本教程介绍如何在 Azure 机器学习工作室中使用 Azure 机器学习,通过无代码自动化机器学习 (AutoML) 来训练分类模型。 此分类模型预测某个金融机构的客户是否会认购定期存款产品。
利用自动化 ML,可以自动完成耗时密集型任务。 自动机器学习会快速循环访问算法和超参数的多个组合,以帮助你根据所选的成功指标找到最佳模型。
学习本教程不需要编写任何代码。 使用工作室界面执行训练。 你将了解如何执行以下任务:
- 创建 Azure 机器学习工作区
- 运行自动化机器学习试验
- 浏览模型详细信息
- 部署建议的模型
先决条件
Azure 订阅。 如果没有 Azure 订阅,请创建一个试用帐户。
下载 bank+marketing.zip 数据文件。 我们将使用 bank-full.csv 文件。 y 列指示客户是否认购了定期存款产品,该列稍后在本教程中将标识为预测目标列。
创建工作区
Azure 机器学习工作区是云中的基础资源,用于试验、训练和部署机器学习模型。 它将 Azure 订阅和资源组关联到服务中一个易于使用的对象。
完成以下步骤来创建一个工作区,然后继续学习本教程。
登录到 Azure 机器学习工作室。
选择“创建工作区”。
提供以下信息来配置新工作区:
字段 说明 工作区名称 输入用于标识工作区的唯一名称。 名称在整个资源组中必须唯一。 使用易于记忆且区别于其他人所创建工作区的名称。 工作区名称不区分大小写。 订阅 选择要使用的 Azure 订阅。 资源组 使用订阅中的现有资源组,或者输入一个名称以创建新的资源组。 资源组保存 Azure 解决方案的相关资源。 需要“参与者”或“所有者”角色才能使用现有资源组。 有关详细信息,请参阅管理对 Azure 机器学习工作区的访问。 区域 选择离你的用户和数据资源最近的 Azure 区域来创建工作区。 选择“创建”以创建工作区。
有关 Azure 资源的详细信息,请参阅创建工作区。
有关在 Azure 中创建工作区的其他方法,请参阅在门户中或使用 Python SDK (v2) 管理 Azure 机器学习工作区。
创建自动化机器学习作业
