本教程系列介绍如何使用托管功能存储来发现、创建和作 Azure 机器学习功能。 功能无缝集成机器学习生命周期的原型制作、训练和作化阶段。
Important
Azure Cache for Redis 已正式公布所有 SKU 的退役时间表。 建议尽快将现有的 Azure Redis 缓存实例移动到 Azure 托管 Redis。
迁移指南:
有关停用的更多详细信息:
在原型制作阶段,可以试验各种功能,并在作化阶段部署使用推理步骤来查找特征数据的模型。 功能在生命周期中充当纽带。
使用 Azure 机器学习项目工作区通过功能存储中的功能训练推理模型。 许多项目工作区可以共享和重复使用同一功能商店。 有关托管功能存储的详细信息,请参阅 什么是托管功能存储 ,并 了解托管功能存储中的顶级实体。
先决条件
- 一个 Azure 机器学习工作区。 有关工作区创建的详细信息,请参阅 快速入门:创建工作区资源。
- 在创建功能存储的资源组中担任所有者角色。
SDK + CLI 或仅 SDK 的教程路径
本教程系列使用 Azure 机器学习 Spark 笔记本进行开发。 可以根据需求在两个曲目之间进行选择以完成教程系列。
SDK + CLI 跟踪使用 Python SDK 用于功能集的开发和测试,并使用 Azure CLI 来执行创建、读取、更新和删除(CRUD)操作。 此流程适用于持续集成和持续交付(CI/CD)及 GitOps 方案,这些方案使用 CLI 和 YAML。
仅使用 Python SDK 的方案。 此课程提供纯 Python 基础的开发和部署。
在克隆的笔记本中,通过打开 cli_and_sdk 或 sdk_only 文件夹中的笔记本,您可以选择一个路径。 请按照教程中对应的选项卡中的说明进行操作。
SDK + CLI 路径使用 Azure CLI 执行 CRUD 操作,并使用要素存储核心 SDK 进行要素集的开发和测试。 此方法适用于使用 CLI 和 YAML 的 GitOps 或 CI/CD 方案。 上传 conda.yml 文件将安装这些资源。
- CLI 用于对特征存储、特征集和特征存储实体执行 CRUD 操作。
功能存储核心 SDK
azureml-featurestore用于功能集开发和使用。 SDK 执行以下作:- 列出或获取已注册的功能集。
- 生成或解析特征检索规范。
- 执行功能集定义以生成 Spark 数据帧。
- 使用时间点联接生成训练数据。
教程 1:开发和注册功能集
