将负责任的 AI 仪表板链接到已注册的模型。 要查看负责任的 AI 仪表板,请前往您的模型注册表,并选择您已为其生成负责任的 AI 仪表板的注册模型。 然后选择“负责任 AI”选项卡查看生成的仪表板列表。

可以配置多个仪表板并将其附加到已注册的模型。 将组件的各种组合(例如可解释性、错误分析和因果分析)附加到每个负责任的 AI 仪表板。
下图显示了仪表板的自定义和在其中生成的组件。 在每个仪表板中,可以在仪表板 UI 本身中查看或隐藏各种组件。

选择仪表板的名称,在浏览器中以完整视图将其打开。 若要返回到仪表板列表,请选择“ 返回模型详细信息”。

先决条件
在打开“负责任的 AI”仪表板之前,请确保您已具备以下条件:
- 一份 Azure 订阅。 如果没有 Azure 订阅,可在开始前创建一个试用帐户。
- Azure 机器学习工作区和计算实例。 完成创建入门所需的资源即可同时创建这两者。
- 已注册模型,并生成了“负责任的 AI”仪表板。 若要创建或更新其中一个,请参阅 工作室 UI 中的“生成负责任的 AI 见解 ”,或使用 SDK 或 CLI 生成负责任的 AI 见解。
- 工作区中用于查看模型和启动计算实例的权限。 例如,工作区范围内的 参与者 或 所有者 可以启动计算实例。 若要获得最低特权访问,请结合使用 读取器 (查看资产)和 AzureML 计算操作员 (用于管理计算)。 有关详细信息,请参阅管理对 Azure 机器学习工作区的访问。
- 所需的网络访问以便您的组织访问 Azure Machine Learning Studio 并连接到计算实例。 如果工作区使用网络隔离(例如托管虚拟网络或具有专用终结点的虚拟网络),请确保允许所需的入站和出站流量。 有关详细信息,请参阅 “规划 Azure 机器学习中的网络隔离 ”,以及 使用虚拟网络保护 Azure 机器学习工作区。
完整功能得益于集成计算资源
“负责任的 AI”仪表板的某些功能需要动态和实时计算,例如假设分析。 如果未将计算资源连接到仪表板,可能会发现缺少某些功能。 连接到计算资源时,将为以下组件启用负责任 AI 仪表板的全部功能:
-
错误分析
- 将全局数据队列设置为任何感兴趣的队列会更新错误树,而不是禁用它。
- 支持选择其他错误或性能指标。
- 支持选择用于训练错误树图的任何特征子集。
- 支持更改每个叶节点所需的最小样本数和错误树深度。
- 支持在最多两个特征上动态更新热度地图。
-
功能重要性
- 支持“单个特征重要性”选项卡中的单个条件期望 (ICE) 图。
-
反事实 what-if
- 支持生成新的 what-if 反事实数据点,从而了解实现所需结果所需的最小更改。
-
因果分析
- 选择任何单个数据点,干扰其处理特征,并查看支持因果假设结果的预期因果结果。 此分析仅适用于回归机器学习方案。
还可以通过在负责任 AI 仪表板页上选择“信息”图标找到此信息,如下图所示:

启用负责任 AI 仪表板的全部功能
若要连接计算实例并在仪表板中解锁实时功能,请完成以下步骤:
在仪表板顶部的 “计算 ”列表中选择正在运行的计算实例。 如果没有正在运行的计算,请通过选择下拉列表旁边的加号(+)创建新的计算实例。 或者,可以选择 “启动计算 ”以启动已停止的计算实例。 创建或启动计算实例可能需要几分钟时间。

计算处于“正在运行”状态后,负责任 AI 仪表板将开始连接到该计算实例。 为了实现此连接,仪表板会在所选计算实例上创建终端进程,并在终端上启动负责任的 AI 终结点。 选择“查看终端输出”以查看当前终端进程。