使用位于 https://studio.ml.azure.cn 的 Azure 机器学习工作室完成以下试验设置并运行步骤。 机器学习工作室是一个整合的界面,其中包含的机器学习工具可供各种技能水平的数据科学实践者用来执行数据科学方案。 Internet Explorer 浏览器不支持此工作室。
选择创建的订阅和工作区。
在导航窗体中,选择创作>自动化 ML。
由于本教程是你的第一个自动化 ML 试验,因此你会看到空列表和文档链接。
选择新建自动化 ML 作业。
在训练方法中,选择自动训练,然后选择开始配置作业。
在基本设置中,选择新建,对于试验名称,输入 my-1st-automl-experiment。
选择下一步加载数据集。

创建数据集并将其加载为数据资产
在配置试验之前,请以 Azure 机器学习数据资产的形式将数据文件上传到工作区。 在本教程中,可以将数据资产看作是自动化 ML 作业的数据集。 这可以确保数据格式适合在试验中使用。
在任务类型和数据中,对于选择任务类型,请选择分类。
在选择数据下,选择创建。
在数据类型窗体中,为数据资产指定名称,并提供可选的说明。
对于类型,选择表格。 自动化 ML 接口目前仅支持 TabularDatasets。
选择下一步。
在数据源窗体上,选择从本地文件。 选择下一步。
在目标存储类型中,选择在创建工作区期间自动设置的默认数据存储: workspaceblobstore。 你可以将数据文件上传到此位置,使其可用于你的工作区。
选择下一步。
在文件或文件夹选择中,选择上传文件或文件夹>上传文件。
选择本地计算机上的 bankmarketing_train.csv 文件。 下载此文件作为必备组件。
选择下一步。
上传完成后,将根据文件类型填充数据预览区域。
在设置窗体中,查看数据的值。 然后选择下一步。
字段 说明 教程的值 文件格式 定义文件中存储的数据的布局和类型。 带分隔符 分隔符 一个或多个字符,用于指定纯文本或其他数据流中不同的独立区域之间的边界。 分号 编码 指定字符架构表中用于读取数据集的位。 UTF-8 列标题 指示如何处理数据集的标头(如果有)。 所有文件都具有相同的标题 跳过行 指示要跳过数据集中的多少行(如果有)。 无 通过“架构”窗体,可以进一步为此试验配置数据。 对于本示例,为 day_of_week 选择切换开关,以使其不包含在内。 选择下一步。