第一个教程介绍如何使用自定义转换创建功能集规范。 然后,使用该特征集生成训练数据,启用物化,并执行回填。 你将学会如何:
- 创建新的最小特征存储资源。
- 使用特征转换功能开发和本地测试特征集。
- 向特征存储注册特征存储实体。
- 请将您开发的特征集注册到特征存储中。
- 使用创建的功能生成示例训练数据帧。
- 对特征集启用离线物化,并回填特征数据。
克隆笔记本
在 Azure 机器学习工作室中,选择左侧导航菜单上的笔记本,然后选择“笔记本”页上的“示例”选项卡。
展开 SDK v2>sdk>python 文件夹,右键单击 featurestore_sample 文件夹,然后选择“ 克隆”。
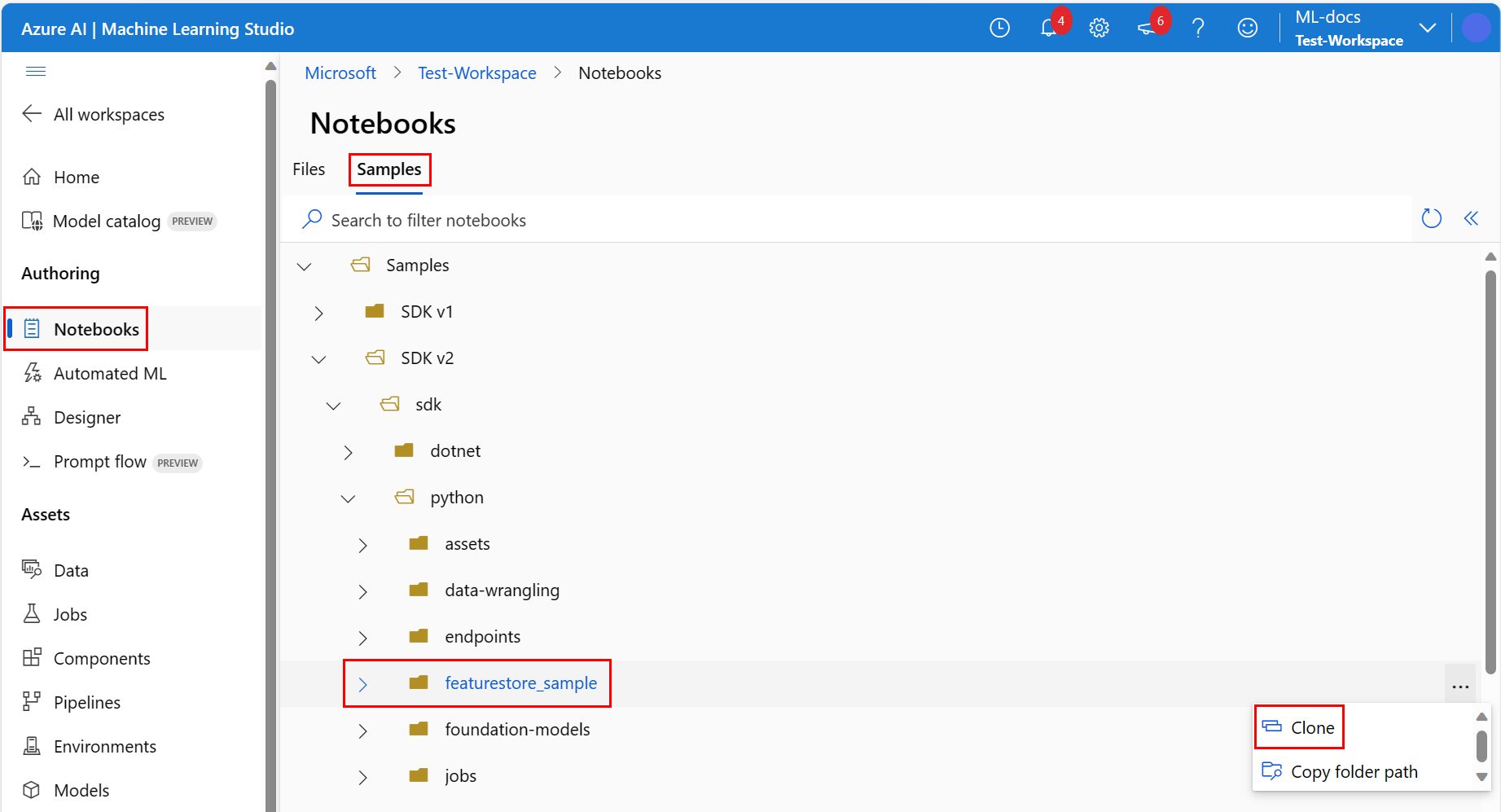
在 “选择目标目录 ”窗格中,确保“ 用户><your_username>>featurestore_sample 出现,然后选择” 克隆”。 featurestore_sample被克隆到您的工作区用户目录。
在“文件”选项卡的“笔记本”页面中,转到已克隆的笔记本,然后展开用户><your_username>>featurestore_sample>项目>env。
右键单击 conda.yml 文件,然后选择“ 下载 ”将其下载到计算机,以便稍后将其上传到服务器环境。
准备并启动笔记本
在文件选项卡的左窗格中,根据您要运行的方式,展开featurestore_sample>笔记本>sdk_and_cli或sdk_only。
通过选择教程的第一章来打开它。
在 “笔记本 ”页的右上角,选择 “计算”旁边的下拉箭头,然后选择“ 无服务器 Spark 计算 - 可用”。 可能需要一两分钟才能连接计算资源。
在笔记本文件上方的顶部栏中,选择“ 配置会话”。
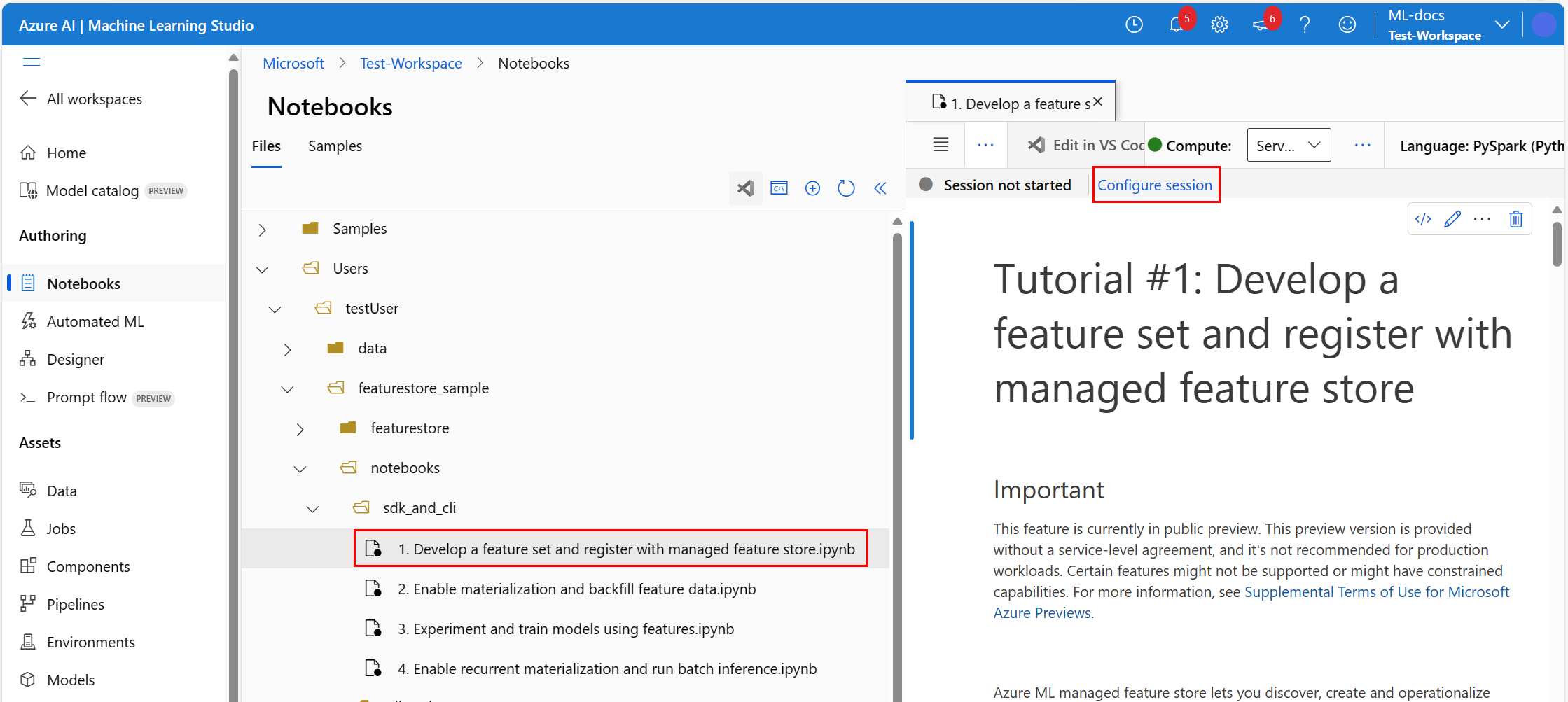
在 “配置会话 ”屏幕上,选择左侧窗格中的 Python 包 。
选择 “上传 conda 文件”,然后在 “选择 conda 文件”下,浏览到并打开下载 conda.yml 文件。
(可选)在左窗格中选择 “设置” ,并增加 会话超时 长度,以帮助防止无服务器 Spark 启动时间超时。
选择应用。

启动笔记本
- 向下滚动笔记本,直到到达第一个单元格,然后运行它以启动会话。 会话最长可能需要 15 分钟才能启动。
# Run this cell to start the spark session (any code block will start the session ). This can take around 10 mins.
print("start spark session")
- 在第二个单元格中,将占位符
<your_user_alias>更新为您的用户名。 运行单元格以设置示例的根目录。
import os
# Please update <your_user_alias> below (or any custom directory you uploaded the samples to).
# You can find the name from the directory structure in the left navigation panel.
root_dir = "./Users/<your_user_alias>/featurestore_sample"
if os.path.isdir(root_dir):
print("The folder exists.")
else:
print("The folder does not exist. Please create or fix the path")
- 运行下一个单元以安装 Azure 机器学习 CLI 扩展。
# Install AzureML CLI extension
!az extension add --name ml
- 运行下一个单元以向 Azure CLI 进行身份验证。
# Authenticate
!az login
- 运行下一个单元格以设置默认的 Azure 订阅。
# Set default subscription
import os
subscription_id = os.environ["AZUREML_ARM_SUBSCRIPTION"]
!az account set -s $subscription_id
创建最小功能商店
- 设置特征存储参数,包括名称、位置和其他值。 提供
<FEATURESTORE_NAME>并运行单元格。
# We use the subscription, resource group, region of this active project workspace.
# You can optionally replace them to create the resources in a different subsciprtion/resource group, or use existing resources.
