 已安装适用于 Python 的 Azure 机器学习 SDK,其中包含 azureml-datasets 包。
- 在数据中的文件路径、文件名或列中指定了带时间戳的结构化(表格)数据。
什么是数据偏移?
数据偏移是模型准确度不断下降的主要原因之一。 对于机器学习模型,数据偏移是指模型输入数据的变化,这会导致模型性能下降。 监视数据偏移有助于检测这些模型性能问题。
数据偏移的原因包括:
- 上游流程更改,例如,更换了传感器,使度量单位由英寸改为厘米。
- 数据质量问题,例如,已损坏的传感器的读数始终为 0。
- 数据的自然偏移,例如,平均温度随着季节而变化。
- 特征之间的关系变化,也称为共变偏移。
Azure 机器学习通过计算单个指标来简化偏移检测,该指标将所比较数据集的复杂性抽象化。 这些数据集可能有数百个特征和数万个行。 一旦检测到偏移,就可以通过向下钻取来了解哪些特征导致了偏移。 然后你可以检查特征级别指标,以调试和厘清偏移的根本原因。
这种自上而下的方法可以轻松监视数据,不必使用传统的基于规则的方法。 基于规则的方法(例如允许的数据范围或允许的唯一值)可能非常耗时且容易出错。
在 Azure 机器学习中,我们使用数据集监视器进行数据偏移检测和报警。
数据集监视器
数据集监视器的功能:
- 检测数据集中新数据的数据偏移并发出警报。
- 分析历史数据的偏移情况。
- 分析一段时间内的新数据。
数据偏移算法提供数据变化的整体度量,并指出需要对哪些特征做进一步的调查。 数据集监视器通过分析 timeseries 数据集中的新数据来生成其他许多指标。
可以通过 Azure Application Insights 针对监视器生成的所有指标设置自定义警报。 数据集监视器可用于快速捕获数据问题,并通过识别可能的原因来减少调试问题所需的时间。
从概念上讲,在 Azure 机器学习中设置数据集监视器有三种主要方案。
| 方案 | 描述 |
|---|---|
| 监视模型的服务数据与训练数据之间的偏移 | 由于服务数据与训练数据之间存在偏移时模型准确度下降,因此可以将此方案的结果解释为在代理中监视模型的准确度。 |