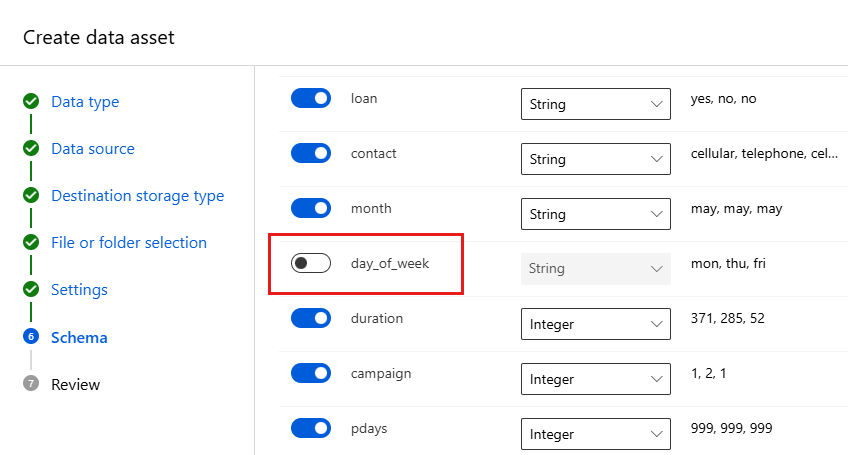
在审核窗体中,验证信息,然后选择创建。
从列表中选择数据集。
选择数据资产并查看预览选项卡来查看数据,确保不包含 day_of_week,然后选择关闭。
选择下一步以继续执行任务设置。
配置作业
加载并配置数据后,可以设置试验。 此设置包括试验设计任务,如选择计算环境大小以及指定要预测的列。
按如下所示填充任务设置窗体:
选择 y(字符串)作为用于执行预测的目标列。 此列指示客户是否认购了定期存款产品。
选择“查看其他配置设置”并按如下所示填充字段。 使用这些设置可以更好地控制训练作业。 否则,将会根据试验选择和数据应用默认设置。
其他配置 说明 教程的值 主要指标 用于对机器学习算法进行度量的评估指标。 AUCWeighted 解释最佳模型 自动显示有关自动化 ML 创建的最佳模型的可解释性。 启用 阻止的模型 要从训练作业中排除的算法 无 选择“保存”。
在验证并测试下:
- 对于验证类型,选择 k-折交叉验证。
- 对于交叉验证次数,选择 2。
选择下一步。
选择“计算群集”作为计算类型。
计算目标是本地的或基于云的资源环境,用于运行训练脚本或托管服务部署。 对于此试验,可以尝试基于云的无服务器计算(预览版),也可以创建自己的基于云的计算。
注意
若要使用无服务器计算,请启用预览功能,选择无服务器,然后跳过此步骤。
若要创建自己的计算目标,请在选择计算类型中选择计算群集以配置计算目标。
填充“虚拟机”窗体以设置计算。 选择“新建”。
字段 说明 教程的值 位置 要从中运行计算机的区域 美国西部 2 虚拟机层 选择试验应具有的优先级 专属 虚拟机类型 选择计算的虚拟机大小。 CPU(中央处理单元) 虚拟机大小 指定计算资源的虚拟机大小。 根据数据和试验类型提供了建议的大小列表。 Standard_DS12_V2 选择下一步转到高级设置窗体。
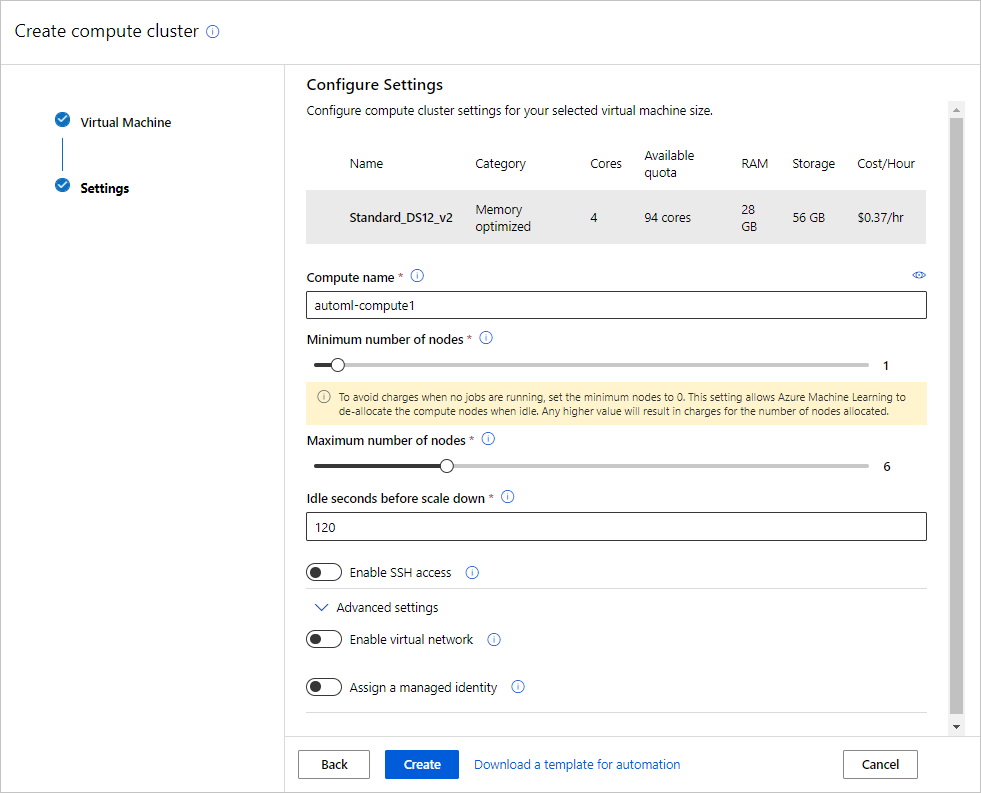
字段 说明 教程的值 计算名称 用于标识计算上下文的唯一名称。 automl-compute 最小/最大节点数 若要分析数据,必须指定一个或多个节点。 最小节点数:1