import os
featurestore_name = "<FEATURESTORE_NAME>"
featurestore_location = "eastus"
featurestore_subscription_id = os.environ["AZUREML_ARM_SUBSCRIPTION"]
featurestore_resource_group_name = os.environ["AZUREML_ARM_RESOURCEGROUP"]
- 创建特征存储。
!az ml feature-store create --subscription $featurestore_subscription_id --resource-group $featurestore_resource_group_name --location $featurestore_location --name $featurestore_name
原型和开发功能集
此笔记本使用托管在可公开访问的 Blob 容器中的示例数据,你只能通过 wasbs 驱动程序将其读入 Spark。 如果使用自己的源数据创建功能集,请在 Azure Data Lake Storage 帐户中托管这些功能集,并在数据路径中使用 abfss 驱动程序。
查看交易源数据
生成一个名为 transactions 具有基于聚合的滚动窗口功能的功能集。
# remove the "." in the roor directory path as we need to generate absolute path to read from spark
transactions_source_data_path = "wasbs://data@azuremlexampledata.blob.core.windows.net/feature-store-prp/datasources/transactions-source/*.parquet"
transactions_src_df = spark.read.parquet(transactions_source_data_path)
display(transactions_src_df.head(5))
# Note: display(training_df.head(5)) displays the timestamp column in a different format. You can can call transactions_src_df.show() to see correctly formatted value
在本地开发功能集
特征集规范是可以在本地开发和测试的特征集的自包含定义。 创建以下滚动窗口聚合功能:
transactions three-day counttransactions amount three-day avgtransactions amount three-day sumtransactions seven-day counttransactions amount seven-day avgtransactions amount seven-day sum
from azureml.featurestore import create_feature_set_spec
from azureml.featurestore.contracts import (
DateTimeOffset,
TransformationCode,
Column,
ColumnType,
SourceType,
TimestampColumn,
)
from azureml.featurestore.feature_source import ParquetFeatureSource
transactions_featureset_code_path = (
root_dir + "/featurestore/featuresets/transactions/transformation_code"
)
transactions_featureset_spec = create_feature_set_spec(
source=ParquetFeatureSource(
path="wasbs://data@azuremlexampledata.blob.core.windows.net/feature-store-prp/datasources/transactions-source/*.parquet",
timestamp_column=TimestampColumn(name="timestamp"),
source_delay=DateTimeOffset(days=0, hours=0, minutes=20),
),
feature_transformation=TransformationCode(
path=transactions_featureset_code_path,
transformer_class="transaction_transform.TransactionFeatureTransformer",
),
index_columns=[Column(name="accountID", type=ColumnType.string)],
source_lookback=DateTimeOffset(days=7, hours=0, minutes=0),
temporal_join_lookback=DateTimeOffset(days=1, hours=0, minutes=0),
infer_schema=True,
)
查看特征转换代码文件:featurestore/featuresets/transactions/transformation_code/transaction_transform.py。 请注意为特征定义的滚动聚合。 此文件是 Spark 转换器。 有关功能集和转换的详细信息,请参阅 什么是托管功能存储?
导出为功能集规格
若要将功能集规范注册到功能存储区,请将该规范保存在支持源代码管理的指定位置和格式中。
import os
# Create a new folder to dump the feature set specification.
transactions_featureset_spec_folder = (
root_dir + "/featurestore/featuresets/transactions/spec"
)
