在设计器中使用管道参数重新训练模型
本操作方法文章介绍如何使用 Azure 机器学习设计器通过管道参数重新训练机器学习模型。 你将使用已发布的管道自动执行工作流,并设置参数以使用新数据训练模型。 通过管道参数可以为不同作业重复使用现有管道。
在本文中,学习如何:
- 训练机器学习模型。
- 创建管道参数。
- 发布训练管道。
- 使用新参数重新训练模型。
先决条件
- Azure 机器学习工作区
- 请完成此操作说明系列的第 1 部分:在设计器中转换数据
重要
如果看不到本文档中提到的图形元素(例如工作室或设计器中的按钮),则你可能没有适当级别的工作区权限。 请与 Azure 订阅管理员联系,验证是否已向你授予正确级别的访问权限。 有关详细信息,请参阅管理用户和角色。
本文还假设你对在设计器中生成管道有一定的了解。 如需了解引导式简介,请完成教程。
示例管道
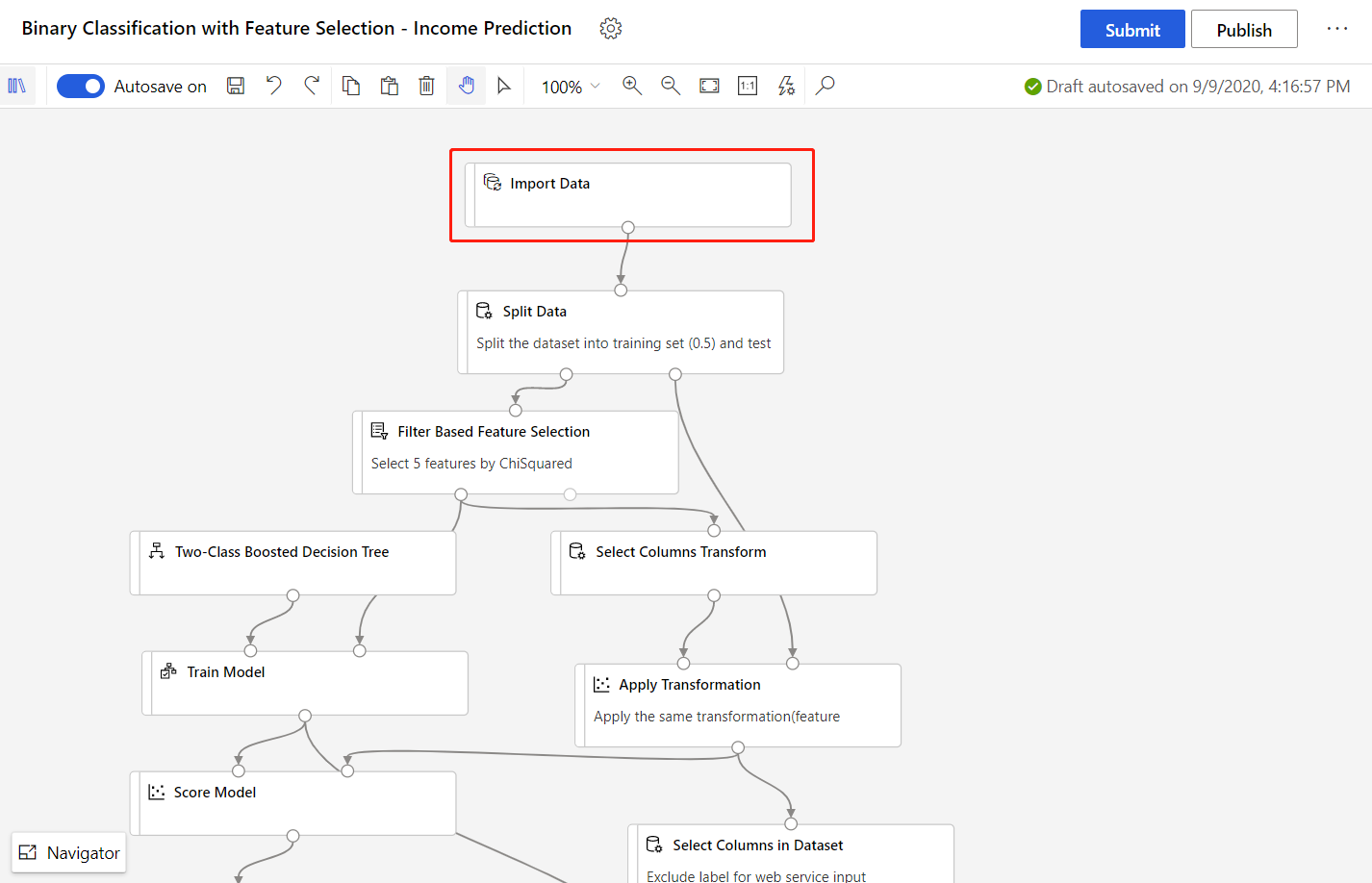
本文中使用的管道是设计器主页中的修改版示例管道:收入预测。 该管道使用导入数据组件,而不是用于演示如何使用自己的数据训练模型的示例数据集。
创建管道参数
管道参数用于生成可在以后使用不同参数值重新提交的通用管道。 一些常见应用场景包括更新数据集或某些超参数以供重新训练。 创建管道参数,以在运行时动态设置变量。
可以将管道参数添加到管道中的数据源或组件参数。 重新提交管道时,可以指定这些参数的值。