| 监视时序数据集与前一个时间段之间的偏移。 | 此方案较为常见,可用于监视涉及到模型生成操作的上游或下游节点的数据集。 目标数据集必须有一个时间戳列。 基线数据集可以是任意表格数据集,其中包含与目标数据集共有的特征。 |
| 对过去的数据进行分析。 | 此方案可用于了解历史数据,并在数据集监视器的设置方面做出决策。 |
数据集监视器依赖于以下 Azure 服务。
| Azure 服务 | 描述 |
|---|---|
| 数据集 | 偏移使用机器学习数据集检索训练数据,并比较用于模型训练的数据。 生成数据概要文件是为了生成一些报告指标,例如最小值、最大值、非重复值、非重复值计数。 |
| Azureml 管道和计算 | 偏移计算作业托管在 azureml 管道中。 该作业按需或按计划触发,可以针对在创建偏移监视器时配置的计算运行。 |
| Application insights | 偏移会向属于机器学习工作区的 Application Insights 发出指标。 |
| Azure blob 存储 | 偏移会向 Azure Blob 存储发出 JSON 格式的指标。 |
基线和目标数据集
可以监视 Azure 机器学习数据集的数据偏移情况。 创建数据集监视器时,需引用:
- 基线数据集 - 通常为模型的训练数据集。
- 目标数据集 - 通常为模型输入数据 - 可以与一段时间内的基线数据集进行比较。 这种比较意味着必须为目标数据集指定一个时间戳列。
该监视器会比较基线和目标数据集。
创建目标数据集
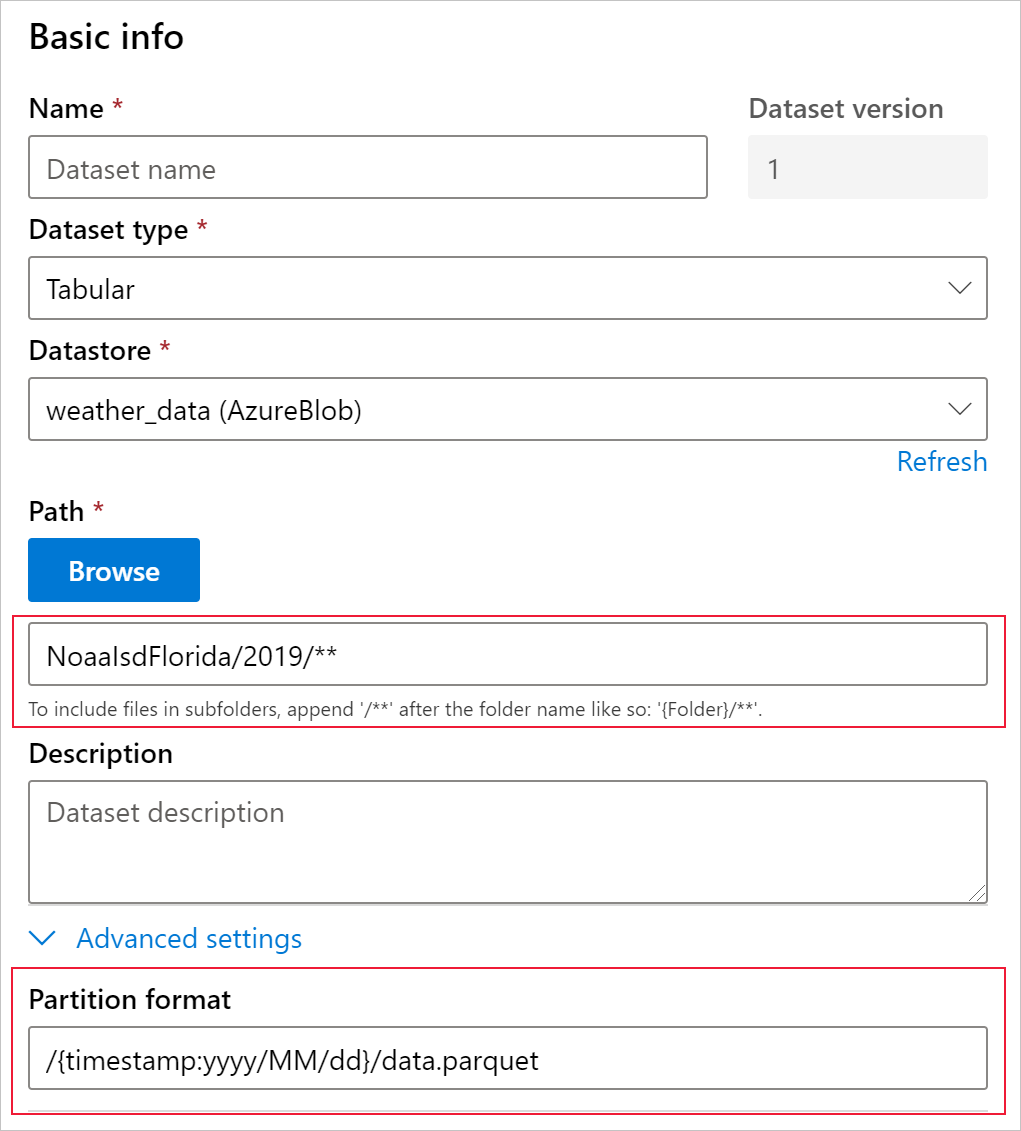
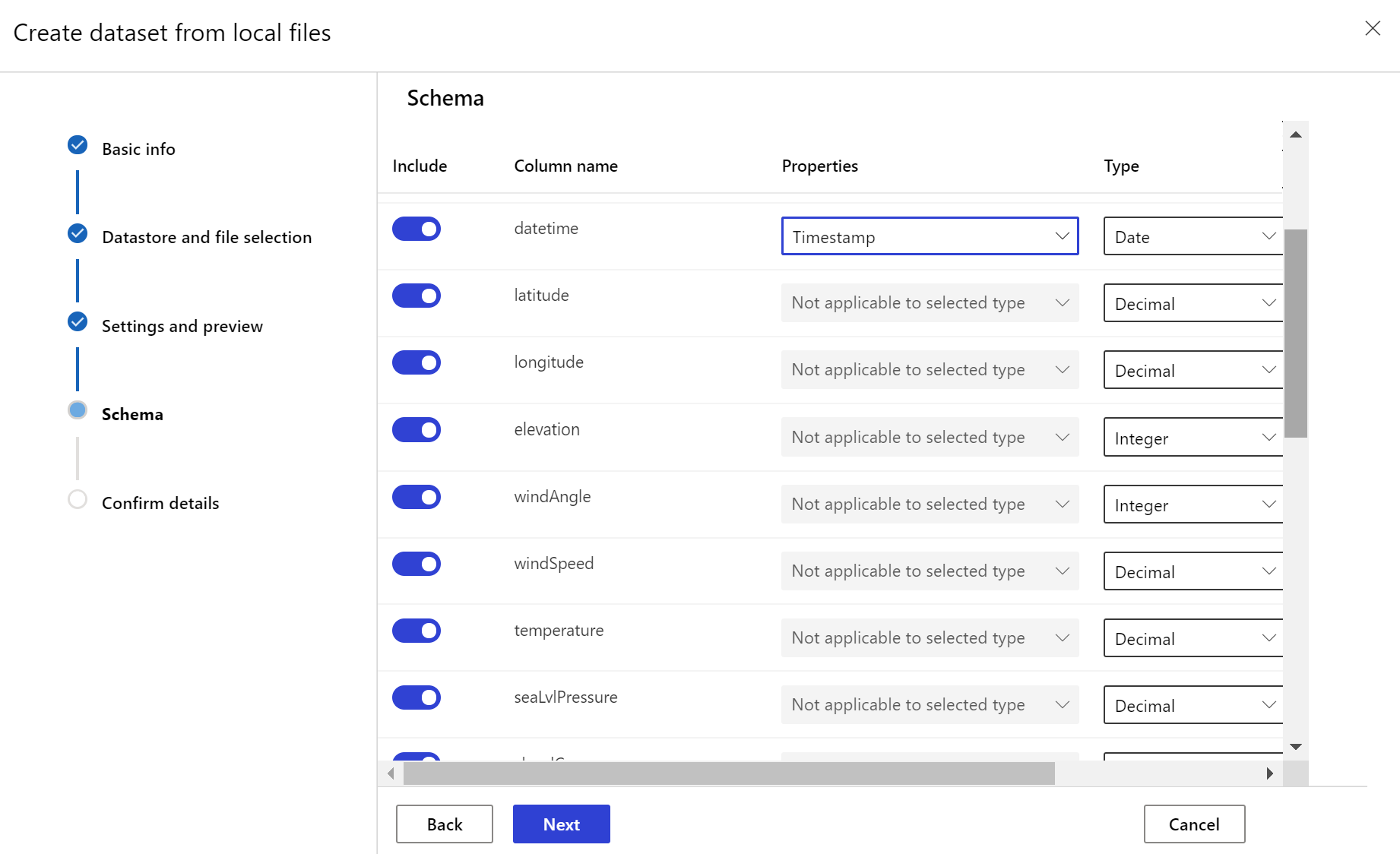
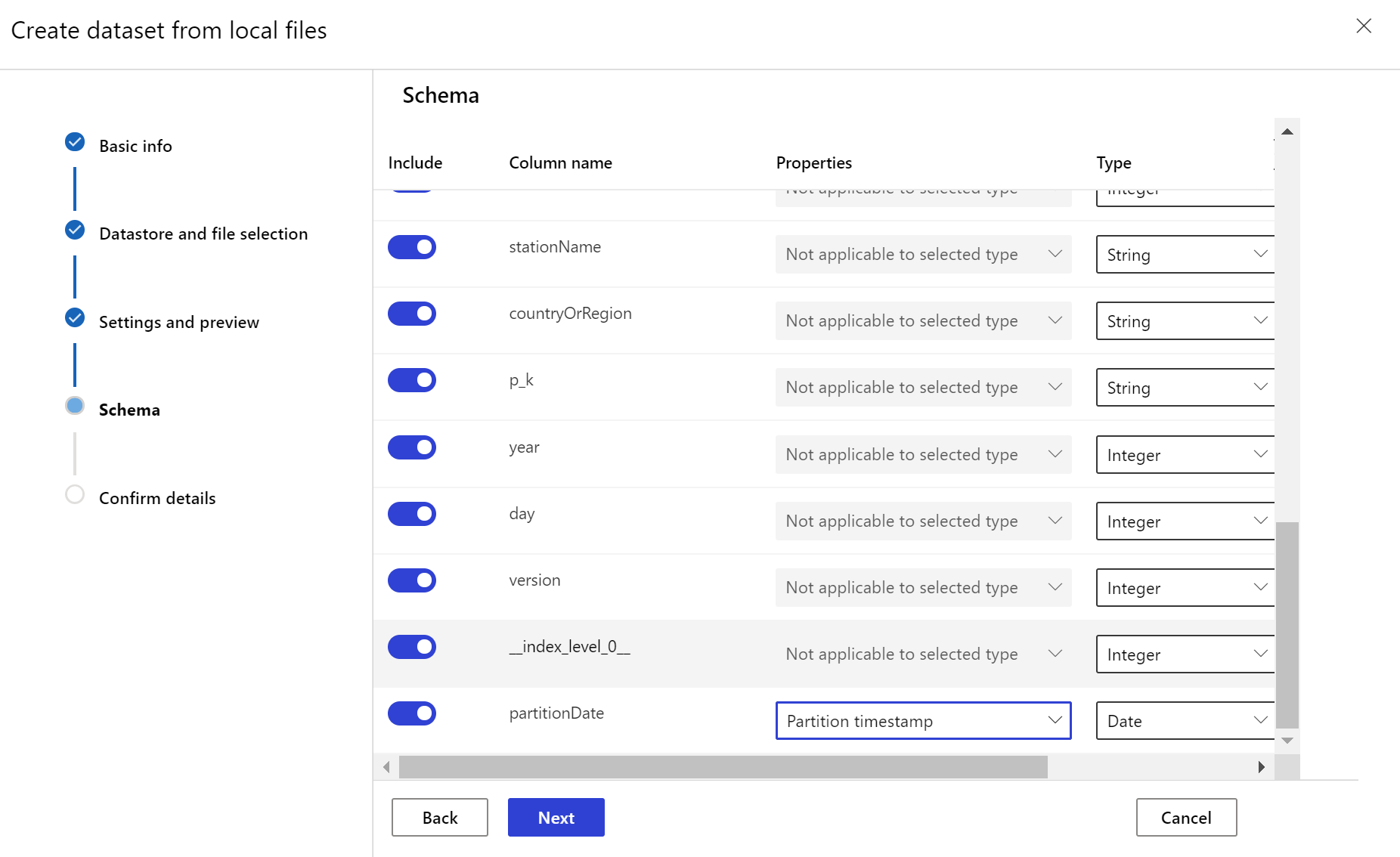
需要通过数据中的某个列或者派生自文件路径模式的某个虚拟列指定一个时间戳列,为目标数据集设置 timeseries 特征。 可通过 Python SDK 或 Azure 机器学习工作室创建带时间戳的数据集。 必须指定表示“时间戳”的列,才能向数据集添加 timeseries 特征。 如果数据已分区为包含时间信息(例如“{yyyy/MM/dd}”)的文件夹结构,请通过路径模式设置创建虚拟列,并将它设置为"分区时间戳"以启用时序 API 功能。