# Check if the folder exists, create one if it does not exist.
if not os.path.exists(transactions_featureset_spec_folder):
os.makedirs(transactions_featureset_spec_folder)
transactions_featureset_spec.dump(transactions_featureset_spec_folder, overwrite=True)
若要查看 featurestore/featuresets/accounts/spec/FeaturesetSpec.yaml 规范,请从文件树打开生成的 transactions 功能集规范。 该规范包含以下元素:
-
source:对存储资源的引用。 在本例中,它是 Blob 存储资源中的 parquet 文件。 -
features:特征及其数据类型的列表。 如果提供转换代码,则该代码必须返回映射到特征和数据类型的数据帧。 -
index_columns:访问特征集中的值所需的联接键。
注册特征存储实体
实体有助于强制实施跨使用相同逻辑实体的功能集使用相同的联接键定义的最佳做法。 实体的示例包括 accounts 和 customers。 实体通常只创建一次,然后在多个特征集之间重用。 若要了解详细信息,请参阅 了解托管功能存储中的顶级实体。
创建一个 account 实体,该实体具有 accountID 类型的联接键 string。 将account实体注册到特征存储中。
account_entity_path = root_dir + "/featurestore/entities/account.yaml"
!az ml feature-store-entity create --file $account_entity_path --resource-group $featurestore_resource_group_name --feature-store-name $featurestore_name
将特征集注册到特征存储中
以下代码向功能存储注册功能集资产。 然后,可以重复使用该资产,并轻松共享它。 注册某个功能集资产提供了托管能力,包括版本控制和实现。 本系列教程的后续部分将介绍托管功能。
account_featureset_path = (
root_dir + "/featurestore/featuresets/transactions/featureset_asset.yaml"
)
!az ml feature-set create --file $account_featureset_path --resource-group $featurestore_resource_group_name --feature-store-name $featurestore_name
了解功能商店 UI
只能通过 SDK 和 CLI 创建和更新功能商店资产。 可以使用机器学习 UI 搜索或浏览特征存储库。
- 打开 Azure 机器学习全球登陆页。
- 在左窗格中,选择“特征存储”。
- 从可访问的功能存储列表中,选择在本教程前面创建的功能存储。
分配存储 Blob 数据读取者角色
必须将 存储 Blob 数据读取者 角色分配给您的用户帐户,以确保该用户帐户能够从脱机具体化存储中读取具体化的功能数据。
从特征存储 UI 的概述页获取有关脱机物化存储的信息。 存储帐户<SUBSCRIPTION_ID>和<RESOURCE_GROUP>及<STORAGE_ACCOUNT_NAME>的脱机具体化存储的值位于脱机具体化存储卡中。

运行以下代码单元进行角色分配。 权限传播可能需要一些时间。
storage_subscription_id = "<SUBSCRIPTION_ID>"
storage_resource_group_name = "<RESOURCE_GROUP>"
storage_account_name = "<STORAGE_ACCOUNT_NAME>"
# Set the ADLS Gen2 storage account ARM ID
gen2_storage_arm_id = "/subscriptions/{sub_id}/resourceGroups/{rg}/providers/Microsoft.Storage/storageAccounts/{account}".format(
sub_id=storage_subscription_id,
rg=storage_resource_group_name,
account=storage_account_name,
)
print(gen2_storage_arm_id)
!az role assignment create --role "Storage Blob Data Reader" --assignee-object-id $your_aad_objectid --assignee-principal-type User --scope $gen2_storage_arm_id
有关访问控制的详细信息,请参阅 管理托管功能存储的访问控制。
生成训练数据数据帧
使用已注册的功能集生成训练数据数据帧。
- 加载事件本身期间捕获的观察数据。
观察数据通常涉及用于训练和推理的核心数据,该数据与特征数据联接以创建完整的训练数据资源。 以下数据具有核心事务数据,包括事务 ID、帐户 ID 和事务金额值。 由于使用数据进行训练,因此它还具有追加的目标变量 is_fraud。
observation_data_path = "wasbs://data@azuremlexampledata.blob.core.windows.net/feature-store-prp/observation_data/train/*.parquet"
observation_data_df = spark.read.parquet(observation_data_path)
obs_data_timestamp_column = "timestamp"
display(observation_data_df)
# Note: the timestamp column is displayed in a different format. Optionally, you can can call training_df.show() to see correctly formatted value
- 获取已注册的功能集并列出其功能。
# Look up the featureset by providing a name and a version.
transactions_featureset = featurestore.feature_sets.get("transactions", "1")
# List its features.
transactions_featureset.features
# Print sample values.
display(transactions_featureset.to_spark_dataframe().head(5))
- 选择要成为训练数据的一部分的功能,并使用功能存储 SDK 生成训练数据本身。 时间点连接将特征追加到训练数据中。
from azureml.featurestore import get_offline_features
# You can select features in pythonic way.
features = [
transactions_featureset.get_feature("transaction_amount_7d_sum"),
transactions_featureset.get_feature("transaction_amount_7d_avg"),
]
# You can also specify features in string form: featureset:version:feature.
more_features = [
f"transactions:1:transaction_3d_count",
f"transactions:1:transaction_amount_3d_avg",
]
more_features = featurestore.resolve_feature_uri(more_features)
features.extend(more_features)
# Generate training dataframe by using feature data and observation data.
training_df = get_offline_features(
features=features,
observation_data=observation_data_df,
timestamp_column=obs_data_timestamp_column,
)
# Ignore the message that says feature set is not materialized (materialization is optional). We will enable materialization in the subsequent part of the tutorial.