此例将训练数据路径从固定值更改为参数,这样便可以使用不同的数据重新训练模型。 还可以根据自己的用例,将其他组件参数添加为管道参数。
选择“导入数据”组件。
注意
此例使用“导入数据”组件访问已注册数据存储中的数据。 但如果使用备用的数据访问模式,则可以遵循类似的步骤操作。
在画布右侧的组件详细信息窗格中,选择数据源。
输入数据的路径。 还可以选择“浏览路径”,以浏览文件树。
将鼠标悬停在“路径”字段,然后选择显示的“路径”字段上方的省略号 。
选择“添加到管道参数”。
提供参数名称和默认值。
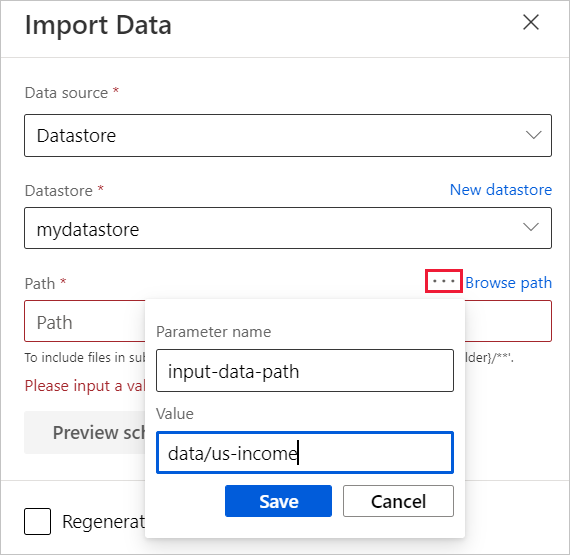
选择“保存”。
注意
还可以在组件详细信息窗格中从管道参数中拆离组件参数,类似于添加管道参数。
你可以选择管道草稿标题旁边的“设置”齿轮图标来检查和编辑管道参数。
- 分离后,可在“设置”窗格中删除管道参数。
- 还可以在“设置”窗格中添加管道参数,然后将其应用于某个组件参数。
提交管道作业。
发布训练管道
将管道发布到管道终结点,便于将来轻松地重新使用管道。 管道终结点会创建 REST 终结点,供将来调用管道。 在此例中,借助管道终结点,你可以重新使用管道来根据不同的数据重新训练模型。
选择设计器画布上方的“发布”。
选择或创建管道终结点。
注意