Dataset 类的 with_timestamp_columns() 方法定义数据集的时间戳列。
from azureml.core import Workspace, Dataset, Datastore
# get workspace object
ws = Workspace.from_config()
# get datastore object
dstore = Datastore.get(ws, 'your datastore name')
# specify datastore paths
dstore_paths = [(dstore, 'weather/*/*/*/*/data.parquet')]
# specify partition format
partition_format = 'weather/{state}/{date:yyyy/MM/dd}/data.parquet'
# create the Tabular dataset with 'state' and 'date' as virtual columns
dset = Dataset.Tabular.from_parquet_files(path=dstore_paths, partition_format=partition_format)
# assign the timestamp attribute to a real or virtual column in the dataset
dset = dset.with_timestamp_columns('date')
# register the dataset as the target dataset
dset = dset.register(ws, 'target')
提示
有关使用数据集的 timeseries 特征的完整示例,请参阅示例笔记本或数据集 SDK 文档。
创建数据集监视器
创建数据集监视器,以检测新数据集中的数据偏移并发出警报。 使用 Python SDK 或 Azure 机器学习工作室。
有关完整详细信息,请参阅有关数据偏移的 Python SDK 参考文档。
以下示例演示如何使用 Python SDK 创建数据集监视器
from azureml.core import Workspace, Dataset
from azureml.datadrift import DataDriftDetector
from datetime import datetime
# get the workspace object
ws = Workspace.from_config()
# get the target dataset
target = Dataset.get_by_name(ws, 'target')
# set the baseline dataset
baseline = target.time_before(datetime(2019, 2, 1))
# set up feature list
features = ['latitude', 'longitude', 'elevation', 'windAngle', 'windSpeed', 'temperature', 'snowDepth', 'stationName', 'countryOrRegion']
# set up data drift detector
monitor = DataDriftDetector.create_from_datasets(ws, 'drift-monitor', baseline, target,
compute_target='cpu-cluster',
frequency='Week',
feature_list=None,
drift_threshold=.6,
latency=24)
# get data drift detector by name
monitor = DataDriftDetector.get_by_name(ws, 'drift-monitor')