display(training_df)
# Note: the timestamp column is displayed in a different format. Optionally, you can can call training_df.show() to see correctly formatted value
启用脱机物化
具体化计算特征窗口的特征值,并将这些值存储在具体化存储中。 然后,所有特征查询都可以使用具体化存储中的这些值。
如果没有物化,特征集查询将即时对源数据应用转换,并在返回值之前计算特征值。 这个过程在原型制作阶段运行良好。 但是,对于生产环境中的训练和推理作,具体化功能可提供更高的可靠性和可用性。
特征存储的默认 Blob 存储是 Azure Data Lake Storage (ADLS) 容器。 特征存储始终是使用脱机具体化存储和用户分配的托管标识 (UAI) 创建的。
如果使用参数默认值offline_store=None和materialization_identity=None创建特征存储,系统将执行以下设置:
- 创建 ADLS 容器作为脱机存储。
- 创建 UAI 并将其作为实例化标识分配给特征存储。
- 将所需的基于角色的访问控制(RBAC)权限分配给脱机存储上的 UAI。
(可选)可以通过定义 offline_store 参数,将现有 ADLS 容器用作脱机存储。 脱机具体化存储仅支持 ADLS 容器。
(可选)可以通过定义 materialization_identity 参数来提供现有的 UAI。 在创建特征存储期间,所需的 RBAC 权限将分配给脱机存储上的 UAI。
下面的代码示例演示如何使用用户定义的 offline_store 和 materialization_identity 参数创建功能存储。
import os
from azure.ai.ml import MLClient
from azure.ai.ml.identity import AzureMLOnBehalfOfCredential
from azure.ai.ml.entities import (
ManagedIdentityConfiguration,
FeatureStore,
MaterializationStore,
)
from azure.mgmt.msi import ManagedServiceIdentityClient
# Get an existing offline store
storage_subscription_id = "<OFFLINE_STORAGE_SUBSCRIPTION_ID>"
storage_resource_group_name = "<OFFLINE_STORAGE_RESOURCE_GROUP>"
storage_account_name = "<OFFLINE_STORAGE_ACCOUNT_NAME>"
storage_file_system_name = "<OFFLINE_STORAGE_CONTAINER_NAME>"
# Get ADLS container ARM ID
gen2_container_arm_id = "/subscriptions/{sub_id}/resourceGroups/{rg}/providers/Microsoft.Storage/storageAccounts/{account}/blobServices/default/containers/{container}".format(
sub_id=storage_subscription_id,
rg=storage_resource_group_name,
account=storage_account_name,
container=storage_file_system_name,
)
offline_store = MaterializationStore(
type="azure_data_lake_gen2",
target=gen2_container_arm_id,
)
# Get an existing UAI
uai_subscription_id = "<UAI_SUBSCRIPTION_ID>"
uai_resource_group_name = "<UAI_RESOURCE_GROUP>"
uai_name = "<FEATURE_STORE_UAI_NAME>"
msi_client = ManagedServiceIdentityClient(
AzureMLOnBehalfOfCredential(), uai_subscription_id