当 Responsible AI 仪表板连接到计算实例时,您会看到一条绿色信息栏。 仪表板现已完全正常运行。

如果连接计算实例的过程耗时过长或仪表板显示红色错误消息栏,则表示启动负责任的 AI 终结点时出现问题。 选择“查看终端输出”,并向下滚动至底部以查看错误消息。

如果无法确定如何解决 无法连接到计算实例 的问题,请选择右上角的 “微笑 ”图标。 向我们提交有关你遇到的任何错误或问题的反馈。 可以在反馈表单中包含屏幕截图和电子邮件地址。




负责任的 AI 仪表板的 UI 概述
“负责任的 AI”仪表板提供了一组丰富的可视化效果和功能,可帮助你分析机器学习模型并做出数据驱动的业务决策。 其中包括:
全局控件
在仪表板顶部,可以创建队列,这些 队列是共享指定特征的数据点的子组。 使用队列集中分析每个组件。 仪表板总是在左上角显示当前应用于仪表板的群组名称。 仪表板中的默认视图是整个数据集,标题为“所有数据(默认值)”。

- 队列设置:查看和修改每个队列的详细信息。
- 仪表板配置:查看和修改整个仪表板的布局。
- 切换队列:选择其他队列并在弹出窗口中查看其统计信息。
- 新队列:在仪表板中创建并添加新队列。
若要打开包含队列列表的窗格,请选择 “队列设置”。 在此区域中,可以创建、编辑、复制或删除队列。

若要打开包含筛选以下值的选项的新窗格,请选择仪表板顶部或队列设置中的“新建队列”。
- 索引:按数据点在完整数据集中的位置进行筛选。
- 数据集:按数据集中特定特征的值进行筛选。
- 预测 Y:根据模型的预测进行筛选。
- True Y:按目标功能的实际值进行筛选。
- 错误(回归):按错误筛选(或 分类结果(分类):按分类的类型和准确性进行筛选。
- 分类值:按应该包含的值列表进行筛选。
- 数值:按布尔运算对值进行筛选。 例如,选择年龄 < 为 64 的数据点。

可以命名新的数据集队列,选择 “添加筛选器” 以添加要使用的每个筛选器,然后执行以下步骤之一:
- 选择“保存”以将新队列保存到队列列表中。
- 选择保存并切换以将仪表板的全局队列保存并切换为新创建的队列。

若要查看仪表板上配置的组件列表,请选择 “仪表板配置”。 可以通过选择“垃圾桶”图标隐藏仪表板上的组件,如下图所示:

可以使用每个组件之间的分隔符中的蓝色圆形加号(+)图标将组件添加回仪表板,如下图所示:

错误分析
后续部分介绍如何解释和使用错误树映射和热度地图。
错误树图
错误分析组件的第一个选项卡是树状图。 它通过树形可视化展示了模型失败如何在各种队列中分布。 选择任意节点以查看发现错误的特征的预测路径。

- 热度地图视图:切换到错误分布的热度地图可视化效果。
- 功能列表:修改热度地图中使用的功能。
- 错误覆盖率:显示集中于所选节点的数据集中所有错误的百分比。
- 错误(回归)或错误率(分类):显示所选节点中所有数据点的错误或失败百分比。
- 节点:表示数据集队列(可能应用了筛选器),以及队列中数据点总数中的错误数。
- 填充线:根据筛选器将数据点的分布可视化为子队列,数据点的数目通过线条粗细表示。
- 选择信息:包含有关所选节点的信息。
- 另存为新队列:使用指定的筛选器创建新的队列。
- 基队列中的实例:显示整个数据集中的点总数以及正确且错误预测的点数。
- 所选队列中的实例:显示所选节点中的点总数以及正确且错误预测的点数。
- 预测路径(筛选器):列出施加在完整数据集上的筛选器,以创建此较小队列。
选择 功能列表 以打开 功能列表。 可以针对特定特性重新训练错误树。