# update data drift detector
monitor = monitor.update(feature_list=features)
# run a backfill for January through May
backfill1 = monitor.backfill(datetime(2019, 1, 1), datetime(2019, 5, 1))
# run a backfill for May through today
backfill1 = monitor.backfill(datetime(2019, 5, 1), datetime.today())
# disable the pipeline schedule for the data drift detector
monitor = monitor.disable_schedule()
# enable the pipeline schedule for the data drift detector
monitor = monitor.enable_schedule()
提示
有关设置 timeseries 数据集和数据偏移检测器的完整示例,请参阅我们的示例笔记本。
了解数据偏移结果
本部分说明了数据集监视结果,这些结果可在 Azure 工作室中的“数据集 / 数据集监视器”页中找到。 你可以在此页上更新设置以及分析特定时间段内的现有数据。
首先大致了解数据偏移幅度,并突出显示要进一步调查的特征。
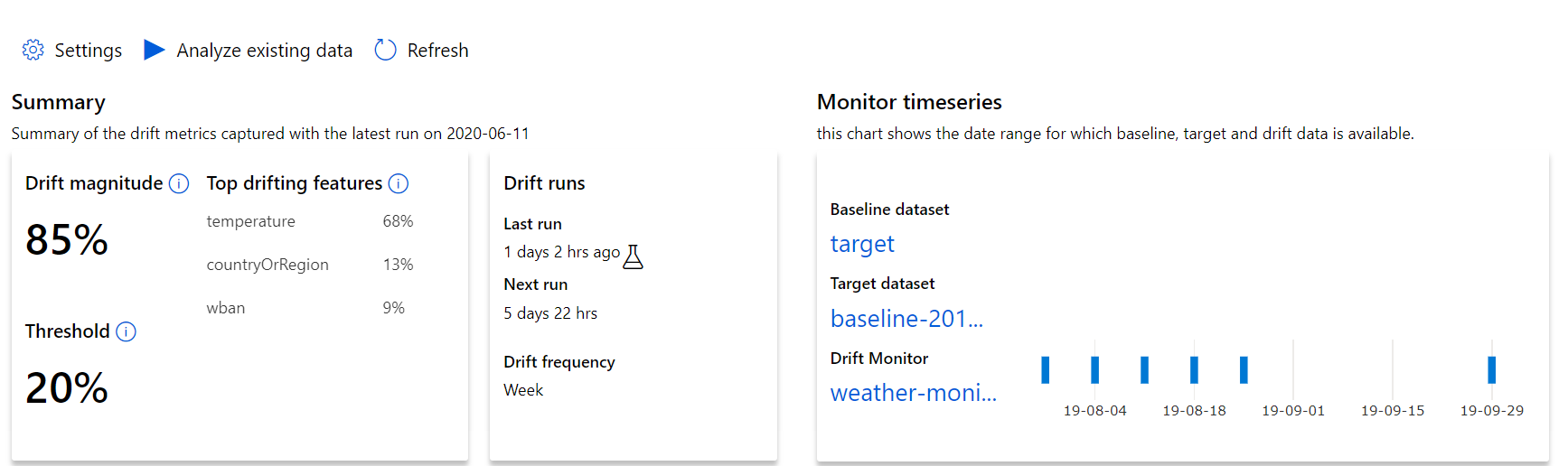
| 指标 | 描述 |
|---|---|
| 数据偏移幅度 | 一段时间内基线与目标数据集之间的偏移百分比。 范围为 0 到 100,0 表示数据集相同,100 表示 Azure 机器学习数据偏移模型可以完全区分两个数据集。 由于这种幅度是使用机器学习技术生成的,预期度量的精确百分比中存在干扰。 |
| 常见偏移特征 | 显示数据集中因偏移最大而对“偏移幅度”指标造成最大影响的特征。 由于共变偏移,特征的基础分布不一定需要改变即可获得相对较高的特征重要性。 |