最大节点数:6缩减前的空闲秒数 群集自动缩减到最小节点数之前的空闲时间。 120(默认值) 高级设置 用于为试验配置虚拟网络并对其进行授权的设置。 无 选择创建。
创建计算可能需要几分钟才能完成。
创建后,从列表中选择新的计算目标。 选择下一步。
选择“提交训练作业”以运行试验。 当试验准备开始时,将打开概述屏幕,并且会在顶部显示状态。 此状态随着试验的进行而更新。 通知也会显示在工作室中,以告知你试验的状态。

重要
准备试验运行时,准备需要 10-15 分钟。 运行以后,每个迭代还需要 2-3 分钟。
在生产环境中,你可能会走开一段时间。 但在本教程中,你可以开始浏览模型选项卡上的已测试算法,因为当其他模型继续运行时,这些模型已经完成。
浏览模型
导航到模型 + 子作业选项卡,以查看测试的算法(模型)。 默认情况下,作业在模型完成后按指标分数对其进行排序。 对于本教程,列表中首先显示分数最高的模型(分数根据所选 AUCWeighted 指标给出)。
在等待所有试验模型完成的时候,可以选择已完成模型的“算法名称”,以便浏览其性能详细信息。 选择概述和指标选项卡,获取有关作业的信息。
以下动画显示了选定模型的属性、指标和性能图表。

查看模型说明
在等待模型完成时,你还可以查看模型说明,了解哪些数据特征(原始的或经过工程处理的)影响特定模型的预测。
这些模型说明可以按需生成。 模型说明仪表板是说明(预览版)选项卡的一部分,总结了这些说明。
若要生成模型说明,请执行以下操作:
在页面顶部的导航链接中,选择要返回到模型屏幕的作业名称。
选择模型 + 子作业选项卡。
对于本教程,请选择第一个“MaxAbsScaler, LightGBM”模型。
选择解释模型。 此时右侧会显示“说明模型”窗格。
选择计算类型,然后选择之前创建的实例或群集:automl-compute。 此计算会启动一个子作业来生成模型说明。
选择创建。 一条绿色成功消息随即出现。
注意
说明性作业需要大约 2-5 分钟才能完成。
选择(说明(预览版))。 在模型说明运行完成后,此选项卡就会进行填充。
在左侧,展开窗格。 在功能下,选择显示原始的行。