- 搜索功能:查找数据集中的特定功能。
- 特征:列出数据集中特征的名称。
- 重要性:有关特征与错误的相关性的指导。 通过使用特征与标签上的错误之间的互信息评分进行计算。 使用此分数可帮助你确定在错误分析中选择哪些功能。
- 复选标记:添加或删除树状图中的功能。
- 最大深度:针对错误训练的代理树的最大深度。
- 叶数:针对错误训练的代理树的叶数。
- 一个叶中的最小样本数:创建一个叶所需的最小数据量。
错误热度地图
选择“热度地图”选项卡切换到数据集中错误的不同视图。 可以选择一个或多个热度地图单元并创建新的队列。 可以选择最多两个特征来创建热度地图。

- 单元格:显示所选单元格的数目。
- 错误覆盖率:显示集中在所选单元格中的所有错误的百分比。
- 错误率:显示所选单元格中所有数据点失败百分比。
- 轴特征:选择要在热度地图中显示的特征的交集。
- 单元:表示数据集队列(应用了筛选器),以及队列中数据点总数中错误的百分比。 蓝色边框表示所选单元,红色边框的暗处表示故障的集中。
- 预测路径(筛选器):列出施加在每个选定队列的完整数据集上的筛选器。
模型概述和公平性指标
模型概述组件提供一组全面的性能和公平性指标,用于评估模型。 它还为指定特征和数据集的各群体提供关键性能差异指标。
数据集队列
在 “数据集队列 ”页上,可以通过比较各种用户指定的数据集队列的模型性能来调查模型。 可以通过仪表板右上角的 “队列设置” 图标访问这些队列。

- 帮助我选择指标:选择此图标,了解有关可在表中显示哪些模型性能指标的详细信息。 通过使用多选列表调整要查看的指标,从而选择或取消选择性能指标。
- 显示热度地图:打开和关闭以显示或隐藏表格中的热度地图可视化效果。 热度地图的渐变对应于每个列中的最小值和最大值之间的规范化范围。
- 每个数据集队列的指标表:查看数据集队列的列、每个队列的样本大小,以及每个队列的选定模型性能指标。
- 可视化单个指标的条形图:查看不同队列的平均绝对误差,以方便比较。
- 选择指标(x 轴):选择要在条形图中查看的指标。
- 选择队列(y 轴):选择要在条形图中查看的队列。 除非首先在组件的“功能队列”选项卡上指定所需功能,否则可能会禁用功能队列选择。
选择 帮助我选择指标 查看模型性能指标及其定义。 此列表可帮助你选择要查看的正确指标。
| 机器学习方案 | 指标 |
|---|---|
| 回归 | 平均绝对误差、均方误差、R 平方、平均值预测。 |
| 分类 | 准确度、精准率、召回率、F1 分数、误报率、漏报率、选择率。 |
特征队列
在 功能队列 页上,可以通过比较用户指定的敏感和不区分功能的模型性能来调查模型。 例如,可以比较不同性别、种族和收入水平群体的性能。