| 阈值 | 数据偏移幅度超出设定阈值就会触发警报。 可在监视器设置中对其进行配置。 |
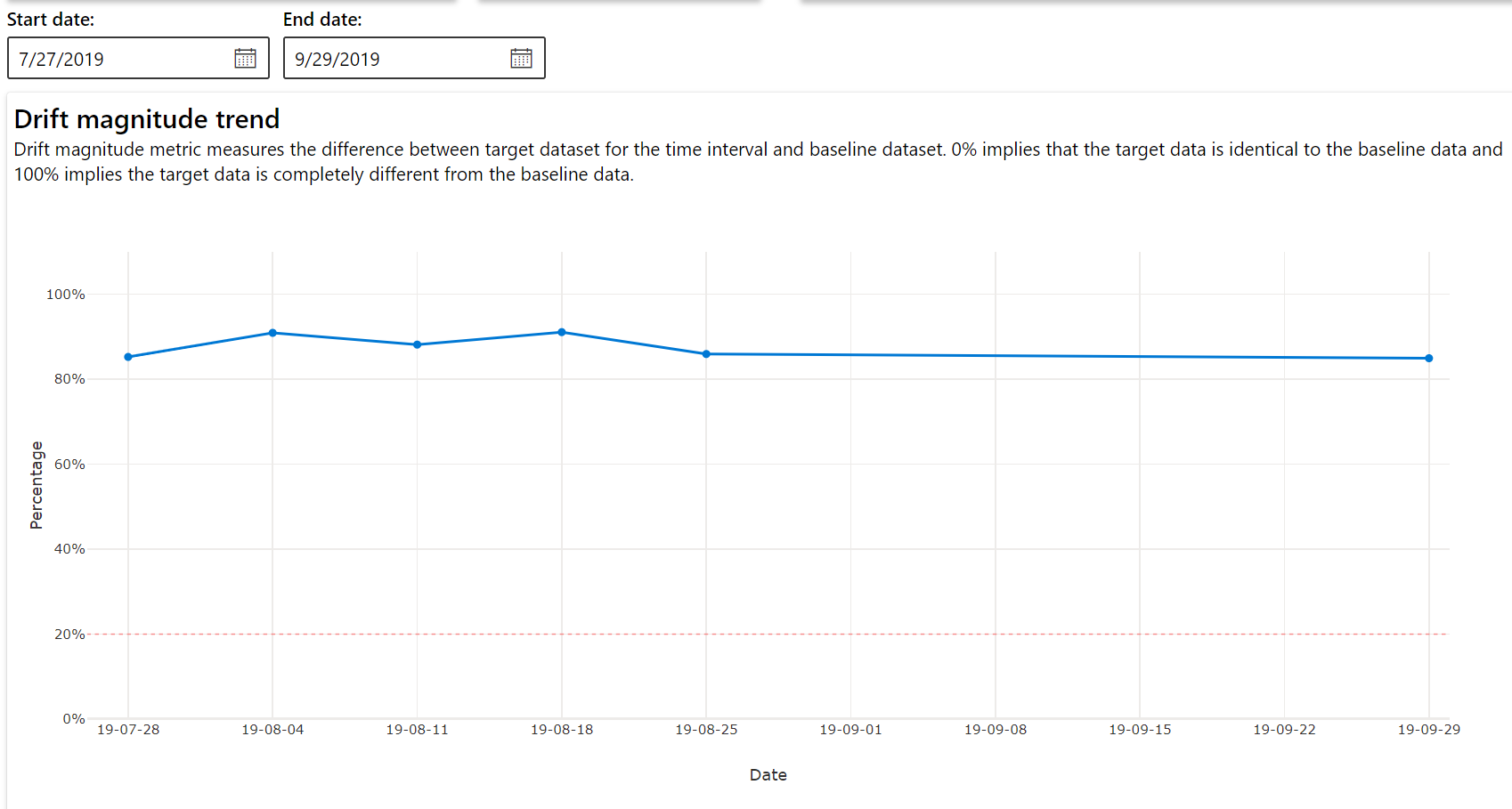
偏移幅度趋势
查看数据集与目标数据集在指定时段内的差异。 越接近 100%,两个数据集的差异越大。
偏移幅度(按特征)
此部分包含对所选特征的分布变化的特征级见解,以及一段时间内的其他统计信息。
此外,将分析一段时间内的目标数据集。 将把一段时间内每个特征的基线分布之间的统计距离与目标数据集的相应距离进行比较。 这在概念上类似于数据偏移幅度。 但是,此统计距离适用于单个特征而非所有特征。 还可以使用最小值、最大值和平均值。
在 Azure 机器学习工作室中,单击条形图中的条可查看该日期的功能级别详细信息。 默认情况下,可以看到基线数据集的分布,以及同一特征的最近作业的分布。
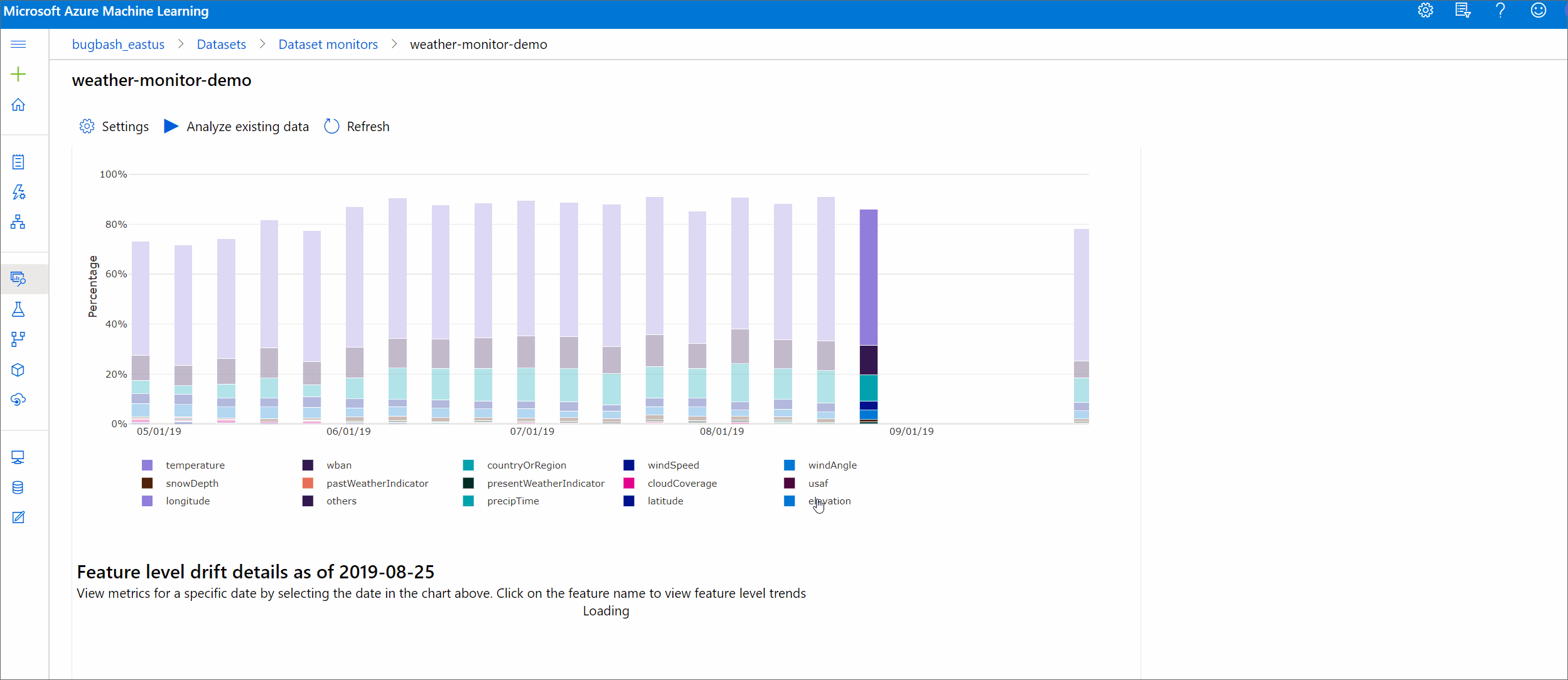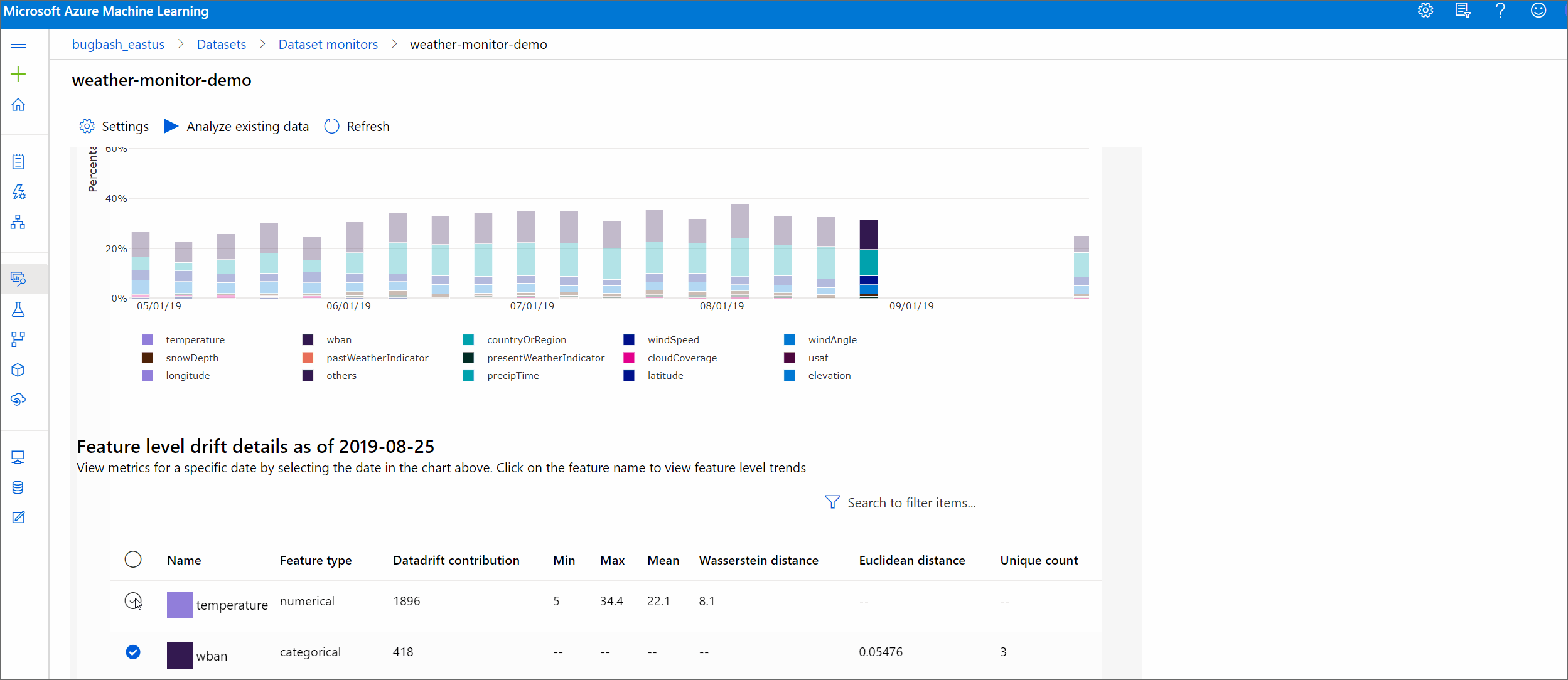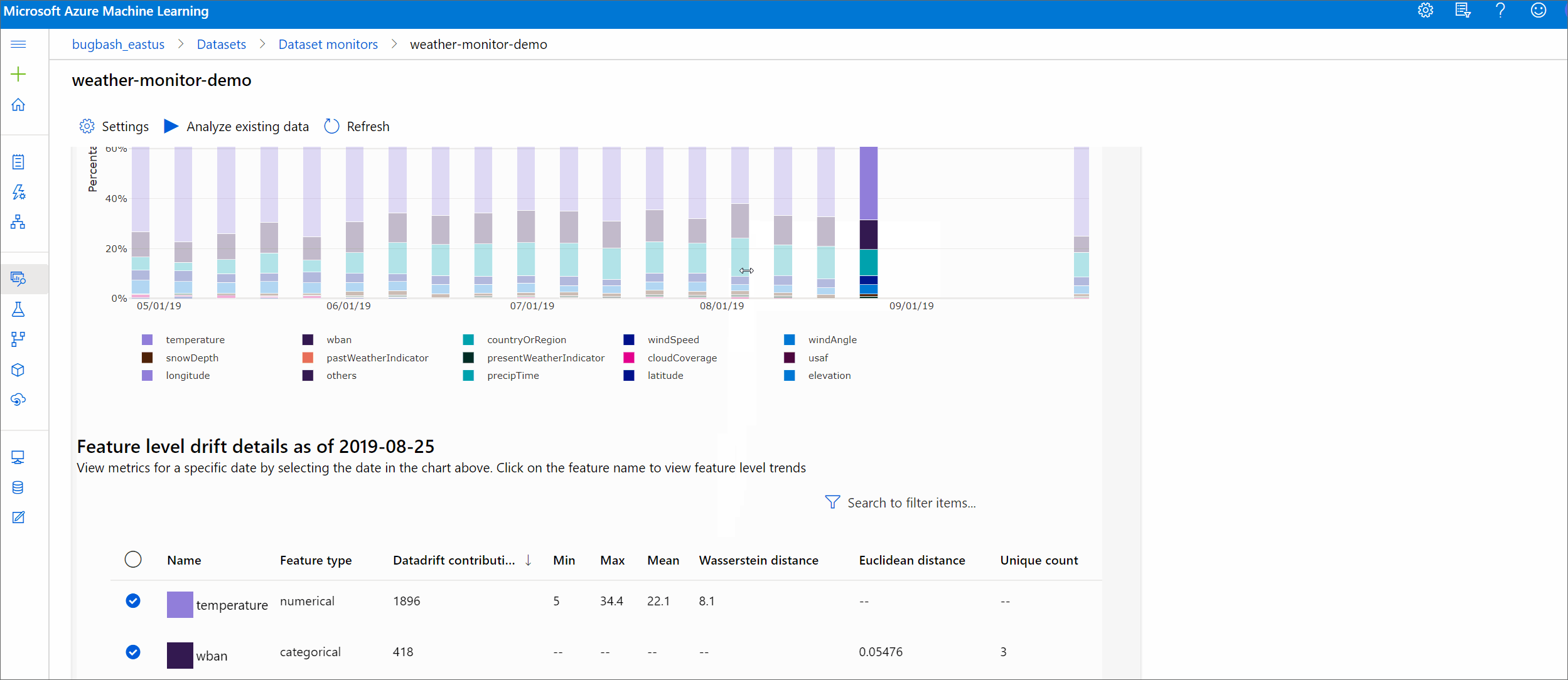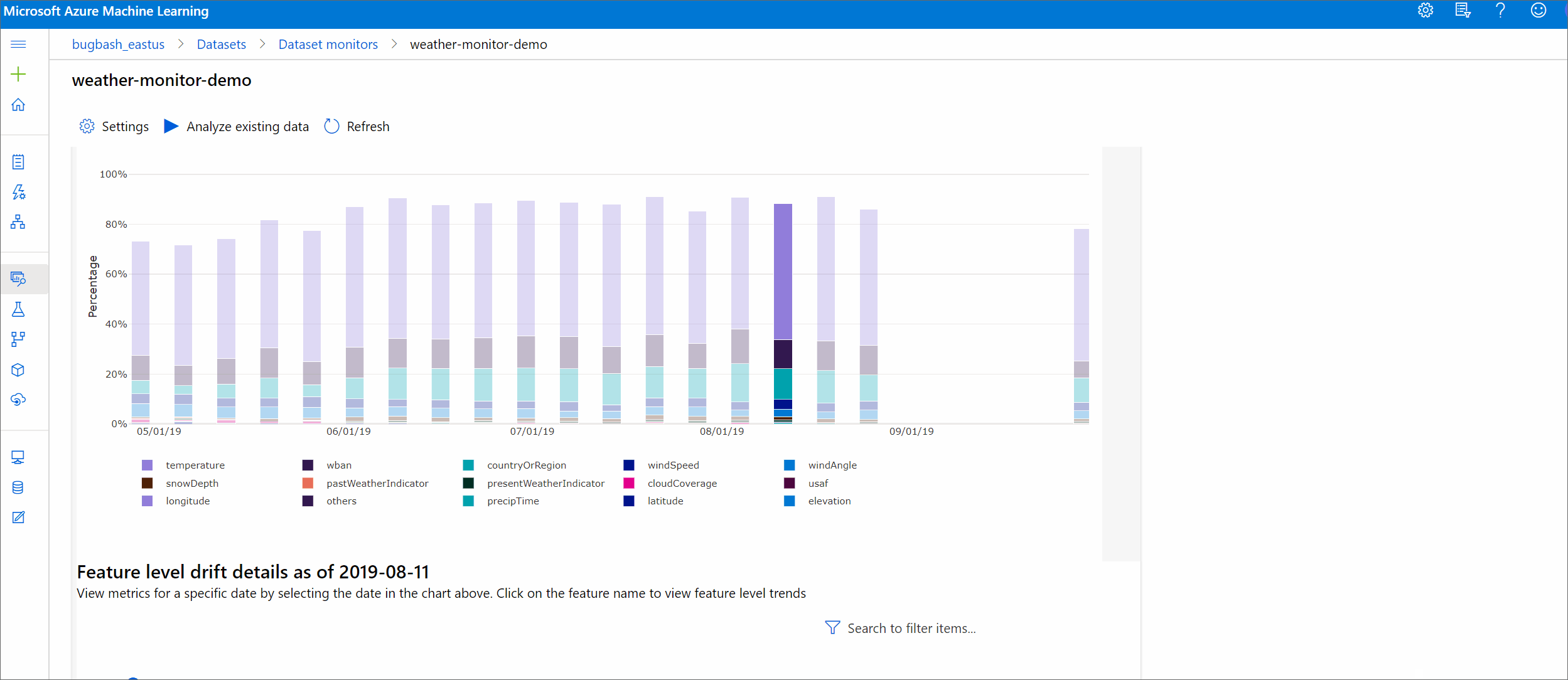
也可以在 Python SDK 中通过对 DataDriftDetector 对象运行 get_metrics() 方法检索这些指标。
特征详细信息
最后,可通过向下滚动来查看每个单独特征的详细信息。 可使用图表上方的下拉列表选择特征,并另外选择要查看的指标。
图表中的指标取决于特征的类型。
数字特征
指标 说明 Wasserstein 距离 将基线分布转换为目标分布的最小工作量。 平均值 特征的平均值。 最小值 特征的最小值。 最大值 特征的最大值。 分类特征
指标 说明 Euclidian 距离 针对分类列进行的计算。 欧氏距离基于两个矢量进行计算,这两个矢量是根据两个数据集中同一分类列的经验分布生成的。 0 表示经验分布没有差别。 与 0 的偏差越大,该列的偏移程度越大。 对此指标进行时序绘图即可观察相关趋势,并可利用这些趋势来发现偏移特征。 唯一值 特征的唯一值(基数)数目。