选择聚合特征重要性选项卡。此图表显示哪些数据特征影响了所选模型的预测。
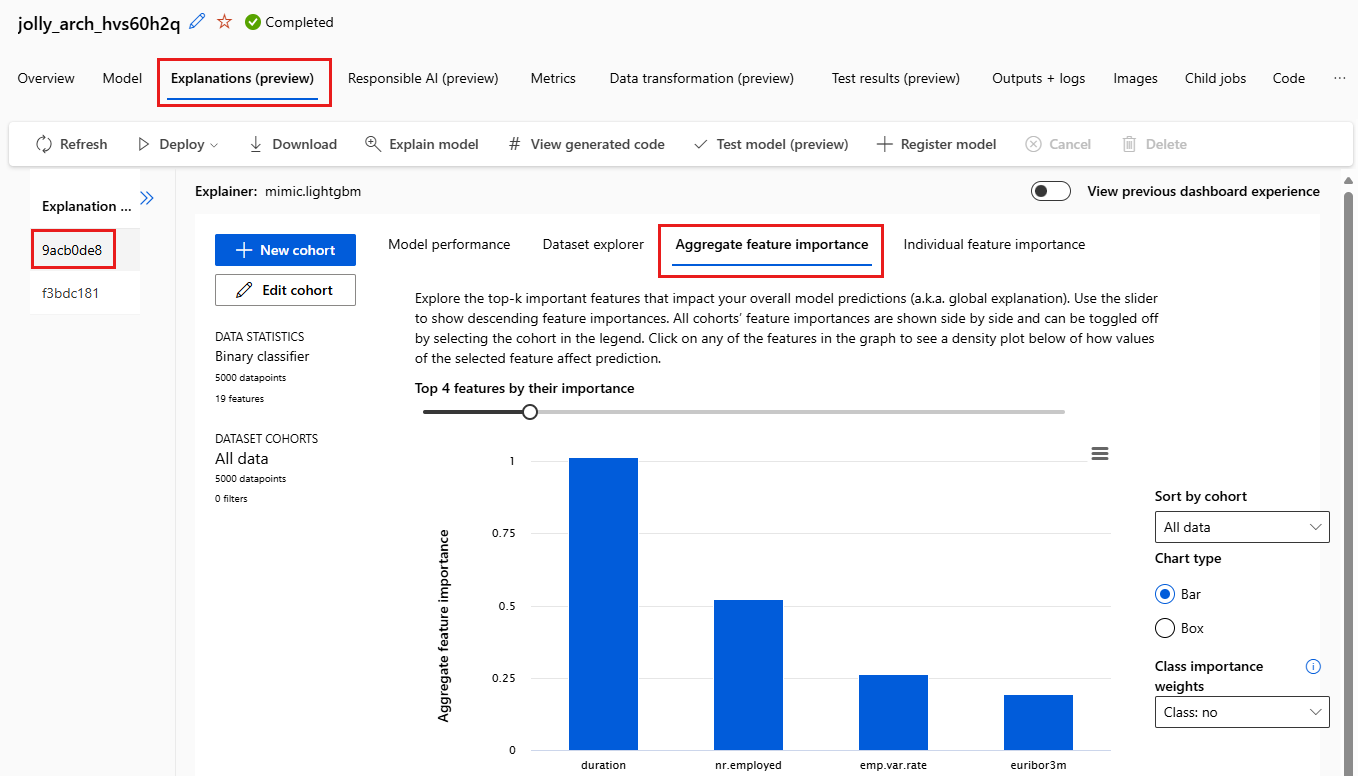
在此示例中,“持续时间”看起来对此模型的预测影响最大。

部署最佳模型
使用自动化机器学习界面,你可以将最佳模型部署为 Web 服务。 部署是模型的集成,因此它可以对新数据进行预测并识别潜在的机会领域。 对于本试验,部署到 Web 服务意味着金融机构现已获得一个迭代和可缩放的 Web 解决方案,用于识别潜在的定期存款客户。
检查试验运行是否完成。 为此,请选择屏幕顶部的作业名称,导航回父作业页。 “已完成”状态将显示在屏幕的左上角。
试验运行完成后,详细信息页中会填充最佳模型摘要部分。 在此试验上下文中,根据 AUCWeighted 指标,VotingEnsemble 被视为最佳模型。
部署此模型。 部署需要大约 20 分钟才能完成。 部署过程需要几个步骤,包括注册模型、生成资源和为 Web 服务配置资源。
选择“VotingEnsemble”打开特定于模型的页面。
选择部署>Web 服务。
按如下所示填充“部署模型”窗格:
字段 值 名称 my-automl-deploy 说明 我的第一个自动化机器学习试验部署 计算类型 选择 Azure 容器实例 启用身份验证 禁用。 使用自定义部署资产 禁用。 允许自动生成默认驱动程序文件(评分脚本)和环境文件。 本示例使用高级菜单中提供的默认值。
选择“部署”。
作业屏幕顶部会出现一条绿色的成功消息。 在模型摘要窗格中,状态消息显示在部署状态下。 定期选择“刷新”以检查部署状态。
你已获得一个正常运行的、可以生成预测结果的 Web 服务。
转到相关内容,详细了解如何使用新的 Web 服务,以及如何使用 Power BI 的内置 Azure 机器学习支持来测试预测。
清理资源
部署文件比数据文件和试验文件更大,因此它们的存储成本也更大。 仅当你想要想要保留工作区和试验文件,才删除部署文件,以最大程度地降低帐户成本。 如果你不打算使用任何文件,请删除整个资源组。
删除部署实例
仅从 Azure 机器学习中删除部署实例,位置为 https://studio.ml.azure.cn/.