帮助我选择指标:选择此图标可查看有关表中显示的指标的详细信息。 通过使用多选列表调整要查看的指标,从而选择或取消选择性能指标。
帮助我选择功能:选择此图标可查看有关可在表中显示哪些功能的详细信息。 该窗格包括每个特性的描述符及其分箱能力。 通过使用多选列表选择和取消选中要查看的功能。
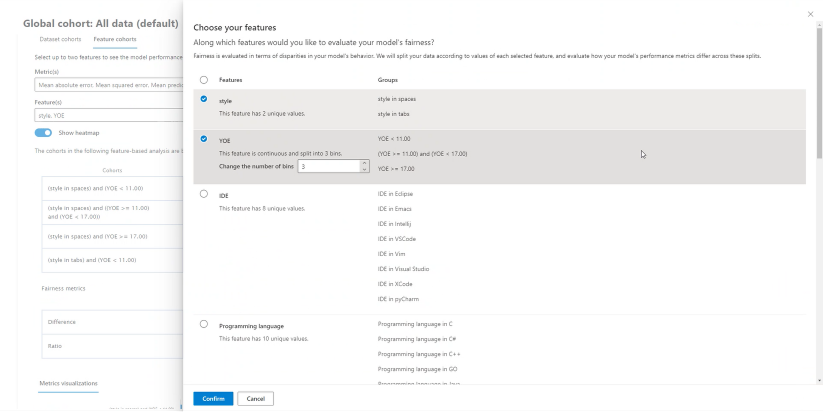
显示热度地图:打开和关闭此项可查看热度地图可视化效果。 热度地图的渐变对应于每个列中的最小值和最大值之间的规范化范围。
每个功能队列的指标表:一个表,其中包含特征队列(所选特征的子队列)、每个队列的示例大小以及每个特征队列的所选模型性能指标。
公平性指标/差异指标:与指标表相对应的表,显示任意两个特征队列之间性能分数的最大差异或最大比率。
可视化单个指标的条形图:查看不同队列的平均绝对误差,以方便比较。
选择队列(y 轴):选择要在条形图中查看的队列。
选择 “选择队列 ”将打开一个窗格,其中包含显示所选数据集队列或特征队列的比较选项。 选择取决于在多选下拉列表中选择的内容。 选择“确认”以保存对条形图视图的更改。
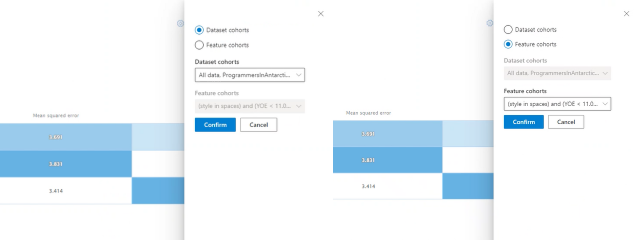
选择指标(x 轴):选择要在条形图中查看的指标。


数据分析
在数据分析组件中, 表视图 显示数据集的所有功能和行的表视图。
图表视图显示数据点的聚合和单个绘图。 你可以使用预测结果、数据集特征和错误组等筛选器来分析 x 轴和 y 轴上的数据统计信息。 此视图可帮助你了解数据集中的表示过度和表示不足。

选择要浏览的数据集队列:指定队列列表中要查看其数据统计信息的数据集队列。
X 轴:显示水平绘制的值的类型。 通过选择按钮打开侧窗格来修改值。
Y 轴:显示垂直绘制的值的类型。 通过选择按钮打开侧窗格来修改值。
图表类型:指定图表类型。 在聚合图(条形图)或单个数据点(散点图)之间进行选择。
选择“图表类型”下的“单个数据点”选项可以切换到提供颜色轴的非聚合视图。

特征重要性(模型说明)
使用模型解释组件可以查看模型预测中最重要的特征。 可以在“聚合特征重要性”窗格中查看影响模型总体预测的特征,或在“单个特征重要性”窗格中查看单个数据点的特征重要性。
聚合特征重要性(全局说明)

前 k 个特征:列出预测中最重要的全局特征,你可以通过滑块更改 k 值。
聚合特征重要性:可视化每个特征在影响所有预测中的模型决策方面的权重。
排序依据:选择用于对聚合特征重要性图表进行排序的队列特征重要性。
图表类型:在每个特征的平均重要性条形图视图和所有数据重要性框图之间进行选择。
在条形图中选择一个特征时,将填充依赖关系图,如下图所示。 此依赖关系图显示特征值与其影响模型预测的相应特征重要性值之间的关系。
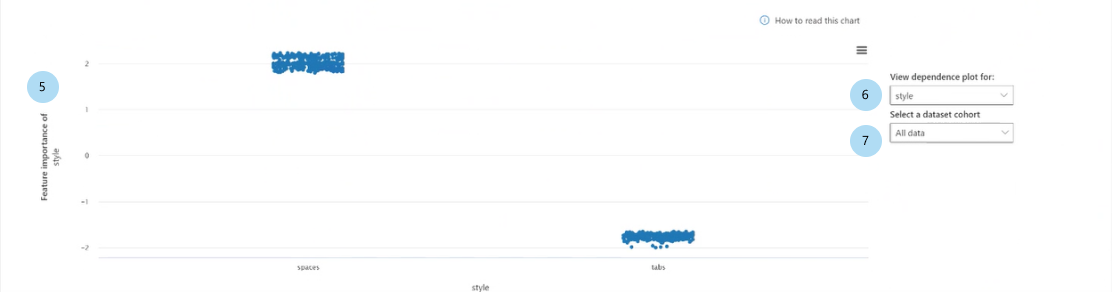
[特征] 的特征重要性(回归)或 [特征] 对于 [预测类] 的特征重要性(分类):绘制预测中特定特征的重要性。 对于回归方案,重要性值与输出有关,因此特征重要性为正意味着它对输出有积极作用。 而对于特征重要性为负的情况则正好相反。 对于分类方案,特征重要性为正意味着特征值对 y 轴标题中所示的预测类有用。 特征重要性为负则意味着它对预测类不利。
查看依赖关系图:选择要绘制其重要性的特征。
选择数据集队列:选择要绘制其重要性的队列。