在此图表中,可以选择单个日期来比较目标与所显示特征的此日期之间的特征分布。 对于数值特征,这会显示两个概率分布。 如果特征为数值,则显示条形图。
指标、警报和事件
可以在与机器学习工作区关联的 Azure Application Insights 资源中查询指标。 可以访问 Application Insights 的所有功能,包括设置自定义警报规则和操作组,以触发电子邮件/短信/推送/语音或 Azure 函数等操作。 有关详细信息,请参阅完整的 Application Insights 文档。
若要开始,请导航到 Azure 门户并选择工作区的“概览”页。 关联的 Application Insights 资源位于最右侧:
在左侧窗格中选择“监视”下的“日志(分析)”:
数据集监视器指标存储为 customMetrics。 可以在设置数据集监视器之后编写和运行查询来查看指标:
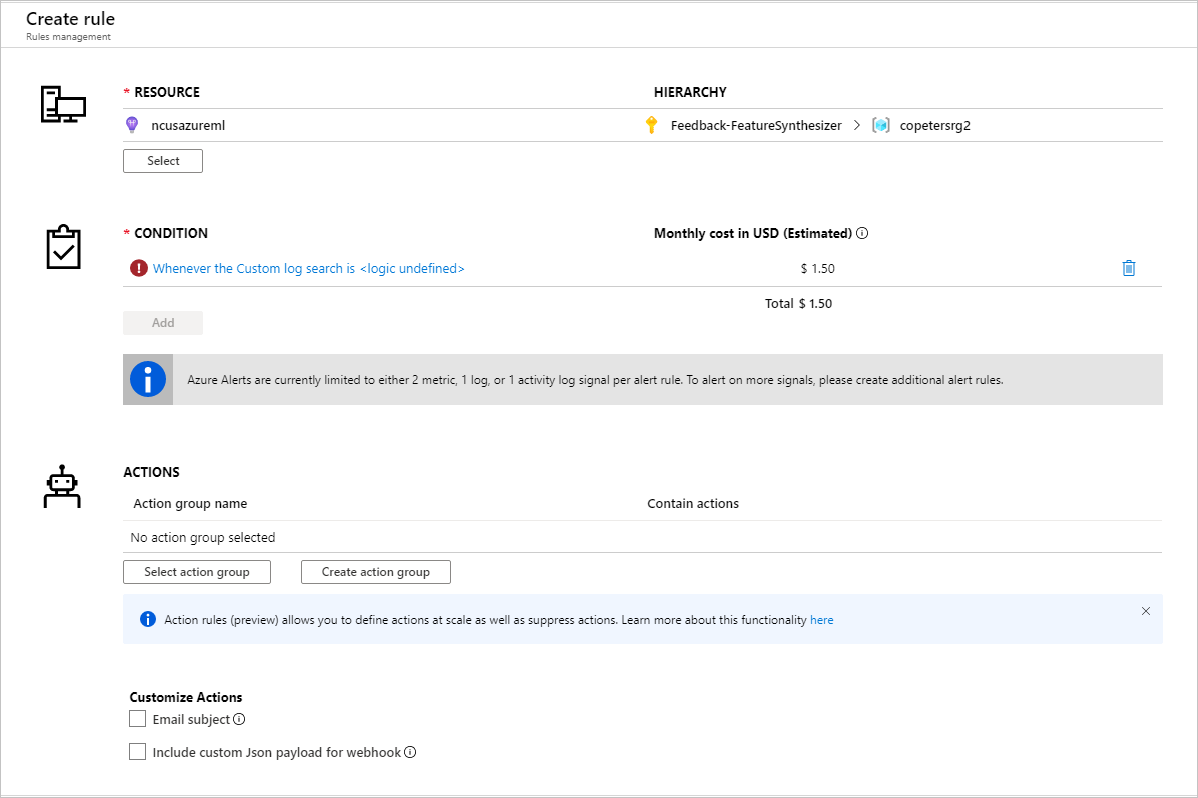
识别要对其设置警报规则的指标后,创建新的警报规则:
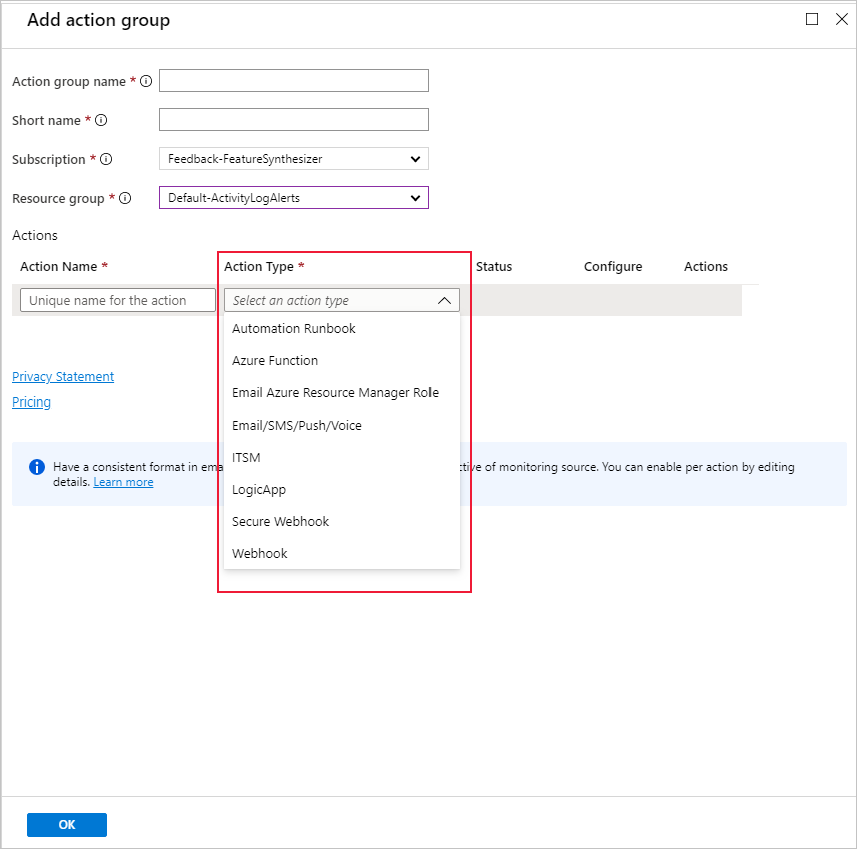
可以使用现有操作组或创建一个新操作组来定义满足设置的条件时要执行的操作:
疑难解答
数据偏移监视器的限制和已知问题:
分析历史数据时的时间范围限制为监视器频率设置的 31 个间隔。
除非未指定特征列表(使用所有特征),否则特征限制为 200 个。
计算大小必须足够大才能处理数据。
确保数据集包含处于给定监视器作业的开始和结束日期范围内的数据。
数据集监视器仅适用于包含 50 行或更多行的数据集。
数据集中的列或特征根据下表中的条件划分为分类值或数字值。 如果特征不满足这些条件 - 例如,某个字符串类型的列包含 100 个以上的唯一值 - 则会从数据偏移算法中删除该特征,但仍会对其进行分析。