)
managed_identity = msi_client.user_assigned_identities.get(
uai_resource_group_name, uai_name
)
# Get UAI information
uai_principal_id = managed_identity.principal_id
uai_client_id = managed_identity.client_id
uai_arm_id = managed_identity.id
materialization_identity1 = ManagedIdentityConfiguration(
client_id=uai_client_id, principal_id=uai_principal_id, resource_id=uai_arm_id
)
# Create a feature store
featurestore_name = "<FEATURE_STORE_NAME>"
featurestore_location = "<AZURE_REGION>"
featurestore_subscription_id = os.environ["AZUREML_ARM_SUBSCRIPTION"]
featurestore_resource_group_name = os.environ["AZUREML_ARM_RESOURCEGROUP"]
ml_client = MLClient(
AzureMLOnBehalfOfCredential(),
subscription_id=featurestore_subscription_id,
resource_group_name=featurestore_resource_group_name,
)
# Use existing ADLS Gen2 container and UAI
fs = FeatureStore(
name=featurestore_name,
location=featurestore_location,
offline_store=offline_store,
materialization_identity=materialization_identity1,
)
fs_poller = ml_client.feature_stores.begin_update(fs)
print(fs_poller.result())
在事务功能集上启用特征集具体化后,可以执行回填。 还可以计划重复具体化作业。 有关详细信息,请参阅本系列中的第三个教程: 启用重复具体化并运行批处理推理。
在 YAML 文件中设置 spark.sql.shuffle.partitions
Spark 配置 spark.sql.shuffle.partitions 是一个可选参数,它可以影响将功能集具体化到脱机存储中时每天生成的 Parquet 文件数。 此参数的默认值为 200。
最佳做法是避免生成许多小型 Parquet 文件。 如果特征集物化后离线特征检索变慢,请在离线存储中打开相应的文件夹。 检查问题是否涉及每天过多的小型 Parquet 文件,并根据特征数据的大小调整该参数的值。
注意
此笔记本中使用的示例数据很小。 因此,参数 spark.sql.shuffle.partitions 设置为 1,featureset_asset_offline_enabled.yaml 文件中。
transaction_asset_mat_yaml = (
root_dir
+ "/featurestore/featuresets/transactions/featureset_asset_offline_enabled.yaml"
)
!az ml feature-set update --file $transaction_asset_mat_yaml --resource-group $featurestore_resource_group_name --feature-store-name $featurestore_name
还可以将特征集资产保存为 YAML 资源。
事务功能集的回填数据
具体化计算特征窗口的特征值,并将这些计算值存储在具体化存储中。 特征具体化可提高计算值的可靠性和可用性。 现在,所有功能查询都使用来自具体化存储的值。 此步骤可对 18 个月的特征窗口执行一次性回填。
注意
可能需要确定回填数据窗口值。 该窗口必须与训练数据的窗口匹配。 例如,若要使用 18 个月的数据进行训练,则必须检索 18 个月的特征。 这意味着您应该在18个月的时间段内进行回填。