单个特征重要性(局部说明)
下图演示了特征如何影响对特定数据点做出的预测。 可以选择最多五个数据点来比较特征重要性。

点选择表:查看数据点,并选择最多五个点,以在特征重要性图或 ICE 绘图中显示。

特征重要性图:模型对选定数据点做出预测所用的每个特征的重要性的条形图。
- Top k 特征:通过滑块指定要显示重要性的特征数量。
- 排序依据:从已选中的点中选择一个点,这些点在特征重要性图中按特征重要性降序显示。
- 查看绝对值:打开此项可按绝对值将条形图排序。 此设置允许你查看影响最大的功能,而不考虑其正向或负方向。
- 条形图:显示数据集中每个特征对于选定数据点的模型预测的重要性。
单个条件期望 (ICE) 图:切换到 ICE 图,其中显示特定特征的一系列值的模型预测。

- 最小值(数值特征):指定 ICE 图中预测范围的下限。
- 最大值(数值特征):指定 ICE 图中预测范围的上限。
- 步骤(数值特征):指定要在间隔内显示其预测的点数。
- 特征值(分类特征):指定要显示其预测的分类特征值。
- 特征:指定要为其进行预测的特征。
反事实 what-if
反事实分析提供了一组不同的“what-if”示例,这些示例通过最小程度地更改特征值以生成所需的预测类(分类)或范围(回归)生成。