特征类型 数据类型 条件 限制 分类 string、bool、int、float 特征中的唯一值数小于 100,并小于行数的 5%。 Null 被视为其自身的类别。 数值 int、float 特征中的值为数字数据类型,且不符合分类特征的条件。 如果 15% 以上的值为 null,则会删除特征。 创建了数据偏移监视器,但无法在 Azure 机器学习工作室的“数据集监视器”页上看到数据时,请尝试以下操作。
- 检查是否已在页面顶部选择了正确的日期范围。
- 在“数据集监视器”选项卡上,选择试验链接以检查作业状态。 此链接位于表的最右侧。
- 如果作业已成功完成,请检查驱动程序日志,以便查看已生成的指标数,或者查看是否有任何警告消息。 单击试验后,在“输出 + 日志”选项卡中查找驱动程序日志。
如果 SDK
backfill()函数未生成预期的输出,则可能是由于身份验证问题。 创建要传入到此函数中的计算时,请勿使用Run.get_context().experiment.workspace.compute_targets, 而应使用 ServicePrincipalAuthentication(例如以下代码)来创建要传入到该backfill()函数中的计算:auth = ServicePrincipalAuthentication( tenant_id=tenant_id, service_principal_id=app_id, service_principal_password=client_secret ) ws = Workspace.get("xxx", auth=auth, subscription_id="xxx", resource_group="xxx") compute = ws.compute_targets.get("xxx")在模型数据收集器中,数据到达 blob 存储帐户最多需要(但通常不到)10 分钟。 在脚本或笔记本中,等待 10 分钟,以确保运行以下单元。
import time time.sleep(600)
后续步骤
- 转到 Azure 机器学习工作室或 Python 笔记本来设置数据集监视器。
- 了解如何在部署到 Azure Kubernetes 服务的模型中设置数据偏移。
- 使用事件网格设置数据集偏移监视器。