转到 Azure 机器学习。 导航到你的工作区,在资产窗格下,选择终结点。
选择要删除的部署,然后选择“删除”。
选择“继续”。
删除资源组
重要
已创建的资源可用作其他 Azure 机器学习教程和操作方法文章的先决条件。
如果你不打算使用已创建的任何资源,请删除它们,以免产生任何费用:
在 Azure 门户的搜索框中输入“资源组”,然后从结果中选择它。
从列表中选择你创建的资源组。
在“概述”页面上,选择“删除资源组”。
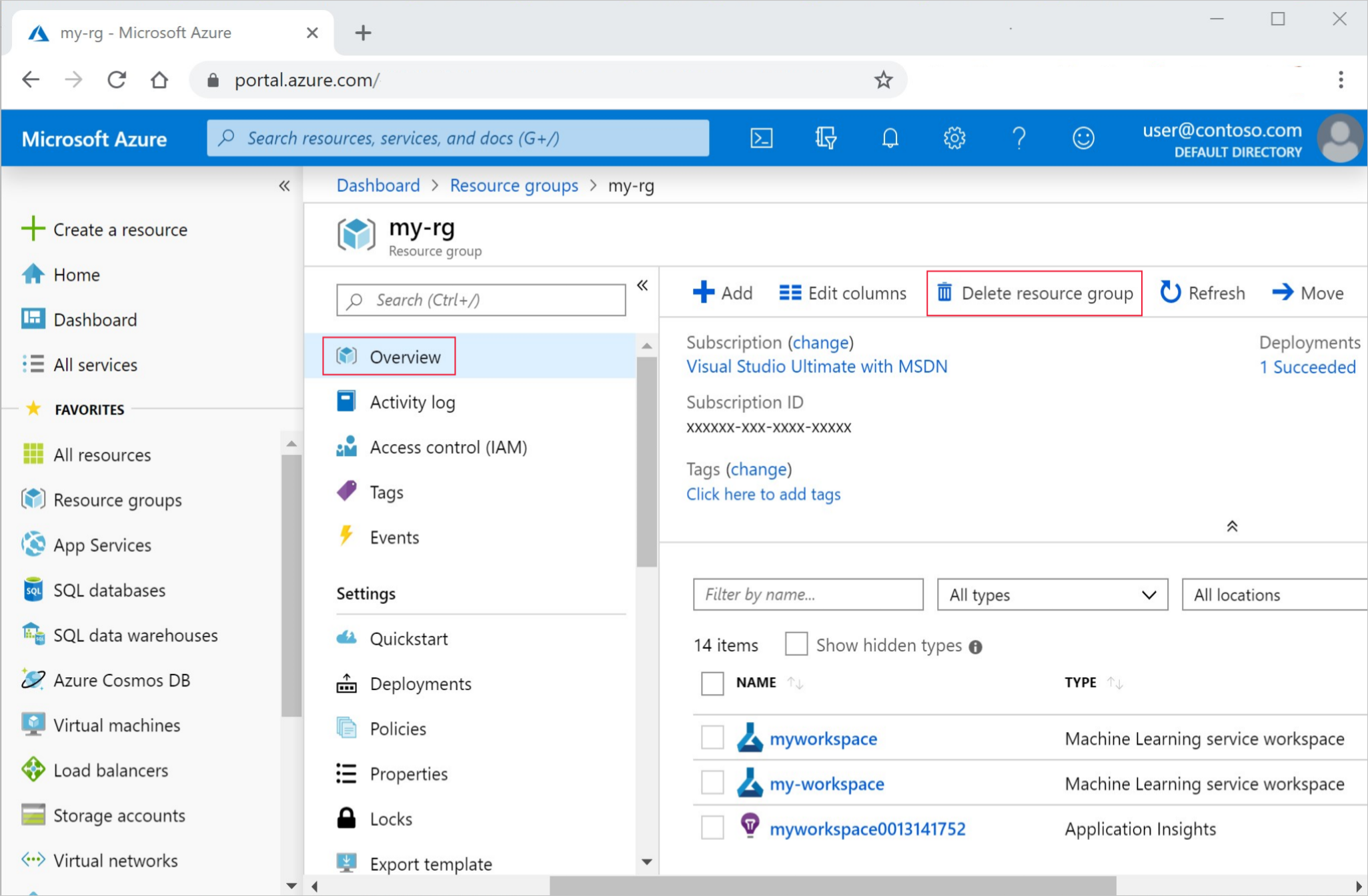
输入资源组名称。 然后选择“删除”。
相关内容
在本自动化机器学习教程中,你已使用 Azure 机器学习的自动化 ML 界面创建并部署了一个分类模型。 有关详细信息和后续步骤,请参阅以下资源:
- 详细了解自动化机器学习。
- 了解分类指标和图表:评估自动化机器学习试验结果文章。
- 详细了解如何为 NLP 设置 AutoML。
此外,请为其他这些模型类型尝试自动化机器学习:
- 有关无代码预测的示例,请参阅教程:在 Azure 机器学习工作室中使用无代码自动化机器学习预测需求。
- 有关物体检测模型的代码优先示例,请参阅教程:使用 AutoML 和 Python 训练物体检测模型。