点选择:选择要为之创建对抗事实并在顶部特征绘图中显示的点。
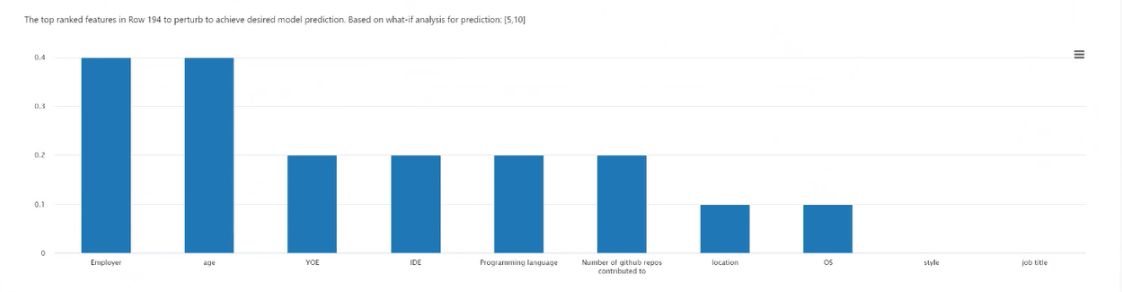
排名靠前的特征图:按平均频率的降序顺序显示要干扰的特征,以创建所需类的不同反事实集。 由于缺乏准确性且反事实数量较少,因此必须为每个数据点生成至少 10 个不同的反图,才能启用此图表。
所选数据点:执行与表中的点选择相同的操作,但下拉菜单除外。
反事实的所需类:指定要为其生成反事实的类或范围。
创建假设情景的反事实:打开用于创建反事实数据点的窗格。
选择创建 what-if 反事实按钮以打开完整页面。
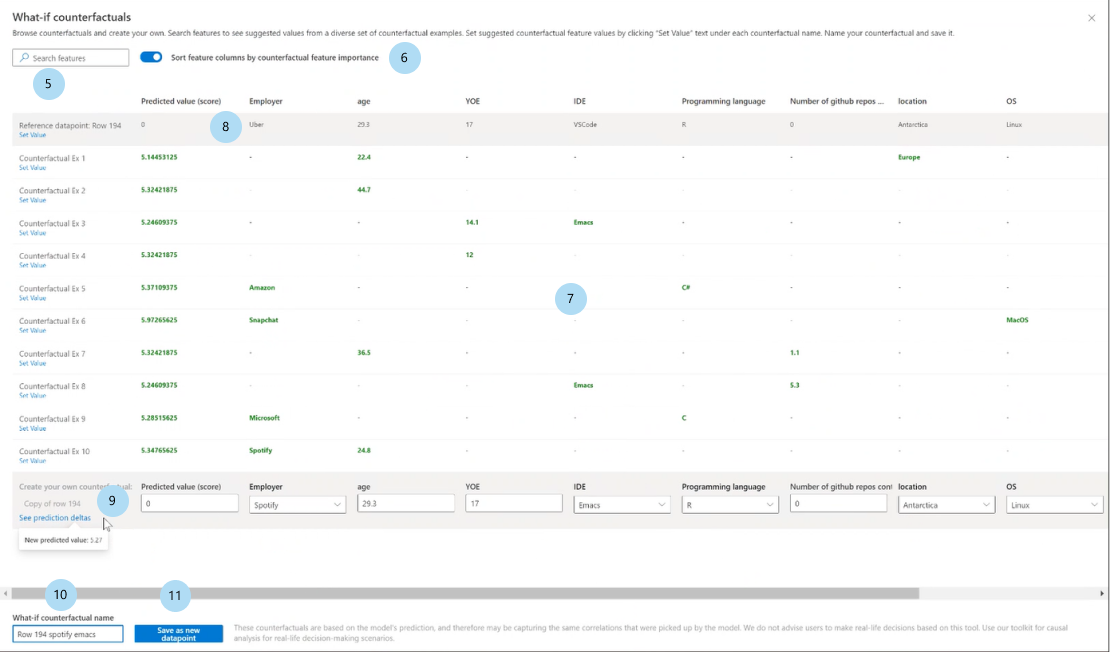
搜索特征:查找要观察并更改值的特征。
按排名特征对反事实进行排序:按扰动效应的顺序对反事实示例进行排序。 另请参阅 排名靠前的特征图,前面已讨论。
反事实示例:列出具有所需类或范围的示例反事实的特征值。 第一行是原始参考数据点。 选择 设置值 ,将你自己的反事实数据点在底行的所有值设置为预生成反事实示例的值。
预测值或类:列出获得这些已更改特征的反事实类的模型预测。
创建自己的反事实:允许干扰自己的特征来修改反事实。 通过标题加粗来表示您对原始特征值进行更改的特征,例如 雇主 和 编程语言。 选择“查看预测增量”查看新预测值与原始数据点的差异。
What-if 反事实名称:允许为反事实提供唯一的名称。
另存为新数据点:保存您创建的反事实。


因果分析
下一部分介绍如何在选择用户指定的治疗时读取数据集的因果分析。
聚合因果效应
选择因果分析组件的 “聚合因果效应 ”选项卡,以显示预定义治疗特征的平均因果效应。 这些功能是你想要处理以优化结果的功能。
注意
因果分析组件不支持全局队列功能。

直接聚合因果效应表:显示在整个数据集上聚合的每个特征的因果效应以及相关的置信度统计信息。
- 连续处理:在此示例中,平均而言,将此功能增加一个单位会导致类的概率增加 X 单位,其中 X 是因果效应。
- 二元处理:在此示例中,打开此功能会导致类的概率增加 X 单位,其中 X 是因果效应。
直接聚合因果效应须状图:可视化表中的点的因果效应和置信区间。
单个因果效应和因果 what-if
要查看单个数据点的因果效应精细视图,请切换到 单个因果假设 选项卡。