可将多个管道发布到一个终结点。 给定终结点中的每个管道都有一个版本号,你可以在调用管道终结点时指定该版本号。
选择“发布”。
重新训练模型
现在你已经有了一个已发布的训练管道,接下来就可以使用它来根据新数据重新训练模型。 你可以从工作室工作区或以编程方式通过管道终结点提交作业。
使用工作室门户提交作业
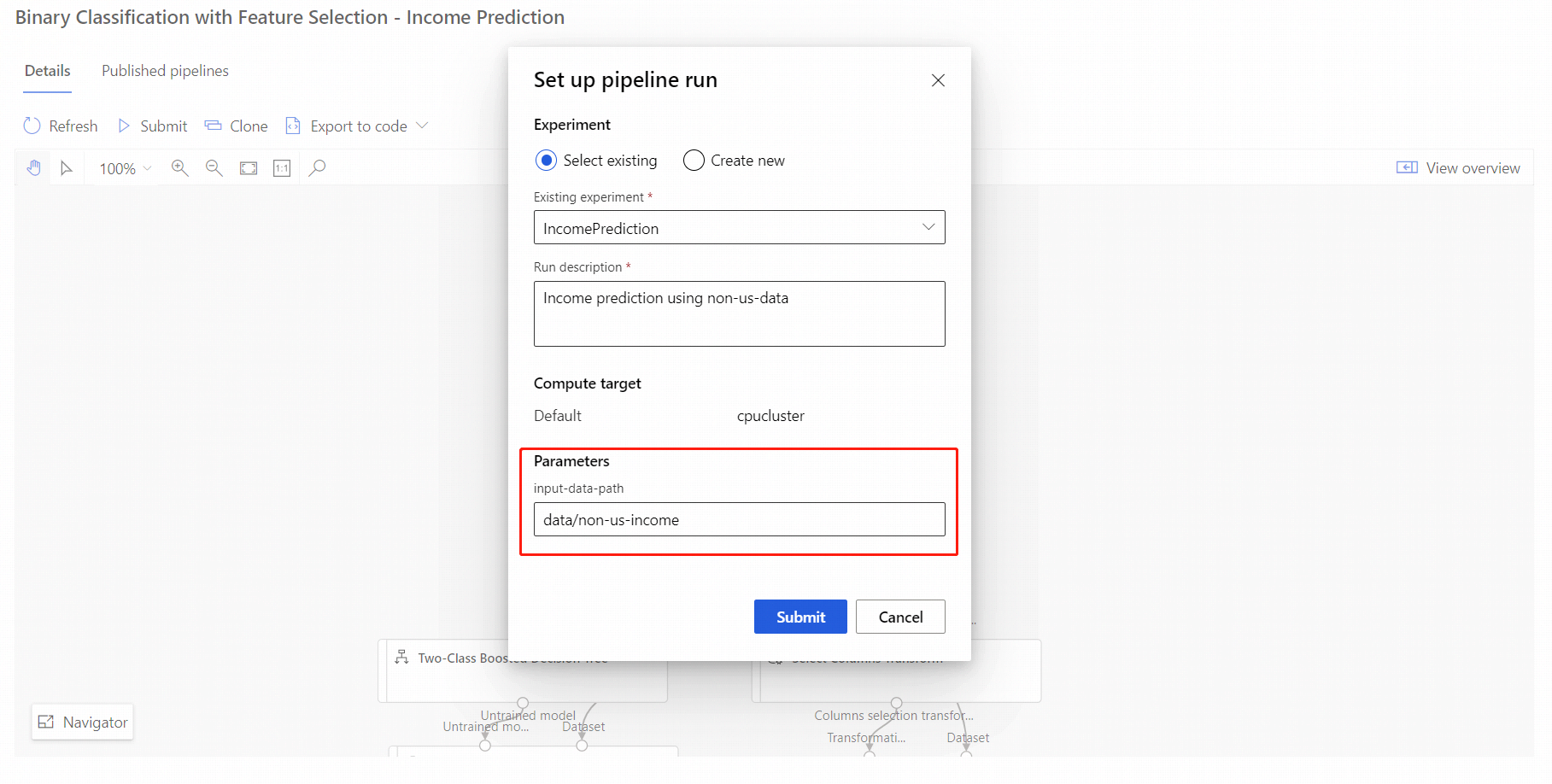
使用以下步骤通过工作室门户提交参数化管道终结点作业:
- 转到工作室工作区中的“终结点”页。
- 选择“管道终结点”选项卡。然后,选择管道终结点。
- 选择“已发布的管道”选项卡。然后,选择要运行的管道版本。
- 选择“提交”。
- 在“设置”对话框中,可以为作业指定参数值。 对于本例,请更新数据路径,使用非美国数据集来训练模型。
使用代码提交作业
在“概述”面板中可以找到已发布管道的 REST 终结点。 通过调用终结点,可重新训练已发布的管道。
若要进行 REST 调用,需要 OAuth 2.0 持有者类型的身份验证标头。 要了解如何设置针对工作区的身份验证并执行参数化 REST 调用,请参阅生成用于批量评分的 Azure 机器学习管道。
后续步骤
本文介绍了如何使用设计器创建参数化训练管道终结点。
有关如何部署模型以执行预测的完整演示,请参阅设计器教程以训练和部署回归模型。
若要了解如何使用 SDK v1 发布作业并将其提交到管道终结点,请参阅本文。