以下代码单元通过当前状态 None 或 Incomplete 生成定义的特征窗口的数据。 可以在单个回填作业中提供多个数据状态的列表,例如 ["None", "Incomplete"]。
feature_window_start_time = "2022-01-01T00:00.000Z"
feature_window_end_time = "2023-06-30T00:00.000Z"
!az ml feature-set backfill --name transactions --version 1 --by-data-status "['None', 'Incomplete']" --feature-window-start-time $feature_window_start_time --feature-window-end-time $feature_window_end_time --feature-store-name $featurestore_name --resource-group $featurestore_resource_group_name
提示
-
timestamp列应遵循yyyy-MM-ddTHH:mm:ss.fffZ格式。 -
feature_window_start_time和feature_window_end_time的粒度限制为秒。 忽略对象中的datetime毫秒数。 - 仅当特征窗口中的数据与提交作业时定义的
data_status相匹配时,才会提交具体化作业。
打印特征集中的示例数据。 输出信息显示,数据是从实化存储中检索的。 该方法 get_offline_features() 检索训练和推理数据,并默认使用具体化存储。
# Look up the feature set by providing a name and a version and display few records.
transactions_featureset = featurestore.feature_sets.get("transactions", "1")
display(transactions_featureset.to_spark_dataframe().head(5))
进一步探索离线功能具体化
可以在“具体化作业”UI 中探索特征集的特征具体化状态。
打开 Azure 机器学习全球登陆页。
在左窗格中,选择“特征存储”。
从可访问的特征存储列表中,选择您已执行回填操作的特征存储。
选择“ 具体化作业 ”选项卡。
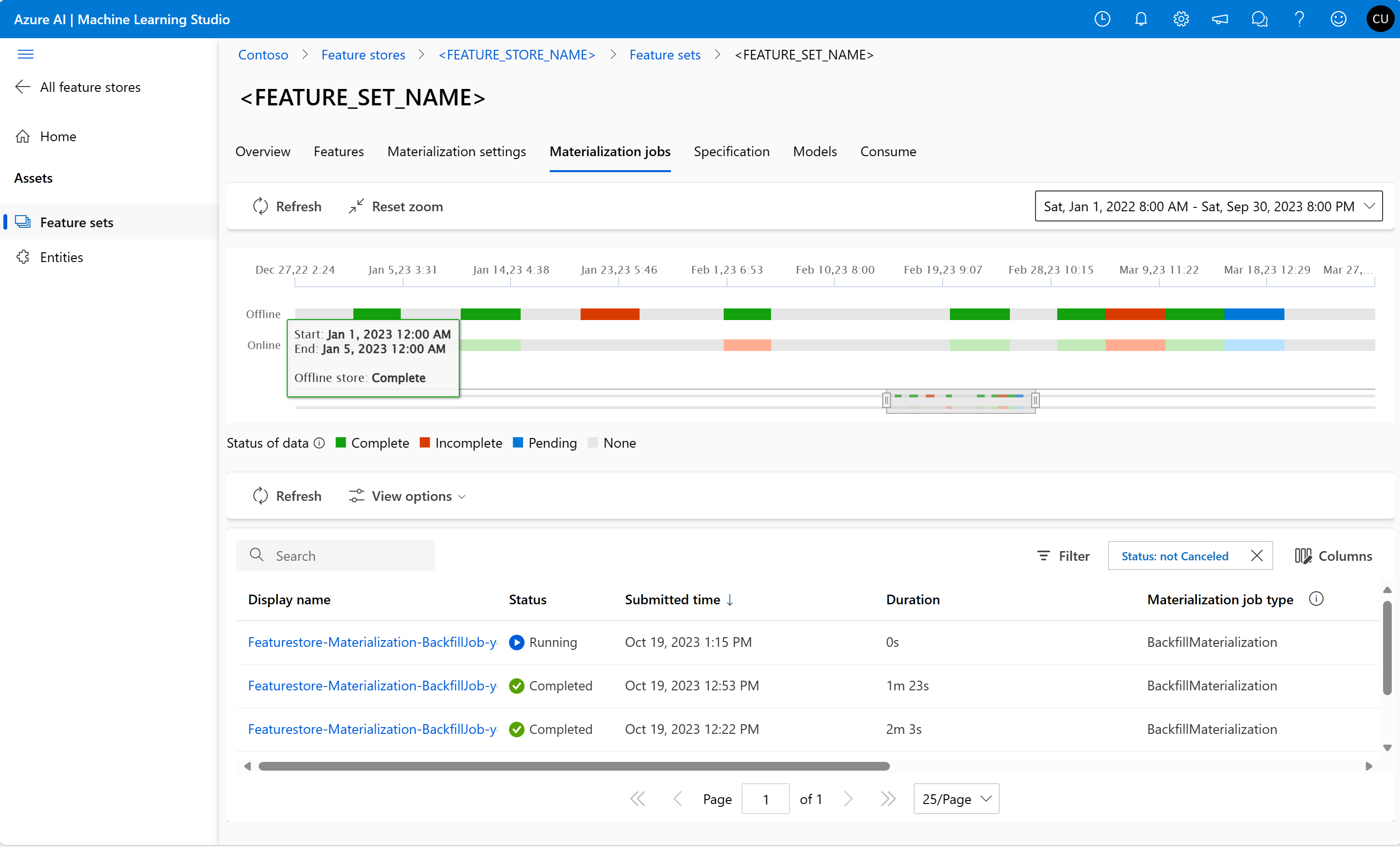

数据具体化状态可以是:
- 完成(绿色)
- 未完成(红色)
- 挂起(蓝色)
- 无(灰色)
数据间隔表示具有相同数据具体化状态的连续数据部分。 例如,前面的快照在脱机具体化存储中具有 16 个数据间隔。 数据最多可以有 2,000 个数据间隔。 如果数据包含的数据间隔超过 2,000 个,请创建一个新的功能集版本。
在回填期间,会针对属于定义的特征窗口内的每个数据间隔提交新的物化作业。 如果具体化作业已挂起或针对未回填的数据间隔运行,则不会提交任何作业。
可以重试失败的具体化任务。
注意
获取失败的物化作业的作业 ID:
- 导航到特性集 <
> UI 。 - 选择“状态”为“失败”的特定作业的“显示名称”。
- 在“作业概述”页上的“名称”属性下,找到以开头
Featurestore-Materialization-的作业 ID。
az ml feature-set backfill --by-job-id <JOB_ID_OF_FAILED_MATERIALIZATION_JOB> --name <FEATURE_SET_NAME> --version <VERSION> --feature-store-name <FEATURE_STORE_NAME> --resource-group <RESOURCE_GROUP>
更新离线物化存储
如果必须在特征存储级别更新脱机实体化存储,则特征存储中的所有特征集都应禁用脱机实体化。
如果在特征集上禁用离线具体化,则离线具体化存储中已具体化的数据的具体化状态将被重置。 重置会使已具体化的数据不可用。 启用脱机物化后,必须重新提交物化作业。
清理
本系列的第五篇教程: 使用自定义源开发功能集,介绍如何删除资源。
后续步骤
本教程使用特征存储中的特征构建了训练数据,启用了将数据实体化到离线特征存储的功能,并进行了回填。
本系列教程中的下一教程: 使用功能试验和训练模型,演示如何使用这些功能运行模型训练。