X 轴:选择要在 x 轴上绘制的特征。
Y 轴:选择要在 y 轴上绘制的特征。
单个因果散点图:将表中的点可视化为散点图,以选择数据点以分析因果假设和查看单个因果效应。
设置新的处理值:
- (数值):显示滑块以更改数值特征的值作为实际干预。
- (分类):显示一个列表以选择分类特征的值。
处理策略
选择“ 治疗策略 ”选项卡,切换到有助于确定真实干预的视图,并显示用于实现特定结果的治疗。

设置处理特征:选择要作为实际干预更改的特征。
建议的全局处理策略:显示数据队列的建议干预以提高目标特征值。 从左到右读取表格,数据集的分段先按行分,然后按列分。 例如,对于雇主不是 Snapchat 且编程语言不是 JavaScript 的 658 个人,建议的处理策略是增加参与的 GitHub 存储库数量。
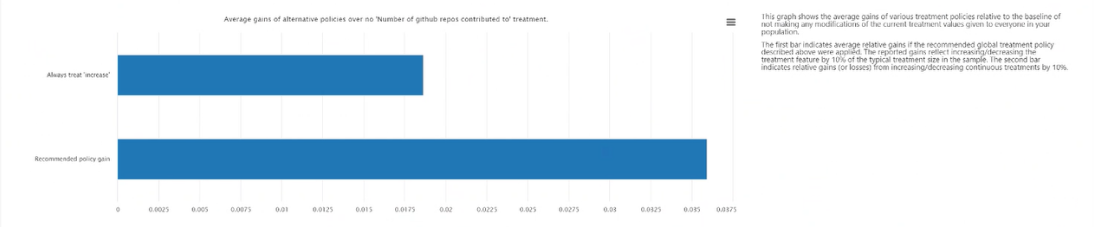
替代策略的平均收益相较于始终应用治疗的收益:将建议治疗策略下结果中的目标特征值的平均增益,与始终应用治疗的结果进行对比,并绘制成条形图。
建议的单个处理策略:
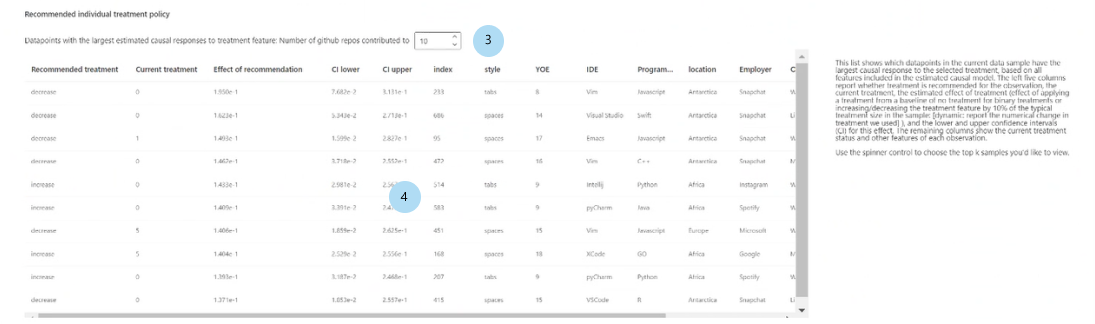
显示按建议的处理特征的因果效应排序的前 k 个数据点样本:选择要表中显示的数据点数。
建议的单个处理策略表:按因果效应的降序顺序列出其目标特征可通过干预实现最佳改善的数据点。


相关内容
- 使用导出为 PDF 的负责任 AI 记分卡汇总和共享负责任 AI 见解。
- 详细了解负责任 AI 仪表板背后的概念和技术。
- 查看示例 YAML 和 Python 笔记本,使用 YAML 或 Python 生成负责任 AI 仪表板。
- 通过此交互式 AI 实验室 Web 演示探索负责任 AI 仪表板的功能。
- 参阅此技术社区博客文章,详细了解如何使用负责任 AI 仪表板和记分卡来调试数据和模型,并为更好的决策提供信息。
- 参阅真实客户案例,了解英国国家医疗服务体系 (NHS) 如何使用负责任 AI 仪表板和记分卡。